 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Normalized Convolution Upsampling for Refined Optical Flow Estimation
Feb 13, 2021
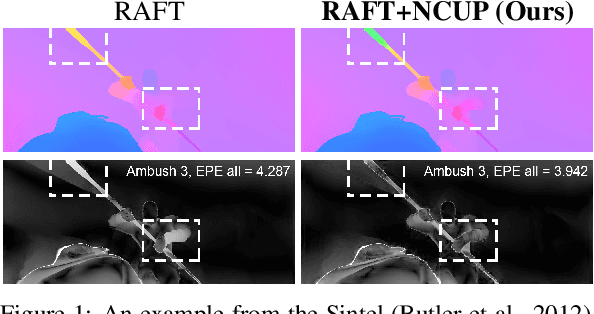
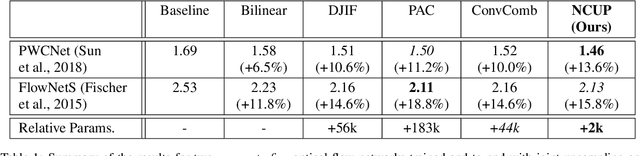
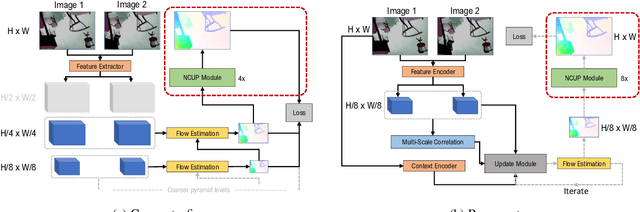
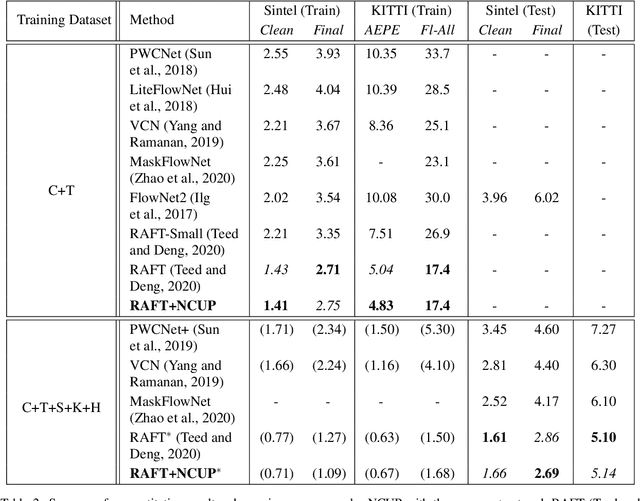
Optical flow is a regression task where convolutional neural networks (CNNs) have led to major breakthroughs. However, this comes at major computational demands due to the use of cost-volumes and pyramidal representations. This was mitigated by producing flow predictions at quarter the resolution, which are upsampled using bilinear interpolation during test time. Consequently, fine details are usually lost and post-processing is needed to restore them. We propose the Normalized Convolution UPsampler (NCUP), an efficient joint upsampling approach to produce the full-resolution flow during the training of optical flow CNNs. Our proposed approach formulates the upsampling task as a sparse problem and employs the normalized convolutional neural networks to solve it. We evaluate our upsampler against existing joint upsampling approaches when trained end-to-end with a a coarse-to-fine optical flow CNN (PWCNet) and we show that it outperforms all other approaches on the FlyingChairs dataset while having at least one order fewer parameters. Moreover, we test our upsampler with a recurrent optical flow CNN (RAFT) and we achieve state-of-the-art results on Sintel benchmark with ~6% error reduction, and on-par on the KITTI dataset, while having 7.5% fewer parameters (see Figure 1). Finally, our upsampler shows better generalization capabilities than RAFT when trained and evaluated on different datasets.
A Neural Few-Shot Text Classification Reality Check
Jan 28, 2021Modern classification models tend to struggle when the amount of annotated data is scarce. To overcome this issue, several neural few-shot classification models have emerged, yielding significant progress over time, both in Computer Vision and Natural Language Processing. In the latter, such models used to rely on fixed word embeddings before the advent of transformers. Additionally, some models used in Computer Vision are yet to be tested in NLP applications. In this paper, we compare all these models, first adapting those made in the field of image processing to NLP, and second providing them access to transformers. We then test these models equipped with the same transformer-based encoder on the intent detection task, known for having a large number of classes. Our results reveal that while methods perform almost equally on the ARSC dataset, this is not the case for the Intent Detection task, where the most recent and supposedly best competitors perform worse than older and simpler ones (while all are given access to transformers). We also show that a simple baseline is surprisingly strong. All the new developed models, as well as the evaluation framework, are made publicly available.
Fail-Aware LIDAR-Based Odometry for Autonomous Vehicles
Mar 05, 2021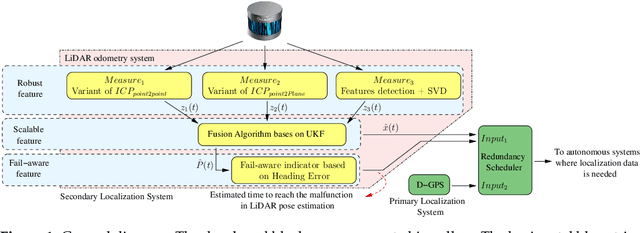
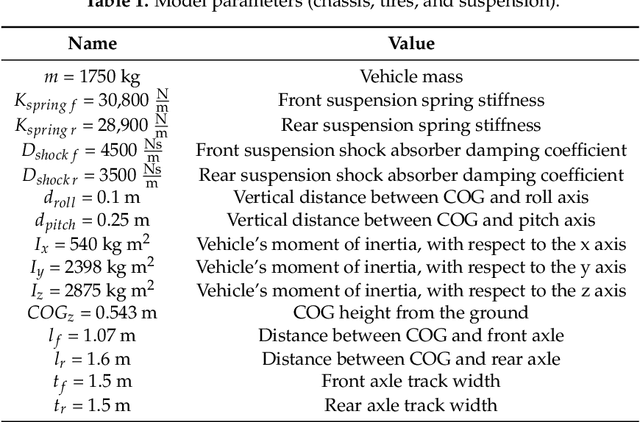
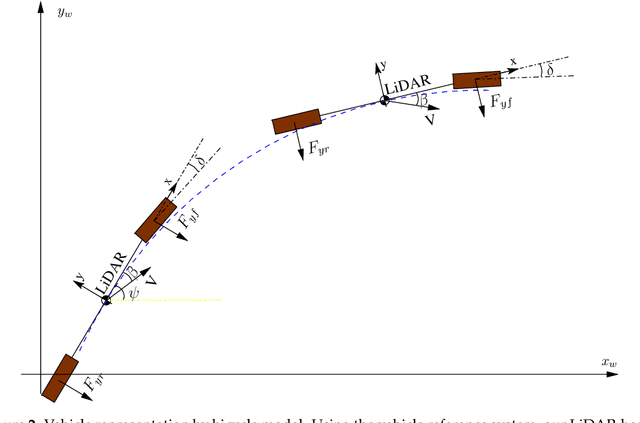
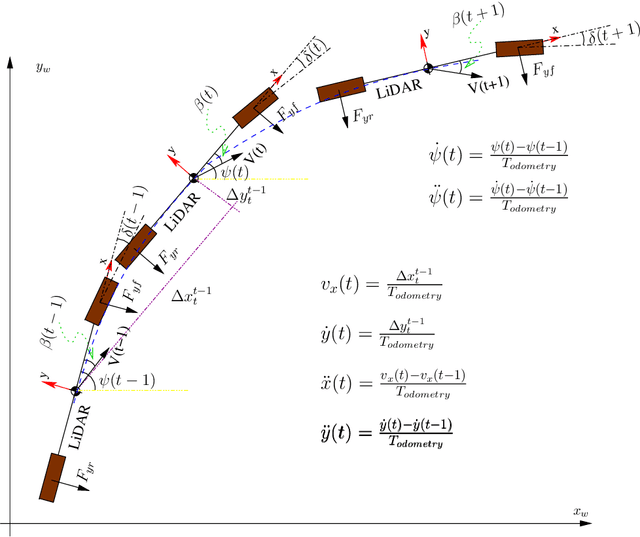
Autonomous driving systems are set to become a reality in transport systems and, so, maximum acceptance is being sought among users. Currently, the most advanced architectures require driver intervention when functional system failures or critical sensor operations take place, presenting problems related to driver state, distractions, fatigue, and other factors that prevent safe control. Therefore, this work presents a redundant, accurate, robust, and scalable LiDAR odometry system with fail-aware system features that can allow other systems to perform a safe stop manoeuvre without driver mediation. All odometry systems have drift error, making it difficult to use them for localisation tasks over extended periods. For this reason, the paper presents an accurate LiDAR odometry system with a fail-aware indicator. This indicator estimates a time window in which the system manages the localisation tasks appropriately. The odometry error is minimised by applying a dynamic 6-DoF model and fusing measures based on the Iterative Closest Points (ICP), environment feature extraction, and Singular Value Decomposition (SVD) methods. The obtained results are promising for two reasons: First, in the KITTI odometry data set, the ranking achieved by the proposed method is twelfth, considering only LiDAR-based methods, where its translation and rotation errors are 1.00% and 0.0041 deg/m, respectively. Second, the encouraging results of the fail-aware indicator demonstrate the safety of the proposed LiDAR odometry system. The results depict that, in order to achieve an accurate odometry system, complex models and measurement fusion techniques must be used to improve its behaviour. Furthermore, if an odometry system is to be used for redundant localisation features, it must integrate a fail-aware indicator for use in a safe manner.
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
Jul 30, 2017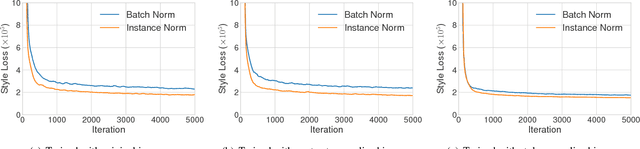

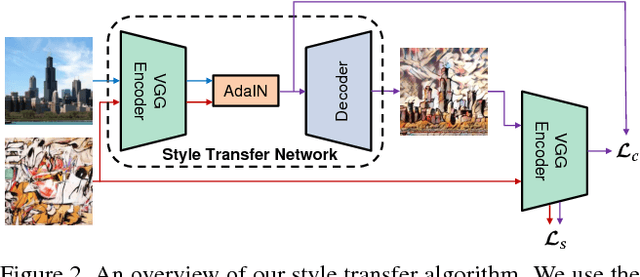
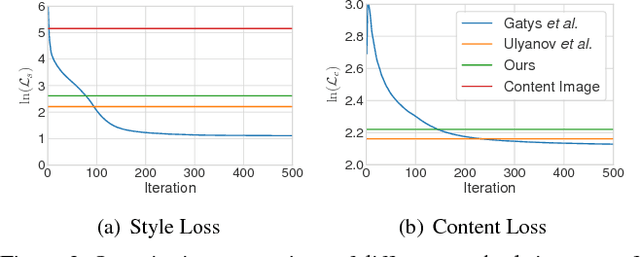
Gatys et al. recently introduced a neural algorithm that renders a content image in the style of another image, achieving so-called style transfer. However, their framework requires a slow iterative optimization process, which limits its practical application. Fast approximations with feed-forward neural networks have been proposed to speed up neural style transfer. Unfortunately, the speed improvement comes at a cost: the network is usually tied to a fixed set of styles and cannot adapt to arbitrary new styles. In this paper, we present a simple yet effective approach that for the first time enables arbitrary style transfer in real-time. At the heart of our method is a novel adaptive instance normalization (AdaIN) layer that aligns the mean and variance of the content features with those of the style features. Our method achieves speed comparable to the fastest existing approach, without the restriction to a pre-defined set of styles. In addition, our approach allows flexible user controls such as content-style trade-off, style interpolation, color & spatial controls, all using a single feed-forward neural network.
TTVOS: Lightweight Video Object Segmentation with Adaptive Template Attention Module and Temporal Consistency Loss
Nov 09, 2020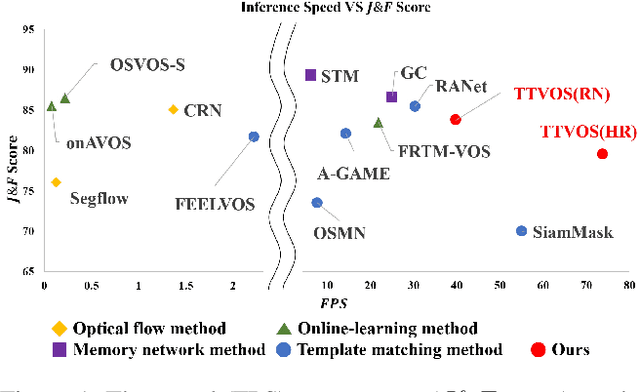
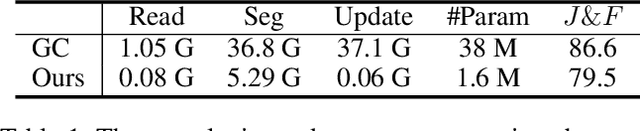
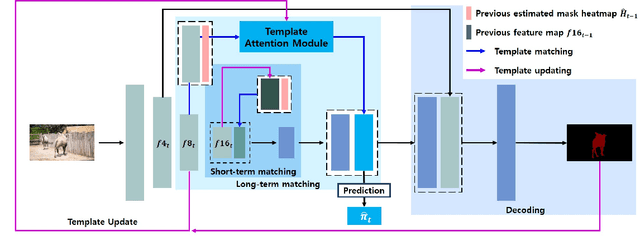
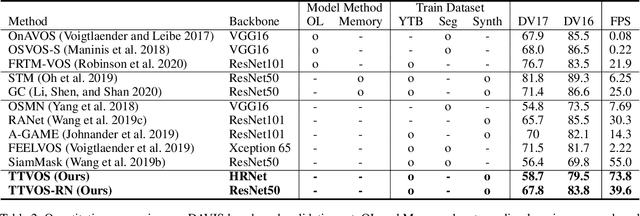
Semi-supervised video object segmentation (semi-VOS) is widely used in many applications. This task is tracking class-agnostic objects by a given segmentation mask. For doing this, various approaches have been developed based on optical flow, online-learning, and memory networks. These methods show high accuracy but are hard to be utilized in real-world applications due to slow inference time and tremendous complexity. To resolve this problem, template matching methods are devised for fast processing speed, sacrificing lots of performance. We introduce a novel semi-VOS model based on a temple matching method and a novel temporal consistency loss to reduce the performance gap from heavy models while expediting inference time a lot. Our temple matching method consists of short-term and long-term matching. The short-term matching enhances target object localization, while long-term matching improves fine details and handles object shape-changing through the newly proposed adaptive template attention module. However, the long-term matching causes error-propagation due to the inflow of the past estimated results when updating the template. To mitigate this problem, we also propose a temporal consistency loss for better temporal coherence between neighboring frames by adopting the concept of a transition matrix. Our model obtains 79.5% J&F score at the speed of 73.8 FPS on the DAVIS16 benchmark.
Exploring the Impact of Tunable Agents in Sequential Social Dilemmas
Jan 28, 2021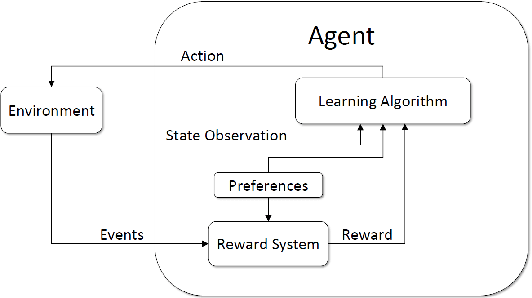
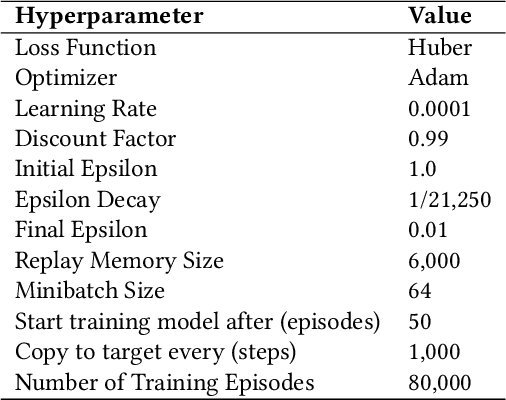
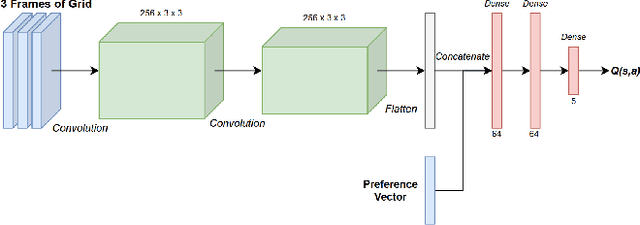

When developing reinforcement learning agents, the standard approach is to train an agent to converge to a fixed policy that is as close to optimal as possible for a single fixed reward function. If different agent behaviour is required in the future, an agent trained in this way must normally be either fully or partially retrained, wasting valuable time and resources. In this study, we leverage multi-objective reinforcement learning to create tunable agents, i.e. agents that can adopt a range of different behaviours according to the designer's preferences, without the need for retraining. We apply this technique to sequential social dilemmas, settings where there is inherent tension between individual and collective rationality. Learning a single fixed policy in such settings leaves one at a significant disadvantage if the opponents' strategies change after learning is complete. In our work, we demonstrate empirically that the tunable agents framework allows easy adaption between cooperative and competitive behaviours in sequential social dilemmas without the need for retraining, allowing a single trained agent model to be adjusted to cater for a wide range of behaviours and opponent strategies.
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
Oct 12, 2020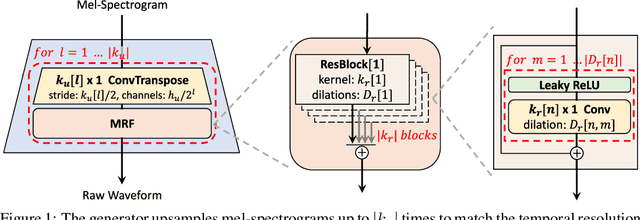
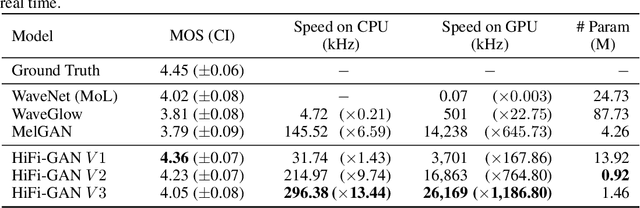
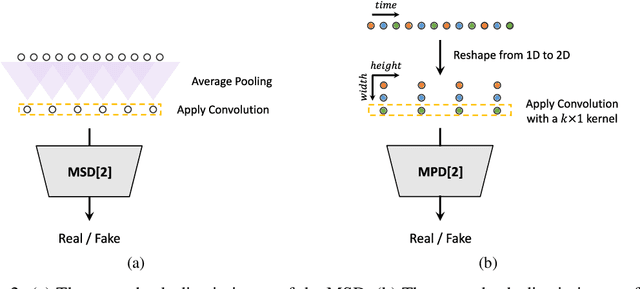
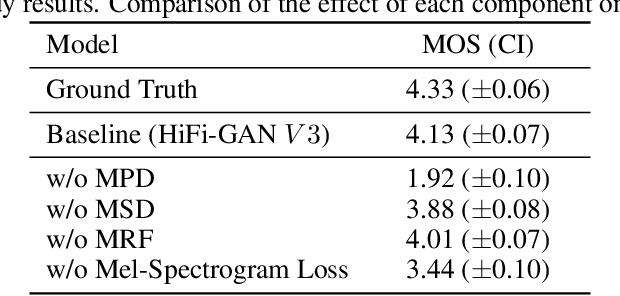
Several recent studies on speech synthesis have employed generative adversarial networks (GANs) to produce raw waveforms. Although such methods improve the sampling efficiency and memory usage, their sample quality has not yet reached that of autoregressive and flow-based generative models. In this study, we propose HiFi-GAN, which achieves both efficient and high-fidelity speech synthesis. As speech audio consists of sinusoidal signals with various periods, we demonstrate that modeling periodic patterns of an audio is crucial for enhancing sample quality. A subjective human evaluation (mean opinion score, MOS) of a single speaker dataset indicates that our proposed method demonstrates similarity to human quality while generating 22.05 kHz high-fidelity audio 167.9 times faster than real-time on a single V100 GPU. We further show the generality of HiFi-GAN to the mel-spectrogram inversion of unseen speakers and end-to-end speech synthesis. Finally, a small footprint version of HiFi-GAN generates samples 13.4 times faster than real time on CPU with comparable quality to an autoregressive counterpart.
Deep Learning-based Resource Allocation For Device-to-Device Communication
Nov 25, 2020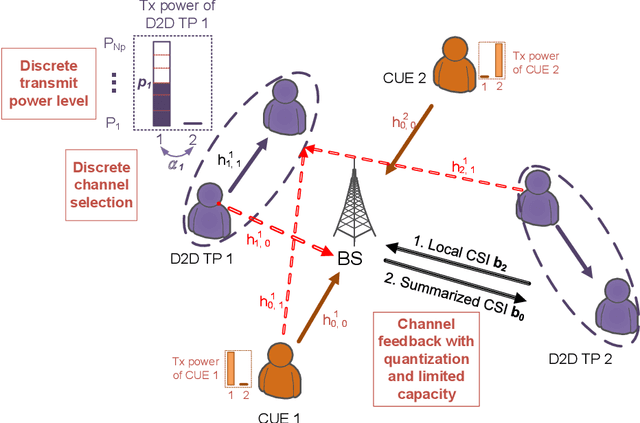
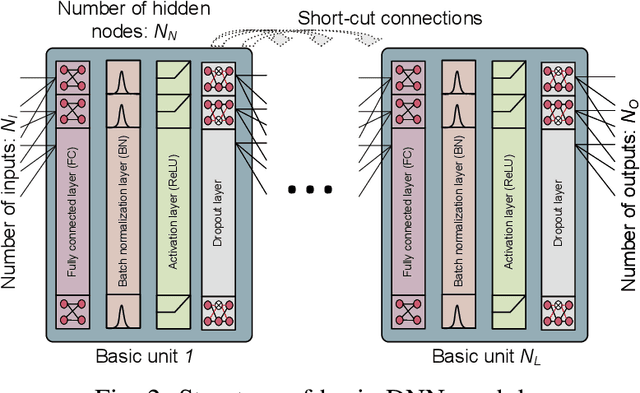
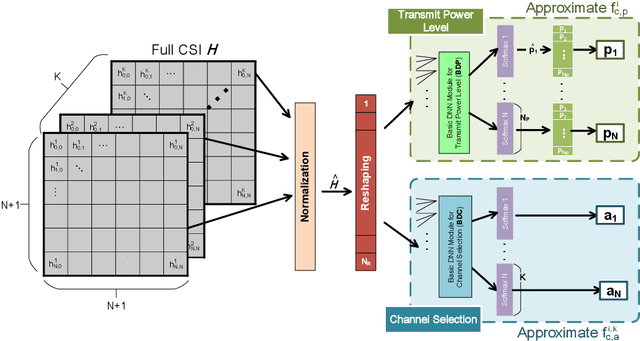
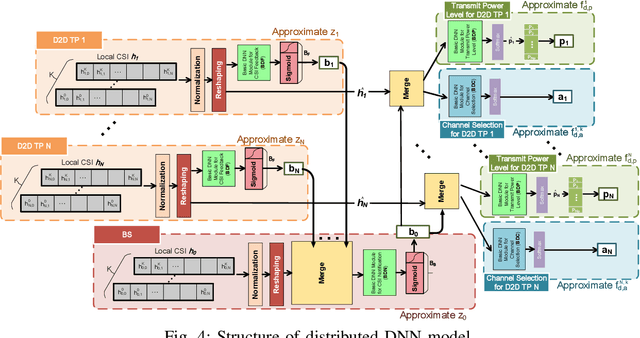
In this paper, a deep learning (DL) framework for the optimization of the resource allocation in multi-channel cellular systems with device-to-device (D2D) communication is proposed. Thereby, the channel assignment and discrete transmit power levels of the D2D users, which are both integer variables, are optimized to maximize the overall spectral efficiency whilst maintaining the quality-of-service (QoS) of the cellular users. Depending on the availability of channel state information (CSI), two different configurations are considered, namely 1) centralized operation with full CSI and 2) distributed operation with partial CSI, where in the latter case, the CSI is encoded according to the capacity of the feedback channel. Instead of solving the resulting resource allocation problem for each channel realization, a DL framework is proposed, where the optimal resource allocation strategy for arbitrary channel conditions is approximated by deep neural network (DNN) models. Furthermore, we propose a new training strategy that combines supervised and unsupervised learning methods and a local CSI sharing strategy to achieve near-optimal performance while enforcing the QoS constraints of the cellular users and efficiently handling the integer optimization variables based on a few ground-truth labels. Our simulation results confirm that near-optimal performance can be attained with low computation time, which underlines the real-time capability of the proposed scheme. Moreover, our results show that not only the resource allocation strategy but also the CSI encoding strategy can be efficiently determined using a DNN. Furthermore, we show that the proposed DL framework can be easily extended to communications systems with different design objectives.
Behavior of linear L2-boosting algorithms in the vanishing learning rate asymptotic
Dec 29, 2020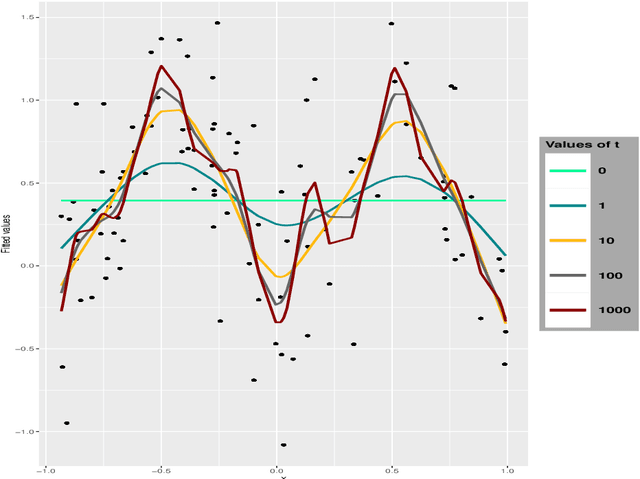
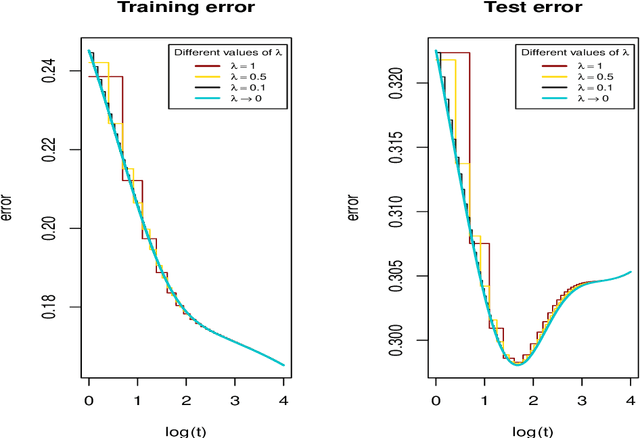
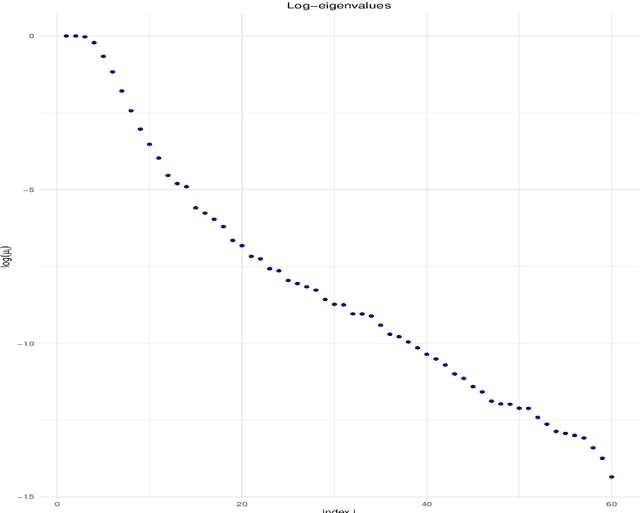
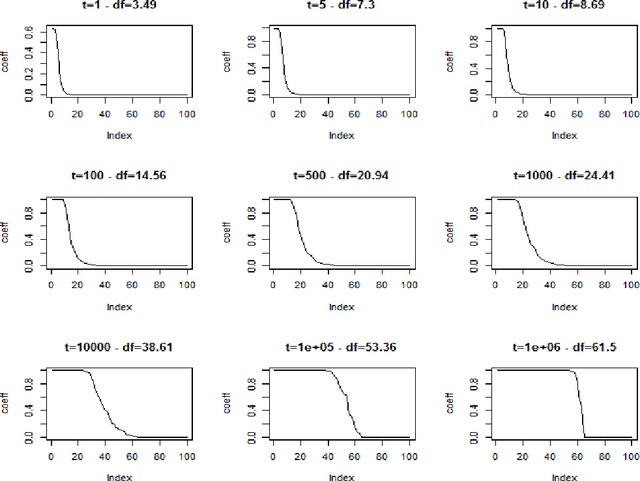
We investigate the asymptotic behaviour of gradient boosting algorithms when the learning rate converges to zero and the number of iterations is rescaled accordingly. We mostly consider L2-boosting for regression with linear base learner as studied in B{\"u}hlmann and Yu (2003) and analyze also a stochastic version of the model where subsampling is used at each step (Friedman 2002). We prove a deterministic limit in the vanishing learning rate asymptotic and characterize the limit as the unique solution of a linear differential equation in an infinite dimensional function space. Besides, the training and test error of the limiting procedure are thoroughly analyzed. We finally illustrate and discuss our result on a simple numerical experiment where the linear L2-boosting operator is interpreted as a smoothed projection and time is related to its number of degrees of freedom.
D${}^3$TW: Discriminative Differentiable Dynamic Time Warping for Weakly Supervised Action Alignment and Segmentation
Jan 09, 2019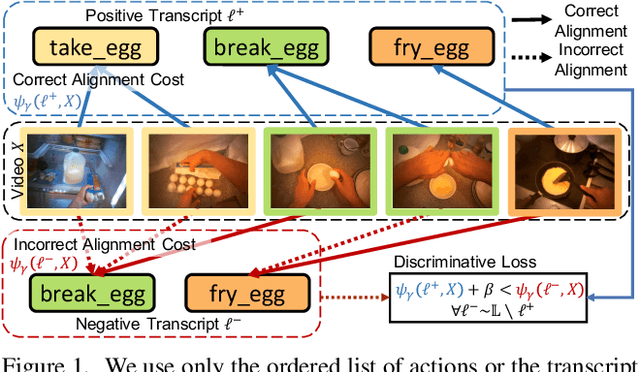
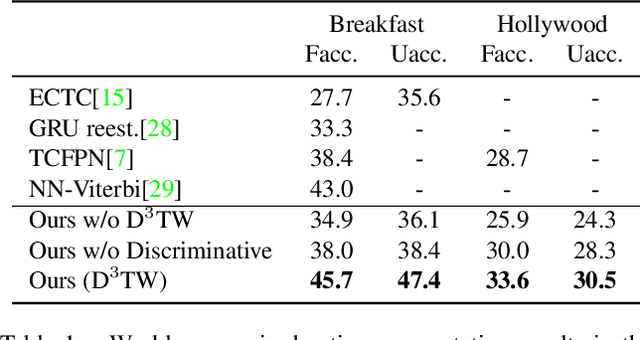
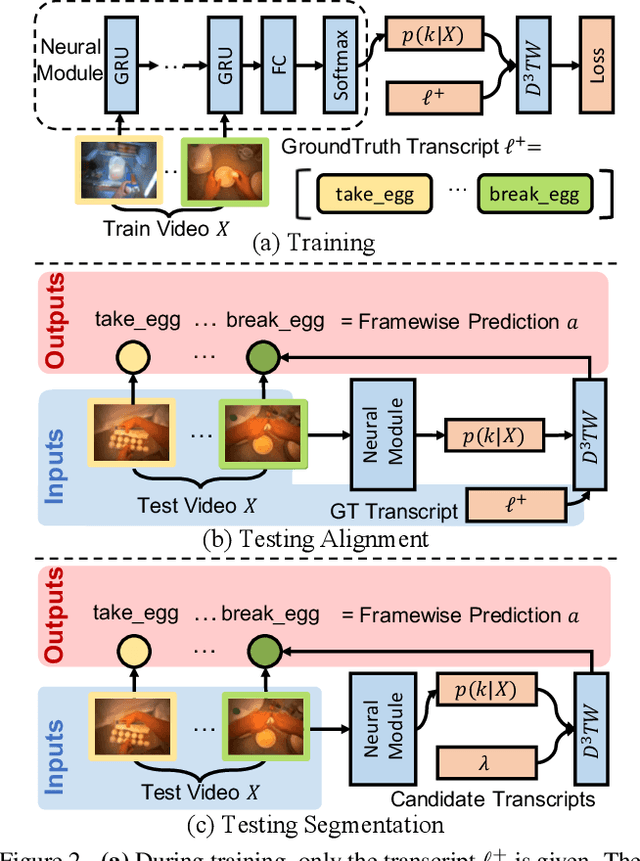
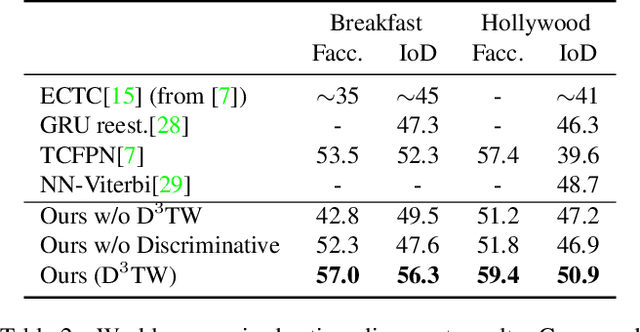
We address weakly-supervised action alignment and segmentation in videos, where only the order of occurring actions is available during training. We propose Discriminative Differentiable Dynamic Time Warping (D${}^3$TW), which is the first discriminative model for weak ordering supervision. This allows us to bypass the degenerated sequence problem usually encountered in previous work. The key technical challenge for discriminative modeling with weak-supervision is that the loss function of the ordering supervision is usually formulated using dynamic programming and is thus not differentiable. We address this challenge by continuous relaxation of the min-operator in dynamic programming and extend the DTW alignment loss to be differentiable. The proposed D${}^3$TW innovatively solves sequence alignment with discriminative modeling and end-to-end training, which substantially improves the performance in weakly supervised action alignment and segmentation tasks. We show that our model outperforms the current state-of-the-art across three evaluation metrics in two challenging datasets.