 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BSUV-Net 2.0: Spatio-Temporal Data Augmentations for Video-Agnostic Supervised Background Subtraction
Feb 24, 2021

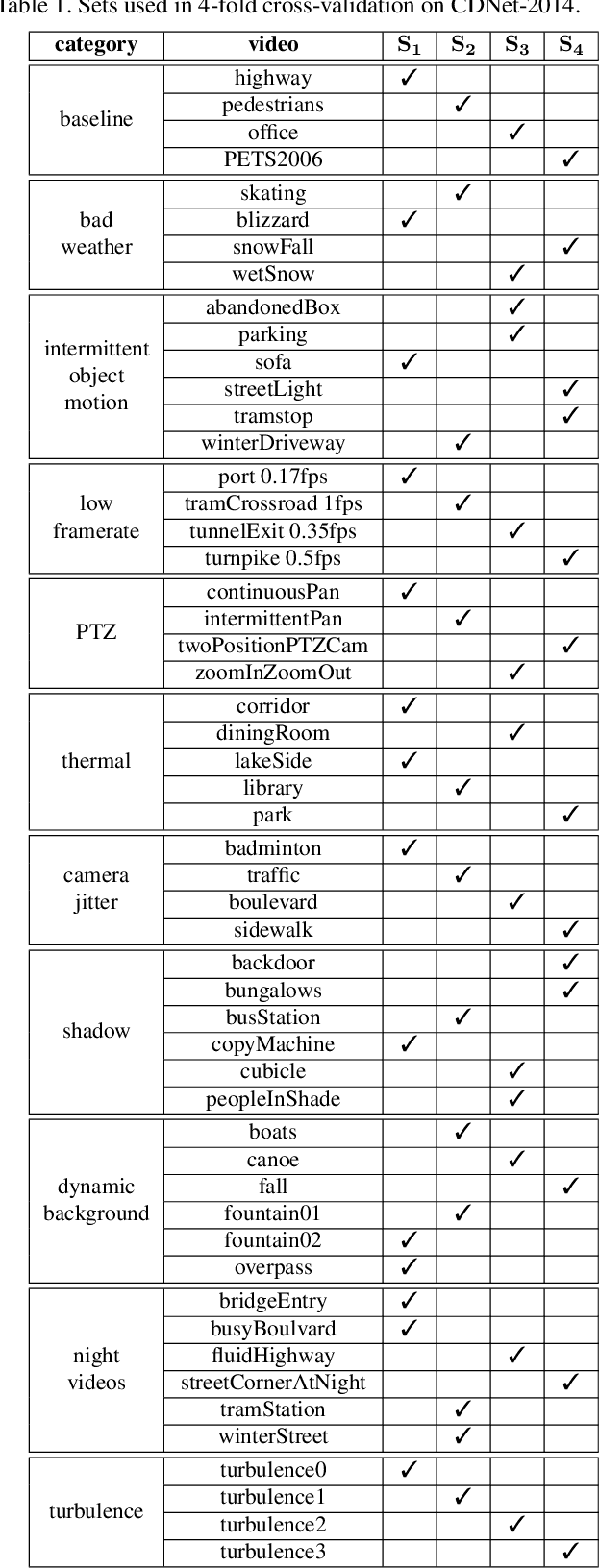
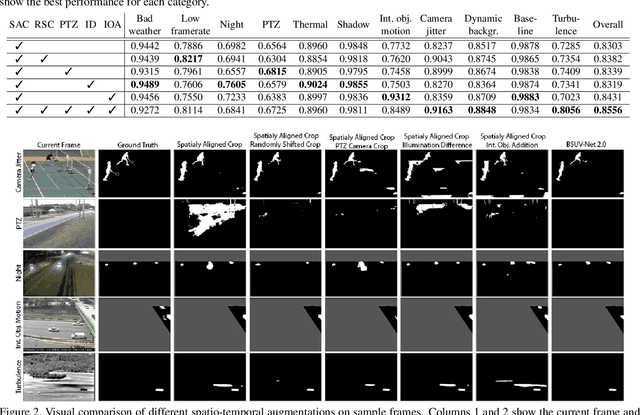
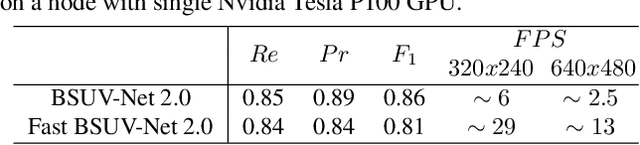
Background subtraction (BGS) is a fundamental video processing task which is a key component of many applications. Deep learning-based supervised algorithms achieve very good perforamnce in BGS, however, most of these algorithms are optimized for either a specific video or a group of videos, and their performance decreases dramatically when applied to unseen videos. Recently, several papers addressed this problem and proposed video-agnostic supervised BGS algorithms. However, nearly all of the data augmentations used in these algorithms are limited to the spatial domain and do not account for temporal variations that naturally occur in video data. In this work, we introduce spatio-temporal data augmentations and apply them to one of the leading video-agnostic BGS algorithms, BSUV-Net. We also introduce a new cross-validation training and evaluation strategy for the CDNet-2014 dataset that makes it possible to fairly and easily compare the performance of various video-agnostic supervised BGS algorithms. Our new model trained using the proposed data augmentations, named BSUV-Net 2.0, significantly outperforms state-of-the-art algorithms evaluated on unseen videos of CDNet-2014. We also evaluate the cross-dataset generalization capacity of BSUV-Net 2.0 by training it solely on CDNet-2014 videos and evaluating its performance on LASIESTA dataset. Overall, BSUV-Net 2.0 provides a ~5% improvement in the F-score over state-of-the-art methods on unseen videos of CDNet-2014 and LASIESTA datasets. Furthermore, we develop a real-time variant of our model, that we call Fast BSUV-Net 2.0, whose performance is close to the state of the art.
Sequential Place Learning: Heuristic-Free High-Performance Long-Term Place Recognition
Mar 02, 2021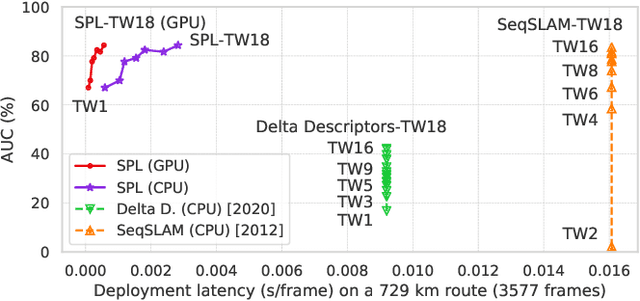
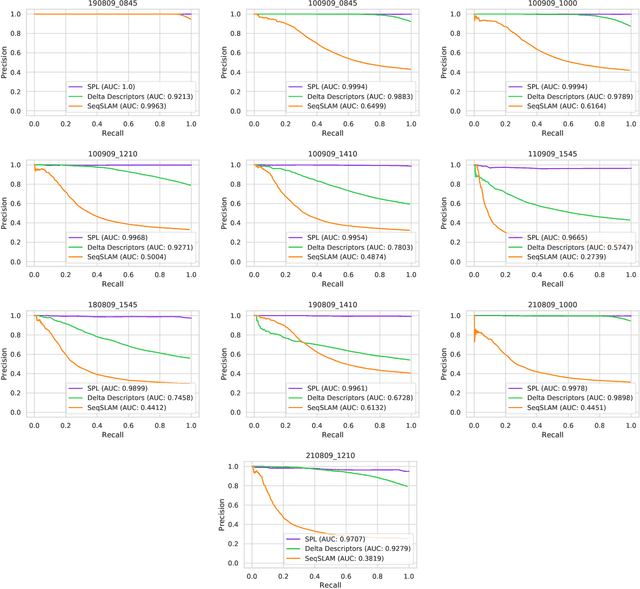
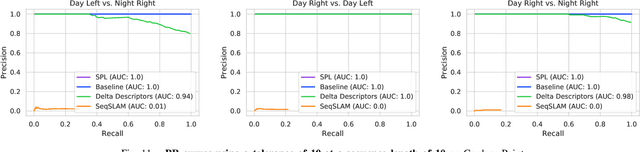
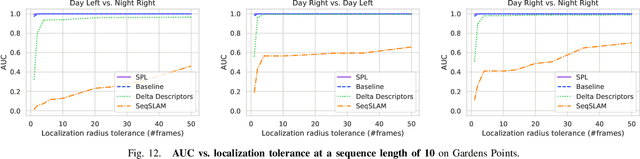
Sequential matching using hand-crafted heuristics has been standard practice in route-based place recognition for enhancing pairwise similarity results for nearly a decade. However, precision-recall performance of these algorithms dramatically degrades when searching on short temporal window (TW) lengths, while demanding high compute and storage costs on large robotic datasets for autonomous navigation research. Here, influenced by biological systems that robustly navigate spacetime scales even without vision, we develop a joint visual and positional representation learning technique, via a sequential process, and design a learning-based CNN+LSTM architecture, trainable via backpropagation through time, for viewpoint- and appearance-invariant place recognition. Our approach, Sequential Place Learning (SPL), is based on a CNN function that visually encodes an environment from a single traversal, thus reducing storage capacity, while an LSTM temporally fuses each visual embedding with corresponding positional data -- obtained from any source of motion estimation -- for direct sequential inference. Contrary to classical two-stage pipelines, e.g., match-then-temporally-filter, our network directly eliminates false-positive rates while jointly learning sequence matching from a single monocular image sequence, even using short TWs. Hence, we demonstrate that our model outperforms 15 classical methods while setting new state-of-the-art performance standards on 4 challenging benchmark datasets, where one of them can be considered solved with recall rates of 100% at 100% precision, correctly matching all places under extreme sunlight-darkness changes. In addition, we show that SPL can be up to 70x faster to deploy than classical methods on a 729 km route comprising 35,768 consecutive frames. Extensive experiments demonstrate the... Baseline code available at https://github.com/mchancan/deepseqslam
Towards Metric Temporal Answer Set Programming
Aug 08, 2020

We elaborate upon the theoretical foundations of a metric temporal extension of Answer Set Programming. In analogy to previous extensions of ASP with constructs from Linear Temporal and Dynamic Logic, we accomplish this in the setting of the logic of Here-and-There and its non-monotonic extension, called Equilibrium Logic. More precisely, we develop our logic on the same semantic underpinnings as its predecessors and thus use a simple time domain of bounded time steps. This allows us to compare all variants in a uniform framework and ultimately combine them in a common implementation.
DeepDT: Learning Geometry From Delaunay Triangulation for Surface Reconstruction
Jan 25, 2021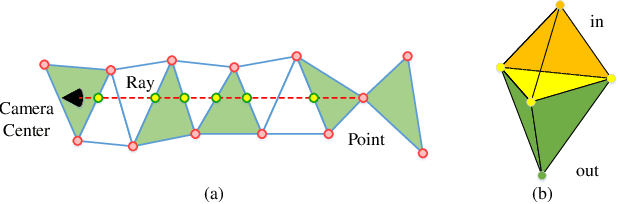

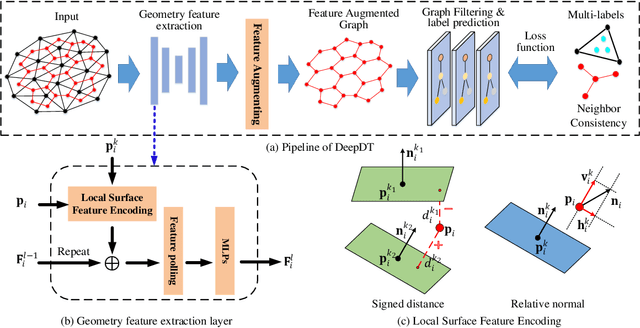

In this paper, a novel learning-based network, named DeepDT, is proposed to reconstruct the surface from Delaunay triangulation of point cloud. DeepDT learns to predict inside/outside labels of Delaunay tetrahedrons directly from a point cloud and corresponding Delaunay triangulation. The local geometry features are first extracted from the input point cloud and aggregated into a graph deriving from the Delaunay triangulation. Then a graph filtering is applied on the aggregated features in order to add structural regularization to the label prediction of tetrahedrons. Due to the complicated spatial relations between tetrahedrons and the triangles, it is impossible to directly generate ground truth labels of tetrahedrons from ground truth surface. Therefore, we propose a multilabel supervision strategy which votes for the label of a tetrahedron with labels of sampling locations inside it. The proposed DeepDT can maintain abundant geometry details without generating overly complex surfaces , especially for inner surfaces of open scenes. Meanwhile, the generalization ability and time consumption of the proposed method is acceptable and competitive compared with the state-of-the-art methods. Experiments demonstrate the superior performance of the proposed DeepDT.
Learning Neural Networks with Two Nonlinear Layers in Polynomial Time
Apr 20, 2018We give a polynomial-time algorithm for learning neural networks with one layer of sigmoids feeding into any Lipschitz, monotone activation function (e.g., sigmoid or ReLU). We make no assumptions on the structure of the network, and the algorithm succeeds with respect to {\em any} distribution on the unit ball in $n$ dimensions (hidden weight vectors also have unit norm). This is the first assumption-free, provably efficient algorithm for learning neural networks with two nonlinear layers. Our algorithm-- {\em Alphatron}-- is a simple, iterative update rule that combines isotonic regression with kernel methods. It outputs a hypothesis that yields efficient oracle access to interpretable features. It also suggests a new approach to Boolean learning problems via real-valued conditional-mean functions, sidestepping traditional hardness results from computational learning theory. Along these lines, we subsume and improve many longstanding results for PAC learning Boolean functions to the more general, real-valued setting of {\em probabilistic concepts}, a model that (unlike PAC learning) requires non-i.i.d. noise-tolerance.
Ensemble and Random Collaborative Representation-Based Anomaly Detector for Hyperspectral Imagery
Jan 06, 2021

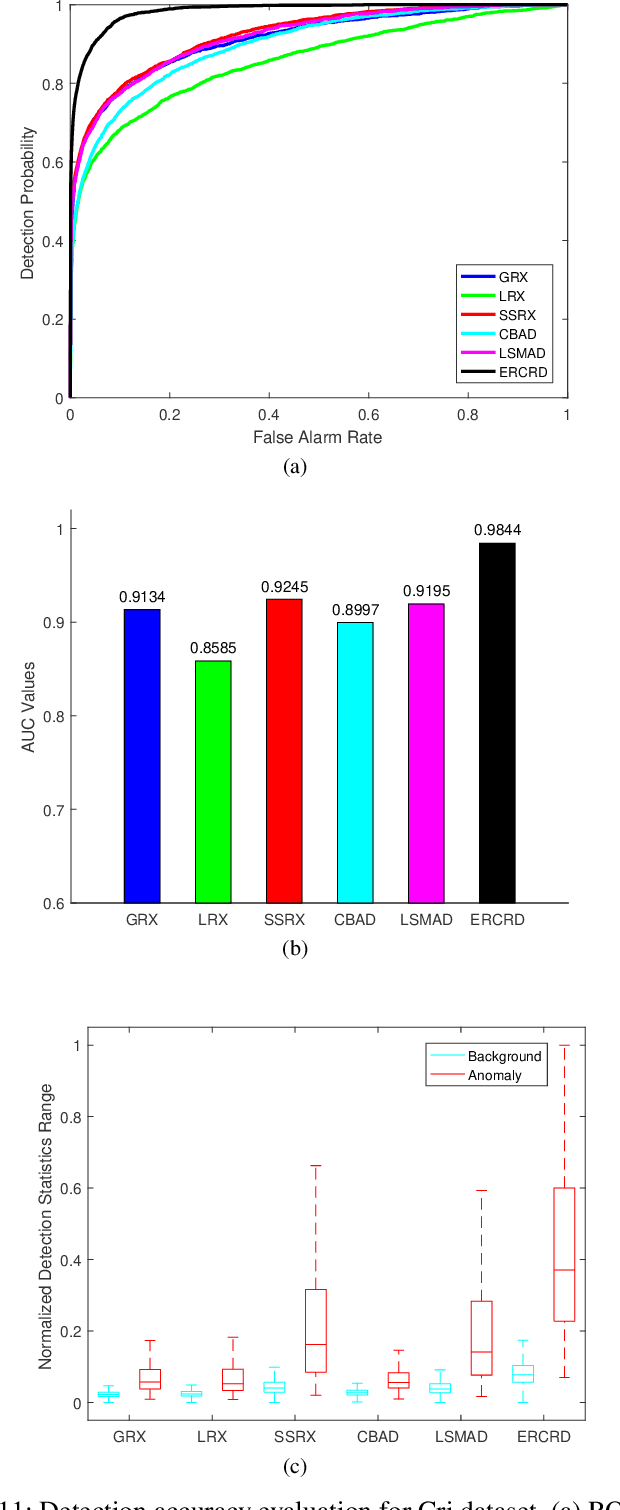
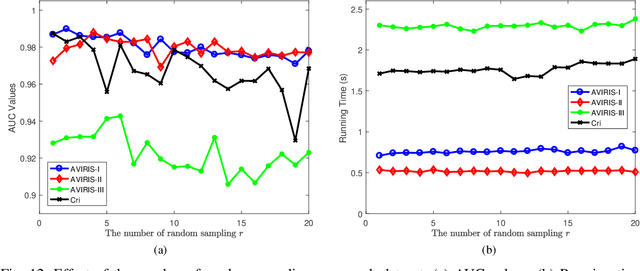
In recent years, hyperspectral anomaly detection (HAD) has become an active topic and plays a significant role in military and civilian fields. As a classic HAD method, the collaboration representation-based detector (CRD) has attracted extensive attention and in-depth research. Despite the good performance of CRD method, its computational cost is too high for the widely demanded real-time applications. To alleviate this problem, a novel ensemble and random collaborative representation-based detector (ERCRD) is proposed for HAD. This approach comprises two main steps. Firstly, we propose a random background modeling to replace the sliding dual window strategy used in the original CRD method. Secondly, we can obtain multiple detection results through multiple random background modeling, and these results are further refined to final detection result through ensemble learning. Experiments on four real hyperspectral datasets exhibit the accuracy and efficiency of this proposed ERCRD method compared with ten state-of-the-art HAD methods.
Extension of Full and Reduced Order Observers for Image-based Depth Estimation using Concurrent Learning
Aug 12, 2020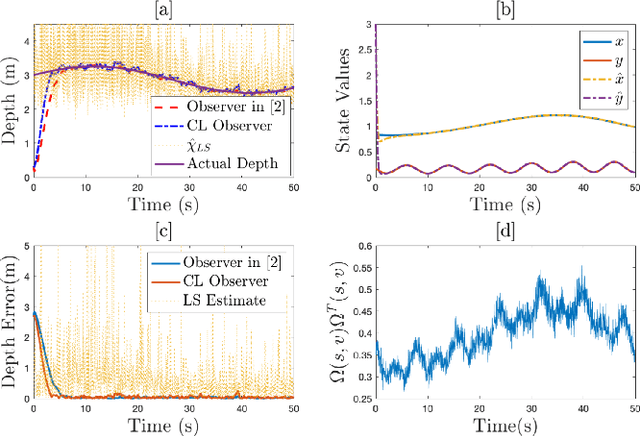
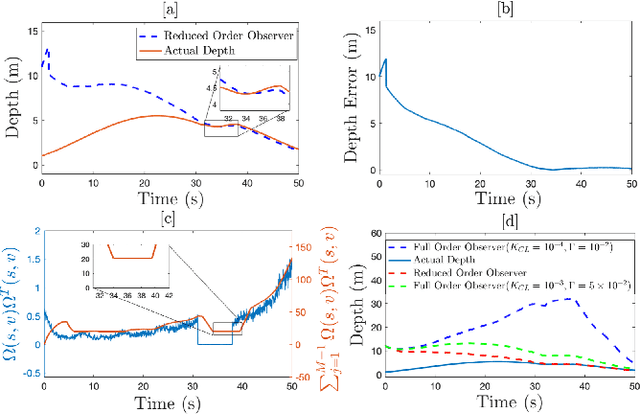
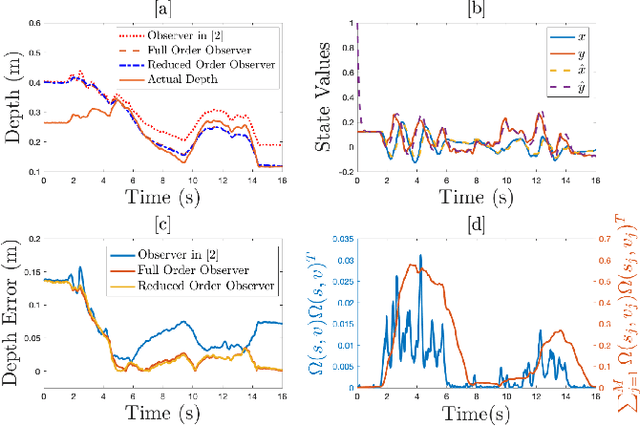
In this paper concurrent learning (CL)-based full and reduced order observers for a perspective dynamical system (PDS) are developed. The PDS is a widely used model for estimating the depth of a feature point from a sequence of camera images. Building on the current progress of CL for parameter estimation in adaptive control, a state observer is developed for the PDS model where the inverse depth appears as a time-varying parameter in the dynamics. The data recorded over a sliding time window in the near past is used in the CL term to design the full and the reduced order state observers. A Lyapunov-based stability analysis is carried out to prove the uniformly ultimately bounded (UUB) stability of the developed observers. Simulation results are presented to validate the accuracy and convergence of the developed observers in terms of convergence time, root mean square error (RMSE) and mean absolute percentage error (MAPE) metrics. Real world depth estimation experiments are performed to demonstrate the performance of the observers using aforementioned metrics on a 7-DoF manipulator with an eye-in-hand configuration.
The model reduction of the Vlasov-Poisson-Fokker-Planck system to the Poisson-Nernst-Planck system via the Deep Neural Network Approach
Sep 28, 2020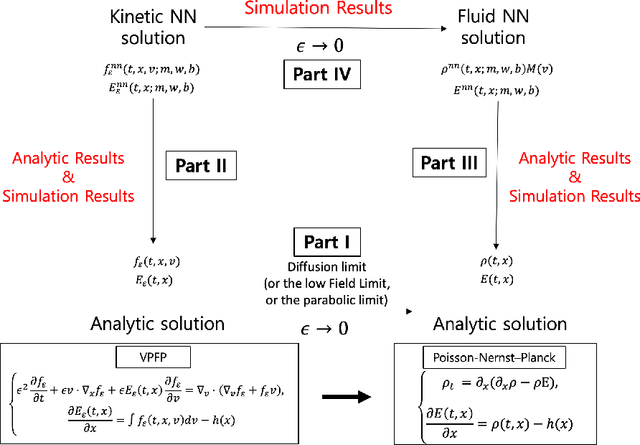
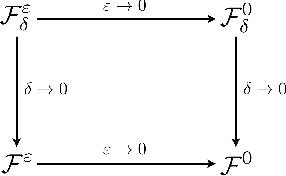
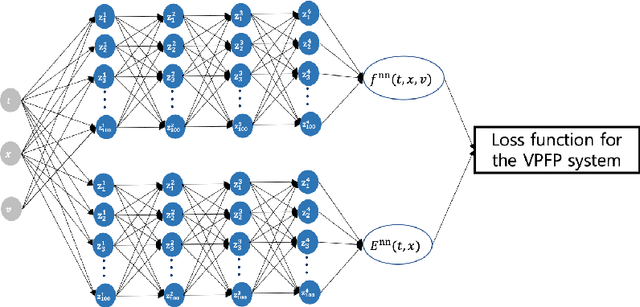
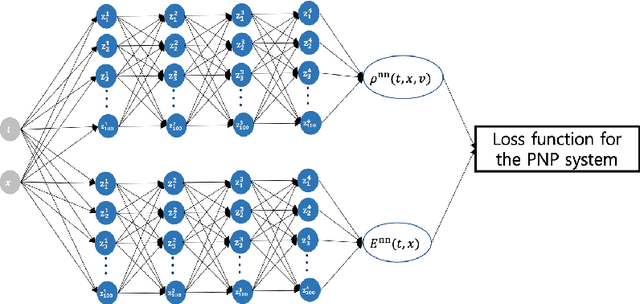
The model reduction of a mesoscopic kinetic dynamics to a macroscopic continuum dynamics has been one of the fundamental questions in mathematical physics since Hilbert's time. In this paper, we consider a diagram of the diffusion limit from the Vlasov-Poisson-Fokker-Planck (VPFP) system on a bounded interval with the specular reflection boundary condition to the Poisson-Nernst-Planck (PNP) system with the no-flux boundary condition. We provide a Deep Learning algorithm to simulate the VPFP system and the PNP system by computing the time-asymptotic behaviors of the solution and the physical quantities. We analyze the convergence of the neural network solution of the VPFP system to that of the PNP system via the Asymptotic-Preserving (AP) scheme. Also, we provide several theoretical evidence that the Deep Neural Network (DNN) solutions to the VPFP and the PNP systems converge to the a priori classical solutions of each system if the total loss function vanishes.
Curating Long-term Vector Maps
Jul 30, 2020
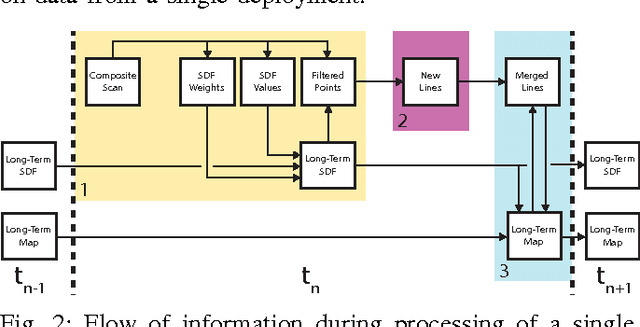
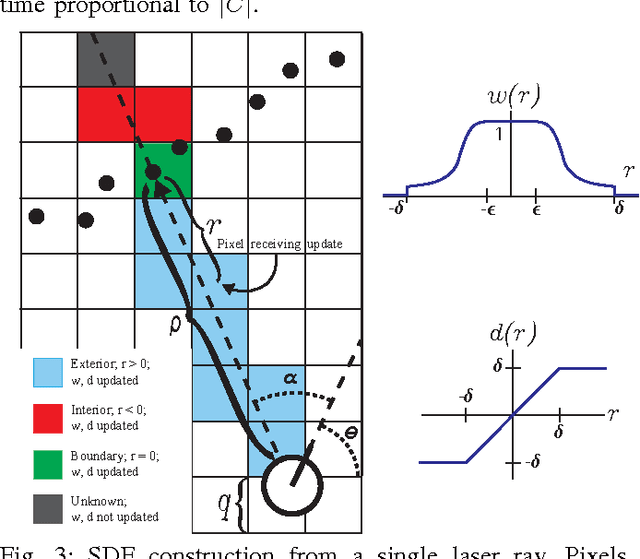
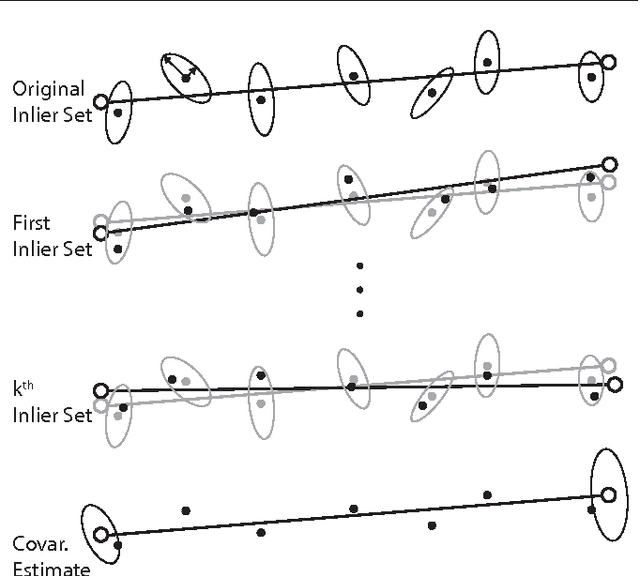
Autonomous service mobile robots need to consistently, accurately, and robustly localize in human environments despite changes to such environments over time. Episodic non-Markov Localization addresses the challenge of localization in such changing environments by classifying observations as arising from Long-Term, Short-Term, or Dynamic Features. However, in order to do so, EnML relies on an estimate of the Long-Term Vector Map (LTVM) that does not change over time. In this paper, we introduce a recursive algorithm to build and update the LTVM over time by reasoning about visibility constraints of objects observed over multiple robot deployments. We use a signed distance function (SDF) to filter out observations of short-term and dynamic features from multiple deployments of the robot. The remaining long-term observations are used to build a vector map by robust local linear regression. The uncertainty in the resulting LTVM is computed via Monte Carlo resampling the observations arising from long-term features. By combining occupancy-grid based SDF filtering of observations with continuous space regression of the filtered observations, our proposed approach builds, updates, and amends LTVMs over time, reasoning about all observations from all robot deployments in an environment. We present experimental results demonstrating the accuracy, robustness, and compact nature of the extracted LTVMs from several long-term robot datasets.
* 6 pages
MP Twitter Engagement and Abuse Post-first COVID-19 Lockdown in the UK: White Paper
Mar 08, 2021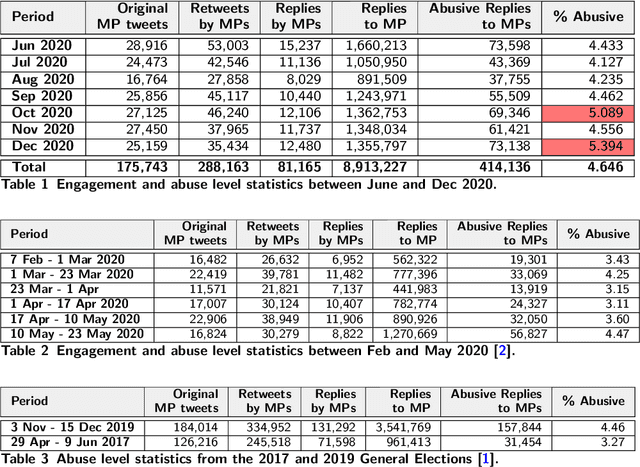
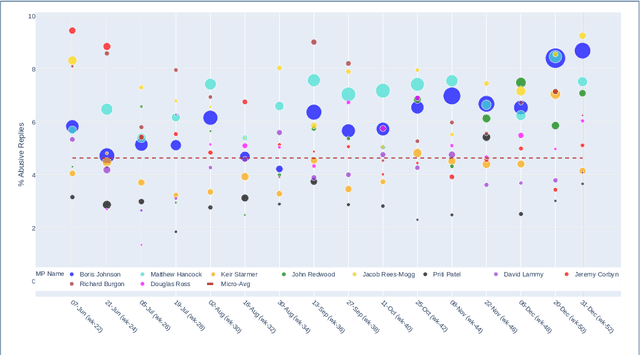
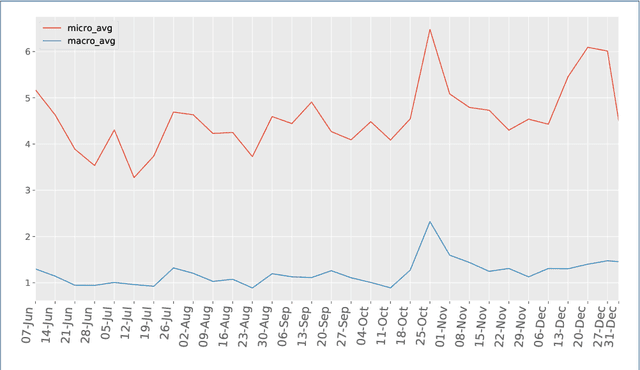
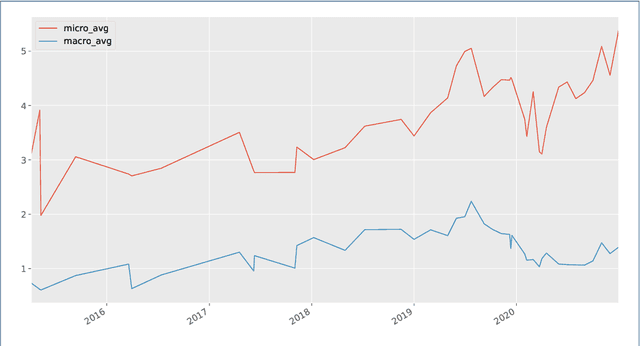
The UK has had a volatile political environment for some years now, with Brexit and leadership crises marking the past five years. With this work, we wanted to understand more about how the global health emergency, COVID-19, influences the amount, type or topics of abuse that UK politicians receive when engaging with the public. With this work, we wanted to understand more about how the global health emergency, COVID-19, influences the amount, type or topics of abuse that UK politicians receive when engaging with the public. This work covers the period of June to December 2020 and analyses Twitter abuse in replies to UK MPs. This work is a follow-up from our analysis of online abuse during the first four months of the COVID-19 pandemic in the UK. The paper examines overall abuse levels during this new seven month period, analyses reactions to members of different political parties and the UK government, and the relationship between online abuse and topics such as Brexit, government's COVID-19 response and policies, and social issues. In addition, we have also examined the presence of conspiracy theories posted in abusive replies to MPs during the period. We have found that abuse levels toward UK MPs were at an all-time high in December 2020 (5.4% of all reply tweets sent to MPs). This is almost 1% higher that the two months preceding the General Election. In a departure from the trend seen in the first four months of the pandemic, MPs from the Tory party received the highest percentage of abusive replies from July 2020 onward, which stays above 5% starting from September 2020 onward, as the COVID-19 crisis deepened and the Brexit negotiations with the EU started nearing completion.