 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Cascaded Residual UNET for Fully Automated Segmentation of Prostate and Peripheral Zone in T2-weighted 3D Fast Spin Echo Images
Dec 25, 2020
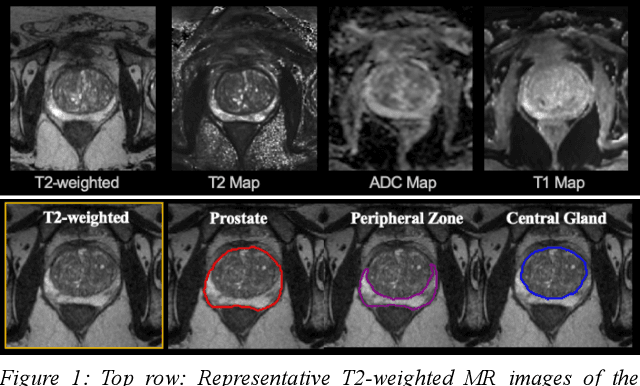

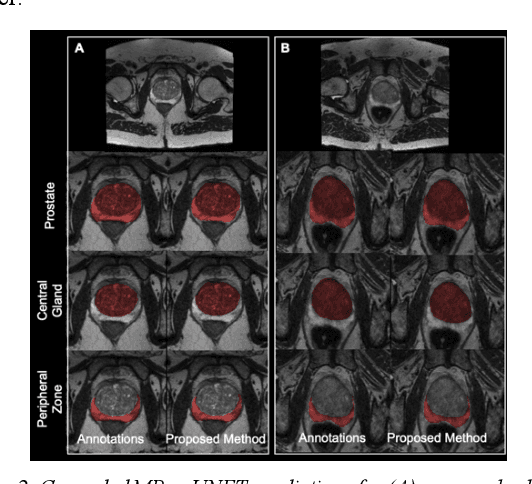
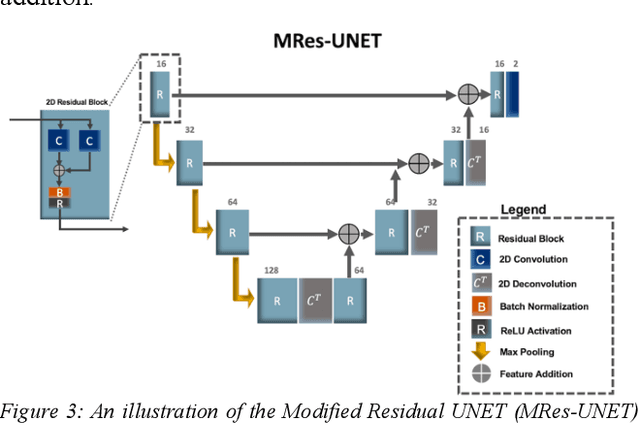
Multi-parametric MR images have been shown to be effective in the non-invasive diagnosis of prostate cancer. Automated segmentation of the prostate eliminates the need for manual annotation by a radiologist which is time consuming. This improves efficiency in the extraction of imaging features for the characterization of prostate tissues. In this work, we propose a fully automated cascaded deep learning architecture with residual blocks, Cascaded MRes-UNET, for segmentation of the prostate gland and the peripheral zone in one pass through the network. The network yields high Dice scores ($0.91\pm.02$), precision ($0.91\pm.04$), and recall scores ($0.92\pm.03$) in prostate segmentation compared to manual annotations by an experienced radiologist. The average difference in total prostate volume estimation is less than 5%.
Mesh Reconstruction from Aerial Images for Outdoor Terrain Mapping Using Joint 2D-3D Learning
Jan 06, 2021
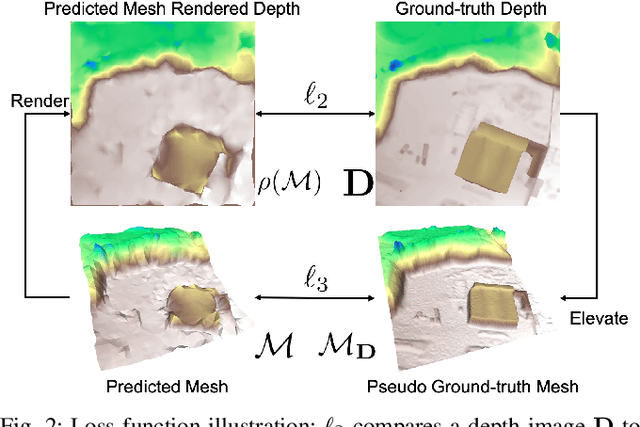
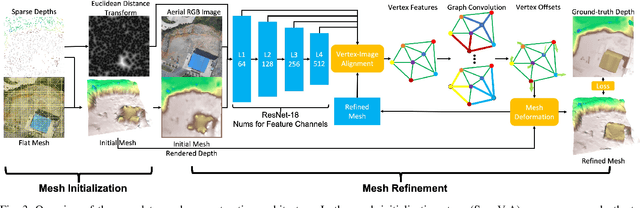
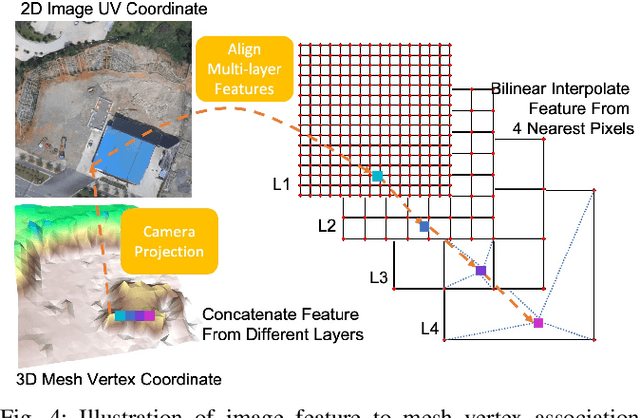
This paper addresses outdoor terrain mapping using overhead images obtained from an unmanned aerial vehicle. Dense depth estimation from aerial images during flight is challenging. While feature-based localization and mapping techniques can deliver real-time odometry and sparse points reconstruction, a dense environment model is generally recovered offline with significant computation and storage. This paper develops a joint 2D-3D learning approach to reconstruct local meshes at each camera keyframe, which can be assembled into a global environment model. Each local mesh is initialized from sparse depth measurements. We associate image features with the mesh vertices through camera projection and apply graph convolution to refine the mesh vertices based on joint 2-D reprojected depth and 3-D mesh supervision. Quantitative and qualitative evaluations using real aerial images show the potential of our method to support environmental monitoring and surveillance applications.
Towards Searching Efficient and Accurate Neural Network Architectures in Binary Classification Problems
Jan 16, 2021
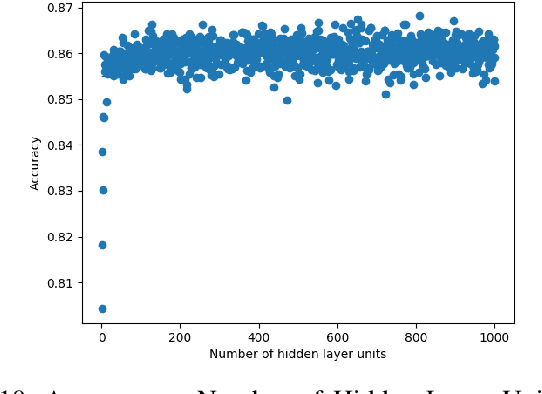
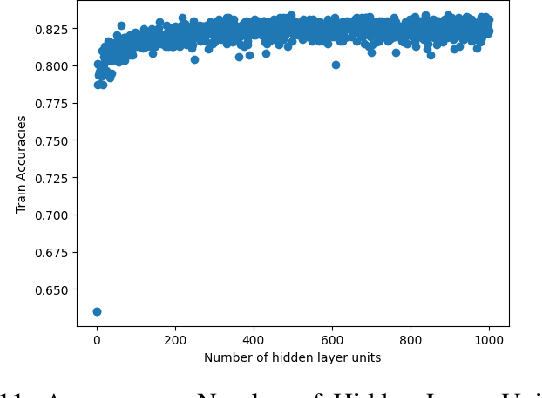
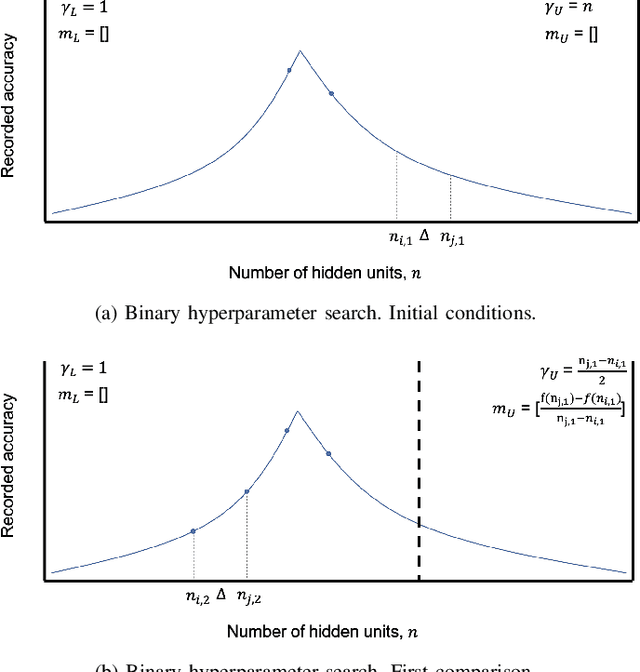
In recent years, deep neural networks have had great success in machine learning and pattern recognition. Architecture size for a neural network contributes significantly to the success of any neural network. In this study, we optimize the selection process by investigating different search algorithms to find a neural network architecture size that yields the highest accuracy. We apply binary search on a very well-defined binary classification network search space and compare the results to those of linear search. We also propose how to relax some of the assumptions regarding the dataset so that our solution can be generalized to any binary classification problem. We report a 100-fold running time improvement over the naive linear search when we apply the binary search method to our datasets in order to find the best architecture candidate. By finding the optimal architecture size for any binary classification problem quickly, we hope that our research contributes to discovering intelligent algorithms for optimizing architecture size selection in machine learning.
Instance-based learning using the Half-Space Proximal Graph
Feb 04, 2021
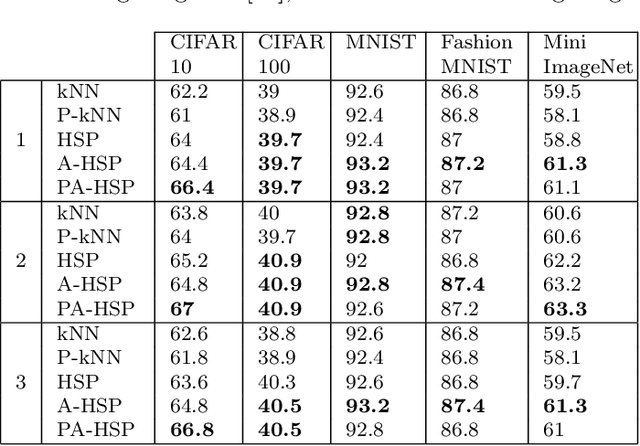
The primary example of instance-based learning is the $k$-nearest neighbor rule (kNN), praised for its simplicity and the capacity to adapt to new unseen data and toss away old data. The main disadvantages often mentioned are the classification complexity, which is $O(n)$, and the estimation of the parameter $k$, the number of nearest neighbors to be used. The use of indexes at classification time lifts the former disadvantage, while there is no conclusive method for the latter. This paper presents a parameter-free instance-based learning algorithm using the {\em Half-Space Proximal} (HSP) graph. The HSP neighbors simultaneously possess proximity and variety concerning the center node. To classify a given query, we compute its HSP neighbors and apply a simple majority rule over them. In our experiments, the resulting classifier bettered $KNN$ for any $k$ in a battery of datasets. This improvement sticks even when applying weighted majority rules to both kNN and HSP classifiers. Surprisingly, when using a probabilistic index to approximate the HSP graph and consequently speeding-up the classification task, our method could {\em improve} its accuracy in stark contrast with the kNN classifier, which worsens with a probabilistic index.
Temporal Knowledge Base Completion: New Algorithms and Evaluation Protocols
May 02, 2020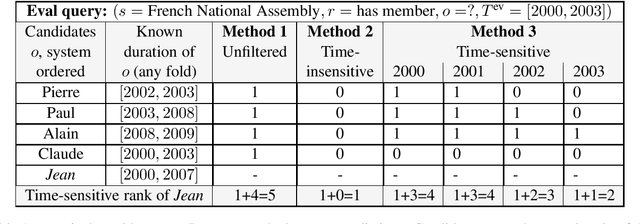
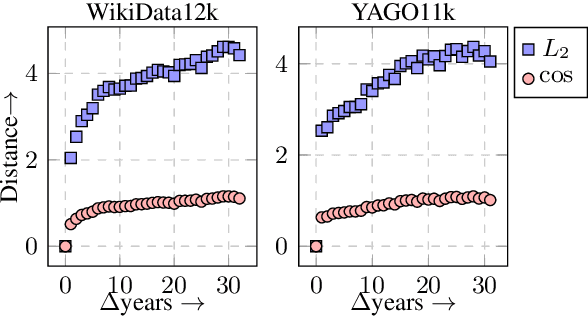
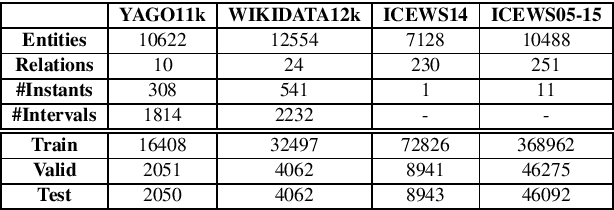
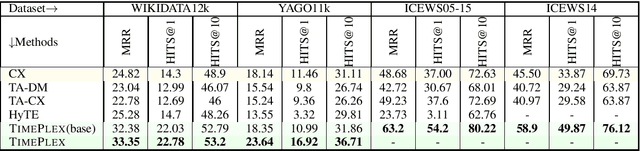
Temporal knowledge bases associate relational (s,r,o) triples with a set of times (or a single time instant) when the relation is valid. While time-agnostic KB completion (KBC) has witnessed significant research, temporal KB completion (TKBC) is in its early days. In this paper, we consider predicting missing entities (link prediction) and missing time intervals (time prediction) as joint TKBC tasks where entities, relations, and time are all embedded in a uniform, compatible space. We present TIMEPLEX, a novel time-aware KBC method, that also automatically exploits the recurrent nature of some relations and temporal interactions between pairs of relations. TIMEPLEX achieves state-of-the-art performance on both prediction tasks. We also find that existing TKBC models heavily overestimate link prediction performance due to imperfect evaluation mechanisms. In response, we propose improved TKBC evaluation protocols for both link and time prediction tasks, dealing with subtle issues that arise from the partial overlap of time intervals in gold instances and system predictions.
Multi-Domain Image-to-Image Translation with Adaptive Inference Graph
Jan 11, 2021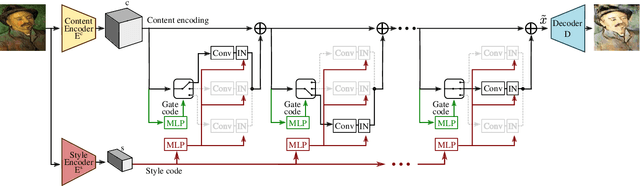



In this work, we address the problem of multi-domain image-to-image translation with particular attention paid to computational cost. In particular, current state of the art models require a large and deep model in order to handle the visual diversity of multiple domains. In a context of limited computational resources, increasing the network size may not be possible. Therefore, we propose to increase the network capacity by using an adaptive graph structure. At inference time, the network estimates its own graph by selecting specific sub-networks. Sub-network selection is implemented using Gumbel-Softmax in order to allow end-to-end training. This approach leads to an adjustable increase in number of parameters while preserving an almost constant computational cost. Our evaluation on two publicly available datasets of facial and painting images shows that our adaptive strategy generates better images with fewer artifacts than literature methods
Streaming Simultaneous Speech Translation with Augmented Memory Transformer
Oct 30, 2020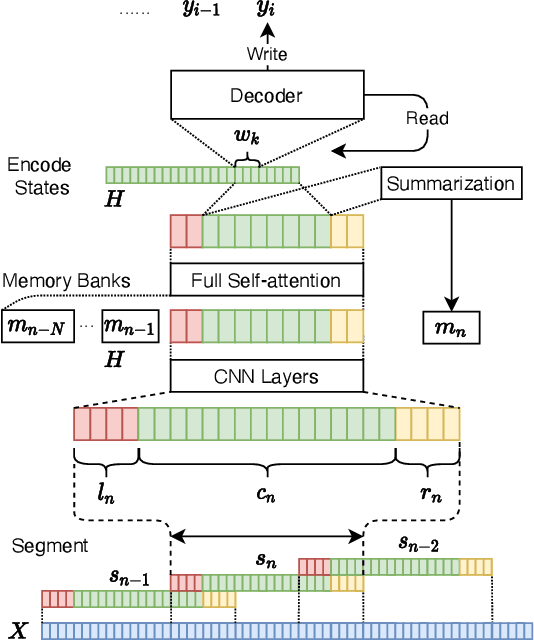
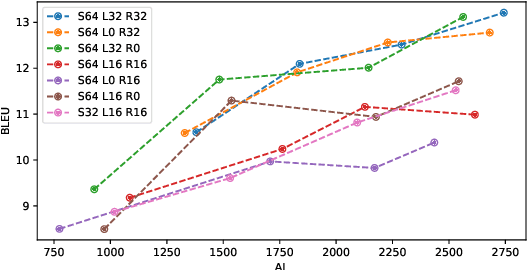
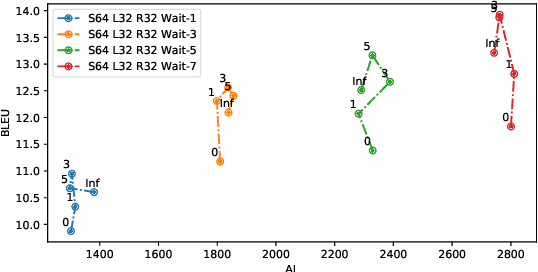
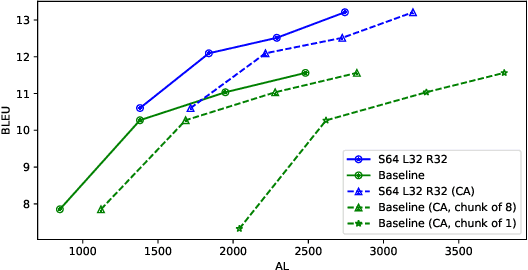
Transformer-based models have achieved state-of-the-art performance on speech translation tasks. However, the model architecture is not efficient enough for streaming scenarios since self-attention is computed over an entire input sequence and the computational cost grows quadratically with the length of the input sequence. Nevertheless, most of the previous work on simultaneous speech translation, the task of generating translations from partial audio input, ignores the time spent in generating the translation when analyzing the latency. With this assumption, a system may have good latency quality trade-offs but be inapplicable in real-time scenarios. In this paper, we focus on the task of streaming simultaneous speech translation, where the systems are not only capable of translating with partial input but are also able to handle very long or continuous input. We propose an end-to-end transformer-based sequence-to-sequence model, equipped with an augmented memory transformer encoder, which has shown great success on the streaming automatic speech recognition task with hybrid or transducer-based models. We conduct an empirical evaluation of the proposed model on segment, context and memory sizes and we compare our approach to a transformer with a unidirectional mask.
High Dynamic Range SLAM with Map-Aware Exposure Time Control
Apr 20, 2018
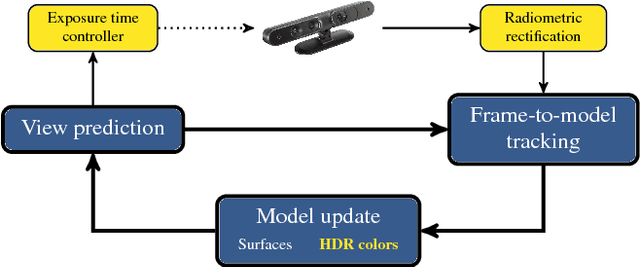
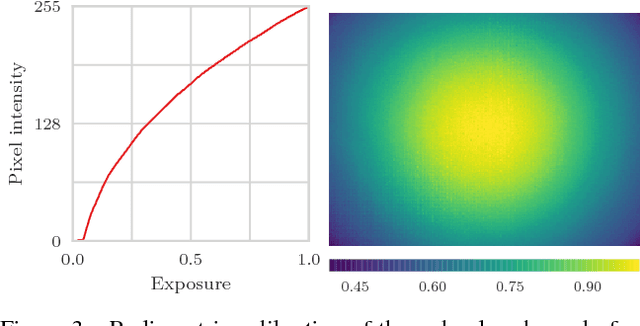
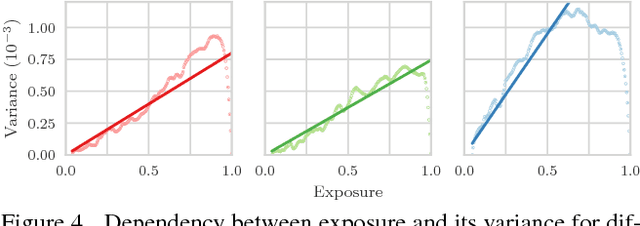
The research in dense online 3D mapping is mostly focused on the geometrical accuracy and spatial extent of the reconstructions. Their color appearance is often neglected, leading to inconsistent colors and noticeable artifacts. We rectify this by extending a state-of-the-art SLAM system to accumulate colors in HDR space. We replace the simplistic pixel intensity averaging scheme with HDR color fusion rules tailored to the incremental nature of SLAM and a noise model suitable for off-the-shelf RGB-D cameras. Our main contribution is a map-aware exposure time controller. It makes decisions based on the global state of the map and predicted camera motion, attempting to maximize the information gain of each observation. We report a set of experiments demonstrating the improved texture quality and advantages of using the custom controller that is tightly integrated in the mapping loop.
Accurate Learning of Graph Representations with Graph Multiset Pooling
Feb 27, 2021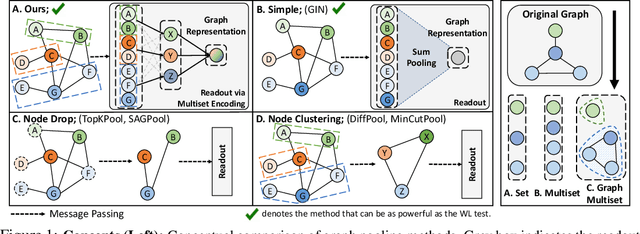
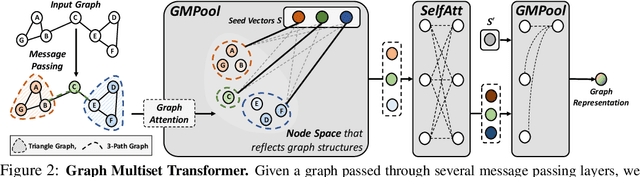
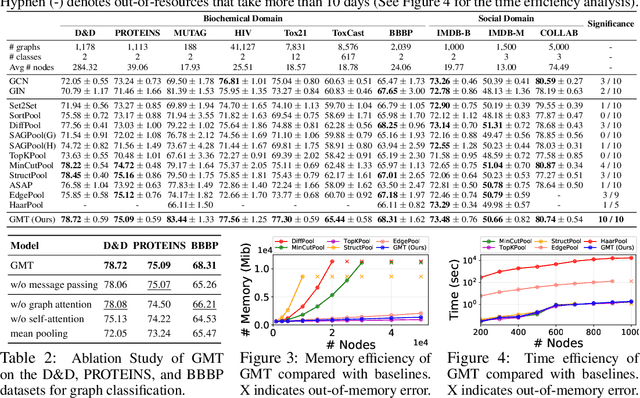
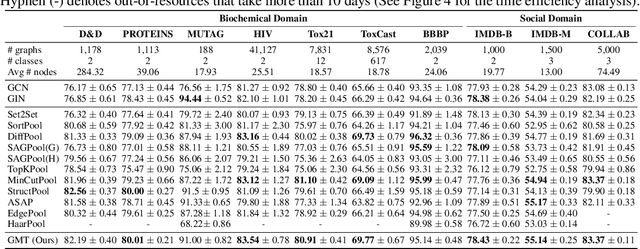
Graph neural networks have been widely used on modeling graph data, achieving impressive results on node classification and link prediction tasks. Yet, obtaining an accurate representation for a graph further requires a pooling function that maps a set of node representations into a compact form. A simple sum or average over all node representations considers all node features equally without consideration of their task relevance, and any structural dependencies among them. Recently proposed hierarchical graph pooling methods, on the other hand, may yield the same representation for two different graphs that are distinguished by the Weisfeiler-Lehman test, as they suboptimally preserve information from the node features. To tackle these limitations of existing graph pooling methods, we first formulate the graph pooling problem as a multiset encoding problem with auxiliary information about the graph structure, and propose a Graph Multiset Transformer (GMT) which is a multi-head attention based global pooling layer that captures the interaction between nodes according to their structural dependencies. We show that GMT satisfies both injectiveness and permutation invariance, such that it is at most as powerful as the Weisfeiler-Lehman graph isomorphism test. Moreover, our methods can be easily extended to the previous node clustering approaches for hierarchical graph pooling. Our experimental results show that GMT significantly outperforms state-of-the-art graph pooling methods on graph classification benchmarks with high memory and time efficiency, and obtains even larger performance gain on graph reconstruction and generation tasks.
Modeling the locomotion of articulated soft robots in granular medium
Mar 06, 2021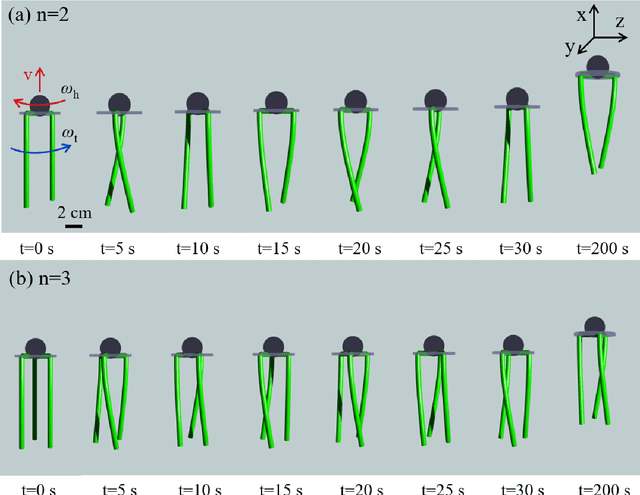

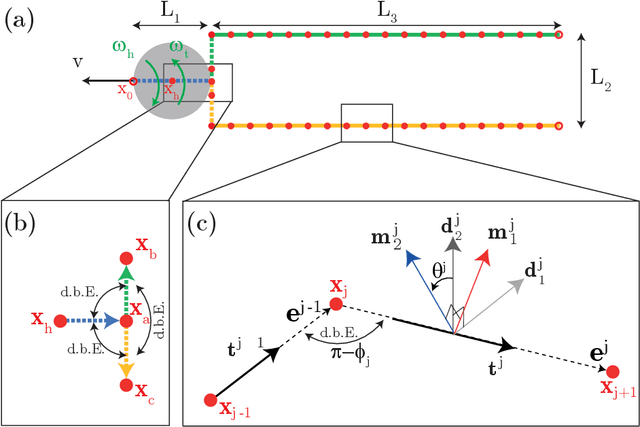
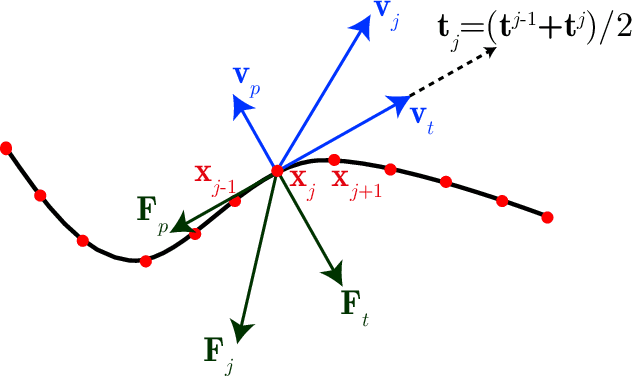
Soft robots, in contrast to their rigid counter parts, have infinite degrees of freedom that are coupled with their interaction with the environment. We consider the locomotion of an untethered robot, in the granular medium, comprised of multiple flexible flagella that rotate about an axis by a motor. Drag from the grains causes the flagella to deform and the deformed shape generates a net forward propulsion. This external drag force depends on the shape of the flagella, while the change in flagellar shape is the result of the competition between the external loading and elastic forces. We introduce a numerical tool that couples discrete differential geometry based simulation of elastic rods - our model for flagella - and a resistive force theory based model for the drag. In parallel with simulations, we conduct experiments to quantify the propulsive speed of this class of robots. We find reasonable quantitative agreement between experiments and simulations. Owing to a rod-based kinematic representation of the robot, the simulation runs faster than real-time, and, therefore, we can use it as a design tool for this class of soft robots. We find that there is an optimal rotational speed at which maximum efficiency is achieved. Moreover, both experiments and simulations show that increasing the number of flagella decreases the speed of the robot. We also gain insight into the mechanics of granular medium - while resistive force theory can successfully describe the propulsion at low number of flagella, it fails when more flagella are added to the robot.