 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCCL EP: Towards a Unified Expert Parallel Communication API for NCCL
Mar 13, 2026Mixture-of-Experts (MoE) architectures have become essential for scaling large language models, driving the development of specialized device-initiated communication libraries such as DeepEP, Hybrid-EP, and others. These libraries demonstrate the performance benefits of GPU-initiated RDMA for MoE dispatch and combine operations. This paper presents NCCL EP (Expert Parallelism), a ground-up MoE communication library built entirely on NCCL's Device API. NCCL EP provides unified ncclEpDispatch and ncclEpCombine primitives with both C and Python interfaces, supporting Low-Latency (LL) mode for inference decoding and High-Throughput (HT) mode for training and inference prefill. LL targets small batch sizes (1-128 tokens) using direct all-to-all RDMA+NVLink mesh connectivity with double-buffered communication for overlapping dispatch and combine phases. HT targets large batches (4096+ tokens) using hierarchical communication that aggregates tokens within NVLink domains before inter-node RDMA transmission. Both modes leverage Device API for both intra- and inter-node communications, taking advantage of its topology awareness and optimized GPU-initiated implementation. We evaluate NCCL EP on an H100-based cluster across multi-node configurations, demonstrating competitive LL kernel performance and presenting end-to-end results with vLLM integration. By building MoE communication natively within NCCL, NCCL EP provides a supported path for expert parallelism on current and emerging NVIDIA platforms.
Exploring GPU-to-GPU Communication: Insights into Supercomputer Interconnects
Aug 26, 2024



Multi-GPU nodes are increasingly common in the rapidly evolving landscape of exascale supercomputers. On these systems, GPUs on the same node are connected through dedicated networks, with bandwidths up to a few terabits per second. However, gauging performance expectations and maximizing system efficiency is challenging due to different technologies, design options, and software layers. This paper comprehensively characterizes three supercomputers - Alps, Leonardo, and LUMI - each with a unique architecture and design. We focus on performance evaluation of intra-node and inter-node interconnects on up to 4096 GPUs, using a mix of intra-node and inter-node benchmarks. By analyzing its limitations and opportunities, we aim to offer practical guidance to researchers, system architects, and software developers dealing with multi-GPU supercomputing. Our results show that there is untapped bandwidth, and there are still many opportunities for optimization, ranging from network to software optimization.
HammingMesh: A Network Topology for Large-Scale Deep Learning
Sep 03, 2022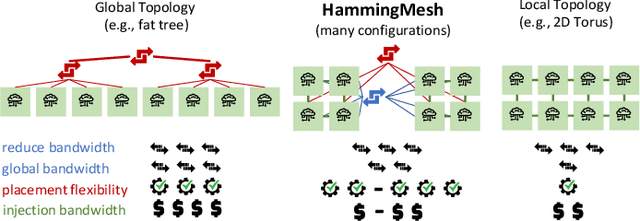
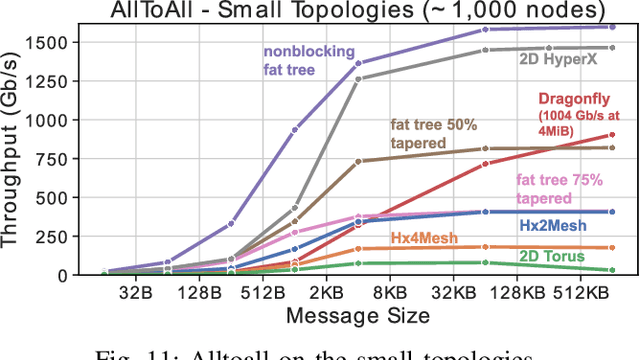
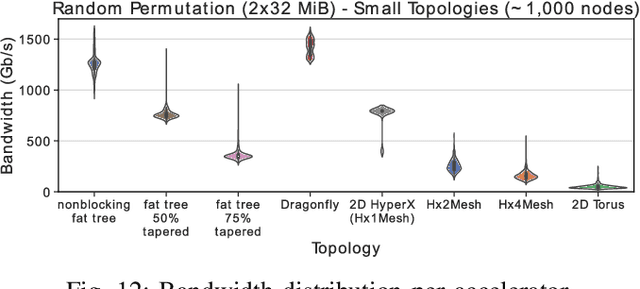
Numerous microarchitectural optimizations unlocked tremendous processing power for deep neural networks that in turn fueled the AI revolution. With the exhaustion of such optimizations, the growth of modern AI is now gated by the performance of training systems, especially their data movement. Instead of focusing on single accelerators, we investigate data-movement characteristics of large-scale training at full system scale. Based on our workload analysis, we design HammingMesh, a novel network topology that provides high bandwidth at low cost with high job scheduling flexibility. Specifically, HammingMesh can support full bandwidth and isolation to deep learning training jobs with two dimensions of parallelism. Furthermore, it also supports high global bandwidth for generic traffic. Thus, HammingMesh will power future large-scale deep learning systems with extreme bandwidth requirements.
Breaking (Global) Barriers in Parallel Stochastic Optimization with Wait-Avoiding Group Averaging
Apr 30, 2020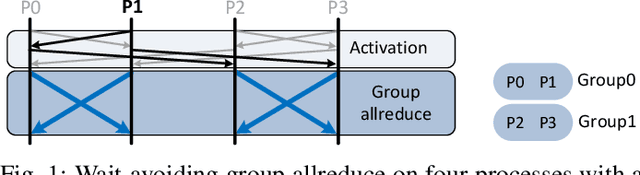
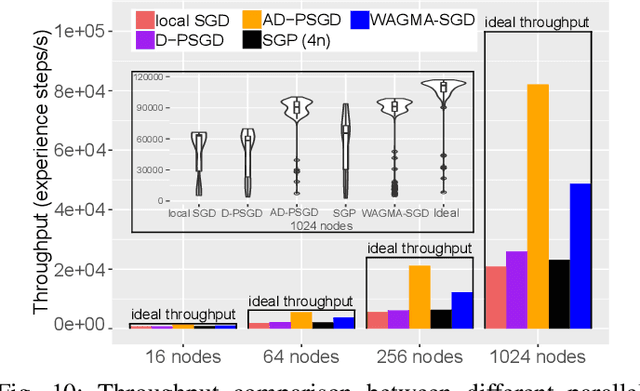
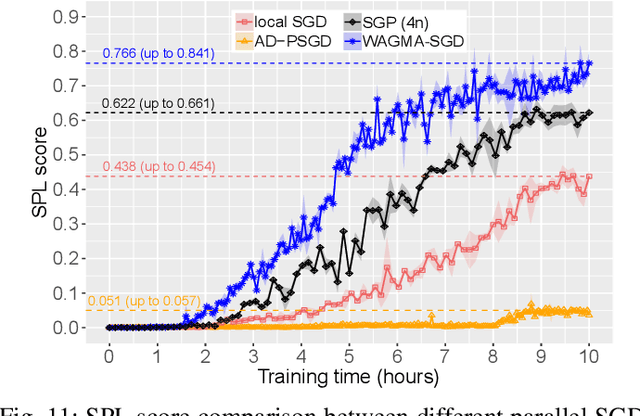
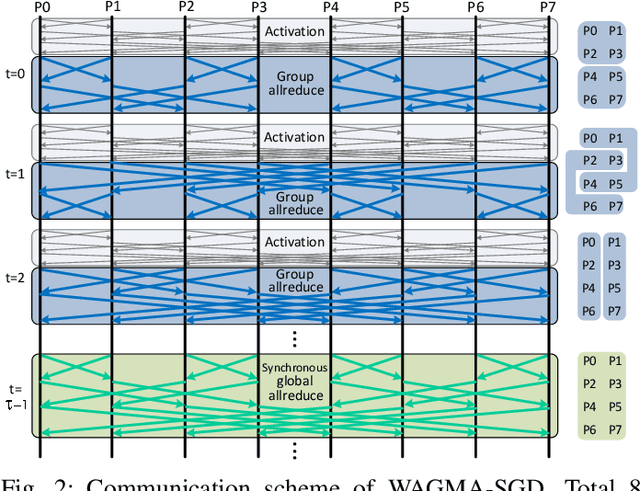
Deep learning at scale is dominated by communication time. Distributing samples across nodes usually yields the best performance, but poses scaling challenges due to global information dissemination and load imbalance across uneven sample lengths. State-of-the-art decentralized optimizers mitigate the problem, but require more iterations to achieve the same accuracy as their globally-communicating counterparts. We present Wait-Avoiding Group Model Averaging (WAGMA) SGD, a wait-avoiding stochastic optimizer that reduces global communication via subgroup weight exchange. The key insight is a combination of algorithmic changes to the averaging scheme and the use of a group allreduce operation. We prove the convergence of WAGMA-SGD, and empirically show that it retains convergence rates equivalent to Allreduce-SGD. For evaluation, we train ResNet-50 on ImageNet; Transformer for machine translation; and deep reinforcement learning for navigation at scale. Compared with state-of-the-art decentralized SGD, WAGMA-SGD significantly improves training throughput (by 2.1x on 1,024 GPUs) and achieves the fastest time-to-solution.
Taming Unbalanced Training Workloads in Deep Learning with Partial Collective Operations
Aug 13, 2019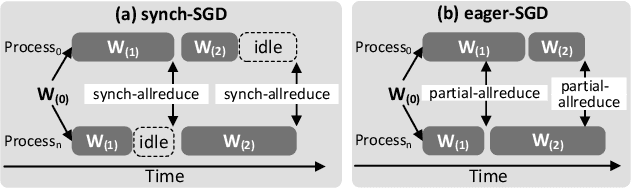

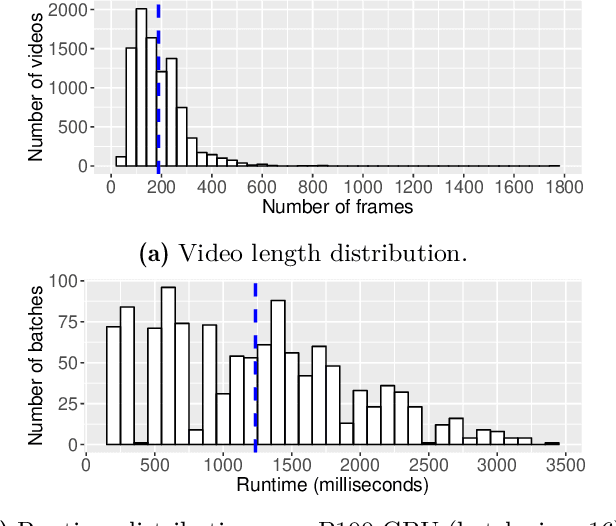
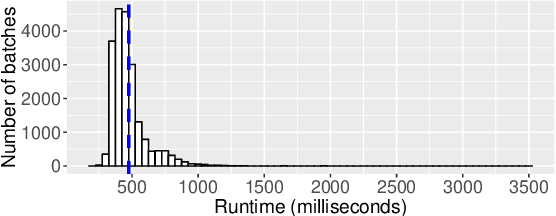
Load imbalance pervasively exists in distributed deep learning training systems, either caused by the inherent imbalance in learned tasks or by the system itself. Traditional synchronous Stochastic Gradient Descent (SGD) achieves good accuracy for a wide variety of tasks, but relies on global synchronization to accumulate the gradients at every training step. In this paper, we propose eager-SGD, which relaxes the global synchronization for decentralized accumulation. To implement eager-SGD, we propose to use two partial collectives: solo and majority. With solo allreduce, the faster processes contribute their gradients eagerly without waiting for the slower processes, whereas with majority allreduce, at least half of the participants must contribute gradients before continuing, all without using a central parameter server. We theoretically prove the convergence of the algorithms and describe the partial collectives in detail. Experimental results on load-imbalanced environments (CIFAR-10, ImageNet, and UCF101 datasets) show that eager-SGD achieves 1.27x speedup over the state-of-the-art synchronous SGD, without losing accuracy.