 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyrax: An Extensible Framework for Rapid ML Experimentation and Unsupervised Discovery in the Era of Rubin, Roman, and Euclid
May 18, 2026The NSF-DOE Vera C. Rubin Observatory, Roman Space Telescope, Euclid, and other next-generation surveys will deliver imaging, spectroscopic, and time-domain data at scales that increasingly shift the bottleneck in astronomical machine learning (ML) projects from model design to infrastructure. We present Hyrax, an open-source, modular, GPU-enabled Python framework that supports the full ML lifecycle in astronomy: from data acquisition and training to inference and experiment comparison, with capabilities including multimodal dataset support, integrated vector databases for similarity search, and interactive two- and three-dimensional latent-space exploration for unsupervised discovery. We demonstrate Hyrax's versatility through five representative applications on real survey data: (i) unsupervised representation learning on $\sim 4\times10^5$ Rubin Legacy Survey of Space and Time (LSST) Data Preview 1 (DP1) galaxies, surfacing new merger and low-surface-brightness candidates missing from reference Euclid and Dark Energy Survey catalogs, while also isolating imaging artifacts -- all without labeled training data; (ii) hybrid density-based clustering for identifying cluster-scale gravitational lens candidates in DP1 data; (iii) multimodal early-time transient classification in the Zwicky Transient Facility leveraging light curves, spectra, images, and metadata; (iv) supervised false-positive filtering in shift-and-stack searches for distant solar system objects in the Dark Energy Camera Ecliptic Exploration Project survey; and (v) supervised detection of semi-resolved dwarf galaxies in Hyper Suprime-Cam and LSST-like imaging using synthetic source injection. Together, these results demonstrate that Hyrax provides astronomy-specific ML infrastructure that enables systematic discovery and rapid methodological iteration across next-generation astronomical surveys.
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020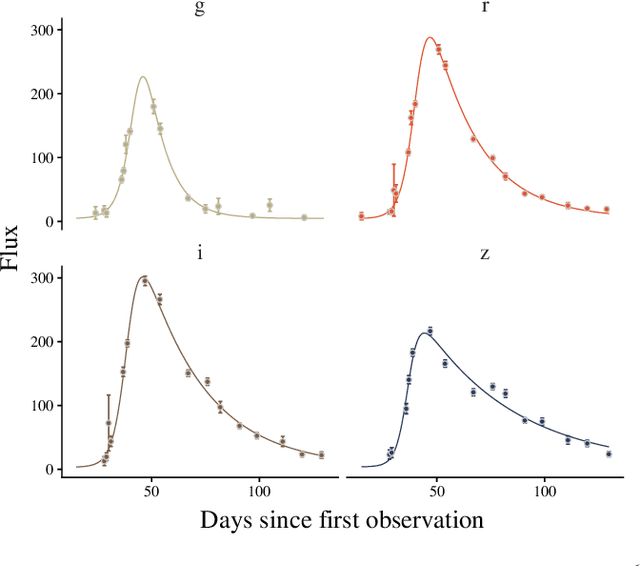
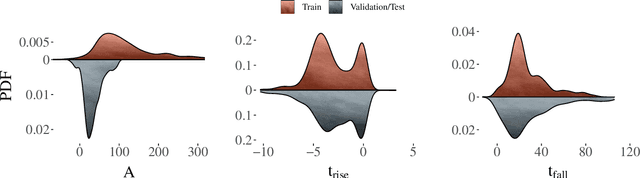
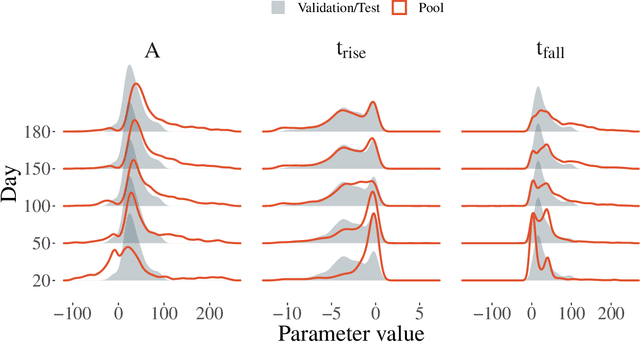
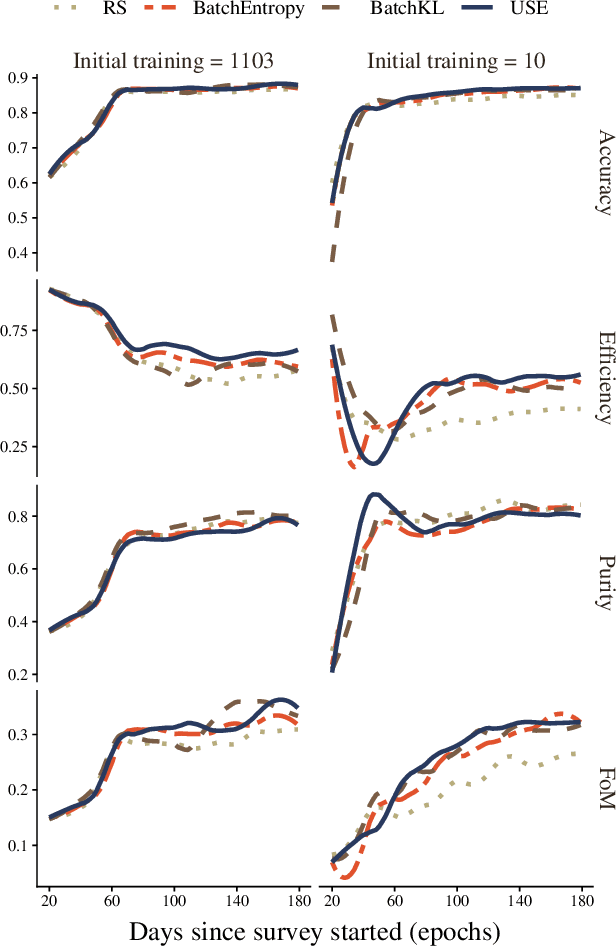
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.