 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low Complexity Sequential Search with Measurement Dependent Noise
May 15, 2020
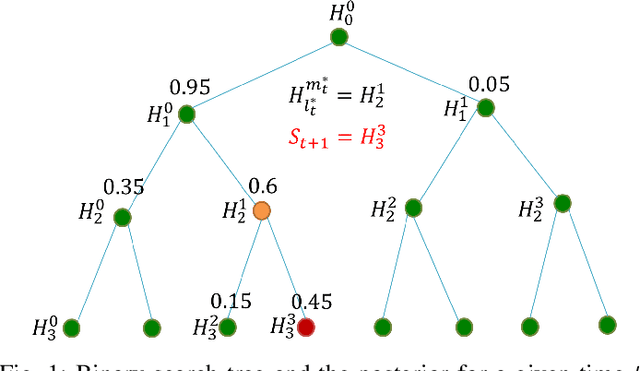
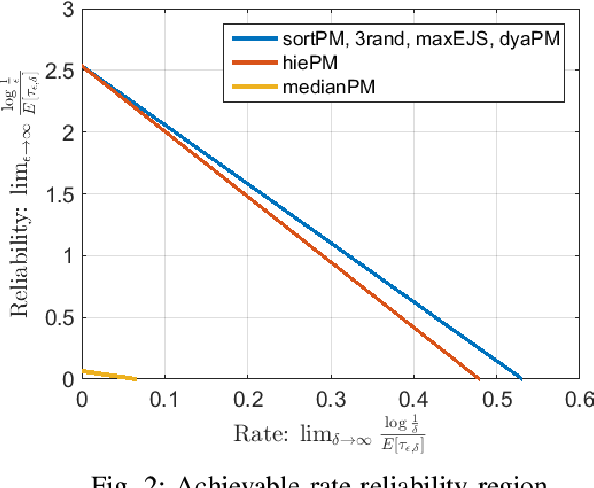
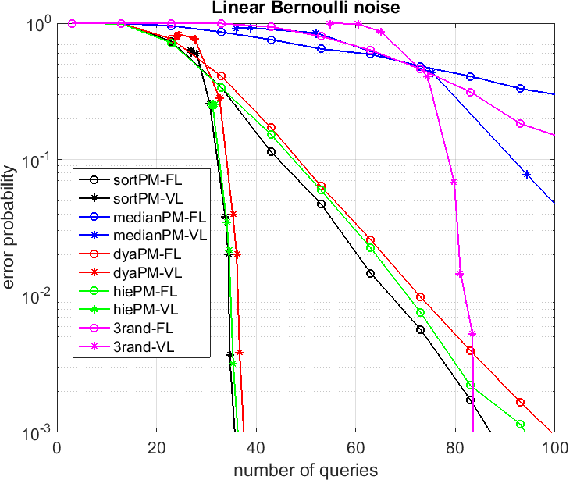
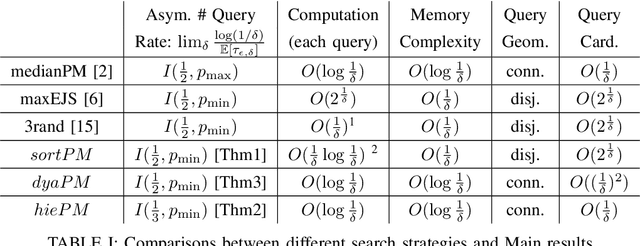
This paper considers a target localization problem where at any given time an agent can choose a region to query for the presence of the target in that region. The measurement noise is assumed to be increasing with the size of the query region the agent chooses. Motivated by practical applications such as initial beam alignment in array processing, heavy hitter detection in networking, and visual search in robotics, we consider practically important complexity constraints/metrics: \textit{time complexity}, \textit{computational and memory complexity}, \textit{query geometry}, and \textit{cardinality of possible query sets}. Two novel search strategy, $dyaPM$ and $hiePM$, are proposed. In contrast to previously proposed algorithms, $dyaPM$ and $hiePM$ are of a connected query geometry (i.e. query set is always a connected set). We also demonstrated how they can be implemented with low computational and memory complexity. Additionally, $hiePM$ has a hierarchical structure and has a low cardinality of possible query sets. These make $hiePM$ suitable for applications such as beamforming in array processing where the extra computation of the query set construction dictates a codebook-based approach (the choice of query set is constrained to a pre-computed small query set collection), and the limit of memory enforces a smaller codebook size. Through a unified analysis with Extrinsic Jensen Shannon (EJS) Divergence, $dyaPM$ is shown to be asymptotically optimal in search time complexity (asymptotic in both resolution (rate) and error (reliability)). On the other hand, $hiePM$ is shown to be near-optimal in rate. In addition, via numerical examples, both $hiePM$ and $dyaPM$ are shown to outperform prior work in the non-asymptotic regime.
Bunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems
Aug 11, 2020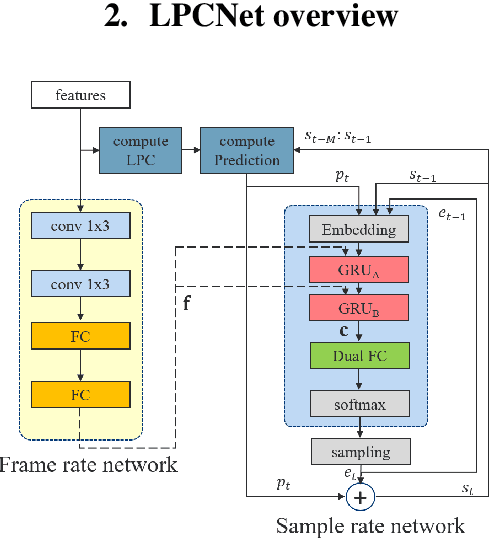
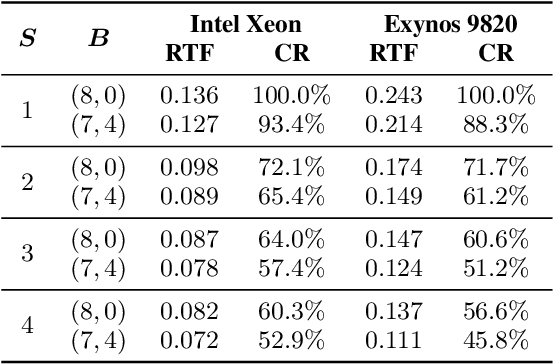
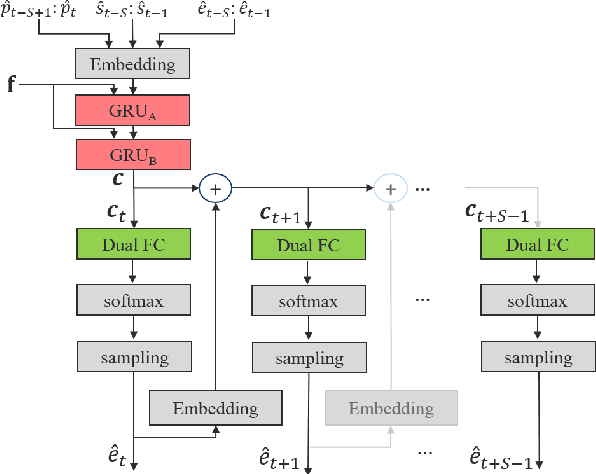
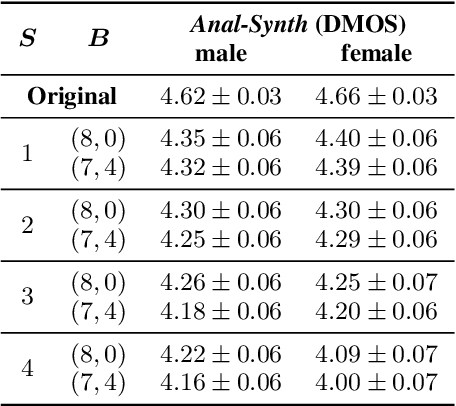
LPCNet is an efficient vocoder that combines linear prediction and deep neural network modules to keep the computational complexity low. In this work, we present two techniques to further reduce it's complexity, aiming for a low-cost LPCNet vocoder-based neural Text-to-Speech (TTS) System. These techniques are: 1) Sample-bunching, which allows LPCNet to generate more than one audio sample per inference; and 2) Bit-bunching, which reduces the computations in the final layer of LPCNet. With the proposed bunching techniques, LPCNet, in conjunction with a Deep Convolutional TTS (DCTTS) acoustic model, shows a 2.19x improvement over the baseline run-time when running on a mobile device, with a less than 0.1 decrease in TTS mean opinion score (MOS).
Detecting Autism Spectrum Disorder using Machine Learning
Sep 30, 2020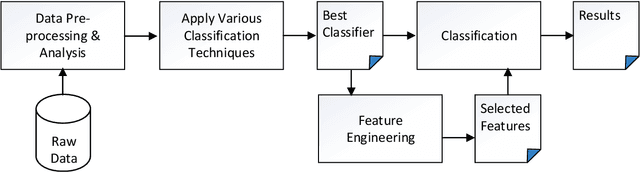
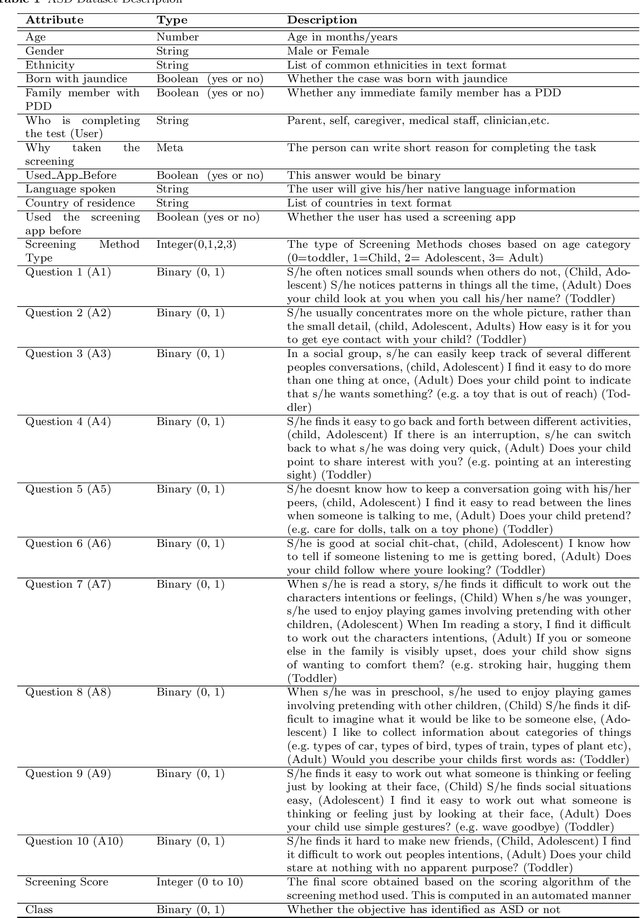
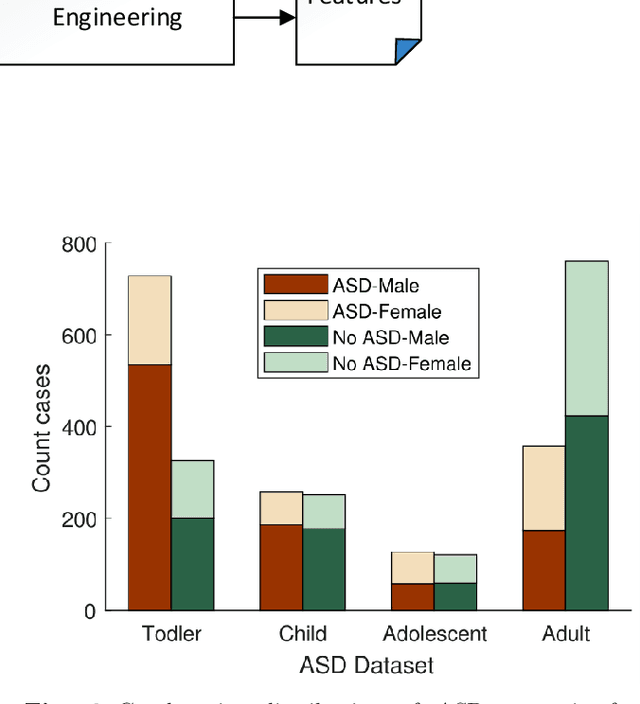
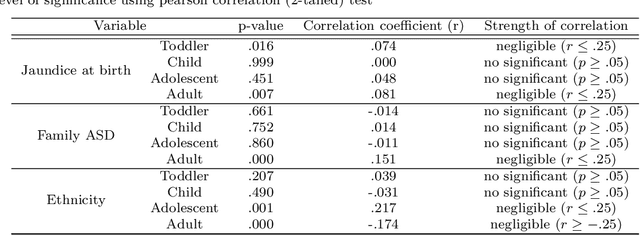
Autism Spectrum Disorder (ASD), which is a neuro development disorder, is often accompanied by sensory issues such an over sensitivity or under sensitivity to sounds and smells or touch. Although its main cause is genetics in nature, early detection and treatment can help to improve the conditions. In recent years, machine learning based intelligent diagnosis has been evolved to complement the traditional clinical methods which can be time consuming and expensive. The focus of this paper is to find out the most significant traits and automate the diagnosis process using available classification techniques for improved diagnosis purpose. We have analyzed ASD datasets of Toddler, Child, Adolescent and Adult. We determine the best performing classifier for these binary datasets using the evaluation metrics recall, precision, F-measures and classification errors. Our finding shows that Sequential minimal optimization (SMO) based Support Vector Machines (SVM) classifier outperforms all other benchmark machine learning algorithms in terms of accuracy during the detection of ASD cases and produces less classification errors compared to other algorithms. Also, we find that Relief Attributes algorithm is the best to identify the most significant attributes in ASD datasets.
Hierarchical HMM for Eye Movement Classification
Aug 18, 2020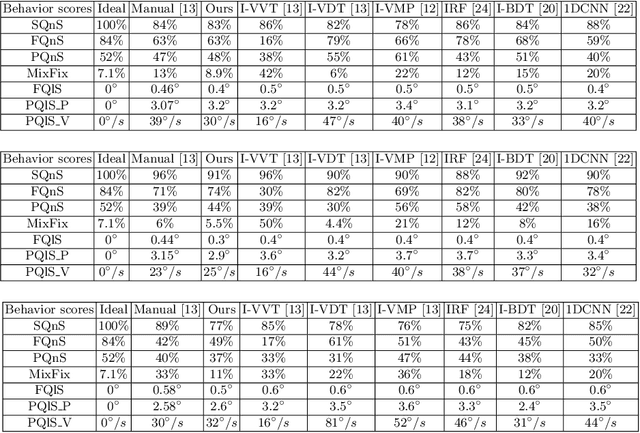
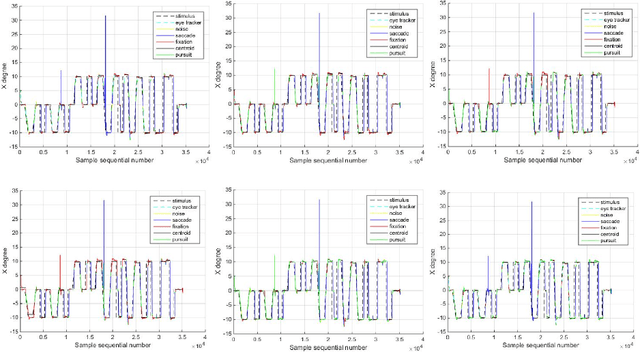
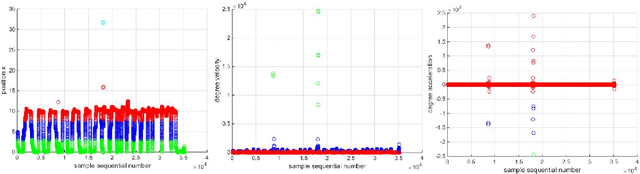
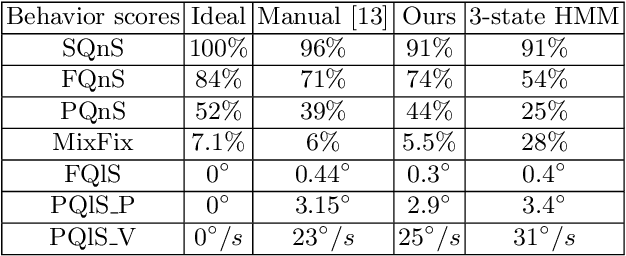
In this work, we tackle the problem of ternary eye movement classification, which aims to separate fixations, saccades and smooth pursuits from the raw eye positional data. The efficient classification of these different types of eye movements helps to better analyze and utilize the eye tracking data. Different from the existing methods that detect eye movement by several pre-defined threshold values, we propose a hierarchical Hidden Markov Model (HMM) statistical algorithm for detecting fixations, saccades and smooth pursuits. The proposed algorithm leverages different features from the recorded raw eye tracking data with a hierarchical classification strategy, separating one type of eye movement each time. Experimental results demonstrate the effectiveness and robustness of the proposed method by achieving competitive or better performance compared to the state-of-the-art methods.
VisCode: Embedding Information in Visualization Images using Encoder-Decoder Network
Sep 07, 2020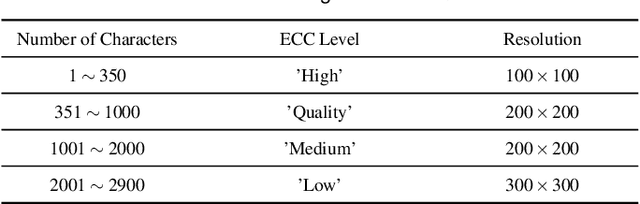
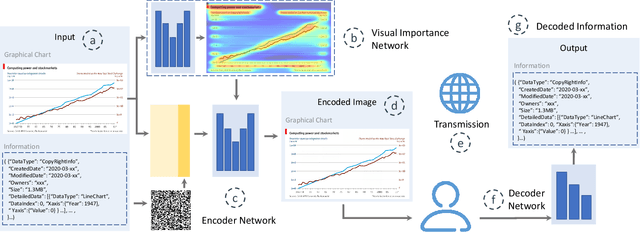
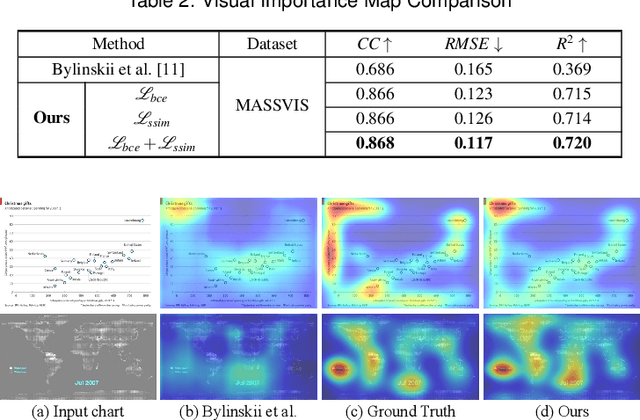
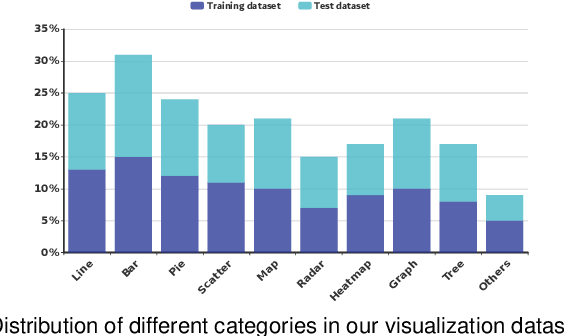
We present an approach called VisCode for embedding information into visualization images. This technology can implicitly embed data information specified by the user into a visualization while ensuring that the encoded visualization image is not distorted. The VisCode framework is based on a deep neural network. We propose to use visualization images and QR codes data as training data and design a robust deep encoder-decoder network. The designed model considers the salient features of visualization images to reduce the explicit visual loss caused by encoding. To further support large-scale encoding and decoding, we consider the characteristics of information visualization and propose a saliency-based QR code layout algorithm. We present a variety of practical applications of VisCode in the context of information visualization and conduct a comprehensive evaluation of the perceptual quality of encoding, decoding success rate, anti-attack capability, time performance, etc. The evaluation results demonstrate the effectiveness of VisCode.
Ask-n-Learn: Active Learning via Reliable Gradient Representations for Image Classification
Sep 30, 2020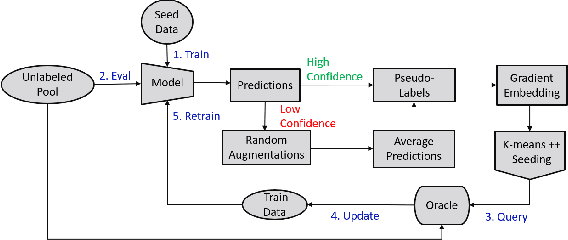
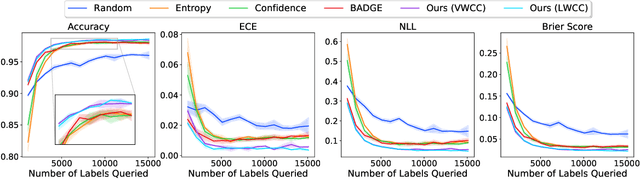
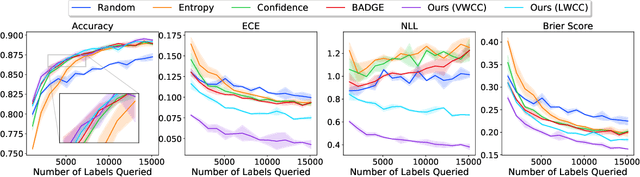
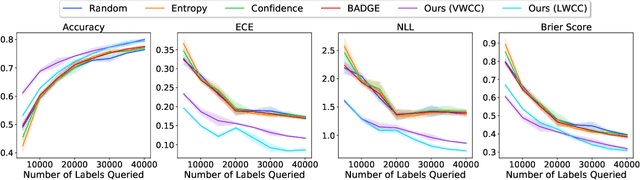
Deep predictive models rely on human supervision in the form of labeled training data. Obtaining large amounts of annotated training data can be expensive and time consuming, and this becomes a critical bottleneck while building such models in practice. In such scenarios, active learning (AL) strategies are used to achieve faster convergence in terms of labeling efforts. Existing active learning employ a variety of heuristics based on uncertainty and diversity to select query samples. Despite their wide-spread use, in practice, their performance is limited by a number of factors including non-calibrated uncertainties, insufficient trade-off between data exploration and exploitation, presence of confirmation bias etc. In order to address these challenges, we propose Ask-n-Learn, an active learning approach based on gradient embeddings obtained using the pesudo-labels estimated in each iteration of the algorithm. More importantly, we advocate the use of prediction calibration to obtain reliable gradient embeddings, and propose a data augmentation strategy to alleviate the effects of confirmation bias during pseudo-labeling. Through empirical studies on benchmark image classification tasks (CIFAR-10, SVHN, Fashion-MNIST, MNIST), we demonstrate significant improvements over state-of-the-art baselines, including the recently proposed BADGE algorithm.
Enhanced detection of fetal pose in 3D MRI by Deep Reinforcement Learning with physical structure priors on anatomy
Jul 16, 2020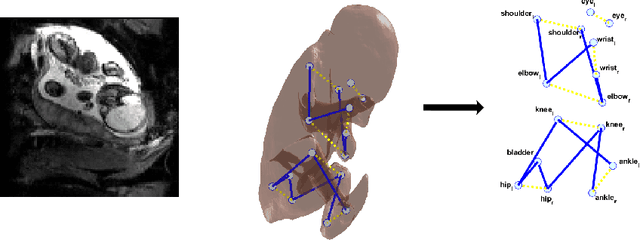
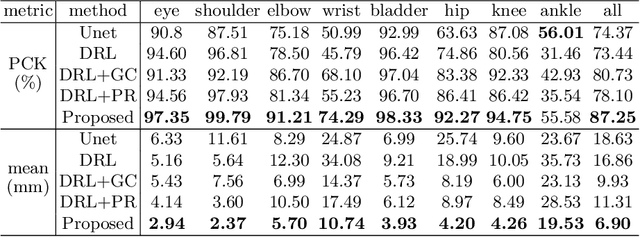
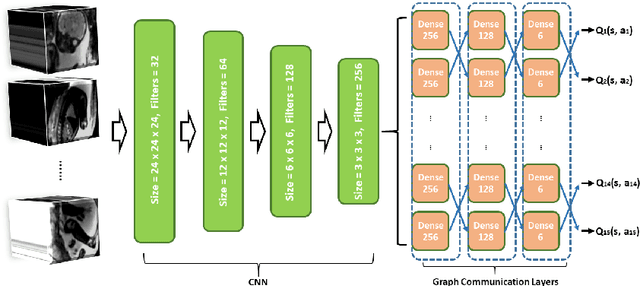
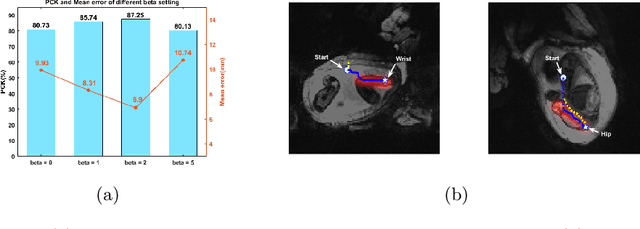
Fetal MRI is heavily constrained by unpredictable and substantial fetal motion that causes image artifacts and limits the set of viable diagnostic image contrasts. Current mitigation of motion artifacts is predominantly performed by fast, single-shot MRI and retrospective motion correction. Estimation of fetal pose in real time during MRI stands to benefit prospective methods to detect and mitigate fetal motion artifacts where inferred fetal motion is combined with online slice prescription with low-latency decision making. Current developments of deep reinforcement learning (DRL), offer a novel approach for fetal landmarks detection. In this task 15 agents are deployed to detect 15 landmarks simultaneously by DRL. The optimization is challenging, and here we propose an improved DRL that incorporates priors on physical structure of the fetal body. First, we use graph communication layers to improve the communication among agents based on a graph where each node represents a fetal-body landmark. Further, additional reward based on the distance between agents and physical structures such as the fetal limbs is used to fully exploit physical structure. Evaluation of this method on a repository of 3-mm resolution in vivo data demonstrates a mean accuracy of landmark estimation within 10 mm of ground truth as 87.3%, and a mean error of 6.9 mm. The proposed DRL for fetal pose landmark search demonstrates a potential clinical utility for online detection of fetal motion that guides real-time mitigation of motion artifacts as well as health diagnosis during MRI of the pregnant mother.
Online Convex Optimization in Changing Environments and its Application to Resource Allocation
Sep 30, 2020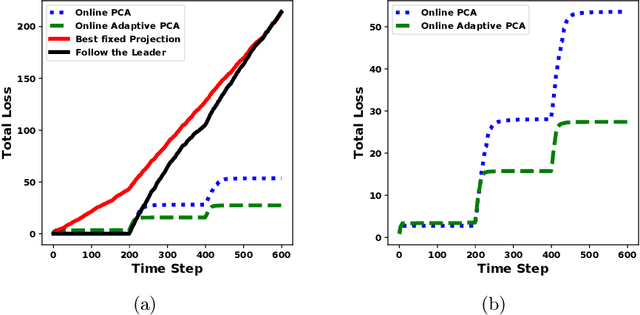
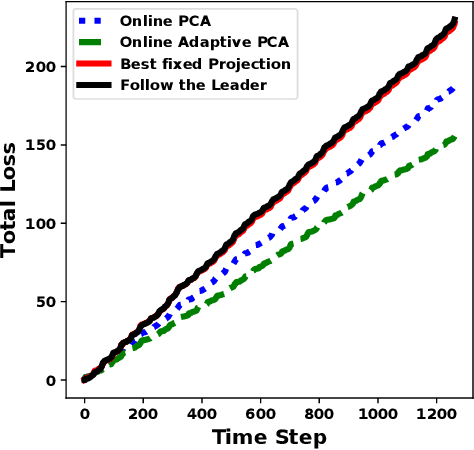
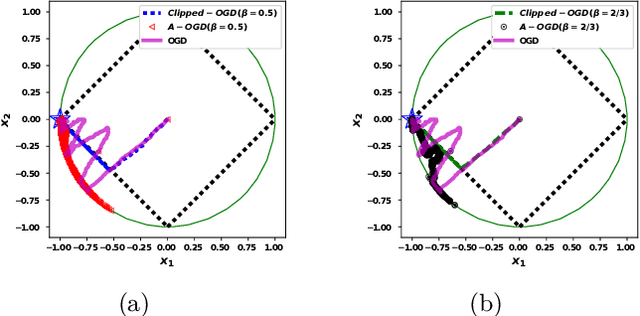
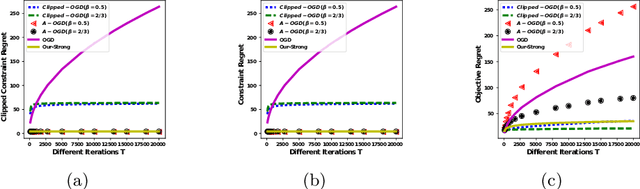
In the era of the big data, we create and collect lots of data from all different kinds of sources: the Internet, the sensors, the consumer market, and so on. Many of the data are coming sequentially, and would like to be processed and understood quickly. One classic way of analyzing data is based on batch processing, in which the data is stored and analyzed in an offline fashion. However, when the volume of the data is too large, it is much more difficult and time-consuming to do batch processing than sequential processing. What's more, sequential data is usually changing dynamically, and needs to be understood on-the-fly in order to capture the changes. Online Convex Optimization (OCO) is a popular framework that matches the above sequential data processing requirement. Applications using OCO include online routing, online auctions, online classification and regression, as well as online resource allocation. Due to the general applicability of OCO to the sequential data and the rigorous theoretical guarantee, it has attracted lots of researchers to develop useful algorithms to fulfill different needs. In this thesis, we show our contributions to OCO's development by designing algorithms to adapt to changing environments.
Multi-Modal Trajectory Prediction of NBA Players
Aug 18, 2020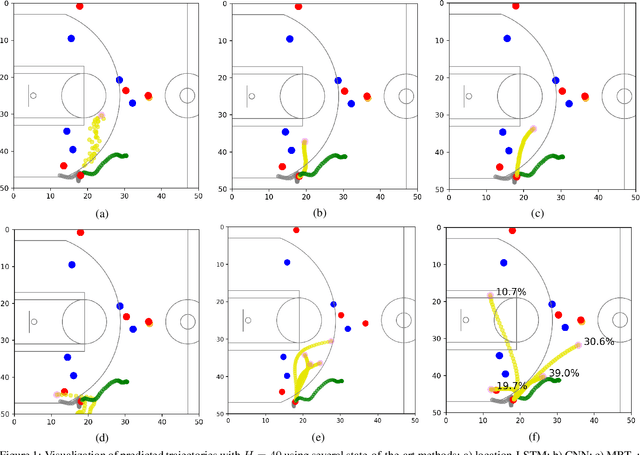
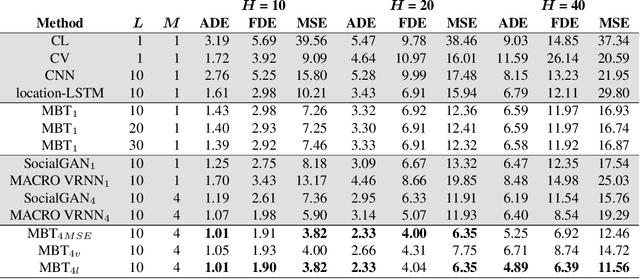
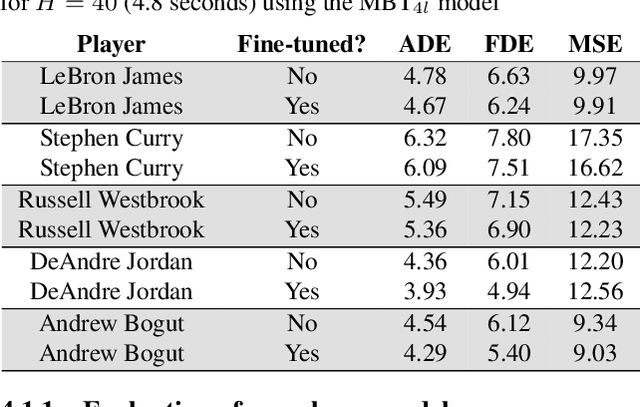
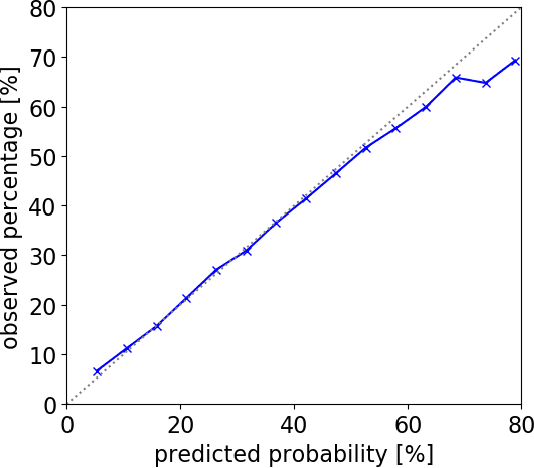
National Basketball Association (NBA) players are highly motivated and skilled experts that solve complex decision making problems at every time point during a game. As a step towards understanding how players make their decisions, we focus on their movement trajectories during games. We propose a method that captures the multi-modal behavior of players, where they might consider multiple trajectories and select the most advantageous one. The method is built on an LSTM-based architecture predicting multiple trajectories and their probabilities, trained by a multi-modal loss function that updates the best trajectories. Experiments on large, fine-grained NBA tracking data show that the proposed method outperforms the state-of-the-art. In addition, the results indicate that the approach generates more realistic trajectories and that it can learn individual playing styles of specific players.
Stochastic-YOLO: Efficient Probabilistic Object Detection under Dataset Shifts
Sep 07, 2020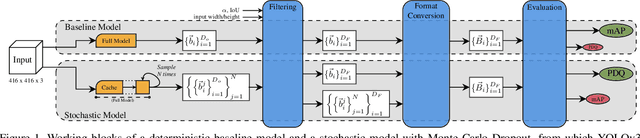
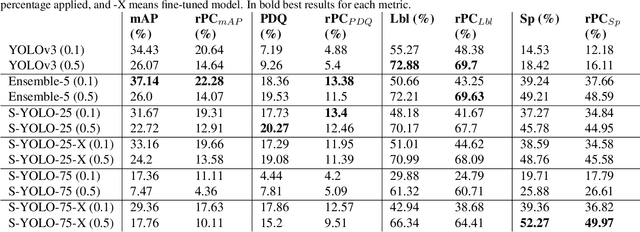
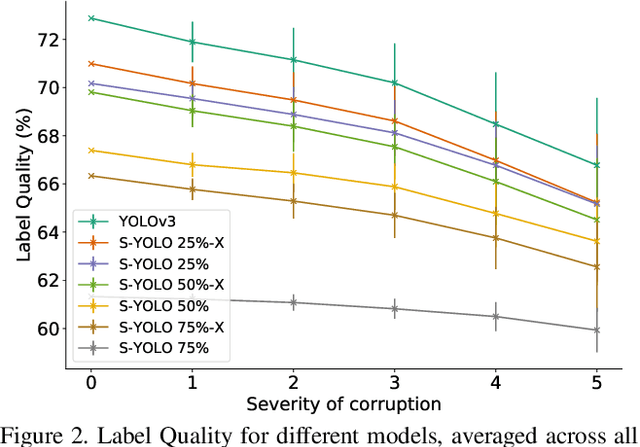
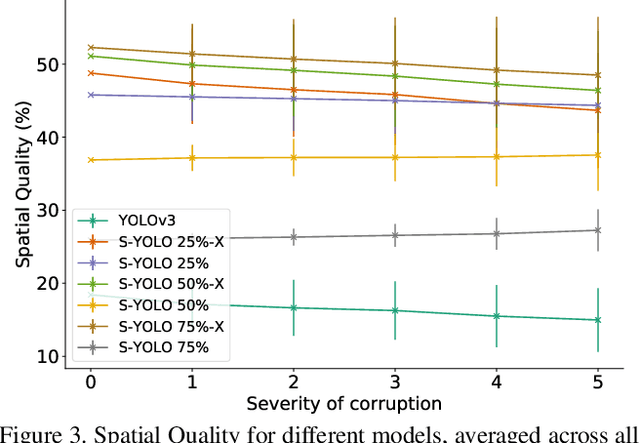
In image classification tasks, the evaluation of models' robustness to increased dataset shifts with a probabilistic framework is very well studied. However, Object Detection (OD) tasks pose other challenges for uncertainty estimation and evaluation. For example, one needs to evaluate both the quality of the label uncertainty (i.e., what?) and spatial uncertainty (i.e., where?) for a given bounding box, but that evaluation cannot be performed with more traditional average precision metrics (e.g., mAP). In this paper, we adapt the well-established YOLOv3 architecture to generate uncertainty estimations by introducing stochasticity in the form of Monte Carlo Dropout (MC-Drop), and evaluate it across different levels of dataset shift. We call this novel architecture Stochastic-YOLO, and provide an efficient implementation to effectively reduce the burden of the MC-Drop sampling mechanism at inference time. Finally, we provide some sensitivity analyses, while arguing that Stochastic-YOLO is a sound approach that improves different components of uncertainty estimations, in particular spatial uncertainties.