 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analysis of COVID-19 cases in India through Machine Learning: A Study of Intervention
Aug 17, 2020
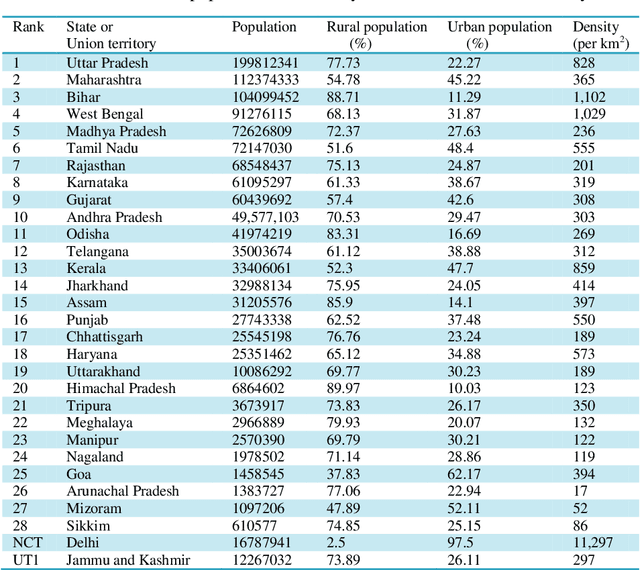
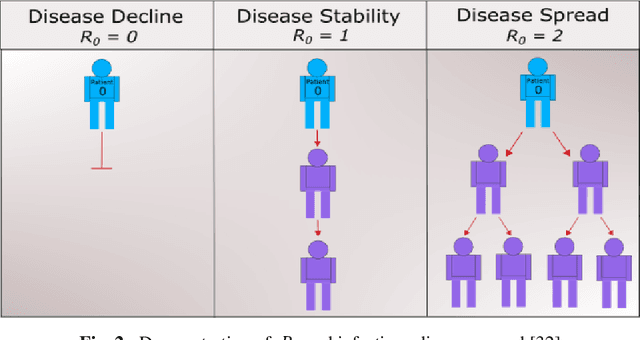
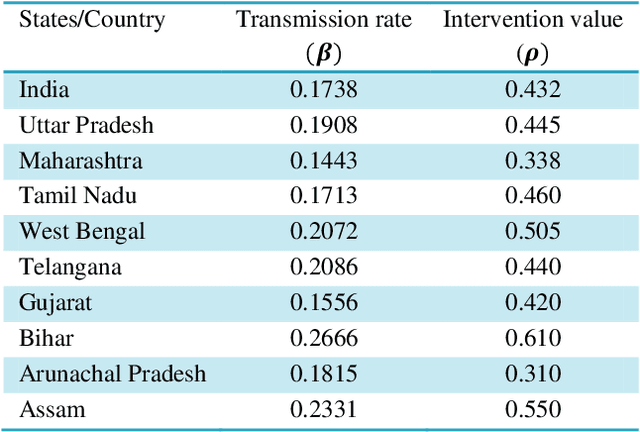
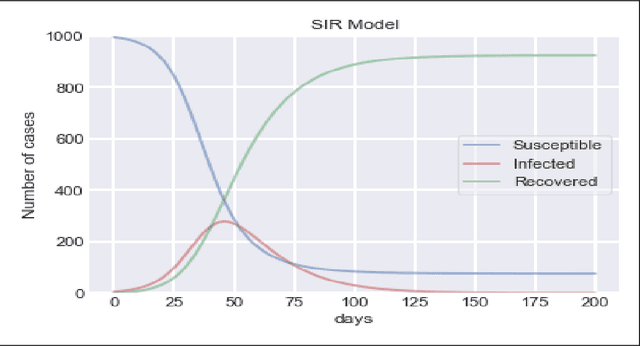
To combat the coronavirus disease 2019 (COVID-19) pandemic, the world has vaccination, plasma therapy, herd immunity, and epidemiological interventions as few possible options. The COVID-19 vaccine development is underway and it may take a significant amount of time to develop the vaccine and after development, it will take time to vaccinate the entire population, and plasma therapy has some limitations. Herd immunity can be a plausible option to fight COVID-19 for small countries. But for a country with huge population like India, herd immunity is not a plausible option, because to acquire herd immunity approximately 67% of the population has to be recovered from COVID-19 infection, which will put an extra burden on medical system of the country and will result in a huge loss of human life. Thus epidemiological interventions (complete lockdown, partial lockdown, quarantine, isolation, social distancing, etc.) are some suitable strategies in India to slow down the COVID-19 spread until the vaccine development. In this work, we have suggested the SIR model with intervention, which incorporates the epidemiological interventions in the classical SIR model. To model the effect of the interventions, we have introduced \r{ho} as the intervention parameter. \r{ho} is a cumulative quantity which covers all type of intervention. We have also discussed the supervised machine learning approach to estimate the transmission rate (\b{eta}) for the SIR model with intervention from the prevalence of COVID-19 data in India and some states of India. To validate our model, we present a comparison between the actual and model-predicted number of COVID-19 cases. Using our model, we also present predicted numbers of active and recovered COVID-19 cases till Sept 30, 2020, for entire India and some states of India and also estimate the 95% and 99% confidence interval for the predicted cases.
Personality Trait Detection Using Bagged SVM over BERT Word Embedding Ensembles
Oct 03, 2020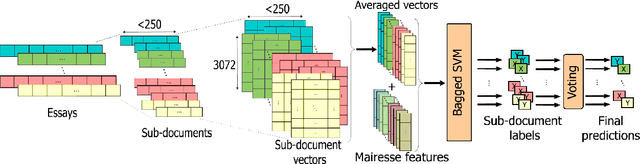
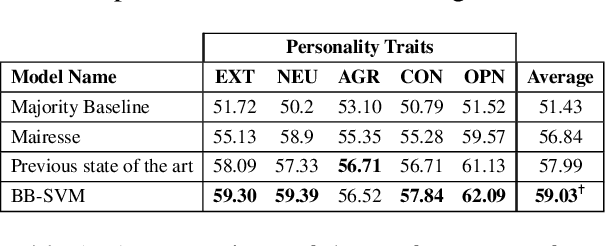
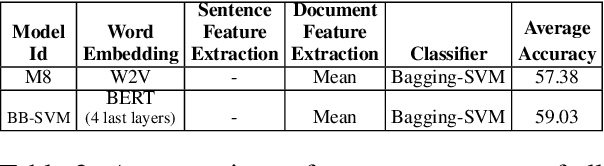
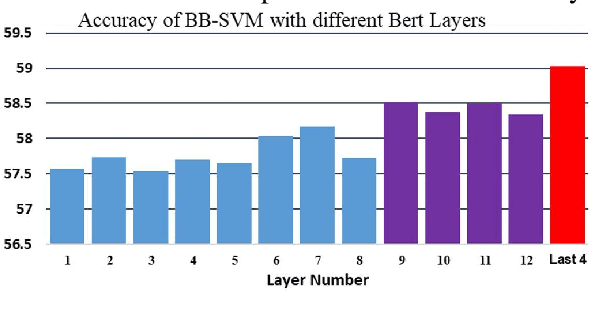
Recently, the automatic prediction of personality traits has received increasing attention and has emerged as a hot topic within the field of affective computing. In this work, we present a novel deep learning-based approach for automated personality detection from text. We leverage state of the art advances in natural language understanding, namely the BERT language model to extract contextualized word embeddings from textual data for automated author personality detection. Our primary goal is to develop a computationally efficient, high-performance personality prediction model which can be easily used by a large number of people without access to huge computation resources. Our extensive experiments with this ideology in mind, led us to develop a novel model which feeds contextualized embeddings along with psycholinguistic features toa Bagged-SVM classifier for personality trait prediction. Our model outperforms the previous state of the art by 1.04% and, at the same time is significantly more computationally efficient to train. We report our results on the famous gold standard Essays dataset for personality detection.
Identification of state functions by physically-guided neural networks with physically-meaningful internal layers
Nov 17, 2020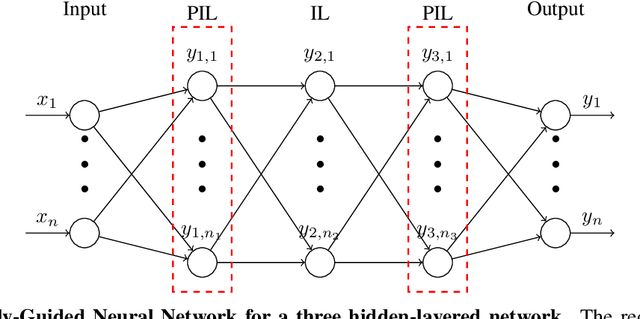

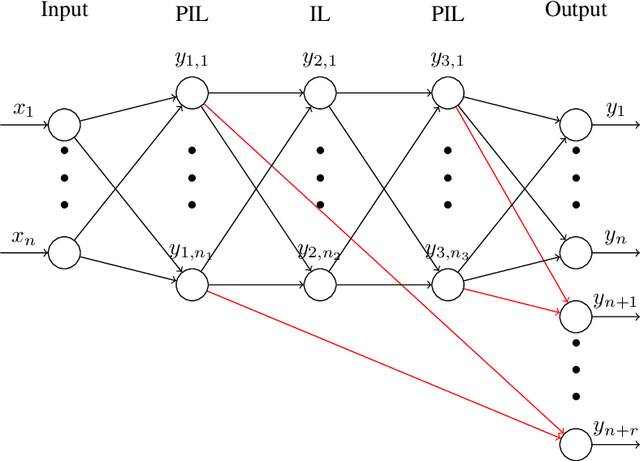

Substitution of well-grounded theoretical models by data-driven predictions is not as simple in engineering and sciences as it is in social and economic fields. Scientific problems suffer most times from paucity of data, while they may involve a large number of variables and parameters that interact in complex and non-stationary ways, obeying certain physical laws. Moreover, a physically-based model is not only useful for making predictions, but to gain knowledge by the interpretation of its structure, parameters, and mathematical properties. The solution to these shortcomings seems to be the seamless blending of the tremendous predictive power of the data-driven approach with the scientific consistency and interpretability of physically-based models. We use here the concept of physically-constrained neural networks (PCNN) to predict the input-output relation in a physical system, while, at the same time fulfilling the physical constraints. With this goal, the internal hidden state variables of the system are associated with a set of internal neuron layers, whose values are constrained by known physical relations, as well as any additional knowledge on the system. Furthermore, when having enough data, it is possible to infer knowledge about the internal structure of the system and, if parameterized, to predict the state parameters for a particular input-output relation. We show that this approach, besides getting physically-based predictions, accelerates the training process, reduces the amount of data required to get similar accuracy, filters partly the intrinsic noise in the experimental data and provides improved extrapolation capacity.
Making Sense of the Robotized Pandemic Response: A Comparison of Global and Canadian Robot Deployments and Success Factors
Sep 21, 2020
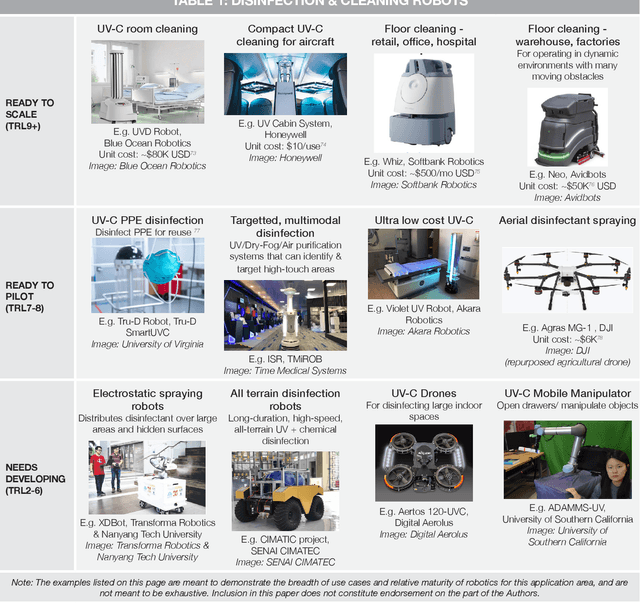
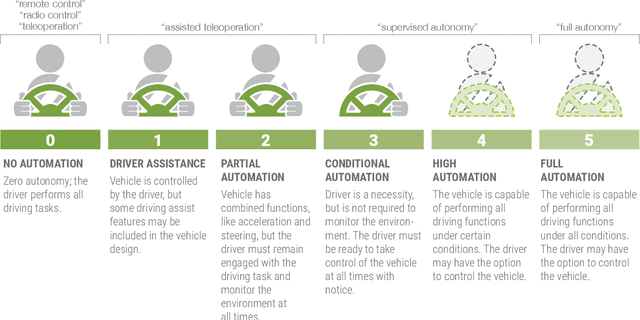
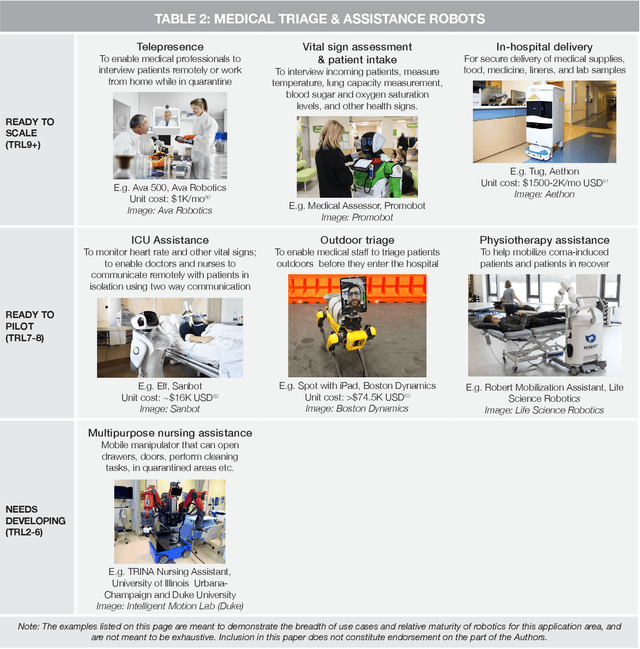
From disinfection and remote triage, to logistics and delivery, countries around the world are making use of robots to address the unique challenges presented by the COVID-19 pandemic. Robots are being used to manage the pandemic in Canada too, but relative to other regions, we have been more cautious in our adoption -- this despite the important role that robots of Canadian origin are now playing on the global stage. This white paper discusses why this is the case, and argues that strategic investment and support for the Canadian robotics industry are urgently needed to bring the benefits of robotics home, where we have more control in shaping the future of this game-changing technology. Such investments will not only serve to support Canada's current pandemic response and post pandemic recovery, but will also prepare this country to weather future crises. Without such support, Canada risks falling behind other developed nations that are investing heavily in hardware automation at this time.
Haar Wavelet based Block Autoregressive Flows for Trajectories
Sep 21, 2020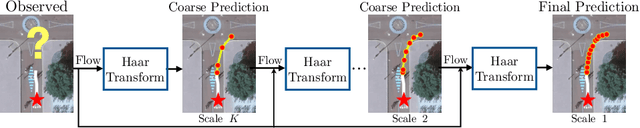
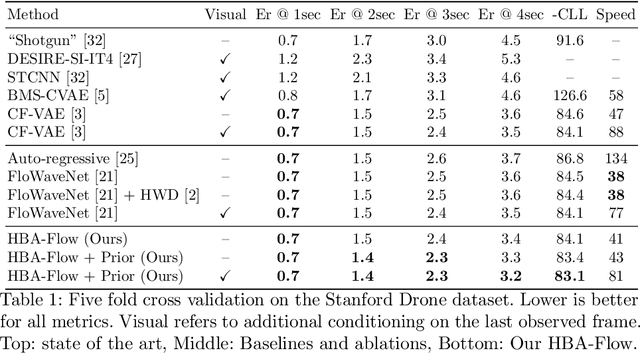
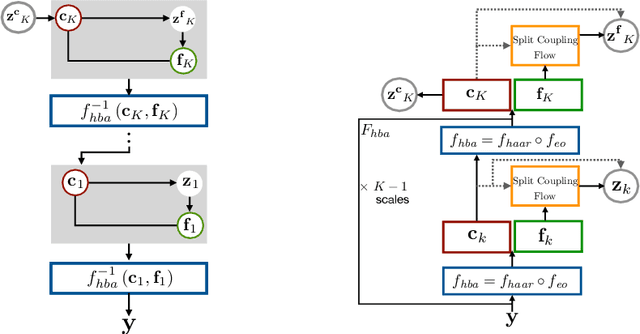
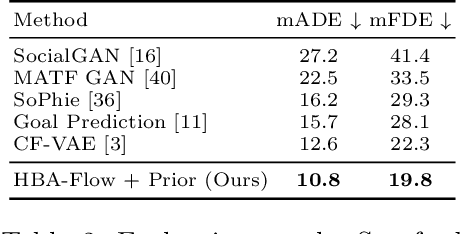
Prediction of trajectories such as that of pedestrians is crucial to the performance of autonomous agents. While previous works have leveraged conditional generative models like GANs and VAEs for learning the likely future trajectories, accurately modeling the dependency structure of these multimodal distributions, particularly over long time horizons remains challenging. Normalizing flow based generative models can model complex distributions admitting exact inference. These include variants with split coupling invertible transformations that are easier to parallelize compared to their autoregressive counterparts. To this end, we introduce a novel Haar wavelet based block autoregressive model leveraging split couplings, conditioned on coarse trajectories obtained from Haar wavelet based transformations at different levels of granularity. This yields an exact inference method that models trajectories at different spatio-temporal resolutions in a hierarchical manner. We illustrate the advantages of our approach for generating diverse and accurate trajectories on two real-world datasets - Stanford Drone and Intersection Drone.
Real-Time Visual Tracking: Promoting the Robustness of Correlation Filter Learning
Sep 09, 2016
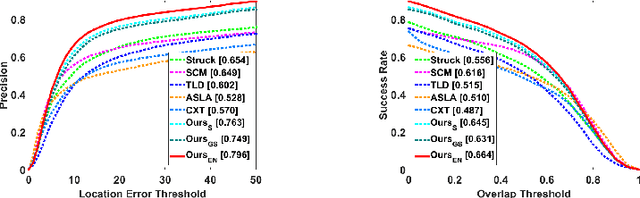
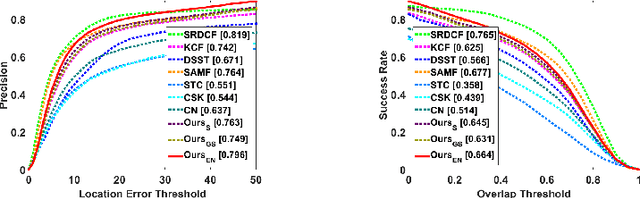
Correlation filtering based tracking model has received lots of attention and achieved great success in real-time tracking, however, the lost function in current correlation filtering paradigm could not reliably response to the appearance changes caused by occlusion and illumination variations. This study intends to promote the robustness of the correlation filter learning. By exploiting the anisotropy of the filter response, three sparsity related loss functions are proposed to alleviate the overfitting issue of previous methods and improve the overall tracking performance. As a result, three real-time trackers are implemented. Extensive experiments in various challenging situations demonstrate that the robustness of the learned correlation filter has been greatly improved via the designed loss functions. In addition, the study reveals, from an experimental perspective, how different loss functions essentially influence the tracking performance. An important conclusion is that the sensitivity of the peak values of the filter in successive frames is consistent with the tracking performance. This is a useful reference criterion in designing a robust correlation filter for visual tracking.
Ranky : An Approach to Solve Distributed SVD on Large Sparse Matrices
Sep 21, 2020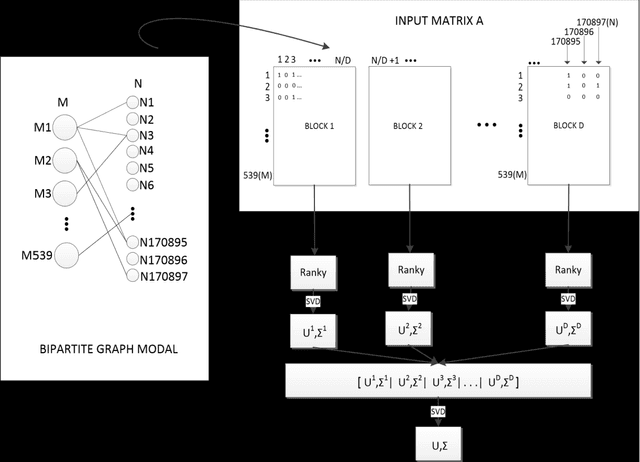
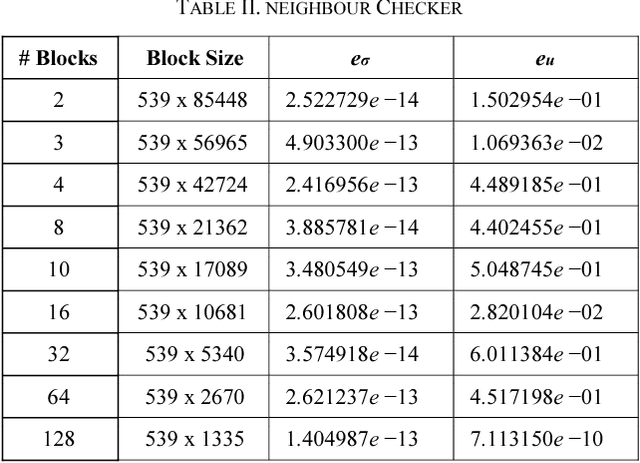
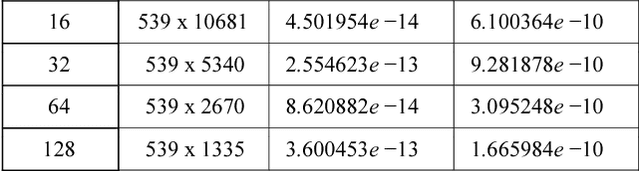
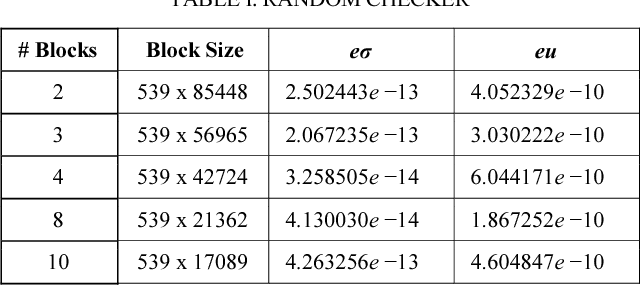
Singular Value Decomposition (SVD) is a well studied research topic in many fields and applications from data mining to image processing. Data arising from these applications can be represented as a matrix where it is large and sparse. Most existing algorithms are used to calculate singular values, left and right singular vectors of a large-dense matrix but not large and sparse matrix. Even if they can find SVD of a large matrix, calculation of large-dense matrix has high time complexity due to sequential algorithms. Distributed approaches are proposed for computing SVD of large matrices. However, rank of the matrix is still being a problem when solving SVD with these distributed algorithms. In this paper we propose Ranky, set of methods to solve rank problem on large and sparse matrices in a distributed manner. Experimental results show that the Ranky approach recovers singular values, singular left and right vectors of a given large and sparse matrix with negligible error.
On-The-Fly Information Retrieval Augmentation for Language Models
Jul 03, 2020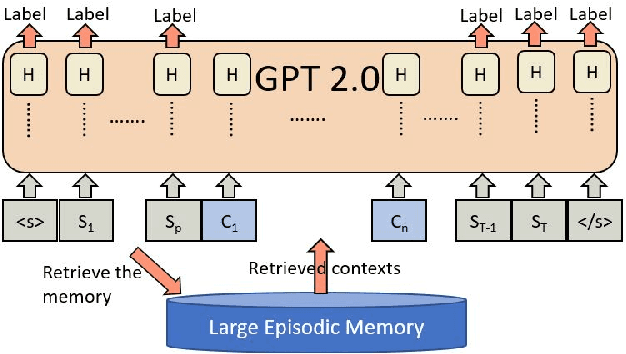

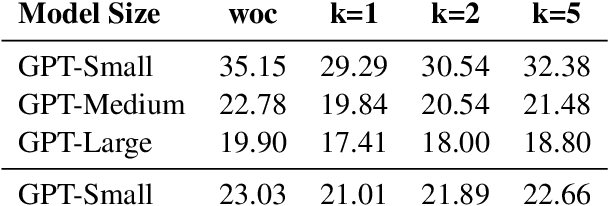
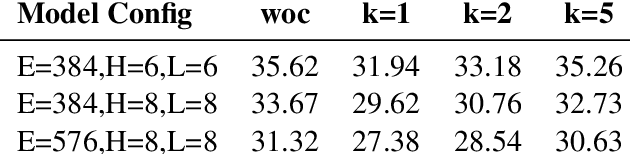
Here we experiment with the use of information retrieval as an augmentation for pre-trained language models. The text corpus used in information retrieval can be viewed as form of episodic memory which grows over time. By augmenting GPT 2.0 with information retrieval we achieve a zero shot 15% relative reduction in perplexity on Gigaword corpus without any re-training. We also validate our IR augmentation on an event co-reference task.
Hotel Recommendation System Based on User Profiles and Collaborative Filtering
Sep 21, 2020Nowadays, people start to use online reservation systems to plan their vacations since they have vast amount of choices available. Selecting when and where to go from this large-scale options is getting harder. In addition, sometimes consumers can miss the better options due to the wealth of information to be found on the online reservation systems. In this sense, personalized services such as recommender systems play a crucial role in decision making. Two traditional recommendation techniques are content-based and collaborative filtering. While both methods have their advantages, they also have certain disadvantages, some of which can be solved by combining both techniques to improve the quality of the recommendation. The resulting system is known as a hybrid recommender system. This paper presents a new hybrid hotel recommendation system that has been developed by combining content-based and collaborative filtering approaches that recommends customer the hotel they need and save them from time loss.
Read what you need: Controllable Aspect-based Opinion Summarization of Tourist Reviews
Jun 09, 2020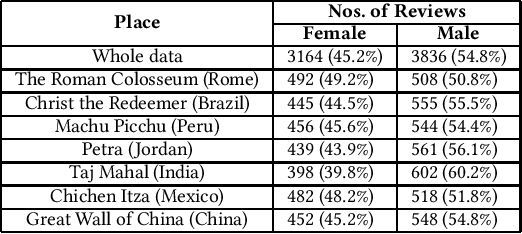
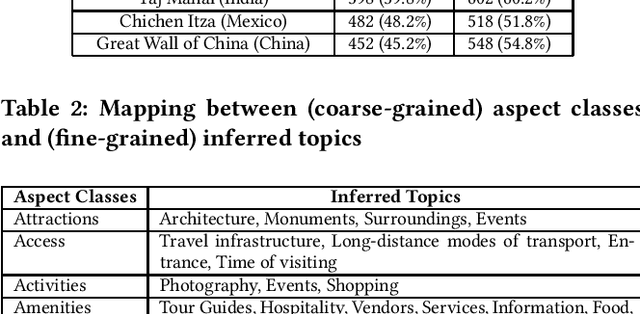
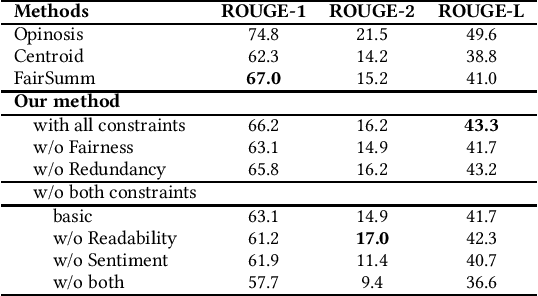
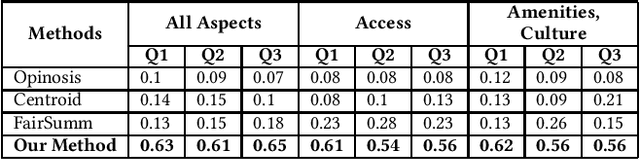
Manually extracting relevant aspects and opinions from large volumes of user-generated text is a time-consuming process. Summaries, on the other hand, help readers with limited time budgets to quickly consume the key ideas from the data. State-of-the-art approaches for multi-document summarization, however, do not consider user preferences while generating summaries. In this work, we argue the need and propose a solution for generating personalized aspect-based opinion summaries from large collections of online tourist reviews. We let our readers decide and control several attributes of the summary such as the length and specific aspects of interest among others. Specifically, we take an unsupervised approach to extract coherent aspects from tourist reviews posted on TripAdvisor. We then propose an Integer Linear Programming (ILP) based extractive technique to select an informative subset of opinions around the identified aspects while respecting the user-specified values for various control parameters. Finally, we evaluate and compare our summaries using crowdsourcing and ROUGE-based metrics and obtain competitive results.