 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RotNet: Fast and Scalable Estimation of Stellar Rotation Periods Using Convolutional Neural Networks
Dec 02, 2020

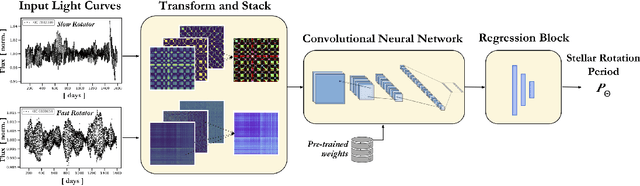
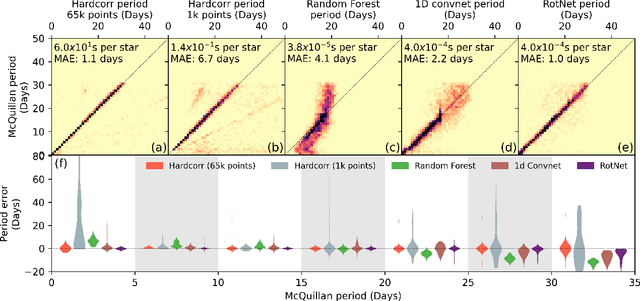
Magnetic activity in stars manifests as dark spots on their surfaces that modulate the brightness observed by telescopes. These light curves contain important information on stellar rotation. However, the accurate estimation of rotation periods is computationally expensive due to scarce ground truth information, noisy data, and large parameter spaces that lead to degenerate solutions. We harness the power of deep learning and successfully apply Convolutional Neural Networks to regress stellar rotation periods from Kepler light curves. Geometry-preserving time-series to image transformations of the light curves serve as inputs to a ResNet-18 based architecture which is trained through transfer learning. The McQuillan catalog of published rotation periods is used as ansatz to groundtruth. We benchmark the performance of our method against a random forest regressor, a 1D CNN, and the Auto-Correlation Function (ACF) - the current standard to estimate rotation periods. Despite limiting our input to fewer data points (1k), our model yields more accurate results and runs 350 times faster than ACF runs on the same number of data points and 10,000 times faster than ACF runs on 65k data points. With only minimal feature engineering our approach has impressive accuracy, motivating the application of deep learning to regress stellar parameters on an even larger scale
Deep Inverse Sensor Models as Priors for evidential Occupancy Mapping
Dec 02, 2020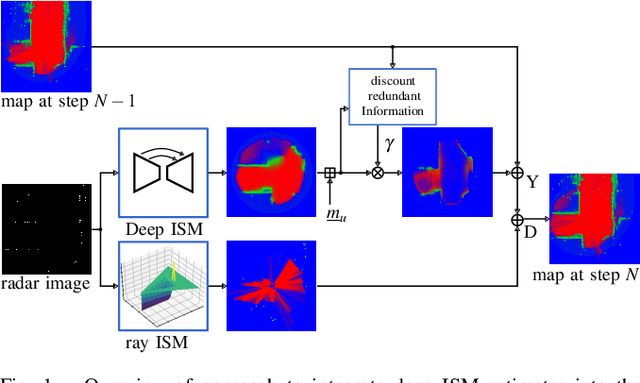
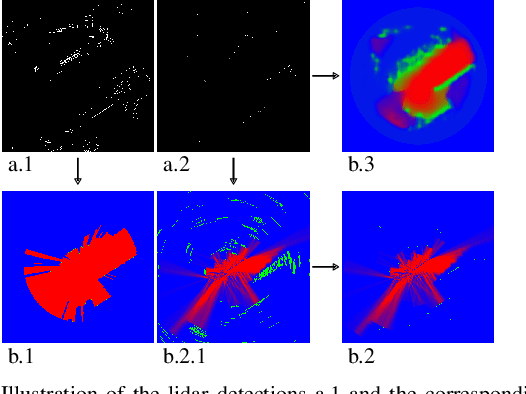
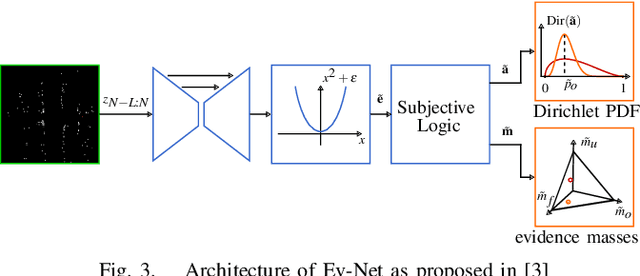

With the recent boost in autonomous driving, increased attention has been paid on radars as an input for occupancy mapping. Besides their many benefits, the inference of occupied space based on radar detections is notoriously difficult because of the data sparsity and the environment dependent noise (e.g. multipath reflections). Recently, deep learning-based inverse sensor models, from here on called deep ISMs, have been shown to improve over their geometric counterparts in retrieving occupancy information. Nevertheless, these methods perform a data-driven interpolation which has to be verified later on in the presence of measurements. In this work, we describe a novel approach to integrate deep ISMs together with geometric ISMs into the evidential occupancy mapping framework. Our method leverages both the capabilities of the data-driven approach to initialize cells not yet observable for the geometric model effectively enhancing the perception field and convergence speed, while at the same time use the precision of the geometric ISM to converge to sharp boundaries. We further define a lower limit on the deep ISM estimate's certainty together with analytical proofs of convergence which we use to distinguish cells that are solely allocated by the deep ISM from cells already verified using the geometric approach.
Neural Temporal Opinion Modelling for Opinion Prediction on Twitter
May 27, 2020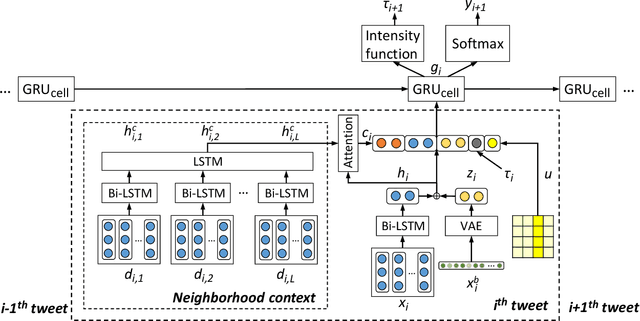
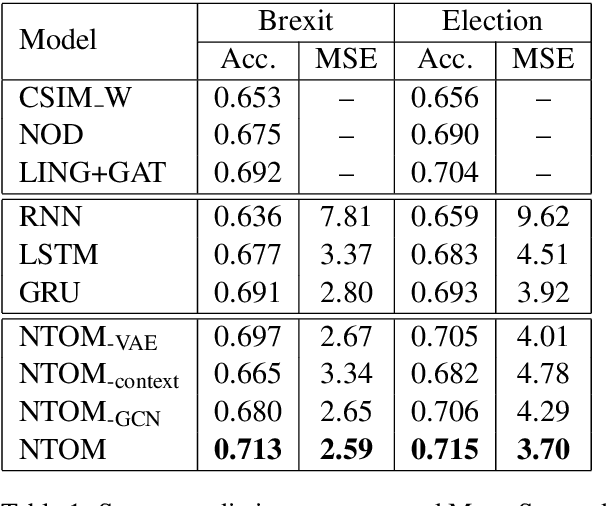
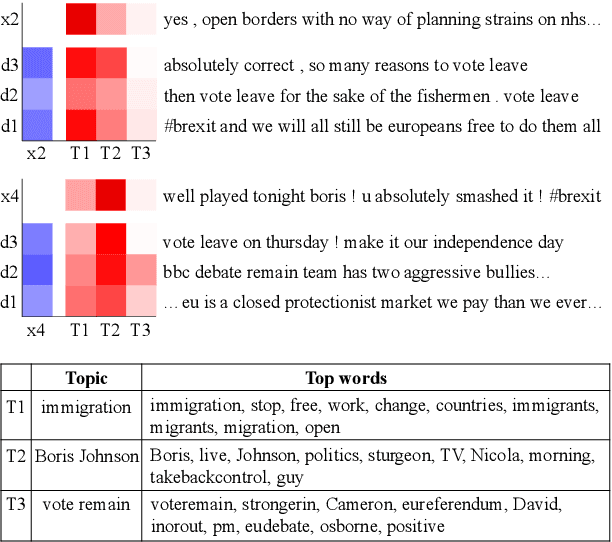
Opinion prediction on Twitter is challenging due to the transient nature of tweet content and neighbourhood context. In this paper, we model users' tweet posting behaviour as a temporal point process to jointly predict the posting time and the stance label of the next tweet given a user's historical tweet sequence and tweets posted by their neighbours. We design a topic-driven attention mechanism to capture the dynamic topic shifts in the neighbourhood context. Experimental results show that the proposed model predicts both the posting time and the stance labels of future tweets more accurately compared to a number of competitive baselines.
Bew: Towards Answering Business-Entity-Related Web Questions
Dec 10, 2020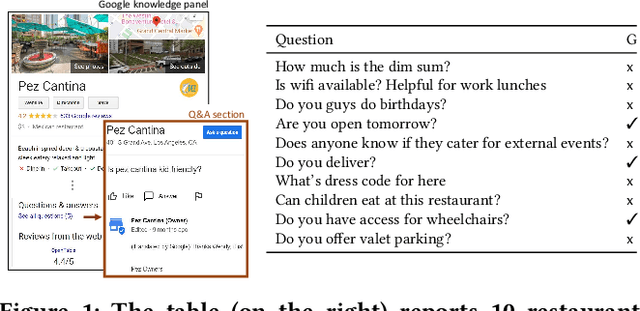
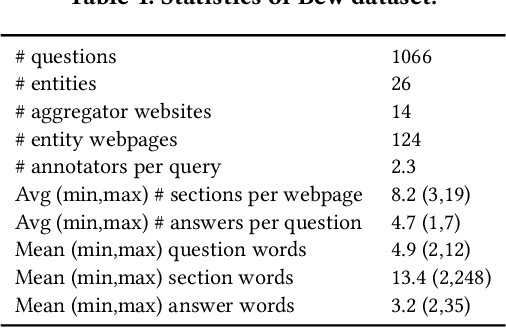
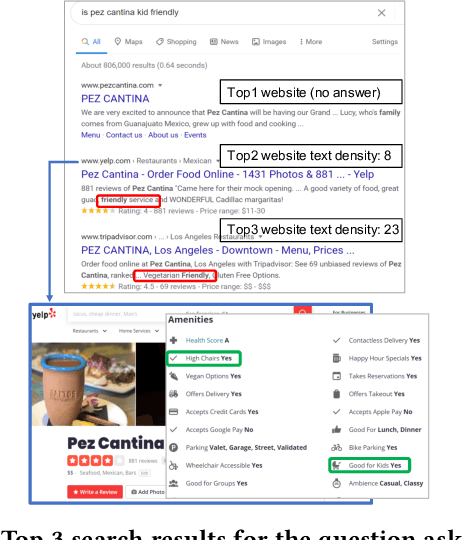
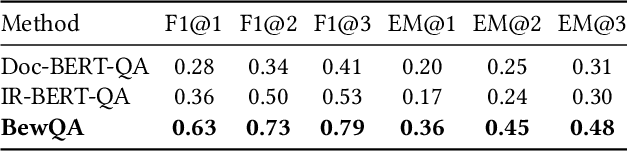
We present BewQA, a system specifically designed to answer a class of questions that we call Bew questions. Bew questions are related to businesses/services such as restaurants, hotels, and movie theaters; for example, "Until what time is happy hour?". These questions are challenging to answer because the answers are found in open-domain Web, are present in short sentences without surrounding context, and are dynamic since the webpage information can be updated frequently. Under these conditions, existing QA systems perform poorly. We present a practical approach, called BewQA, that can answer Bew queries by mining a template of the business-related webpages and using the template to guide the search. We show how we can extract the template automatically by leveraging aggregator websites that aggregate information about business entities in a domain (e.g., restaurants). We answer a given question by identifying the section from the extracted template that is most likely to contain the answer. By doing so we can extract the answers even when the answer span does not have sufficient context. Importantly, BewQA does not require any training. We crowdsource a new dataset of 1066 Bew questions and ground-truth answers in the restaurant domain. Compared to state-of-the-art QA models, BewQA has a 27 percent point improvement in F1 score. Compared to a commercial search engine, BewQA answered correctly 29% more Bew questions.
Accelerating Probabilistic Volumetric Mapping using Ray-Tracing Graphics Hardware
Dec 02, 2020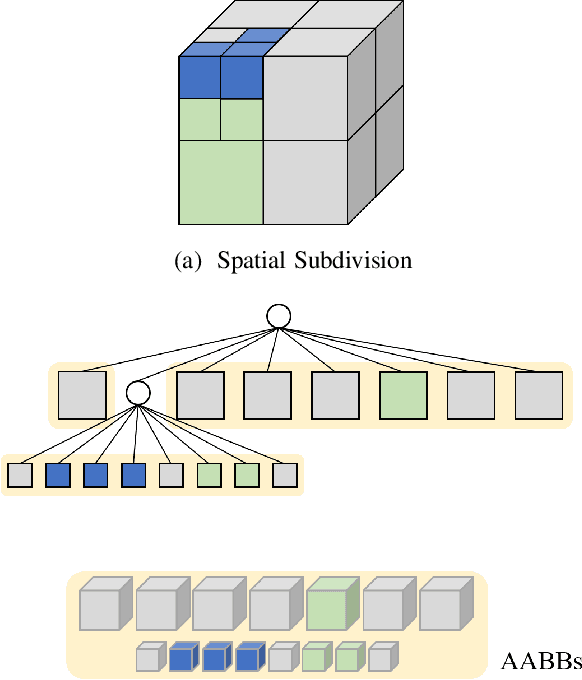
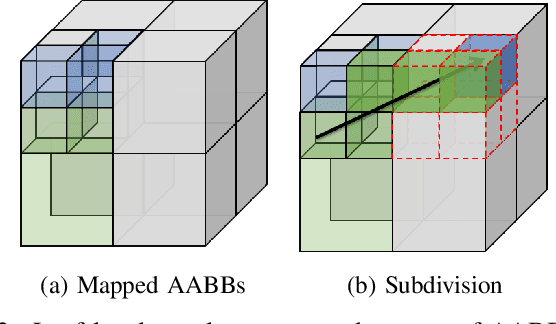
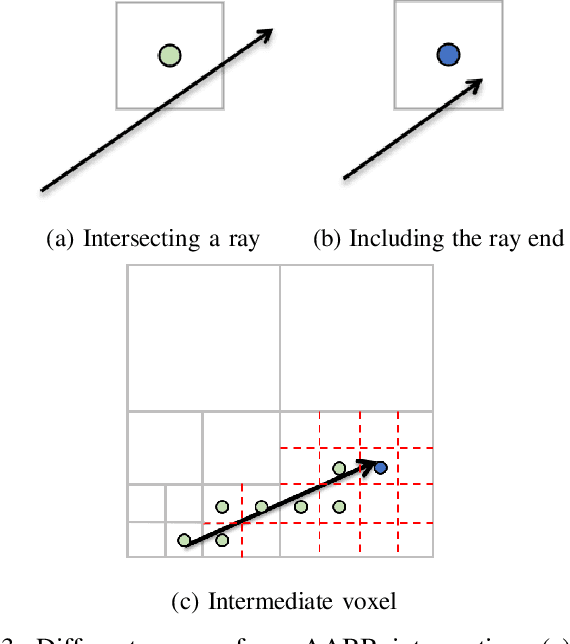
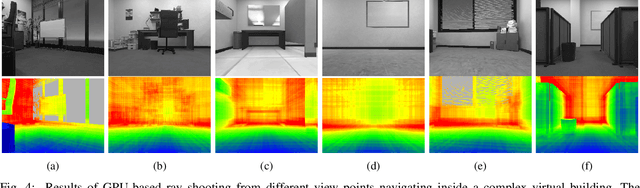
Probabilistic volumetric mapping (PVM) represents a 3D environmental map for an autonomous robotic navigational task. A popular implementation such as Octomap is widely used in the robotics community for such a purpose. The Octomap relies on octree to represent a PVM and its main bottleneck lies in massive ray-shooting to determine the occupancy of the underlying volumetric voxel grids. In this paper, we propose GPU-based ray shooting to drastically improve the ray shooting performance in Octomap. Our main idea is based on the use of recent ray-tracing RTX GPU, mainly designed for real-time photo-realistic computer graphics and the accompanying graphics API, known as DXR. Our ray-shooting first maps leaf-level voxels in the given octree to a set of axis-aligned bounding boxes (AABBs) and employ massively parallel ray shooting on them using GPUs to find free and occupied voxels. These are fed back into CPU to update the voxel occupancy and restructure the octree. In our experiments, we have observed more than three-orders-of-magnitude performance improvement in terms of ray shooting using ray-tracing RTX GPU over a state-of-the-art Octomap CPU implementation, where the benchmarking environments consist of more than 77K points and 25K~34K voxel grids.
PWCLO-Net: Deep LiDAR Odometry in 3D Point Clouds Using Hierarchical Embedding Mask Optimization
Dec 02, 2020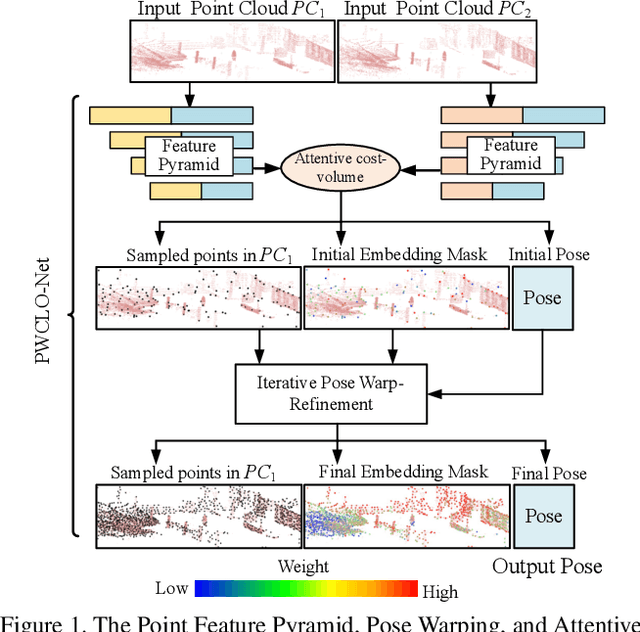
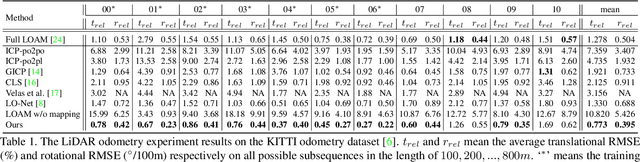
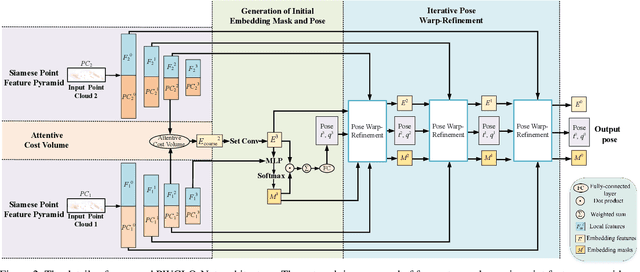

A novel 3D point cloud learning model for deep LiDAR odometry, named PWCLO-Net, using hierarchical embedding mask optimization is proposed in this paper. In this model, the Pyramid, Warping, and Cost volume (PWC) structure for the LiDAR Odometry task is built to hierarchically refine the estimated pose in a coarse-to-fine approach. An attentive cost volume is built to associate two point clouds and obtain the embedding motion information. Then, a novel trainable embedding mask is proposed to weight the cost volume of all points to the overall pose information and filter outlier points. The estimated current pose is used to warp the first point cloud to bridge the distance to the second point cloud, and then the cost volume of the residual motion is built. At the same time, the embedding mask is optimized hierarchically from coarse to fine to obtain more accurate filtering information for pose refinement. The pose warp-refinement process is repeatedly used to make the pose estimation more robust for outliers. The superior performance and effectiveness of our LiDAR odometry model are demonstrated on the KITTI odometry dataset. Our method outperforms all recent learning-based methods and outperforms the geometry-based approach, LOAM with mapping optimization, on most sequences of the KITTI odometry dataset.
DRF: A Framework for High-Accuracy Autonomous Driving Vehicle Modeling
Nov 01, 2020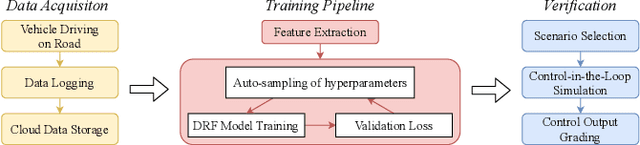
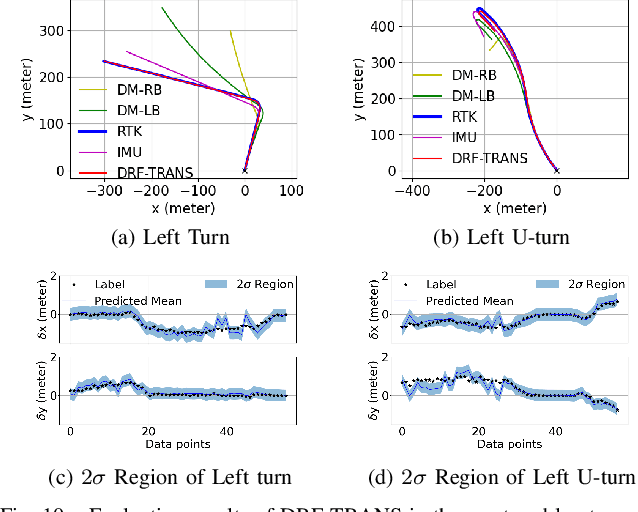
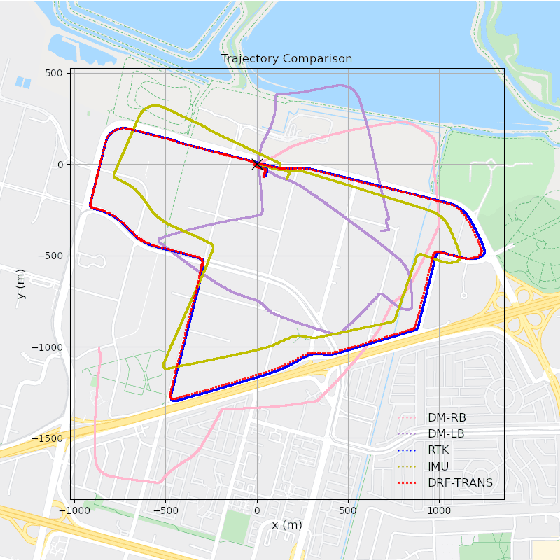
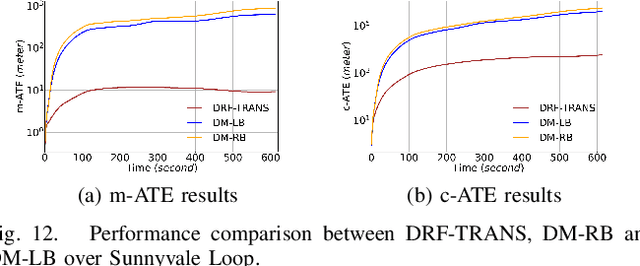
An accurate vehicle dynamic model is the key to bridge the gap between simulation and real road test in autonomous driving. In this paper, we present a Dynamic model-Residual correction model Framework (DRF) for vehicle dynamic modeling. On top of any existing open-loop dynamic model, this framework builds a Residual Correction Model (RCM) by integrating deep Neural Networks (NN) with Sparse Variational Gaussian Process (SVGP) model. RCM takes a sequence of vehicle control commands and dynamic status for a certain time duration as modeling inputs, extracts underlying context from this sequence with deep encoder networks, and predicts open-loop dynamic model prediction errors. Five vehicle dynamic models are derived from DRF via encoder variation. Our contribution is consolidated by experiments on evaluation of absolute trajectory error and similarity between DRF outputs and the ground truth. Compared to classic rule-based and learning-based vehicle dynamic models, DRF accomplishes as high as 74.12% to 85.02% of absolute trajectory error drop among all DRF variations.
Adversarial Linear Contextual Bandits with Graph-Structured Side Observations
Dec 10, 2020
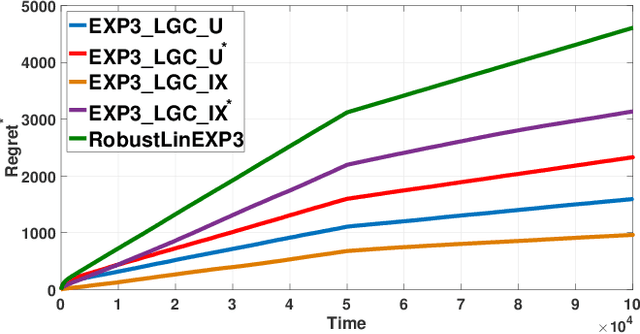
This paper studies the adversarial graphical contextual bandits, a variant of adversarial multi-armed bandits that leverage two categories of the most common side information: \emph{contexts} and \emph{side observations}. In this setting, a learning agent repeatedly chooses from a set of $K$ actions after being presented with a $d$-dimensional context vector. The agent not only incurs and observes the loss of the chosen action, but also observes the losses of its neighboring actions in the observation structures, which are encoded as a series of feedback graphs. This setting models a variety of applications in social networks, where both contexts and graph-structured side observations are available. Two efficient algorithms are developed based on \texttt{EXP3}. Under mild conditions, our analysis shows that for undirected feedback graphs the first algorithm, \texttt{EXP3-LGC-U}, achieves the regret of order $\mathcal{O}(\sqrt{(K+\alpha(G)d)T\log{K}})$ over the time horizon $T$, where $\alpha(G)$ is the average \emph{independence number} of the feedback graphs. A slightly weaker result is presented for the directed graph setting as well. The second algorithm, \texttt{EXP3-LGC-IX}, is developed for a special class of problems, for which the regret is reduced to $\mathcal{O}(\sqrt{\alpha(G)dT\log{K}\log(KT)})$ for both directed as well as undirected feedback graphs. Numerical tests corroborate the efficiency of proposed algorithms.
Persistent And Scalable JADE: A Cloud based InMemory Multi-agent Framework
Sep 14, 2020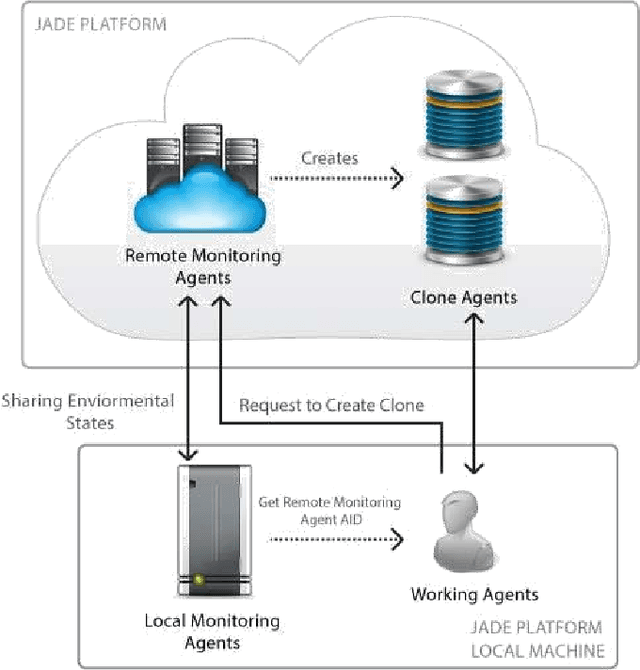
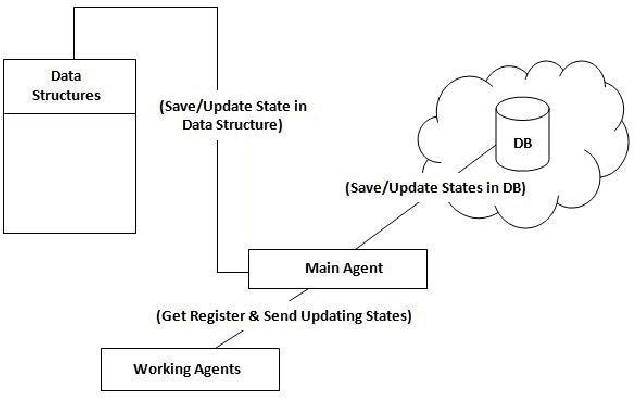
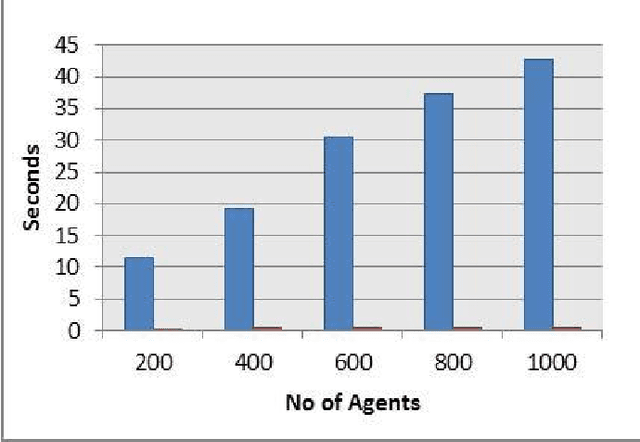
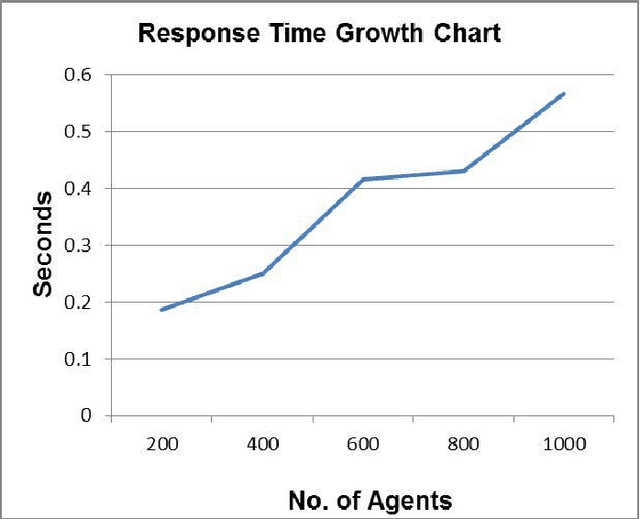
Multi-agent systems are often limited in terms of persistenceand scalability. This issue is more prevalent for applications inwhich agent states changes frequently. This makes the existingmethods less usable as they increase the agent's complexityand are less scalable. This research study has presented anovel in-memory agent persistence framework. Two prototypeshave been implemented, one using the proposed solution andthe other using an established agent persistency environment.Experimental results confirm that the proposed framework ismore scalable than existing approaches whilst providing asimilar level of persistency. These findings will help futurereal-time multiagent systems to become scalable and persistentin a dynamic cloud environment.
Hardware Acceleration of Monte-Carlo Sampling for Energy Efficient Robust Robot Manipulation
Jul 15, 2020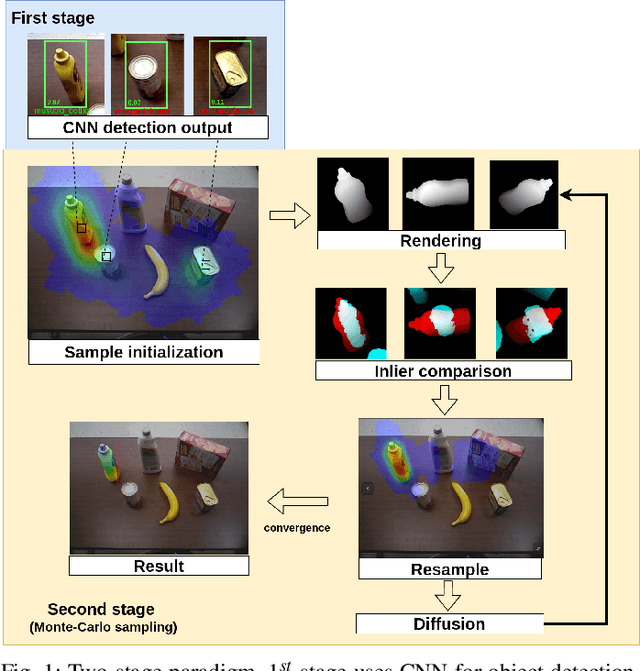
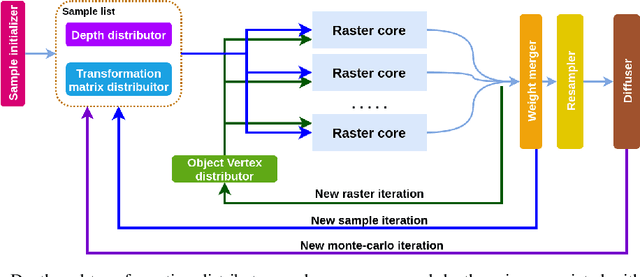
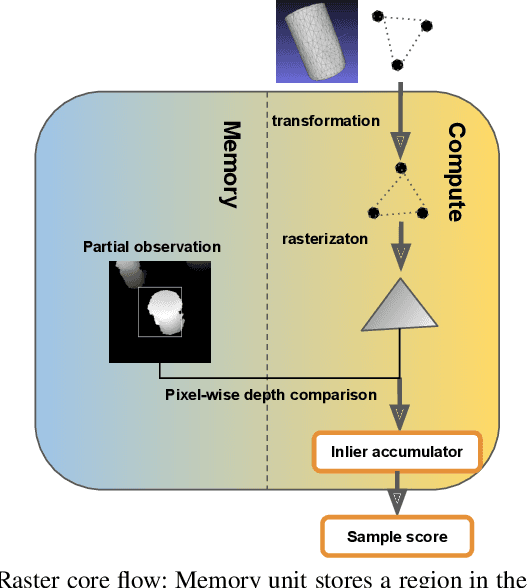

Algorithms based on Monte-Carlo sampling have been widely adapted in robotics and other areas of engineering due to their performance robustness. However, these sampling-based approaches have high computational requirements, making them unsuitable for real-time applications with tight energy constraints. In this paper, we investigate 6 degree-of-freedom (6DoF) pose estimation for robot manipulation using this method, which uses rendering combined with sequential Monte-Carlo sampling. While potentially very accurate, the significant computational complexity of the algorithm makes it less attractive for mobile robots, where runtime and energy consumption are tightly constrained. To address these challenges, we develop a novel hardware implementation of Monte-Carlo sampling on an FPGA with lower computational complexity and memory usage, while achieving high parallelism and modularization. Our results show 12X-21X improvements in energy efficiency over low-power and high-end GPU implementations, respectively. Moreover, we achieve real time performance without compromising accuracy.