 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Age-Based Coded Computation for Bias Reduction in Distributed Learning
Jun 02, 2020
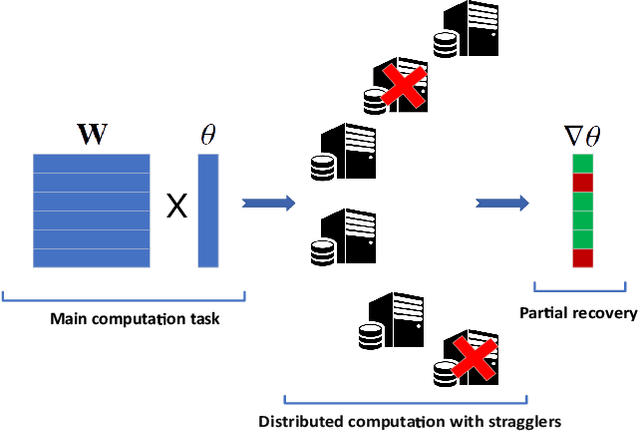
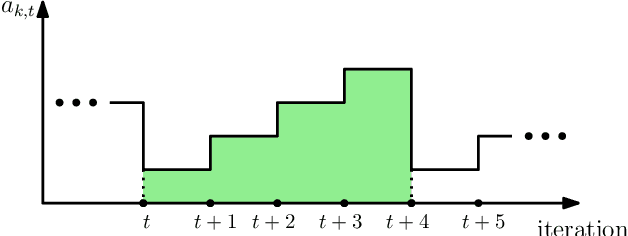

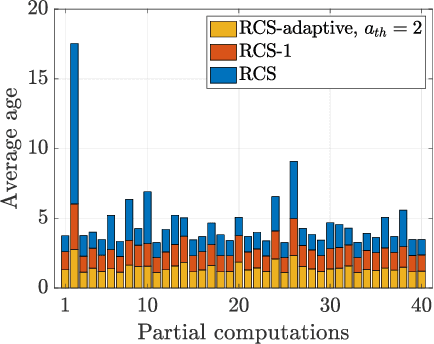
Coded computation can be used to speed up distributed learning in the presence of straggling workers. Partial recovery of the gradient vector can further reduce the computation time at each iteration; however, this can result in biased estimators, which may slow down convergence, or even cause divergence. Estimator bias will be particularly prevalent when the straggling behavior is correlated over time, which results in the gradient estimators being dominated by a few fast servers. To mitigate biased estimators, we design a $timely$ dynamic encoding framework for partial recovery that includes an ordering operator that changes the codewords and computation orders at workers over time. To regulate the recovery frequencies, we adopt an $age$ metric in the design of the dynamic encoding scheme. We show through numerical results that the proposed dynamic encoding strategy increases the timeliness of the recovered computations, which as a result, reduces the bias in model updates, and accelerates the convergence compared to the conventional static partial recovery schemes.
Probabilistic Analysis of RRT Trees
May 04, 2020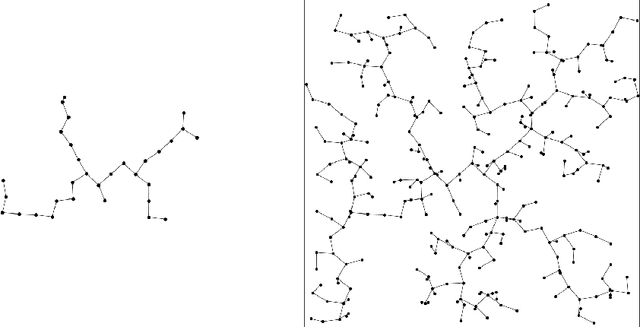
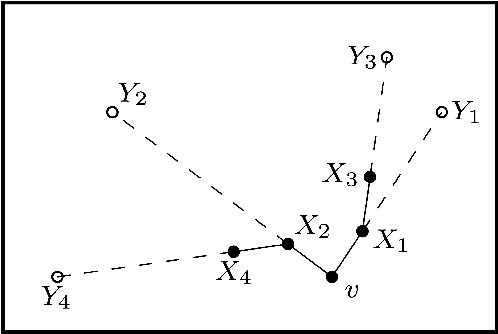

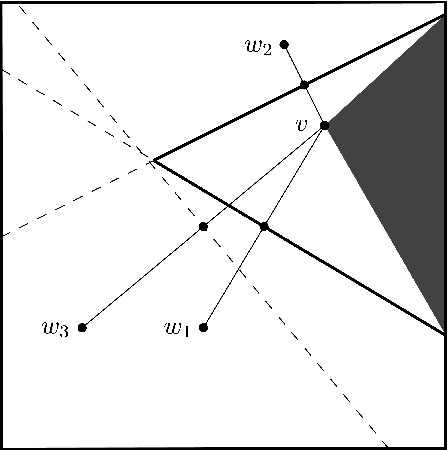
This thesis presents analysis of the properties and run-time of the Rapidly-exploring Random Tree (RRT) algorithm. It is shown that the time for the RRT with stepsize $\epsilon$ to grow close to every point in the $d$-dimensional unit cube is $\Theta\left(\frac1{\epsilon^d} \log \left(\frac1\epsilon\right)\right)$. Also, the time it takes for the tree to reach a region of positive probability is $O\left(\epsilon^{-\frac32}\right)$. Finally, a relationship is shown to the Nearest Neighbour Tree (NNT). This relationship shows that the total Euclidean path length after $n$ steps is $O(\sqrt n)$ and the expected height of the tree is bounded above by $(e + o(1)) \log n$.
Logic-based Clustering and Learning for Time-Series Data
May 15, 2017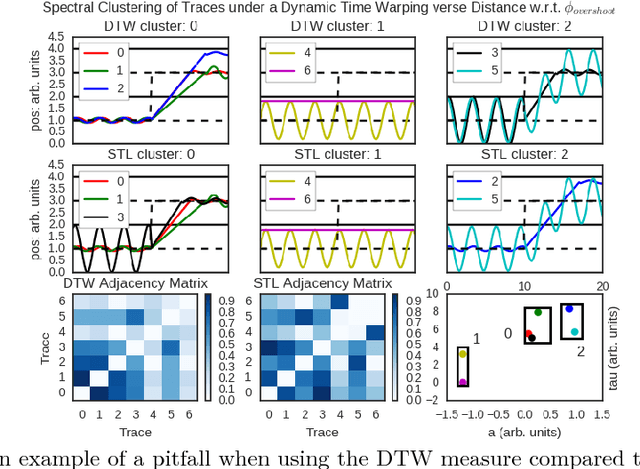
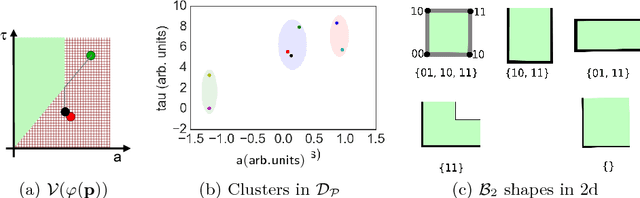
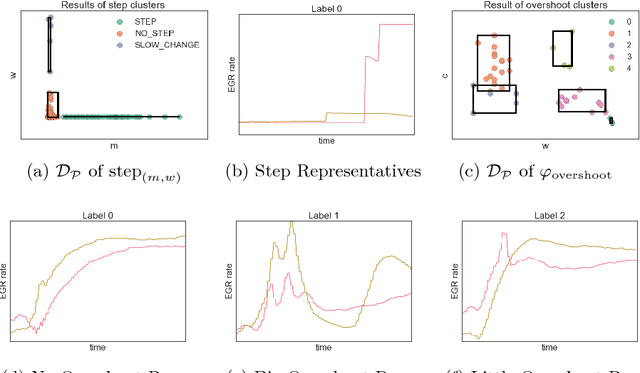
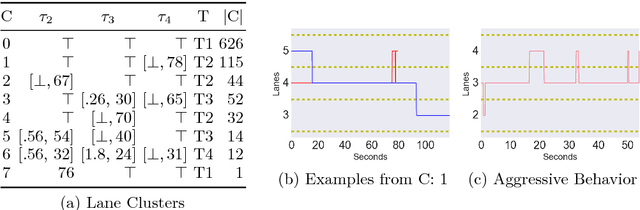
To effectively analyze and design cyberphysical systems (CPS), designers today have to combat the data deluge problem, i.e., the burden of processing intractably large amounts of data produced by complex models and experiments. In this work, we utilize monotonic Parametric Signal Temporal Logic (PSTL) to design features for unsupervised classification of time series data. This enables using off-the-shelf machine learning tools to automatically cluster similar traces with respect to a given PSTL formula. We demonstrate how this technique produces interpretable formulas that are amenable to analysis and understanding using a few representative examples. We illustrate this with case studies related to automotive engine testing, highway traffic analysis, and auto-grading massively open online courses.
Modeling bike counts in a bike-sharing system considering the effect of weather conditions
Jun 13, 2020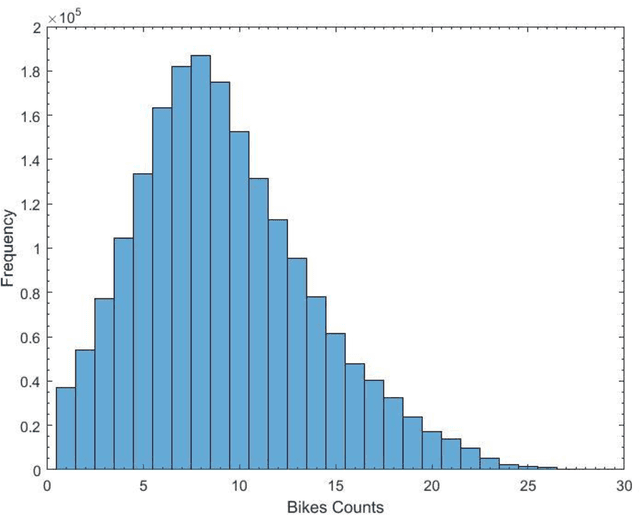

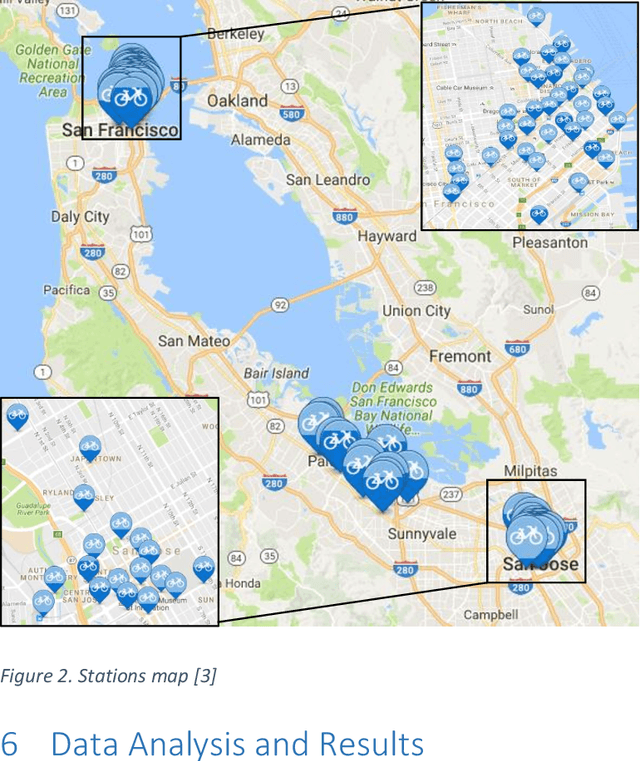
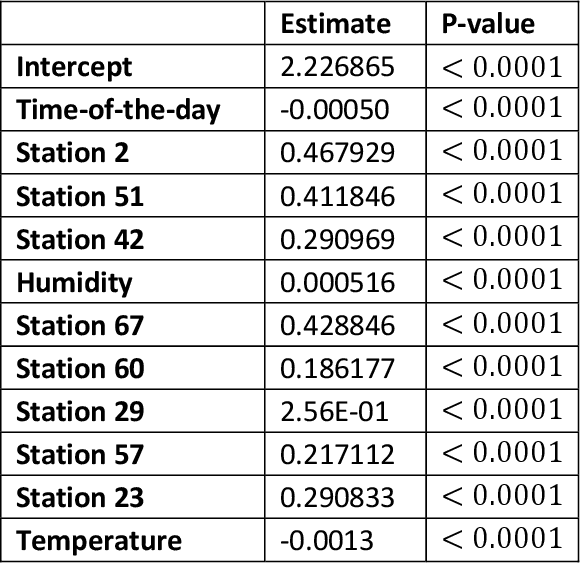
The paper develops a method that quantifies the effect of weather conditions on the prediction of bike station counts in the San Francisco Bay Area Bike Share System. The Random Forest technique was used to rank the predictors that were then used to develop a regression model using a guided forward step-wise regression approach. The Bayesian Information Criterion was used in the development and comparison of the various prediction models. We demonstrated that the proposed approach is promising to quantify the effect of various features on a large BSS and on each station in cases of large networks with big data. The results show that the time-of-the-day, temperature, and humidity level (which has not been studied before) are significant count predictors. It also shows that as weather variables are geographic location dependent and thus should be quantified before using them in modeling. Further, findings show that the number of available bikes at station i at time t-1 and time-of-the-day were the most significant variables in estimating the bike counts at station i.
* Published in Case Studies on Transport Policy (Volume 7, Issue 2, June 2019, Pages 261-268)
Structured Logconcave Sampling with a Restricted Gaussian Oracle
Oct 08, 2020
We give algorithms for sampling several structured logconcave families to high accuracy. We further develop a reduction framework, inspired by proximal point methods in convex optimization, which bootstraps samplers for regularized densities to improve dependences on problem conditioning. A key ingredient in our framework is the notion of a "restricted Gaussian oracle" (RGO) for $g: \mathbb{R}^d \rightarrow \mathbb{R}$, which is a sampler for distributions whose negative log-likelihood sums a quadratic and $g$. By combining our reduction framework with our new samplers, we obtain the following bounds for sampling structured distributions to total variation distance $\epsilon$. For composite densities $\exp(-f(x) - g(x))$, where $f$ has condition number $\kappa$ and convex (but possibly non-smooth) $g$ admits an RGO, we obtain a mixing time of $O(\kappa d \log^3\frac{\kappa d}{\epsilon})$, matching the state-of-the-art non-composite bound; no composite samplers with better mixing than general-purpose logconcave samplers were previously known. For logconcave finite sums $\exp(-F(x))$, where $F(x) = \frac{1}{n}\sum_{i \in [n]} f_i(x)$ has condition number $\kappa$, we give a sampler querying $\widetilde{O}(n + \kappa\max(d, \sqrt{nd}))$ gradient oracles to $\{f_i\}_{i \in [n]}$; no high-accuracy samplers with nontrivial gradient query complexity were previously known. For densities with condition number $\kappa$, we give an algorithm obtaining mixing time $O(\kappa d \log^2\frac{\kappa d}{\epsilon})$, improving the prior state-of-the-art by a logarithmic factor with a significantly simpler analysis; we also show a zeroth-order algorithm attains the same query complexity.
SceneFormer: Indoor Scene Generation with Transformers
Dec 17, 2020


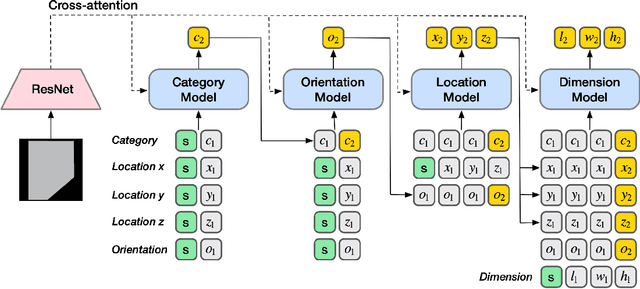
The task of indoor scene generation is to generate a sequence of objects, their locations and orientations conditioned on the shape and size of a room. Large scale indoor scene datasets allow us to extract patterns from user-designed indoor scenes and then generate new scenes based on these patterns. Existing methods rely on the 2D or 3D appearance of these scenes in addition to object positions, and make assumptions about the possible relations between objects. In contrast, we do not use any appearance information, and learn relations between objects using the self attention mechanism of transformers. We show that this leads to faster scene generation compared to existing methods with the same or better levels of realism. We build simple and effective generative models conditioned on the room shape, and on text descriptions of the room using only the cross-attention mechanism of transformers. We carried out a user study showing that our generated scenes are preferred over DeepSynth scenes 57.7% of the time for bedroom scenes, and 63.3% for living room scenes. In addition, we generate a scene in 1.48 seconds on average, 20% faster than the state of the art method Fast & Flexible, allowing interactive scene generation.
Beyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases
Nov 18, 2020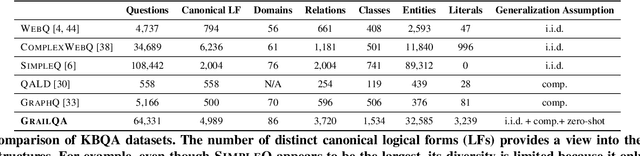
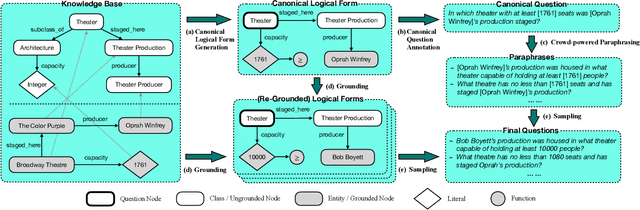

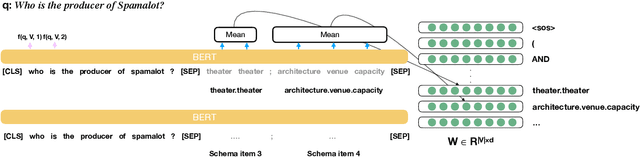
Existing studies on question answering on knowledge bases (KBQA) mainly operate with the standard i.i.d assumption, i.e., training distribution over questions is the same as the test distribution. However, i.i.d may be neither reasonably achievable nor desirable on large-scale KBs because 1) true user distribution is hard to capture and 2) randomly sample training examples from the enormous space would be highly data-inefficient. Instead, we suggest that KBQA models should have three levels of built-in generalization: i.i.d, compositional, and zero-shot. To facilitate the development of KBQA models with stronger generalization, we construct and release a new large-scale, high-quality dataset with 64,331 questions, GrailQA, and provide evaluation settings for all three levels of generalization. In addition, we propose a novel BERT-based KBQA model. The combination of our dataset and model enables us to thoroughly examine and demonstrate, for the first time, the key role of pre-trained contextual embeddings like BERT in the generalization of KBQA.
Semantic Segmentation of Surface from Lidar Point Cloud
Sep 13, 2020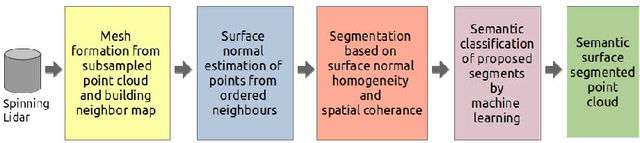
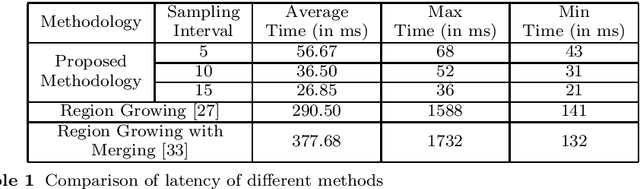
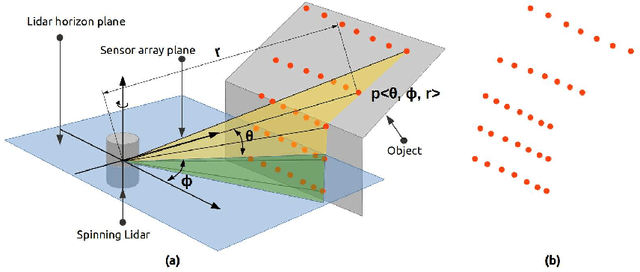
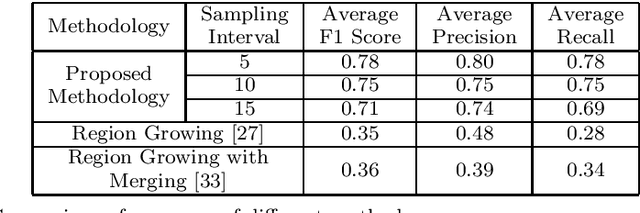
In the field of SLAM (Simultaneous Localization And Mapping) for robot navigation, mapping the environment is an important task. In this regard the Lidar sensor can produce near accurate 3D map of the environment in the format of point cloud, in real time. Though the data is adequate for extracting information related to SLAM, processing millions of points in the point cloud is computationally quite expensive. The methodology presented proposes a fast algorithm that can be used to extract semantically labelled surface segments from the cloud, in real time, for direct navigational use or higher level contextual scene reconstruction. First, a single scan from a spinning Lidar is used to generate a mesh of subsampled cloud points online. The generated mesh is further used for surface normal computation of those points on the basis of which surface segments are estimated. A novel descriptor to represent the surface segments is proposed and utilized to determine the surface class of the segments (semantic label) with the help of classifier. These semantic surface segments can be further utilized for geometric reconstruction of objects in the scene, or can be used for optimized trajectory planning by a robot. The proposed methodology is compared with number of point cloud segmentation methods and state of the art semantic segmentation methods to emphasize its efficacy in terms of speed and accuracy.
Data Programming by Demonstration: A Framework for Interactively Learning Labeling Functions
Sep 04, 2020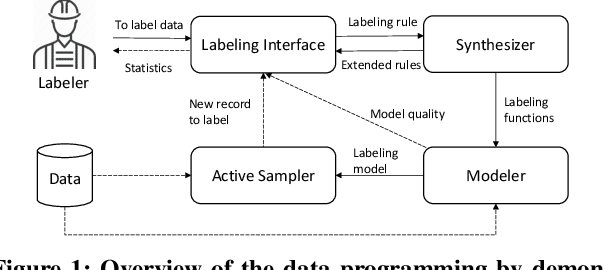
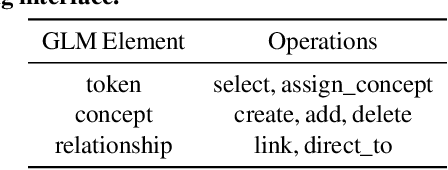
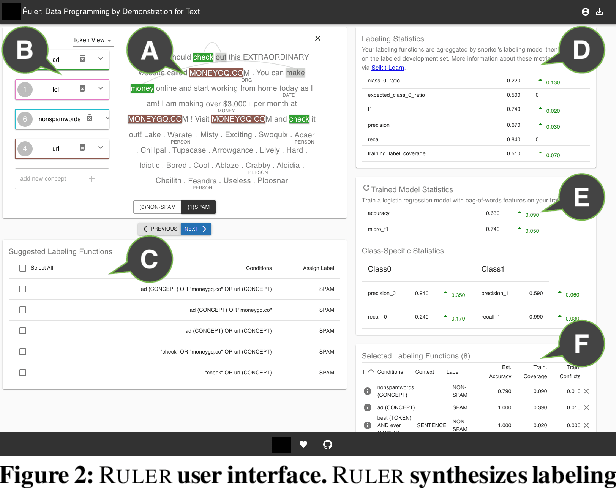

Data programming is a programmatic weak supervision approach to efficiently curate large-scale labeled training data. Writing data programs (labeling functions) requires, however, both programming literacy and domain expertise. Many subject matter experts have neither programming proficiency nor time to effectively write data programs. Furthermore, regardless of one's expertise in coding or machine learning, transferring domain expertise into labeling functions by enumerating rules and thresholds is not only time consuming but also inherently difficult. Here we propose a new framework, data programming by demonstration (DPBD), to generate labeling rules using interactive demonstrations of users. DPBD aims to relieve the burden of writing labeling functions from users, enabling them to focus on higher-level semantics such as identifying relevant signals for labeling tasks. We operationalize our framework with Ruler, an interactive system that synthesizes labeling rules for document classification by using span-level annotations of users on document examples. We compare Ruler with conventional data programming through a user study conducted with 10 data scientists creating labeling functions for sentiment and spam classification tasks. We find that Ruler is easier to use and learn and offers higher overall satisfaction, while providing discriminative model performances comparable to ones achieved by conventional data programming.
TeaForN: Teacher-Forcing with N-grams
Oct 09, 2020



Sequence generation models trained with teacher-forcing suffer from issues related to exposure bias and lack of differentiability across timesteps. Our proposed method, Teacher-Forcing with N-grams (TeaForN), addresses both these problems directly, through the use of a stack of N decoders trained to decode along a secondary time axis that allows model parameter updates based on N prediction steps. TeaForN can be used with a wide class of decoder architectures and requires minimal modifications from a standard teacher-forcing setup. Empirically, we show that TeaForN boosts generation quality on one Machine Translation benchmark, WMT 2014 English-French, and two News Summarization benchmarks, CNN/Dailymail and Gigaword.