 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Anomaly detection and motif discovery in symbolic representations of time series
Apr 18, 2017
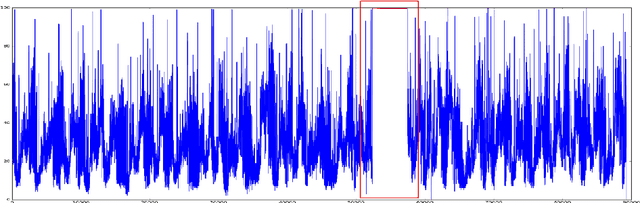
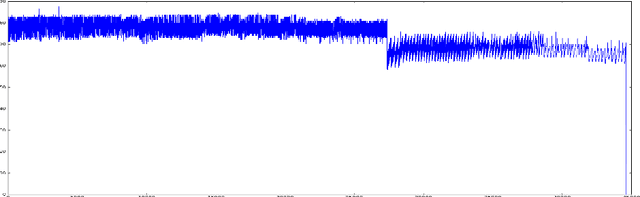
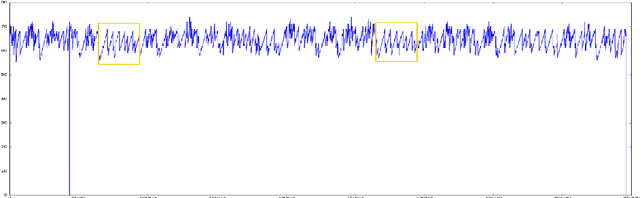
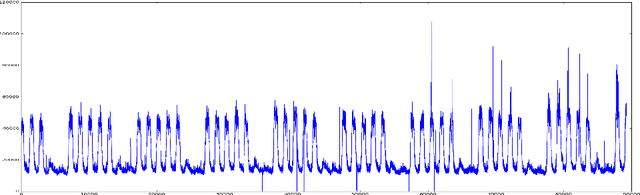
The advent of the Big Data hype and the consistent recollection of event logs and real-time data from sensors, monitoring software and machine configuration has generated a huge amount of time-varying data in about every sector of the industry. Rule-based processing of such data has ceased to be relevant in many scenarios where anomaly detection and pattern mining have to be entirely accomplished by the machine. Since the early 2000s, the de-facto standard for representing time series has been the Symbolic Aggregate approXimation (SAX).In this document, we present a few algorithms using this representation for anomaly detection and motif discovery, also known as pattern mining, in such data. We propose a benchmark of anomaly detection algorithms using data from Cloud monitoring software.
Linear Time Clustering for High Dimensional Mixtures of Gaussian Clouds
Mar 01, 2018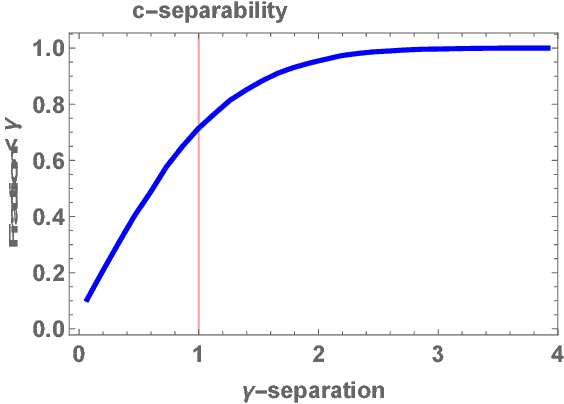
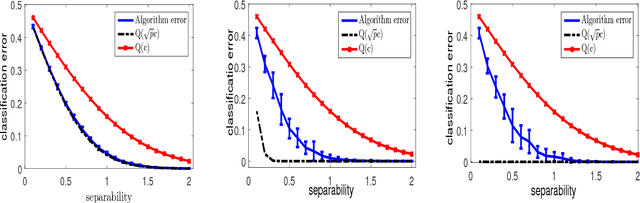
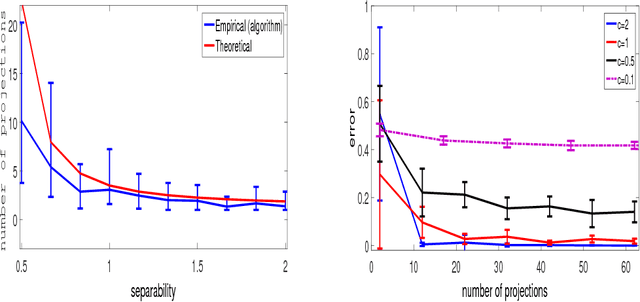
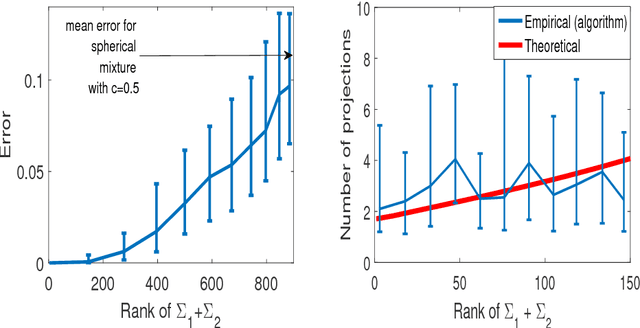
Clustering mixtures of Gaussian distributions is a fundamental and challenging problem that is ubiquitous in various high-dimensional data processing tasks. While state-of-the-art work on learning Gaussian mixture models has focused primarily on improving separation bounds and their generalization to arbitrary classes of mixture models, less emphasis has been paid to practical computational efficiency of the proposed solutions. In this paper, we propose a novel and highly efficient clustering algorithm for $n$ points drawn from a mixture of two arbitrary Gaussian distributions in $\mathbb{R}^p$. The algorithm involves performing random 1-dimensional projections until a direction is found that yields a user-specified clustering error $e$. For a 1-dimensional separation parameter $\gamma$ satisfying $\gamma=Q^{-1}(e)$, the expected number of such projections is shown to be bounded by $o(\ln p)$, when $\gamma$ satisfies $\gamma\leq c\sqrt{\ln{\ln{p}}}$, with $c$ as the separability parameter of the two Gaussians in $\mathbb{R}^p$. Consequently, the expected overall running time of the algorithm is linear in $n$ and quasi-linear in $p$ at $o(\ln{p})O(np)$, and the sample complexity is independent of $p$. This result stands in contrast to prior works which provide polynomial, with at-best quadratic, running time in $p$ and $n$. We show that our bound on the expected number of 1-dimensional projections extends to the case of three or more Gaussian components, and we present a generalization of our results to mixture distributions beyond the Gaussian model.
Optimal Task Assignment to Heterogeneous Federated Learning Devices
Oct 01, 2020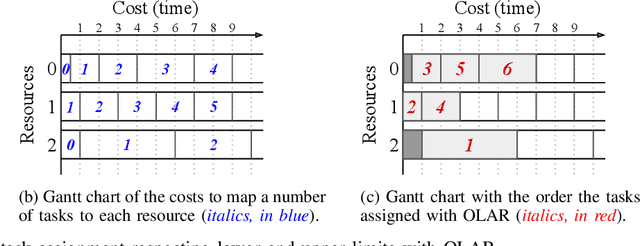
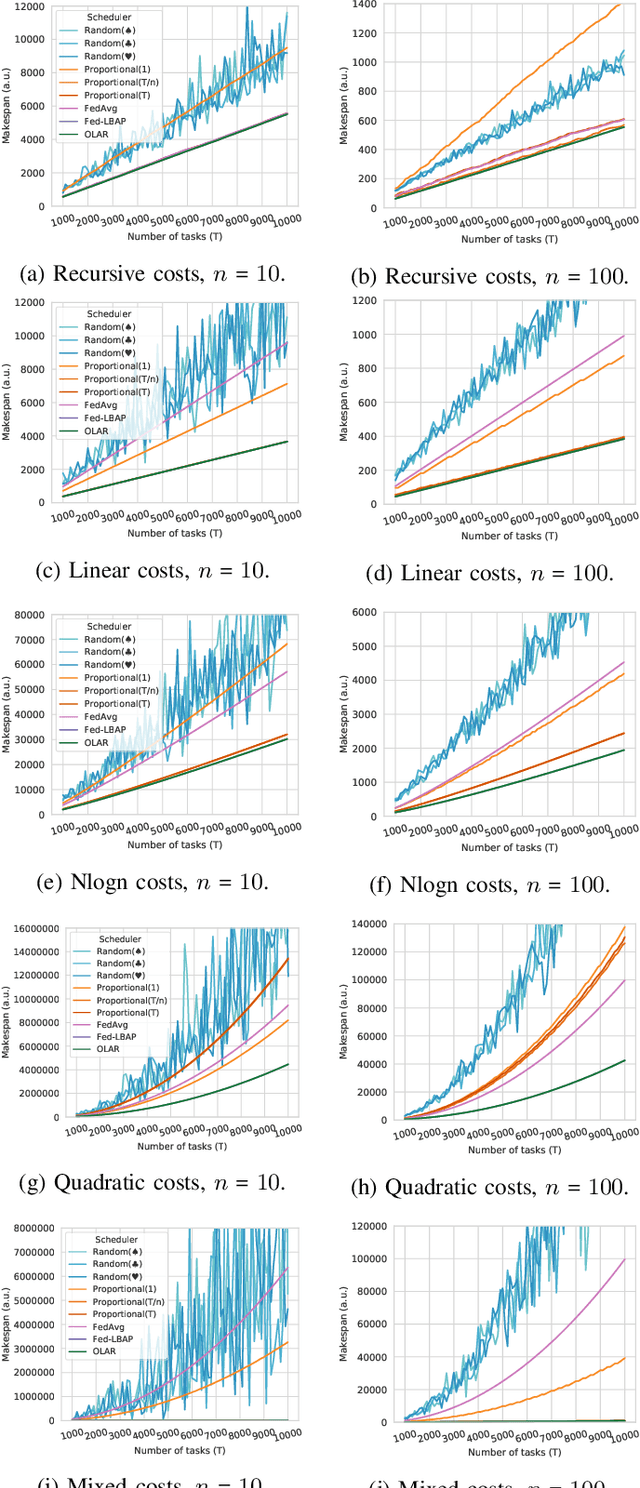
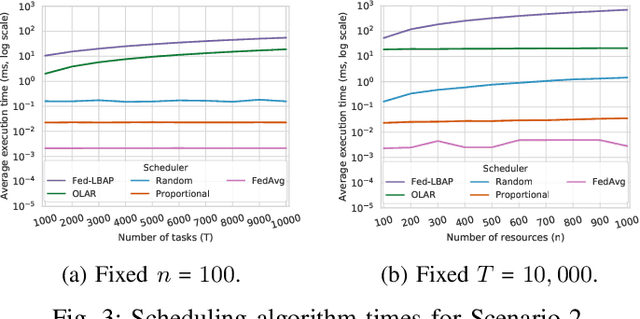
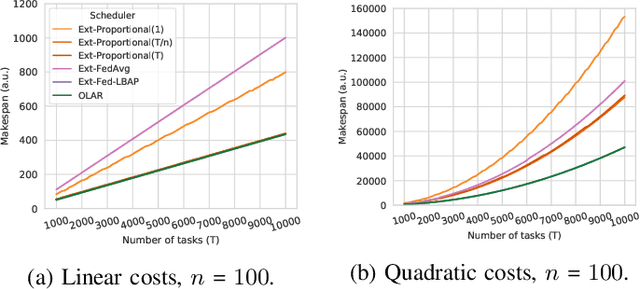
Federated Learning provides new opportunities for training machine learning models while respecting data privacy. This technique is based on heterogeneous devices that work together to iteratively train a model while never sharing their own data. Given the synchronous nature of this training, the performance of Federated Learning systems is dictated by the slowest devices, also known as stragglers. In this paper, we investigate the problem of minimizing the duration of Federated Learning rounds by controlling how much data each device uses for training. We formulate this problem as a makespan minimization problem with identical, independent, and atomic tasks that have to be assigned to heterogeneous resources with non-decreasing cost functions while respecting lower and upper limits of tasks per resource. Based on this formulation, we propose a polynomial-time algorithm named OLAR and prove that it provides optimal schedules. We evaluate OLAR in an extensive experimental evaluation using simulation that includes comparisons to other algorithms from the state of the art and new extensions to them. Our results indicate that OLAR provides optimal solutions with a small execution time. They also show that the presence of lower and upper limits of tasks per resource erase any benefits that suboptimal heuristics could provide in terms of algorithm execution time.
Fast Greedy Subset Selection from Large Candidate Solution Sets in Evolutionary Multi-objective Optimization
Feb 01, 2021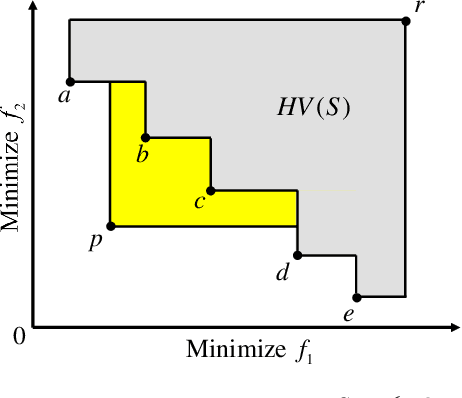
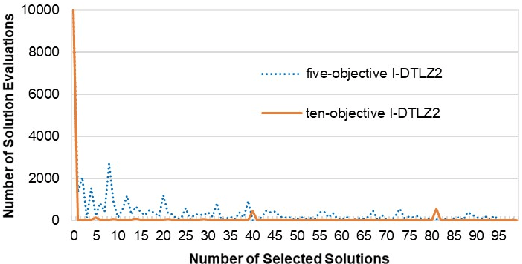
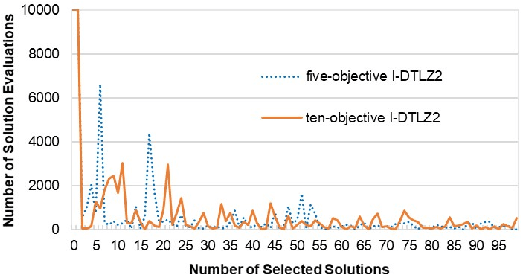
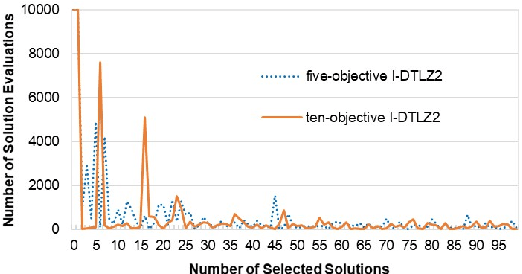
Subset selection is an interesting and important topic in the field of evolutionary multi-objective optimization (EMO). Especially, in an EMO algorithm with an unbounded external archive, subset selection is an essential post-processing procedure to select a pre-specified number of solutions as the final result. In this paper, we discuss the efficiency of greedy subset selection for the hypervolume, IGD and IGD+ indicators. Greedy algorithms usually efficiently handle subset selection. However, when a large number of solutions are given (e.g., subset selection from tens of thousands of solutions in an unbounded external archive), they often become time-consuming. Our idea is to use the submodular property, which is known for the hypervolume indicator, to improve their efficiency. First, we prove that the IGD and IGD+ indicators are also submodular. Next, based on the submodular property, we propose an efficient greedy inclusion algorithm for each indicator. Then, we demonstrate through computational experiments that the proposed algorithms are much faster than the standard greedy subset selection algorithms.
Deep Reinforcement Learning for Combinatorial Optimization: Covering Salesman Problems
Feb 11, 2021



This paper introduces a new deep learning approach to approximately solve the Covering Salesman Problem (CSP). In this approach, given the city locations of a CSP as input, a deep neural network model is designed to directly output the solution. It is trained using the deep reinforcement learning without supervision. Specifically, in the model, we apply the Multi-head Attention to capture the structural patterns, and design a dynamic embedding to handle the dynamic patterns of the problem. Once the model is trained, it can generalize to various types of CSP tasks (different sizes and topologies) with no need of re-training. Through controlled experiments, the proposed approach shows desirable time complexity: it runs more than 20 times faster than the traditional heuristic solvers with a tiny gap of optimality. Moreover, it significantly outperforms the current state-of-the-art deep learning approaches for combinatorial optimization in the aspect of both training and inference. In comparison with traditional solvers, this approach is highly desirable for most of the challenging tasks in practice that are usually large-scale and require quick decisions.
Singer Identification Using Deep Timbre Feature Learning with KNN-Net
Feb 20, 2021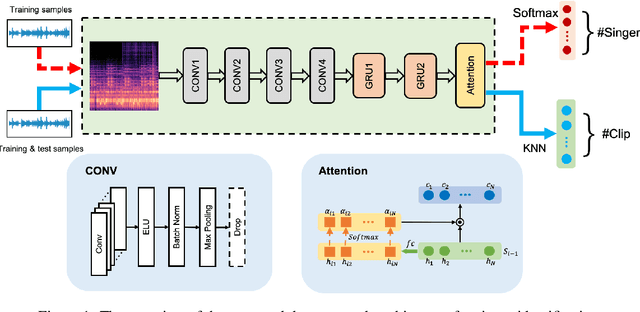
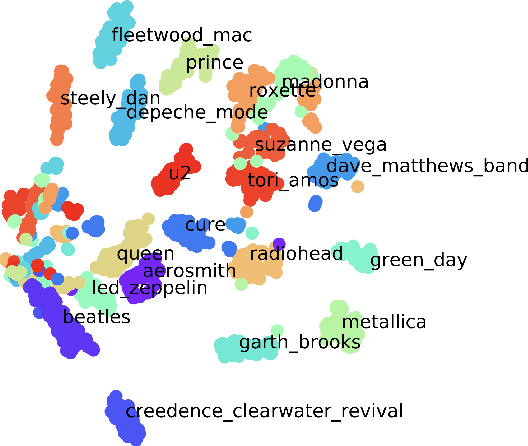
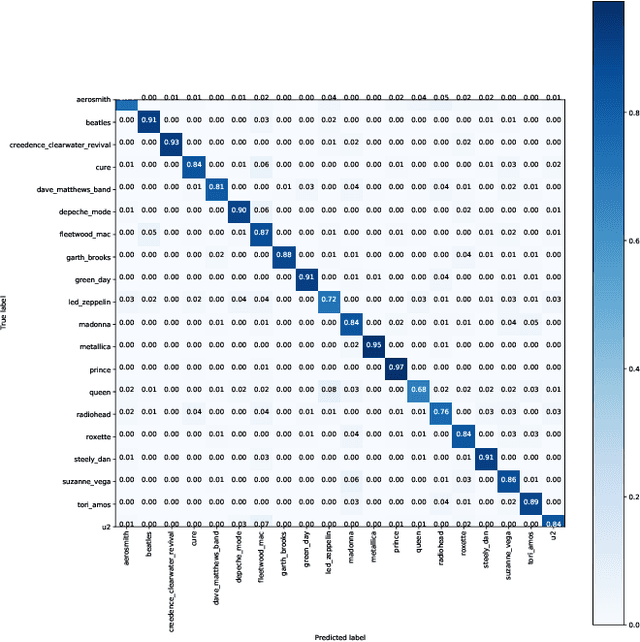
In this paper, we study the issue of automatic singer identification (SID) in popular music recordings, which aims to recognize who sang a given piece of song. The main challenge for this investigation lies in the fact that a singer's singing voice changes and intertwines with the signal of background accompaniment in time domain. To handle this challenge, we propose the KNN-Net for SID, which is a deep neural network model with the goal of learning local timbre feature representation from the mixture of singer voice and background music. Unlike other deep neural networks using the softmax layer as the output layer, we instead utilize the KNN as a more interpretable layer to output target singer labels. Moreover, attention mechanism is first introduced to highlight crucial timbre features for SID. Experiments on the existing artist20 dataset show that the proposed approach outperforms the state-of-the-art method by 4%. We also create singer32 and singer60 datasets consisting of Chinese pop music to evaluate the reliability of the proposed method. The more extensive experiments additionally indicate that our proposed model achieves a significant performance improvement compared to the state-of-the-art methods.
An Improved Simulation Model for Pedestrian Crowd Evacuation
Dec 04, 2020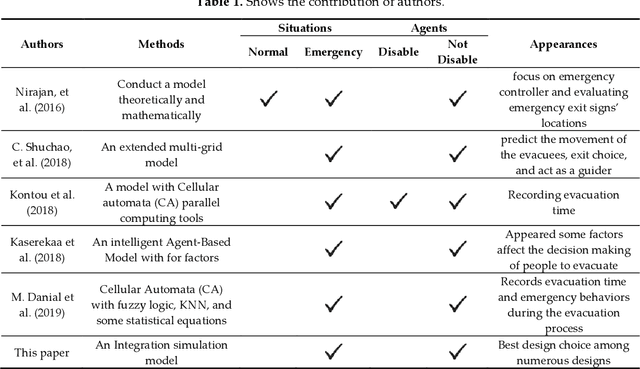
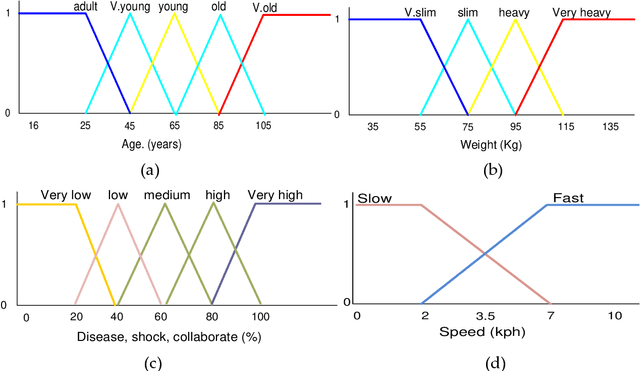
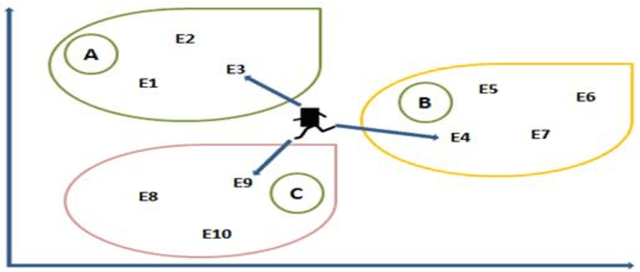

This paper works on one of the most recent pedestrian crowd evacuation models, i.e., "a simulation model for pedestrian crowd evacuation based on various AI techniques", developed in late 2019. This study adds a new feature to the developed model by proposing a new method and integrating it with the model. This method enables the developed model to find a more appropriate evacuation area design, among others regarding safety due to selecting the best exit door location among many suggested locations. This method is completely dependent on the selected model's output, i.e., the evacuation time for each individual within the evacuation process. The new method finds an average of the evacuees' evacuation times of each exit door location; then, based on the average evacuation time, it decides which exit door location would be the best exit door to be used for evacuation by the evacuees. To validate the method, various designs for the evacuation area with various written scenarios were used. The results showed that the model with this new method could predict a proper exit door location among many suggested locations. Lastly, from the results of this research using the integration of this newly proposed method, a new capability for the selected model in terms of safety allowed the right decision in selecting the finest design for the evacuation area among other designs.
Auto-tuning of Deep Neural Networks by Conflicting Layer Removal
Mar 07, 2021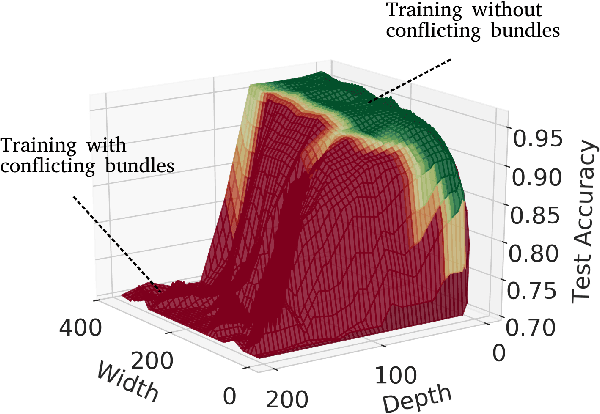
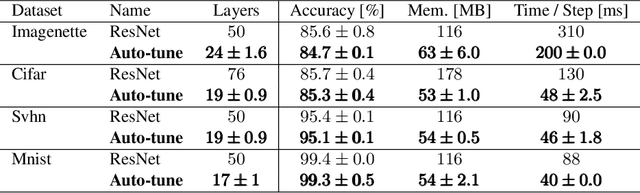
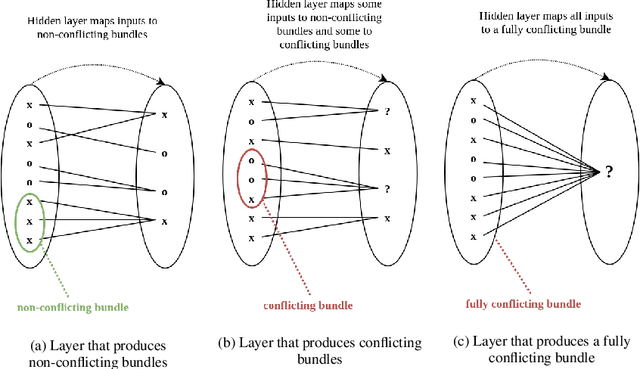
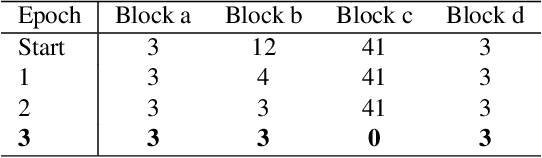
Designing neural network architectures is a challenging task and knowing which specific layers of a model must be adapted to improve the performance is almost a mystery. In this paper, we introduce a novel methodology to identify layers that decrease the test accuracy of trained models. Conflicting layers are detected as early as the beginning of training. In the worst-case scenario, we prove that such a layer could lead to a network that cannot be trained at all. A theoretical analysis is provided on what is the origin of those layers that result in a lower overall network performance, which is complemented by our extensive empirical evaluation. More precisely, we identified those layers that worsen the performance because they would produce what we name conflicting training bundles. We will show that around 60% of the layers of trained residual networks can be completely removed from the architecture with no significant increase in the test-error. We will further present a novel neural-architecture-search (NAS) algorithm that identifies conflicting layers at the beginning of the training. Architectures found by our auto-tuning algorithm achieve competitive accuracy values when compared against more complex state-of-the-art architectures, while drastically reducing memory consumption and inference time for different computer vision tasks. The source code is available on https://github.com/peerdavid/conflicting-bundles
Audiovisual Highlight Detection in Videos
Feb 11, 2021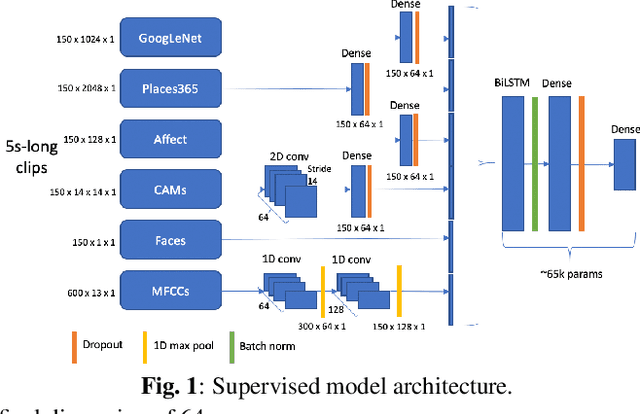
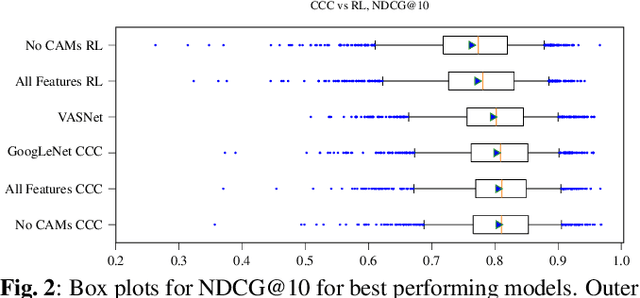
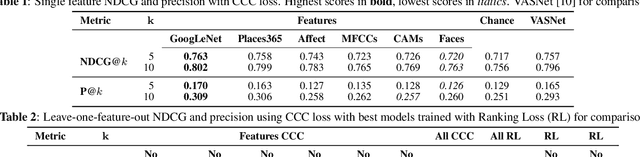
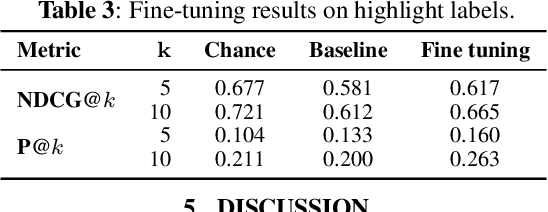
In this paper, we test the hypothesis that interesting events in unstructured videos are inherently audiovisual. We combine deep image representations for object recognition and scene understanding with representations from an audiovisual affect recognition model. To this set, we include content agnostic audio-visual synchrony representations and mel-frequency cepstral coefficients to capture other intrinsic properties of audio. These features are used in a modular supervised model. We present results from two experiments: efficacy study of single features on the task, and an ablation study where we leave one feature out at a time. For the video summarization task, our results indicate that the visual features carry most information, and including audiovisual features improves over visual-only information. To better study the task of highlight detection, we run a pilot experiment with highlights annotations for a small subset of video clips and fine-tune our best model on it. Results indicate that we can transfer knowledge from the video summarization task to a model trained specifically for the task of highlight detection.
ESCAPED: Efficient Secure and Private Dot Product Framework for Kernel-based Machine Learning Algorithms with Applications in Healthcare
Dec 04, 2020
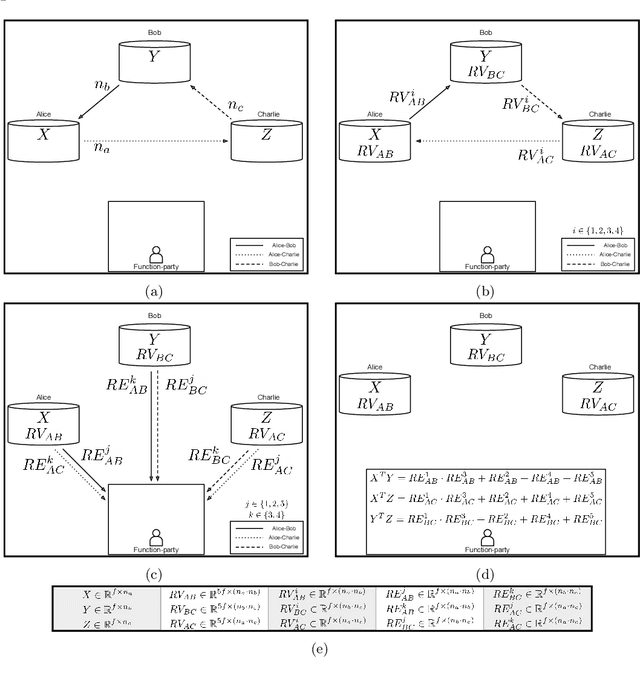
To train sophisticated machine learning models one usually needs many training samples. Especially in healthcare settings these samples can be very expensive, meaning that one institution alone usually does not have enough on its own. Merging privacy-sensitive data from different sources is usually restricted by data security and data protection measures. This can lead to approaches that reduce data quality by putting noise onto the variables (e.g., in $\epsilon$-differential privacy) or omitting certain values (e.g., for $k$-anonymity). Other measures based on cryptographic methods can lead to very time-consuming computations, which is especially problematic for larger multi-omics data. We address this problem by introducing ESCAPED, which stands for Efficient SeCure And PrivatE Dot product framework, enabling the computation of the dot product of vectors from multiple sources on a third-party, which later trains kernel-based machine learning algorithms, while neither sacrificing privacy nor adding noise. We evaluated our framework on drug resistance prediction for HIV-infected people and multi-omics dimensionality reduction and clustering problems in precision medicine. In terms of execution time, our framework significantly outperforms the best-fitting existing approaches without sacrificing the performance of the algorithm. Even though we only show the benefit for kernel-based algorithms, our framework can open up new research opportunities for further machine learning models that require the dot product of vectors from multiple sources.