 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Linear-Time Sequence Classification using Restricted Boltzmann Machines
Mar 08, 2018
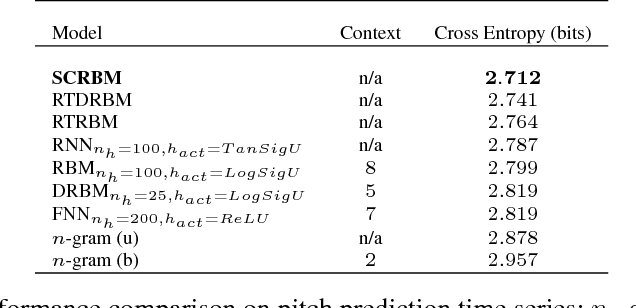
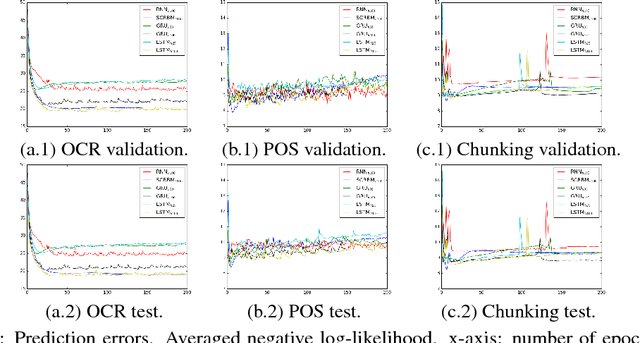

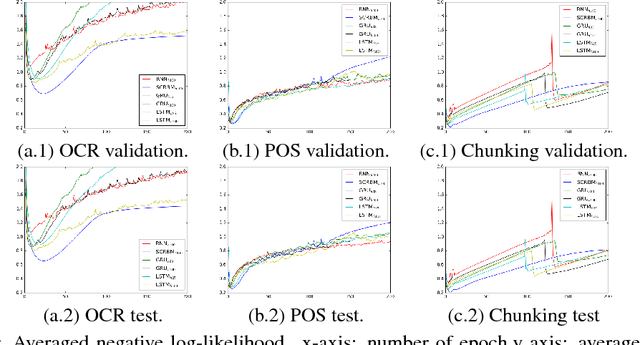
Classification of sequence data is the topic of interest for dynamic Bayesian models and Recurrent Neural Networks (RNNs). While the former can explicitly model the temporal dependencies between class variables, the latter have a capability of learning representations. Several attempts have been made to improve performance by combining these two approaches or increasing the processing capability of the hidden units in RNNs. This often results in complex models with a large number of learning parameters. In this paper, a compact model is proposed which offers both representation learning and temporal inference of class variables by rolling Restricted Boltzmann Machines (RBMs) and class variables over time. We address the key issue of intractability in this variant of RBMs by optimising a conditional distribution, instead of a joint distribution. Experiments reported in the paper on melody modelling and optical character recognition show that the proposed model can outperform the state-of-the-art. Also, the experimental results on optical character recognition, part-of-speech tagging and text chunking demonstrate that our model is comparable to recurrent neural networks with complex memory gates while requiring far fewer parameters.
RRT* Combined with GVO for Real-time Nonholonomic Robot Navigation in Dynamic Environment
Apr 11, 2018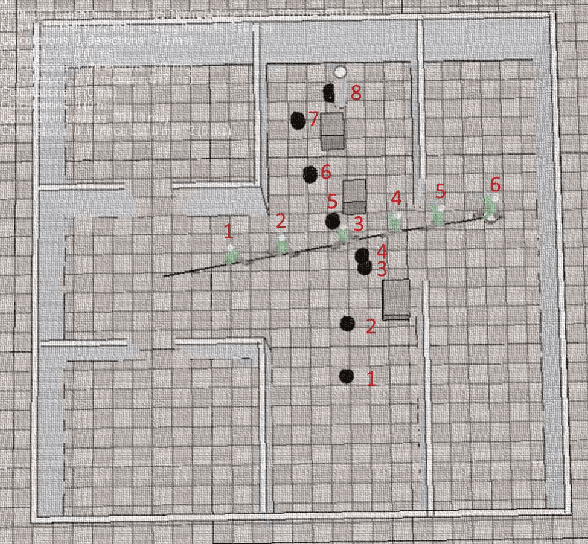
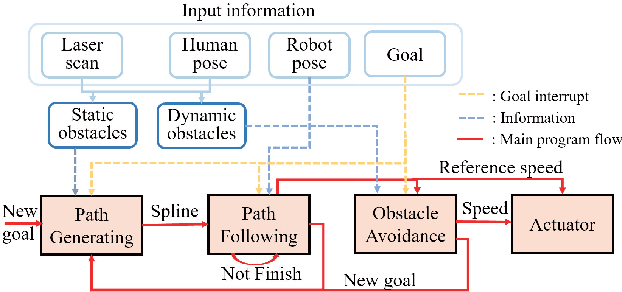
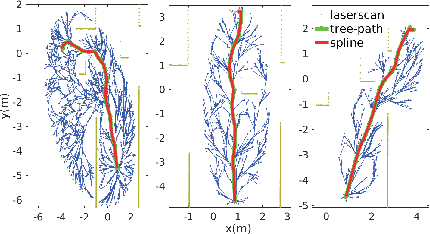
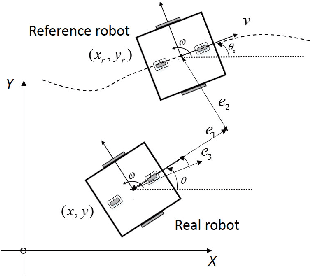
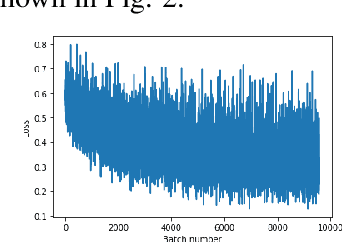
Challenges persist in nonholonomic robot navigation in dynamic environments. This paper presents a framework for such navigation based on the model of generalized velocity obstacles (GVO). The idea of velocity obstacles has been well studied and developed for obstacle avoidance since being proposed in 1998. Though it has been proved to be successful, most studies have assumed equations of motion to be linear, which limits their application to holonomic robots. In addition, more attention has been paid to the immediate reaction of robots, while advance planning has been neglected. By applying the GVO model to differential drive robots and by combining it with RRT*, we reduce the uncertainty of the robot trajectory, thus further reducing the range of concern, and save both computation time and running time. By introducing uncertainty for the dynamic obstacles with a Kalman filter, we dilute the risk of considering the obstacles as uniformly moving along a straight line and guarantee the safety. Special concern is given to path generation, including curvature check, making the generated path feasible for nonholonomic robots. We experimentally demonstrate the feasibility of the framework.
FILM: A Fast, Interpretable, and Low-rank Metric Learning Approach for Sentence Matching
Oct 13, 2020

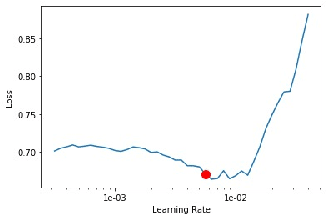
Detection of semantic similarity plays a vital role in sentence matching. It requires to learn discriminative representations of natural language. Recently, owing to more and more sophisticated model architecture, impressive progress has been made, along with a time-consuming training process and not-interpretable inference. To alleviate this problem, we explore a metric learning approach, named FILM (Fast, Interpretable, and Low-rank Metric learning) to efficiently find a high discriminative projection of the high-dimensional data. We construct this metric learning problem as a manifold optimization problem and solve it with the Cayley transformation method with the Barzilai-Borwein step size. In experiments, we apply FILM with triplet loss minimization objective to the Quora Challenge and Semantic Textual Similarity (STS) Task. The results demonstrate that the FILM method achieves superior performance as well as the fastest computation speed, which is consistent with our theoretical analysis of time complexity.
LUCIDGames: Online Unscented Inverse Dynamic Games for Adaptive Trajectory Prediction and Planning
Nov 16, 2020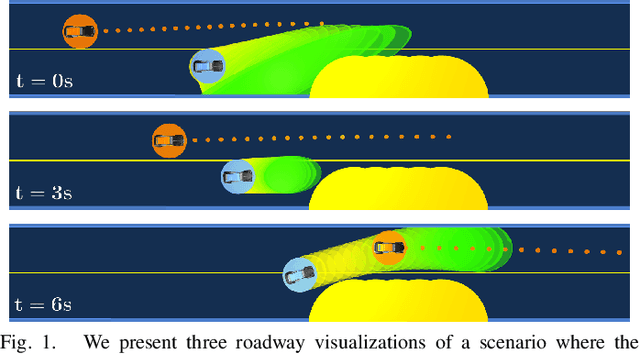
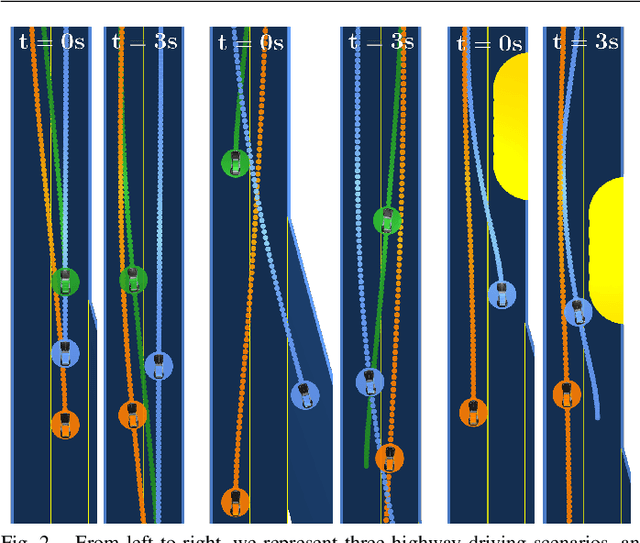
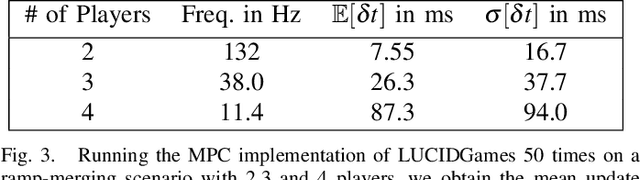
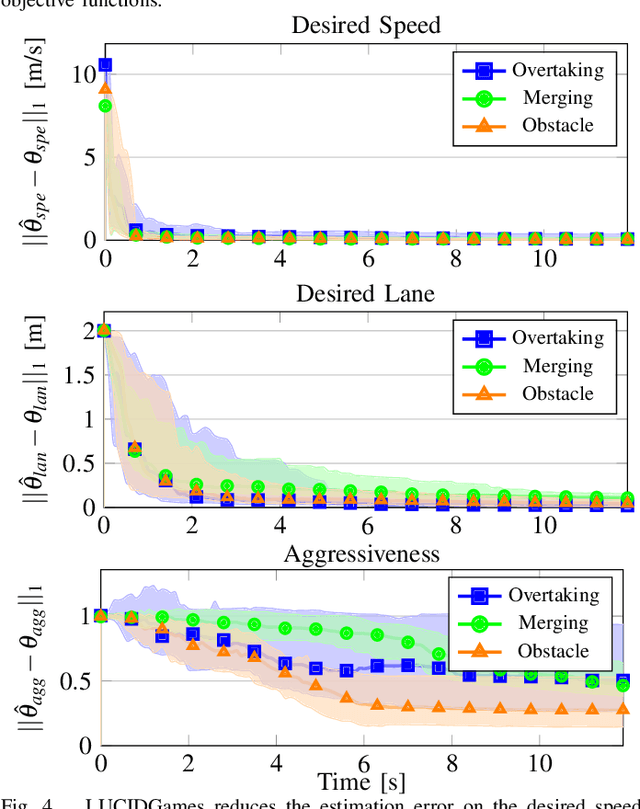
Existing game-theoretic planning methods assume that the robot knows the objective functions of the other agents a priori while, in practical scenarios, this is rarely the case. This paper introduces LUCIDGames, an inverse optimal control algorithm that is able to estimate the other agents' objective functions in real time, and incorporate those estimates online into a receding-horizon game-theoretic planner. LUCIDGames solves the inverse optimal control problem by recasting it in a recursive parameter-estimation framework. LUCIDGames uses an unscented Kalman filter (UKF) to iteratively update a Bayesian estimate of the other agents' cost function parameters, improving that estimate online as more data is gathered from the other agents' observed trajectories. The planner then takes account of the uncertainty in the Bayesian parameter estimates of other agents by planning a trajectory for the robot subject to uncertainty ellipse constraints. The algorithm assumes no explicit communication or coordination between the robot and the other agents in the environment. An MPC implementation of LUCIDGames demonstrates real-time performance on complex autonomous driving scenarios with an update frequency of 40 Hz. Empirical results demonstrate that LUCIDGames improves the robot's performance over existing game-theoretic and traditional MPC planning approaches. Our implementation of LUCIDGames is available at https://github.com/RoboticExplorationLab/LUCIDGames.jl.
Validity of time reversal for testing Granger causality
Feb 11, 2016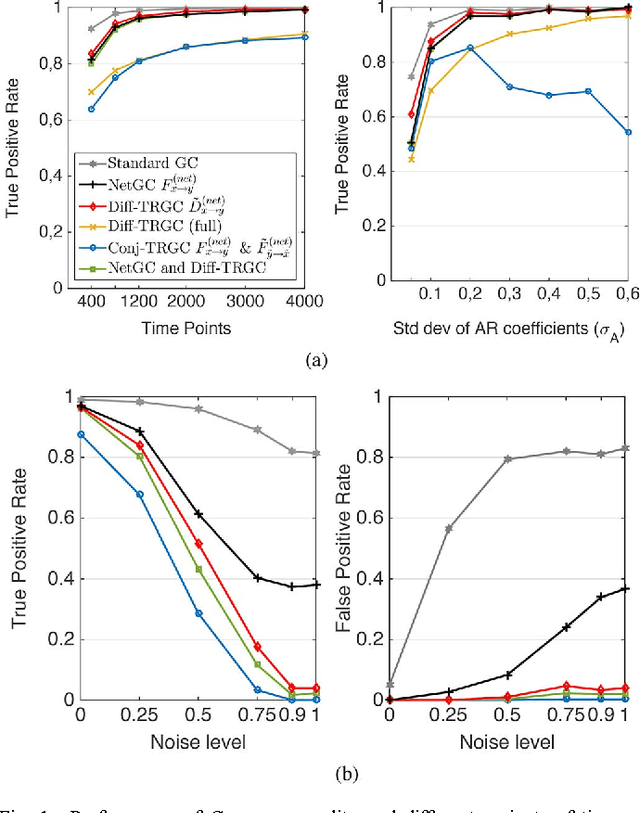
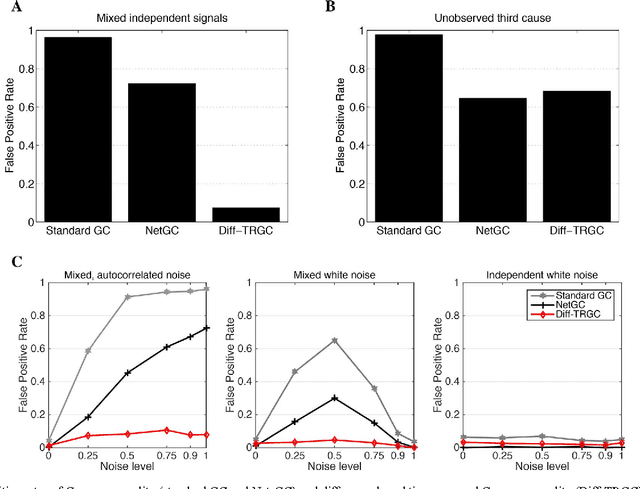
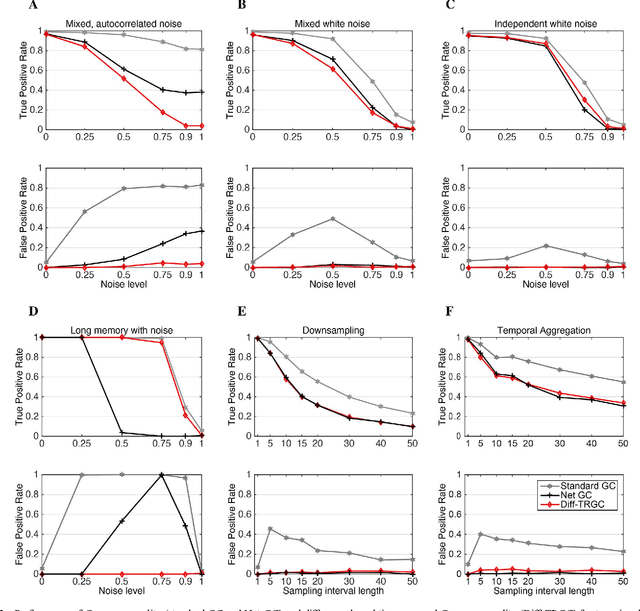
Inferring causal interactions from observed data is a challenging problem, especially in the presence of measurement noise. To alleviate the problem of spurious causality, Haufe et al. (2013) proposed to contrast measures of information flow obtained on the original data against the same measures obtained on time-reversed data. They show that this procedure, time-reversed Granger causality (TRGC), robustly rejects causal interpretations on mixtures of independent signals. While promising results have been achieved in simulations, it was so far unknown whether time reversal leads to valid measures of information flow in the presence of true interaction. Here we prove that, for linear finite-order autoregressive processes with unidirectional information flow, the application of time reversal for testing Granger causality indeed leads to correct estimates of information flow and its directionality. Using simulations, we further show that TRGC is able to infer correct directionality with similar statistical power as the net Granger causality between two variables, while being much more robust to the presence of measurement noise.
Hide-and-Seek Privacy Challenge
Jul 24, 2020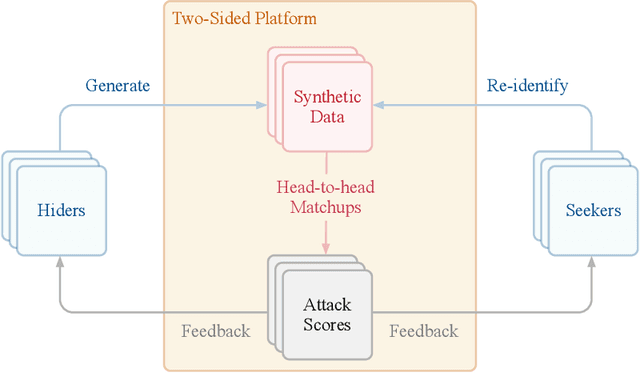
The clinical time-series setting poses a unique combination of challenges to data modeling and sharing. Due to the high dimensionality of clinical time series, adequate de-identification to preserve privacy while retaining data utility is difficult to achieve using common de-identification techniques. An innovative approach to this problem is synthetic data generation. From a technical perspective, a good generative model for time-series data should preserve temporal dynamics, in the sense that new sequences respect the original relationships between high-dimensional variables across time. From the privacy perspective, the model should prevent patient re-identification by limiting vulnerability to membership inference attacks. The NeurIPS 2020 Hide-and-Seek Privacy Challenge is a novel two-tracked competition to simultaneously accelerate progress in tackling both problems. In our head-to-head format, participants in the synthetic data generation track (i.e. "hiders") and the patient re-identification track (i.e. "seekers") are directly pitted against each other by way of a new, high-quality intensive care time-series dataset: the AmsterdamUMCdb dataset. Ultimately, we seek to advance generative techniques for dense and high-dimensional temporal data streams that are (1) clinically meaningful in terms of fidelity and predictivity, as well as (2) capable of minimizing membership privacy risks in terms of the concrete notion of patient re-identification.
Genetic Improvement of Routing Protocols for Delay Tolerant Networks
Mar 12, 2021



Routing plays a fundamental role in network applications, but it is especially challenging in Delay Tolerant Networks (DTNs). These are a kind of mobile ad hoc networks made of e.g. (possibly, unmanned) vehicles and humans where, despite a lack of continuous connectivity, data must be transmitted while the network conditions change due to the nodes' mobility. In these contexts, routing is NP-hard and is usually solved by heuristic "store and forward" replication-based approaches, where multiple copies of the same message are moved and stored across nodes in the hope that at least one will reach its destination. Still, the existing routing protocols produce relatively low delivery probabilities. Here, we genetically improve two routing protocols widely adopted in DTNs, namely Epidemic and PRoPHET, in the attempt to optimize their delivery probability. First, we dissect them into their fundamental components, i.e., functionalities such as checking if a node can transfer data, or sending messages to all connections. Then, we apply Genetic Improvement (GI) to manipulate these components as terminal nodes of evolving trees. We apply this methodology, in silico, to six test cases of urban networks made of hundreds of nodes, and find that GI produces consistent gains in delivery probability in four cases. We then verify if this improvement entails a worsening of other relevant network metrics, such as latency and buffer time. Finally, we compare the logics of the best evolved protocols with those of the baseline protocols, and we discuss the generalizability of the results across test cases.
Tree-structured Ising models can be learned efficiently
Oct 28, 2020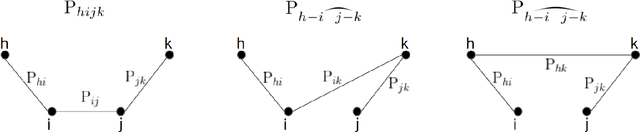
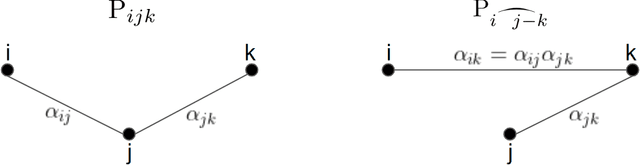
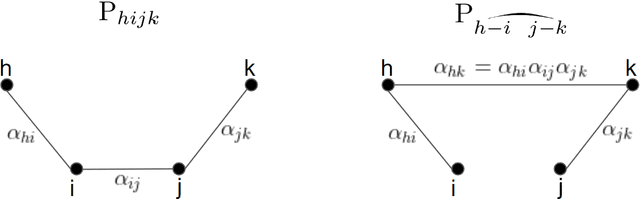
We provide the first polynomial-sample and polynomial-time algorithm for learning tree-structured Ising models. In particular, we show that $n$-variable tree-structured Ising models can be learned computationally-efficiently to within total variation distance~$\epsilon$ from an optimal $O(n \log n/\epsilon^2)$ samples, where $O(.)$ hides an absolute constant which does not depend on the model being learned -- neither its tree nor the magnitude of its edge strengths, on which we place no assumptions. Our guarantees hold, in fact, for the celebrated Chow-Liu [1968] algorithm, using the plug-in estimator for mutual information. While this (or any other) algorithm may fail to identify the structure of the underlying model correctly from a finite sample, we show that it will still learn a tree-structured model that is close to the true one in TV distance, a guarantee called "proper learning." Prior to our work there were no known sample- and time-efficient algorithms for learning (properly or non-properly) arbitrary tree-structured graphical models. In particular, our guarantees cannot be derived from known results for the Chow-Liu algorithm and the ensuing literature on learning graphical models, including a recent renaissance of algorithms on this learning challenge, which only yield asymptotic consistency results, or sample-inefficient and/or time-inefficient algorithms, unless further assumptions are placed on the graphical model, such as bounds on the "strengths" of the model's edges. While we establish guarantees for a widely known and simple algorithm, the analysis that this algorithm succeeds is quite complex, requiring a hierarchical classification of the edges into layers with different reconstruction guarantees, depending on their strength, combined with delicate uses of the subadditivity of the squared Hellinger distance over graphical models to control the error accumulation.
Risk Aware and Multi-Objective Decision Making with Distributional Monte Carlo Tree Search
Feb 02, 2021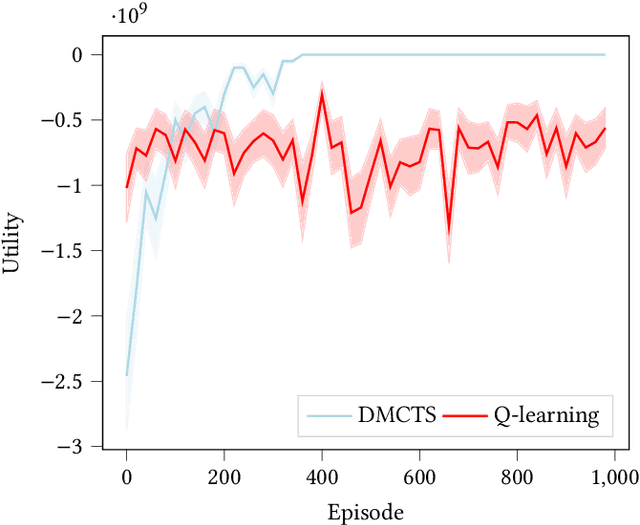
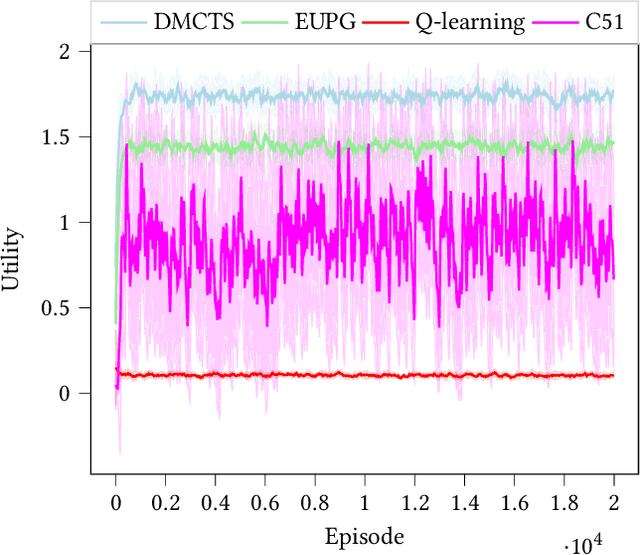
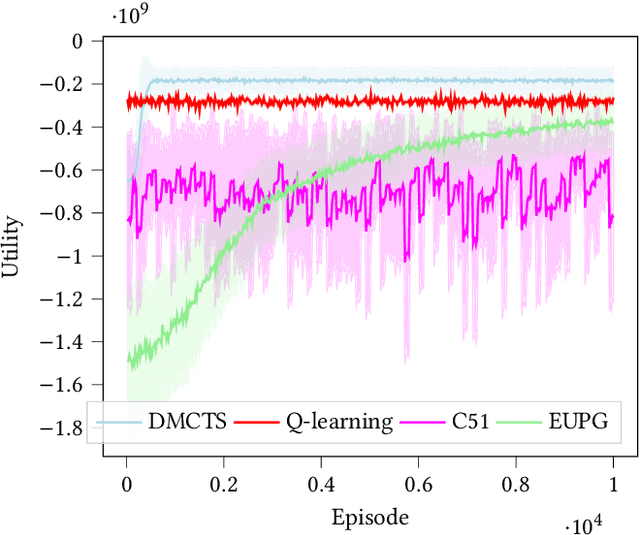
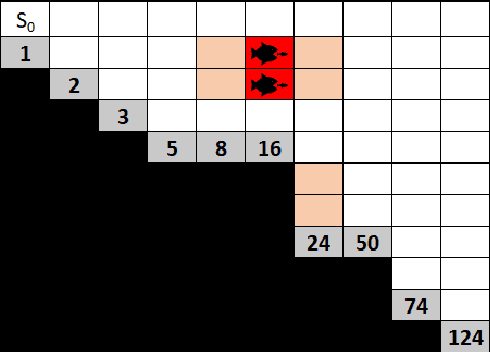
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from the single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. When making a decision, just the expected return -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Our key insight is that we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time. In this paper, we propose Distributional Monte Carlo Tree Search, an algorithm that learns a posterior distribution over the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Moreover, our algorithm outperforms the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Enhanced Robust Adaptive Beamforming Designs for General-Rank Signal Model via an Induced Norm of Matrix Errors
Mar 24, 2021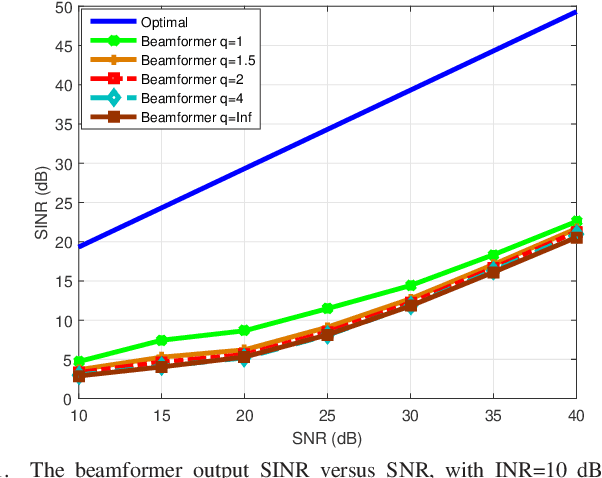
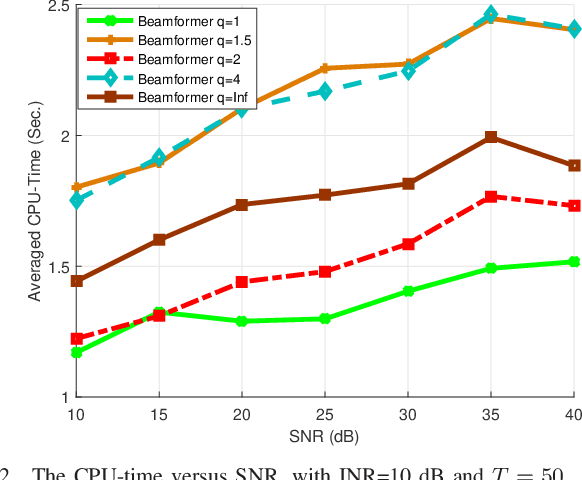
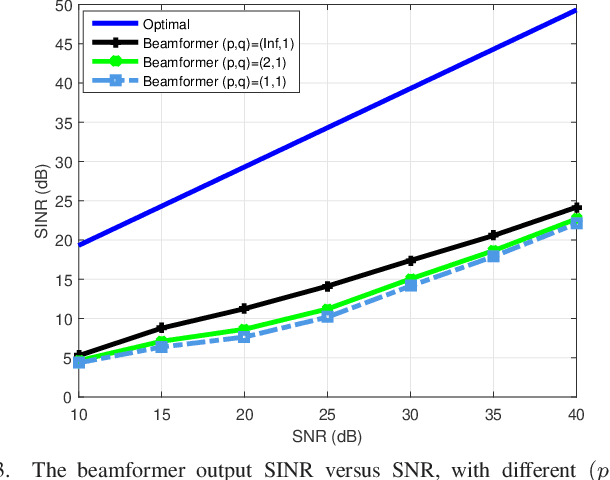
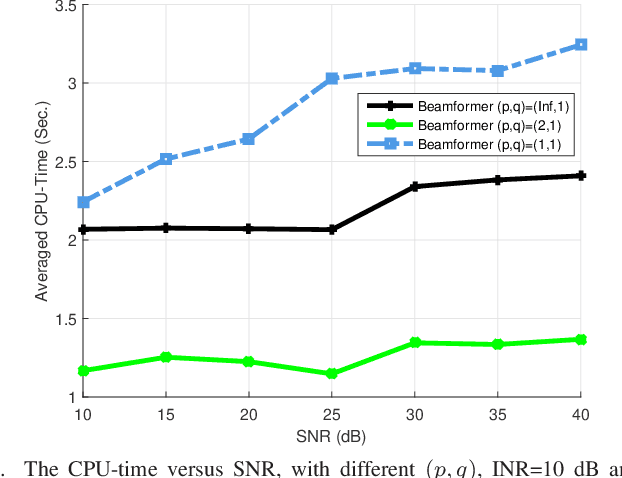
The robust adaptive beamforming (RAB) problem for general-rank signal model with an uncertainty set defined through a matrix induced norm is considered. The worst-case signal-to-interference-plus-noise ratio (SINR) maximization RAB problem is formulated by decomposing the presumed covariance of the desired signal into a product between a matrix and its Hermitian, and putting an error term into the matrix and its Hermitian. In the literature, the norm of the matrix errors often is the Frobenius norm in the maximization problem. Herein, the closed-form optimal value for a minimization problem of the least-squares residual over the matrix errors with an induced $l_{p,q}$-norm constraint is first derived. Then, the worst-case SINR maximization problem is reformulated into the maximization of the difference between an $l_2$-norm function and a $l_q$-norm function, subject to a convex quadratic constraint. It is shown that for any $q$ in the set of rational numbers greater than or equal to one, the maximization problem can be approximated by a sequence of second-order cone programming (SOCP) problems, with the ascent optimal values. The resultant beamvector for some $q$ in the set, corresponding to the maximal actual array output SINR, is treated as the best candidate such that the RAB design is improved the most. In addition, a generalized RAB problem of maximizing the difference between an $l_p$-norm function and an $l_q$-norm function subject to the convex quadratic constraint is studied, and the actual array output SINR is further enhanced by properly selecting $p$ and $q$. Simulation examples are presented to demonstrate the improved performance of the robust beamformers for certain matrix induced $l_{p,q}$-norms, in terms of the actual array output SINR and the CPU-time for the sequential SOCP approximation algorithm.