 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Finding teams that balance expert load and task coverage
Nov 03, 2020
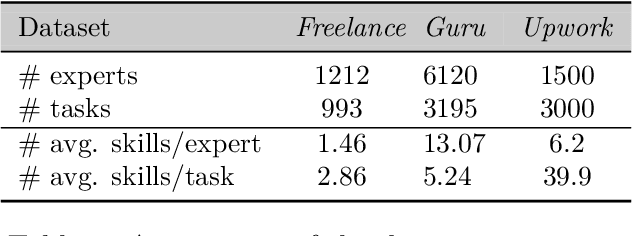
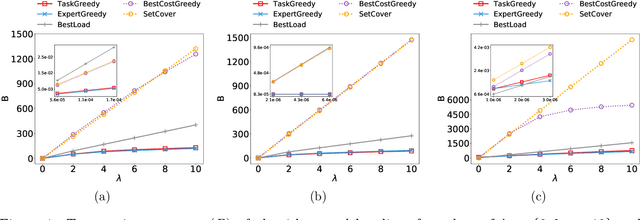
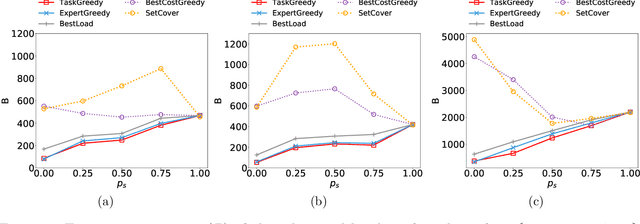
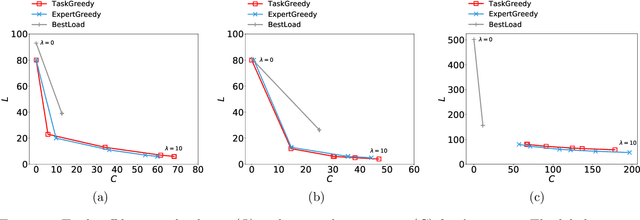
The rise of online labor markets (e.g., Freelancer, Guru and Upwork) has ignited a lot of research on team formation, where experts acquiring different skills form teams to complete tasks. The core idea in this line of work has been the strict requirement that the team of experts assigned to complete a given task should contain a superset of the skills required by the task. However, in many applications the required skills are often a wishlist of the entity that posts the task and not all of the skills are absolutely necessary. Thus, in our setting we relax the complete coverage requirement and we allow for tasks to be partially covered by the formed teams, assuming that the quality of task completion is proportional to the fraction of covered skills per task. At the same time, we assume that when multiple tasks need to be performed, the less the load of an expert the better the performance. We combine these two high-level objectives into one and define the BalancedTA problem. We also consider a generalization of this problem where each task consists of required and optional skills. In this setting, our objective is the same under the constraint that all required skills should be covered. From the technical point of view, we show that the BalancedTA problem (and its variant) is NP-hard and design efficient heuristics for solving it in practice. Using real datasets from three online market places, Freelancer, Guru and Upwork we demonstrate the efficiency of our methods and the practical utility of our framework.
Automated Reasoning in Temporal DL-Lite
Aug 17, 2020
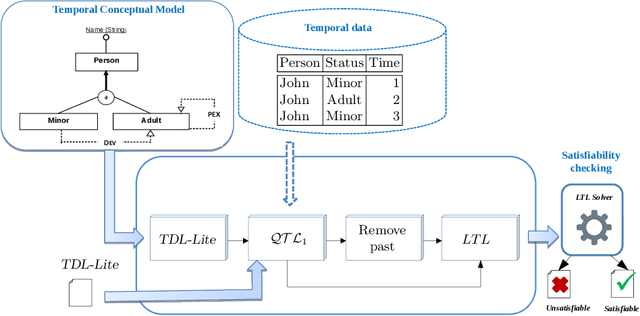
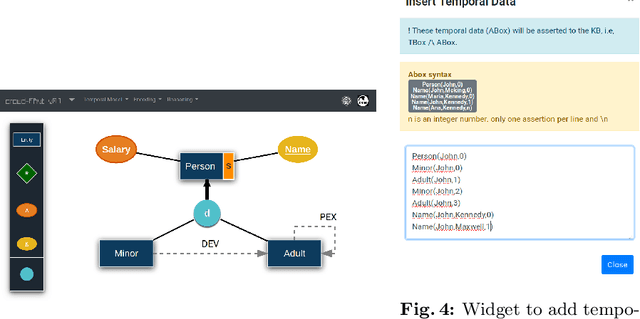
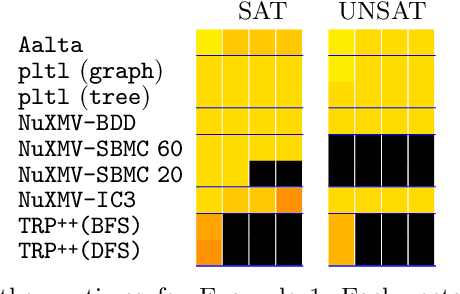
This paper investigates the feasibility of automated reasoning over temporal DL-Lite (TDL-Lite) knowledge bases (KBs). We test the usage of off-the-shelf LTL reasoners to check satisfiability of TDL-Lite KBs. In particular, we test the robustness and the scalability of reasoners when dealing with TDL-Lite TBoxes paired with a temporal ABox. We conduct various experiments to analyse the performance of different reasoners by randomly generating TDL-Lite KBs and then measuring the running time and the size of the translations. Furthermore, in an effort to make the usage of TDL-Lite KBs a reality, we present a fully fledged tool with a graphical interface to design them. Our interface is based on conceptual modelling principles and it is integrated with our translation tool and a temporal reasoner.
Data Synopses Management based on a Deep Learning Model
Aug 01, 2020
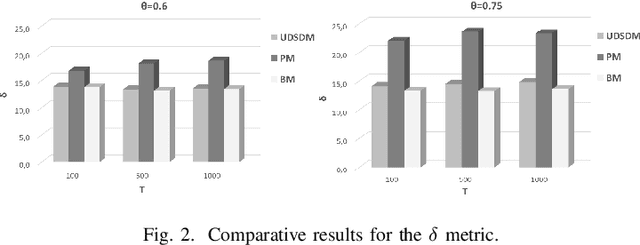
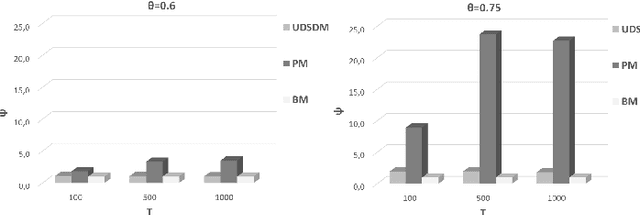
Pervasive computing involves the placement of processing services close to end users to support intelligent applications. With the advent of the Internet of Things (IoT) and the Edge Computing (EC), one can find room for placing services at various points in the interconnection of the aforementioned infrastructures. Of significant importance is the processing of the collected data. Such a processing can be realized upon the EC nodes that exhibit increased computational capabilities compared to IoT devices. An ecosystem of intelligent nodes is created at the EC giving the opportunity to support cooperative models. Nodes become the hosts of geo-distributed datasets formulated by the IoT devices reports. Upon the datasets, a number of queries/tasks can be executed. Queries/tasks can be offloaded for performance reasons. However, an offloading action should be carefully designed being always aligned with the data present to the hosting node. In this paper, we present a model to support the cooperative aspect in the EC infrastructure. We argue on the delivery of data synopses to EC nodes making them capable to take offloading decisions fully aligned with data present at peers. Nodes exchange data synopses to inform their peers. We propose a scheme that detects the appropriate time to distribute synopses trying to avoid the network overloading especially when synopses are frequently extracted due to the high rates at which IoT devices report data to EC nodes. Our approach involves a Deep Learning model for learning the distribution of calculated synopses and estimate future trends. Upon these trends, we are able to find the appropriate time to deliver synopses to peer nodes. We provide the description of the proposed mechanism and evaluate it based on real datasets. An extensive experimentation upon various scenarios reveals the pros and cons of the approach by giving numerical results.
Face Mask Assistant: Detection of Face Mask Service Stage Based on Mobile Phone
Oct 09, 2020



Coronavirus Disease 2019 (COVID-19) has spread all over the world since it broke out massively in December 2019, which has caused a large loss to the whole world. Both the confirmed cases and death cases have reached a relatively frightening number. Syndrome coronaviruses 2 (SARS-CoV-2), the cause of COVID-19, can be transmitted by small respiratory droplets. To curb its spread at the source, wearing masks is a convenient and effective measure. In most cases, people use face masks in a high-frequent but short-time way. Aimed at solving the problem that we don't know which service stage of the mask belongs to, we propose a detection system based on the mobile phone. We first extract four features from the GLCMs of the face mask's micro-photos. Next, a three-result detection system is accomplished by using KNN algorithm. The results of validation experiments show that our system can reach a precision of 82.87% (standard deviation=8.5%) on the testing dataset. In future work, we plan to expand the detection objects to more mask types. This work demonstrates that the proposed mobile microscope system can be used as an assistant for face mask being used, which may play a positive role in fighting against COVID-19.
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020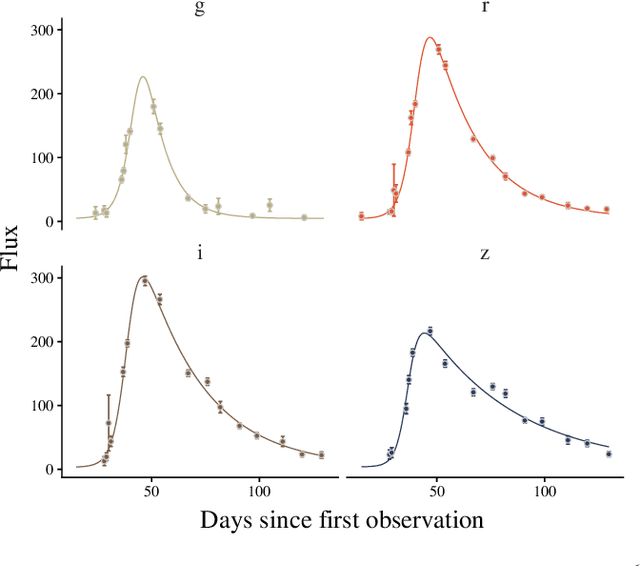
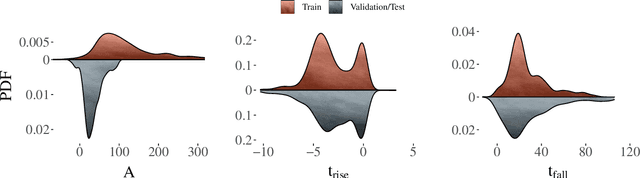
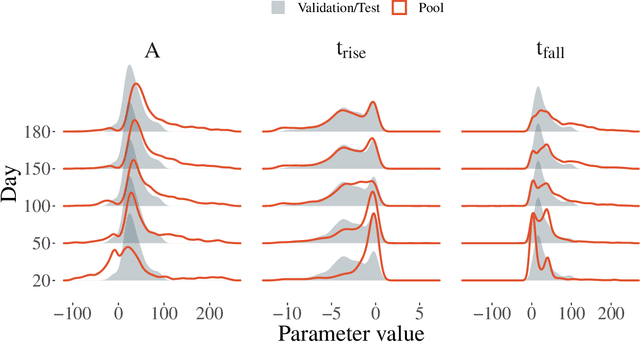
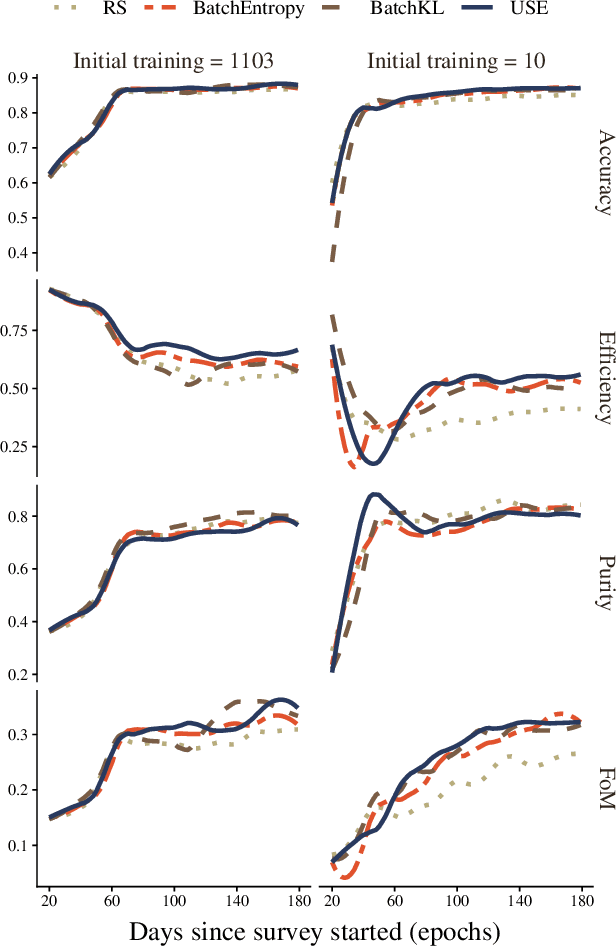
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.
Distributed ADMM with Synergetic Communication and Computation
Sep 29, 2020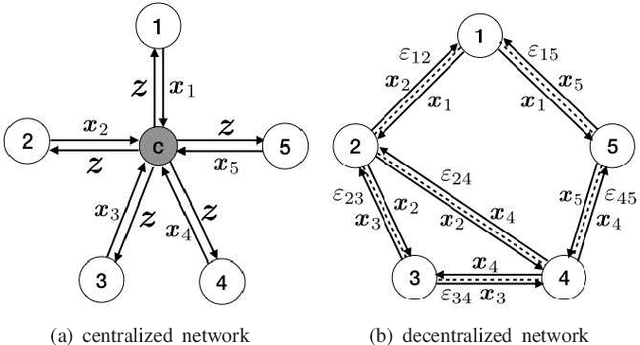
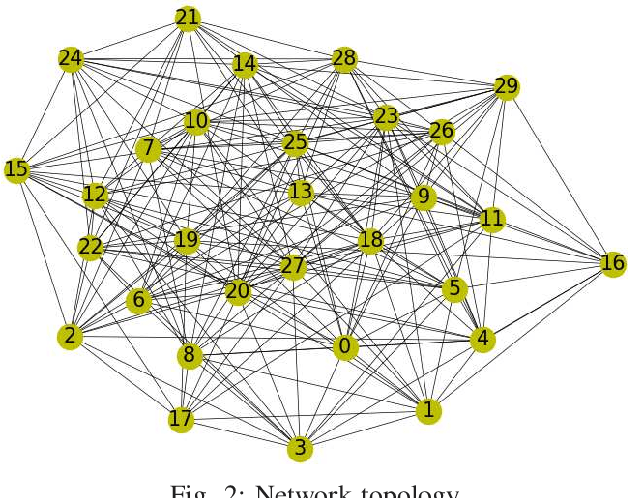
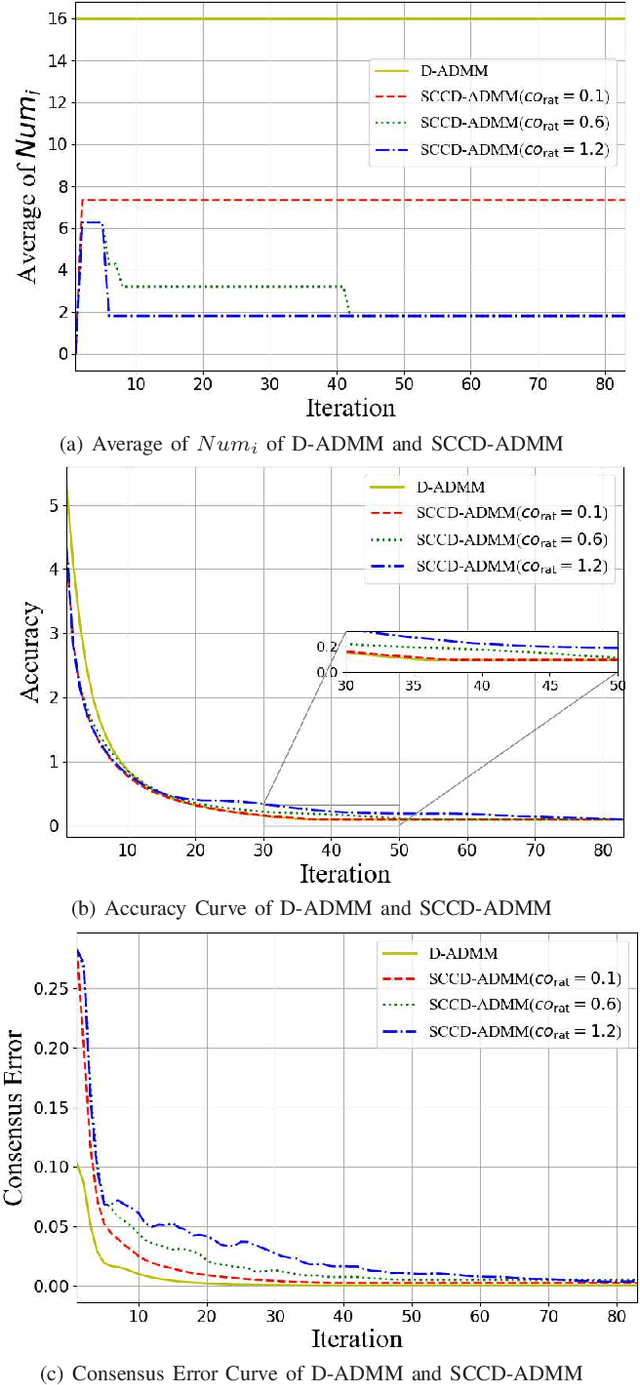
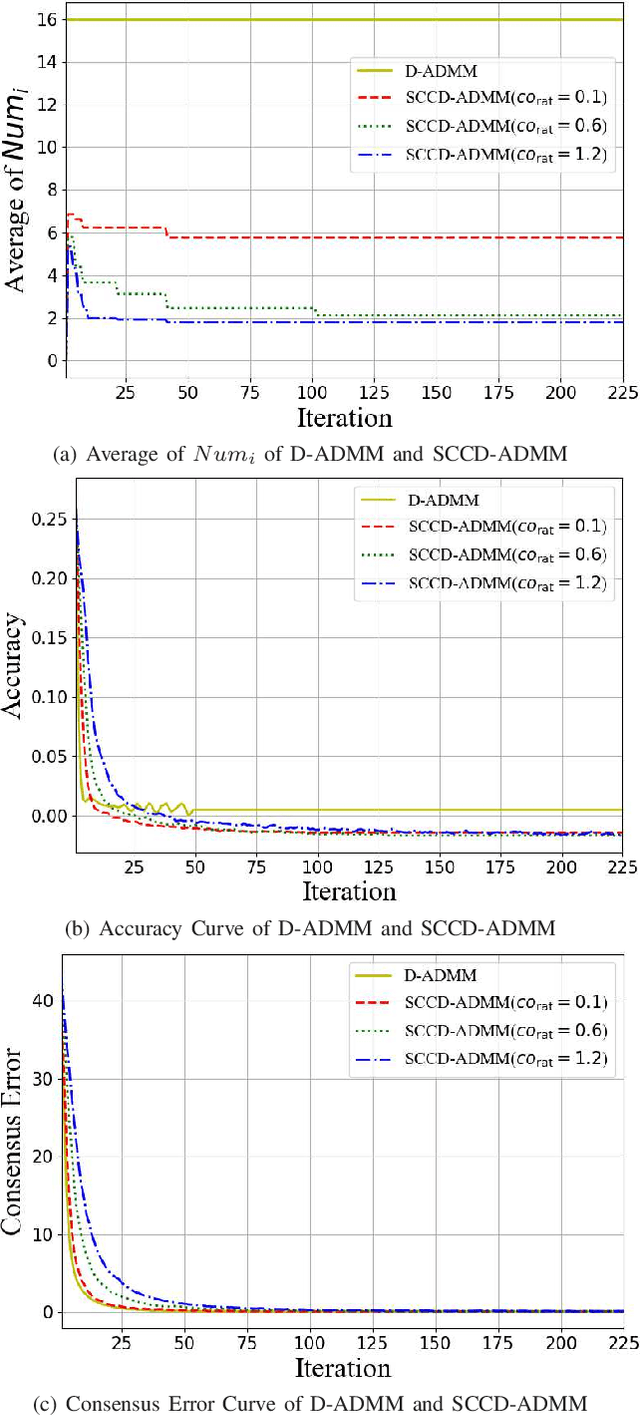
In this paper, we propose a novel distributed alternating direction method of multipliers (ADMM) algorithm with synergetic communication and computation, called SCCD-ADMM, to reduce the total communication and computation cost of the system. Explicitly, in the proposed algorithm, each node interacts with only part of its neighboring nodes, the number of which is progressively determined according to a heuristic searching procedure, which takes into account both the predicted convergence rate and the communication and computation costs at each iteration, resulting in a trade-off between communication and computation. Then the node chooses its neighboring nodes according to an importance sampling distribution derived theoretically to minimize the variance with the latest information it locally stores. Finally, the node updates its local information with a new update rule which adapts to the number of communication nodes. We prove the convergence of the proposed algorithm and provide an upper bound of the convergence variance brought by randomness. Extensive simulations validate the excellent performances of the proposed algorithm in terms of convergence rate and variance, the overall communication and computation cost, the impact of network topology as well as the time for evaluation, in comparison with the traditional counterparts.
Recurrent Graph Tensor Networks
Sep 18, 2020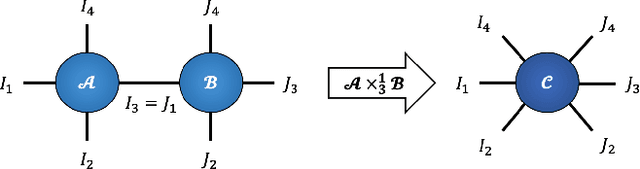

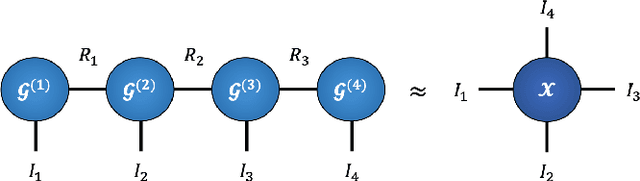
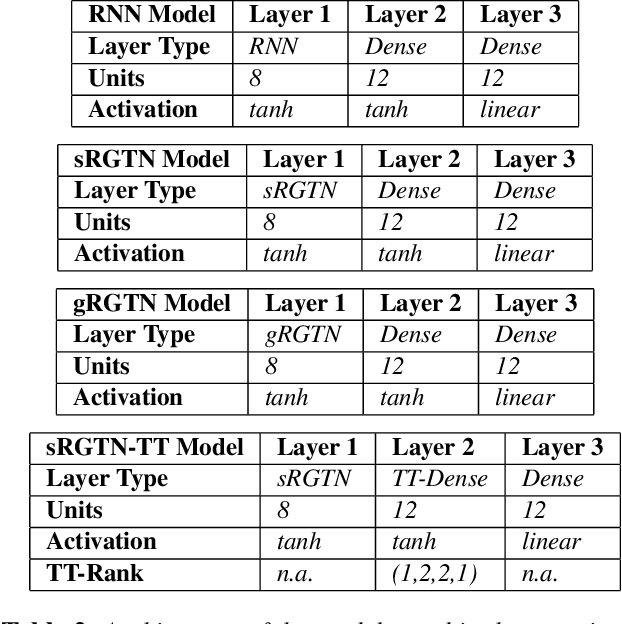
Recurrent Neural Networks (RNNs) are among the most successful machine learning models for sequence modelling. In this paper, we show that the modelling of hidden states in RNNs can be approximated through a multi-linear graph filter, which describes the directional flow of temporal information. The derived multi-linear graph filter is then generalized in tensor network form to improve its modelling power, resulting in a novel Recurrent Graph Tensor Network (RGTN). To validate the expressive power of the derived network, several variants RGTN models were porposed and employed to the task of time-series forecasting, demonstrating superior properties in terms of convergence, performance, and complexity. Specifically, by leveraging the multi-modal nature of tensor networks, RGTN models were able to out-perform a simple RNN by 45% in terms of mean-squared-error, while using up to 90% less parameters. Therefore, by combining the expressive power of tensor networks with a suitable graph filter, we show that the proposed RGTN can out-perform a classical RNN at a drastically lower parameters complexity, especially in the multi-modal setting.
A Deep Neural Network for SSVEP-based Brain Computer Interfaces
Nov 17, 2020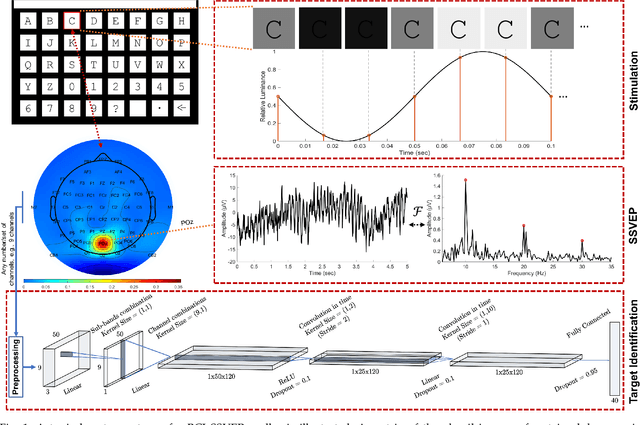
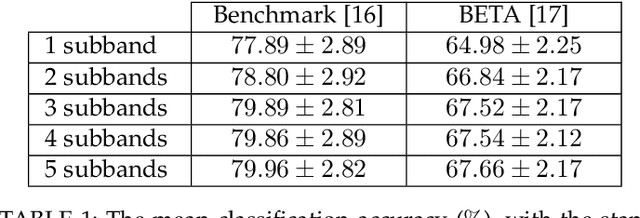

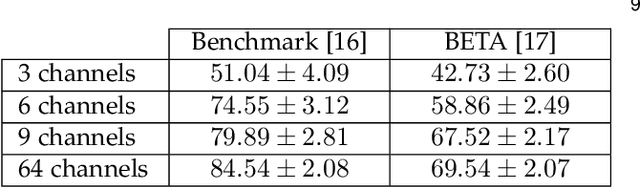
The target identification in brain-computer interface (BCI) speller systems refers to the multi-channel electroencephalogram (EEG) classification for predicting the target character that the user intends to spell. The EEG in such systems is known to include the steady-state visually evoked potentials (SSVEP) signal, which is the brain response when the user concentrates on the target while being visually presented a matrix of certain alphanumeric each of which flickers at a unique frequency. The SSVEP in this setting is characteristically dominated at varying degrees by the harmonics of the stimulation frequency; hence, a pattern analysis of the SSVEP can solve for the mentioned multi-class classification problem. To this end, we propose a novel deep neural network (DNN) architecture for the target identification in BCI SSVEP spellers. The proposed DNN is an end-to-end system: it receives the multi-channel SSVEP signal, proceeds with convolutions across the sub-bands of the harmonics, channels and time, and classifies at the fully connected layer. Our experiments are on two publicly available (the benchmark and the BETA) datasets consisting of in total 105 subjects with 40 characters. We train in two stages. The first stage obtains a global perspective into the whole SSVEP data by exploiting the commonalities, and transfers the global model to the second stage that fine tunes it down to each subject separately by exploiting the individual statistics. In our extensive comparisons, our DNN is demonstrated to significantly outperform the state-of-the-art on the both two datasets, by achieving the information transfer rates (ITR) 265.23 bits/min and 196.59 bits/min, respectively. To the best of our knowledge, our ITRs are the highest ever reported performance results on these datasets. The code, and the proposed DNN model are available at https://github.com/osmanberke/Deep-SSVEP-BCI.
Learning to Optimise General TSP Instances
Nov 03, 2020
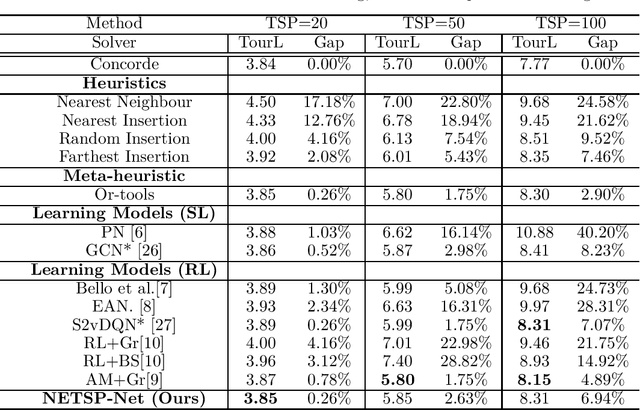
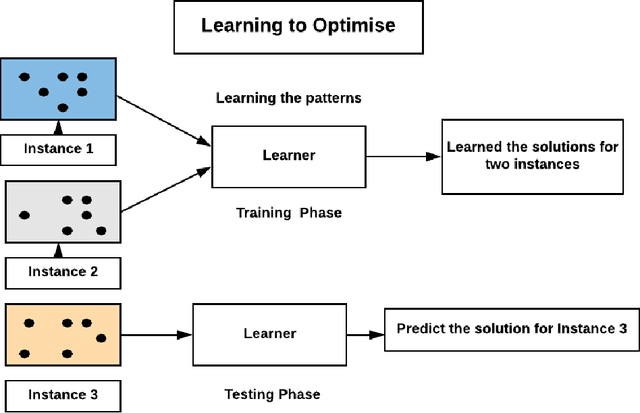
The Travelling Salesman Problem (TSP) is a classical combinatorial optimisation problem. Deep learning has been successfully extended to meta-learning, where previous solving efforts assist in learning how to optimise future optimisation instances. In recent years, learning to optimise approaches have shown success in solving TSP problems. However, they focus on one type of TSP problem, namely ones where the points are uniformly distributed in Euclidean spaces and have issues in generalising to other embedding spaces, e.g., spherical distance spaces, and to TSP instances where the points are distributed in a non-uniform manner. An aim of learning to optimise is to train once and solve across a broad spectrum of (TSP) problems. Although supervised learning approaches have shown to achieve more optimal solutions than unsupervised approaches, they do require the generation of training data and running a solver to obtain solutions to learn from, which can be time-consuming and difficult to find reasonable solutions for harder TSP instances. Hence this paper introduces a new learning-based approach to solve a variety of different and common TSP problems that are trained on easier instances which are faster to train and are easier to obtain better solutions. We name this approach the non-Euclidean TSP network (NETSP-Net). The approach is evaluated on various TSP instances using the benchmark TSPLIB dataset and popular instance generator used in the literature. We performed extensive experiments that indicate our approach generalises across many types of instances and scales to instances that are larger than what was used during training.
Learning Emotional-Blinded Face Representations
Sep 18, 2020
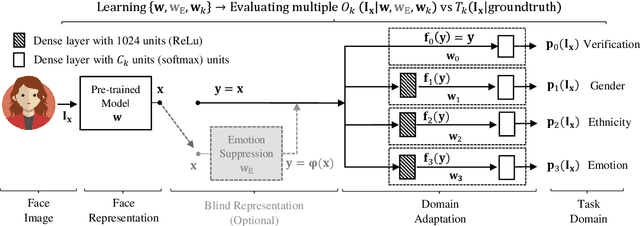
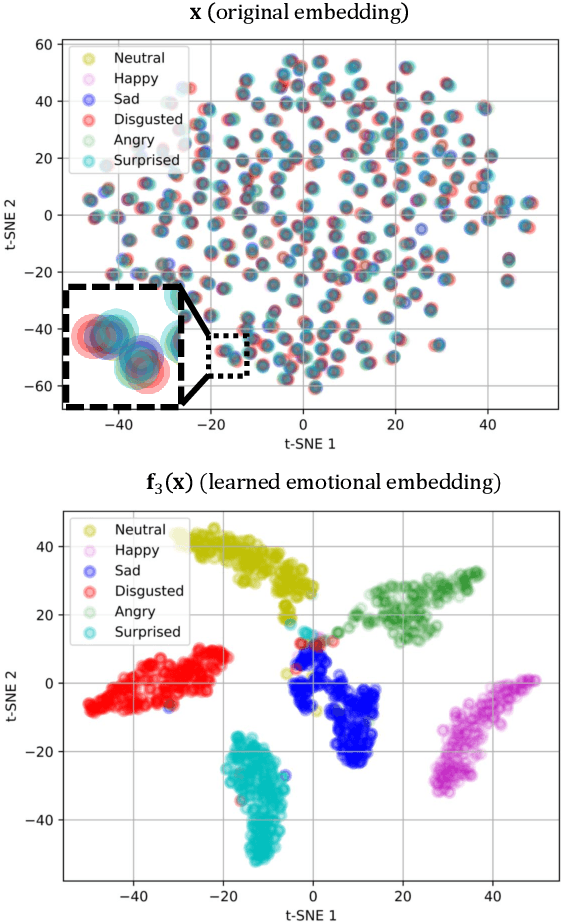
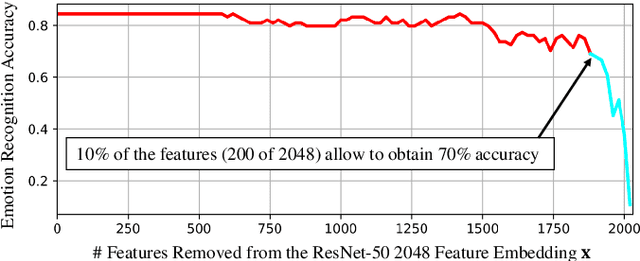
We propose two face representations that are blind to facial expressions associated to emotional responses. This work is in part motivated by new international regulations for personal data protection, which enforce data controllers to protect any kind of sensitive information involved in automatic processes. The advances in Affective Computing have contributed to improve human-machine interfaces but, at the same time, the capacity to monitorize emotional responses triggers potential risks for humans, both in terms of fairness and privacy. We propose two different methods to learn these expression-blinded facial features. We show that it is possible to eliminate information related to emotion recognition tasks, while the performance of subject verification, gender recognition, and ethnicity classification are just slightly affected. We also present an application to train fairer classifiers in a case study of attractiveness classification with respect to a protected facial expression attribute. The results demonstrate that it is possible to reduce emotional information in the face representation while retaining competitive performance in other face-based artificial intelligence tasks.