 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020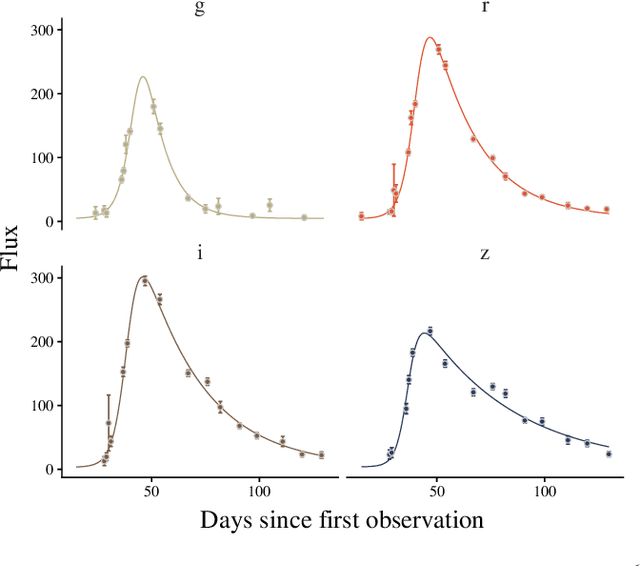
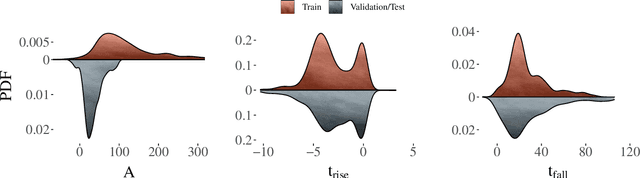
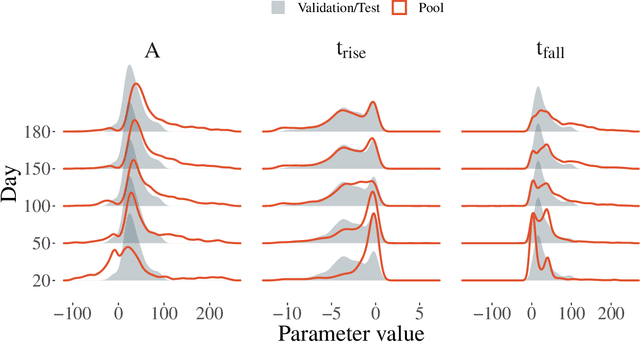
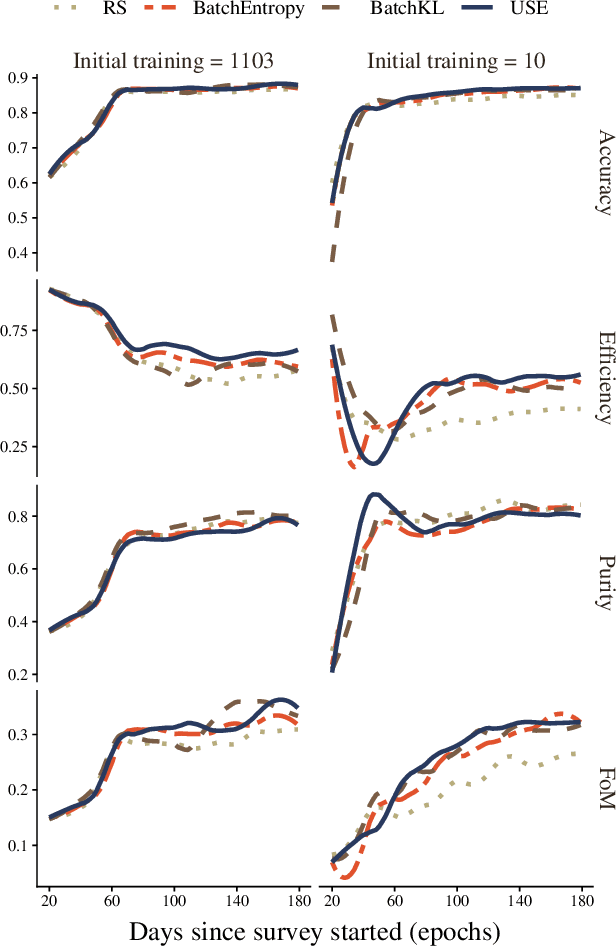
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.
Conditional Density Estimation Tools in Python and R with Applications to Photometric Redshifts and Likelihood-Free Cosmological Inference
Aug 30, 2019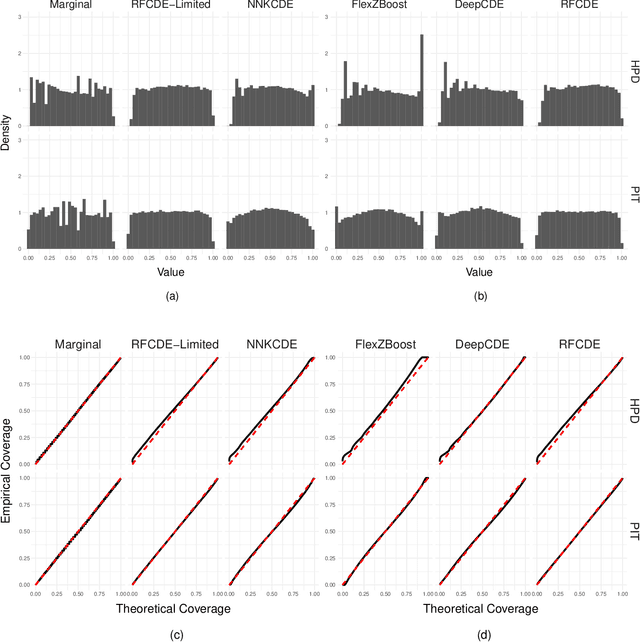
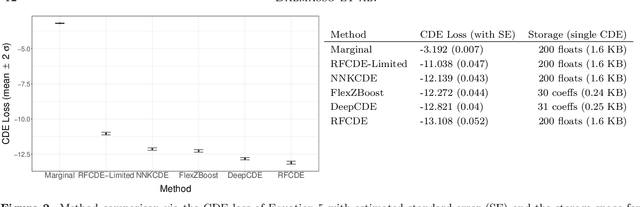
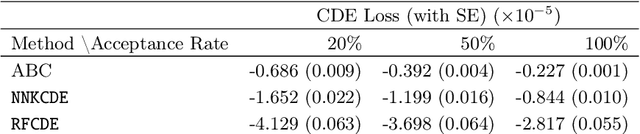
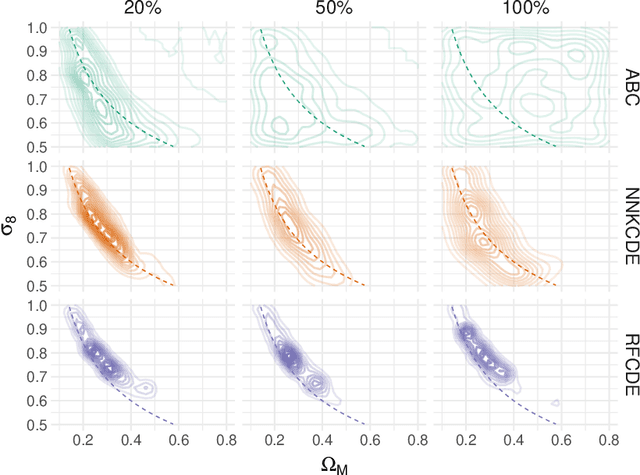
It is well known in astronomy that propagating non-Gaussian prediction uncertainty in photometric redshift estimates is key to reducing bias in downstream cosmological analyses. Similarly, likelihood-free inference approaches, which are beginning to emerge as a tool for cosmological analysis, require the full uncertainty landscape of the parameters of interest given observed data. However, most machine learning (ML) based methods with open-source software target point prediction or classification, and hence fall short in quantifying uncertainty in complex regression and parameter inference settings such as the applications mentioned above. As an alternative to methods that focus on predicting the response (or parameters) $\mathbf{y}$ from features $\mathbf{x}$, we provide nonparametric conditional density estimation (CDE) tools for approximating and validating the entire probability density $\mathrm{p}(\mathbf{y} \mid \mathbf{x})$ given training data for $\mathbf{x}$ and $\mathbf{y}$. As there is no one-size-fits-all CDE method, the goal of this work is to provide a comprehensive range of statistical tools and open-source software for nonparametric CDE and method assessment which can accommodate different types of settings and which in addition can easily be fit to the problem at hand. Specifically, we introduce CDE software packages in $\texttt{Python}$ and $\texttt{R}$ based on four ML prediction methods adapted and optimized for CDE: $\texttt{NNKCDE}$, $\texttt{RFCDE}$, $\texttt{FlexCode}$, and $\texttt{DeepCDE}$. Furthermore, we present the $\texttt{cdetools}$ package, which includes functions for computing a CDE loss function for model selection and tuning of parameters, together with diagnostics functions. We provide sample code in $\texttt{Python}$ and $\texttt{R}$ as well as examples of applications to photometric redshift estimation and likelihood-free cosmology via CDE.