 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality
Mar 21, 2018
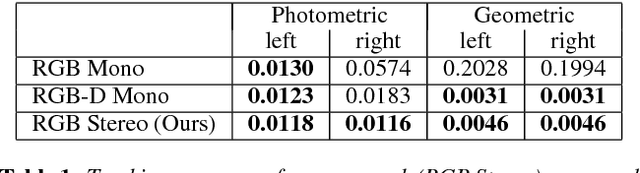

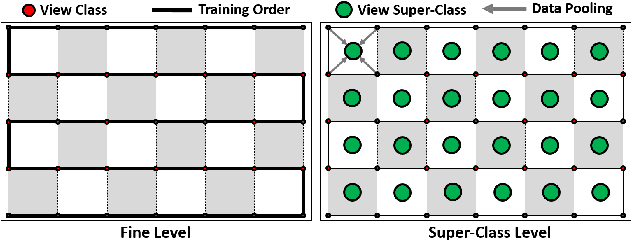
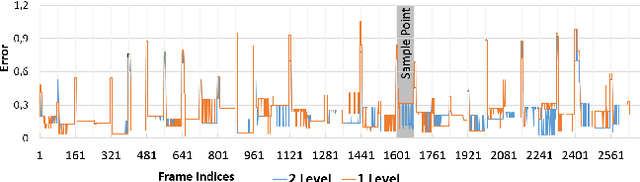
We propose FaceVR, a novel image-based method that enables video teleconferencing in VR based on self-reenactment. State-of-the-art face tracking methods in the VR context are focused on the animation of rigged 3d avatars. While they achieve good tracking performance the results look cartoonish and not real. In contrast to these model-based approaches, FaceVR enables VR teleconferencing using an image-based technique that results in nearly photo-realistic outputs. The key component of FaceVR is a robust algorithm to perform real-time facial motion capture of an actor who is wearing a head-mounted display (HMD), as well as a new data-driven approach for eye tracking from monocular videos. Based on reenactment of a prerecorded stereo video of the person without the HMD, FaceVR incorporates photo-realistic re-rendering in real time, thus allowing artificial modifications of face and eye appearances. For instance, we can alter facial expressions or change gaze directions in the prerecorded target video. In a live setup, we apply these newly-introduced algorithmic components.
Low-latency Perception in Off-Road Dynamical Low Visibility Environments
Dec 23, 2020
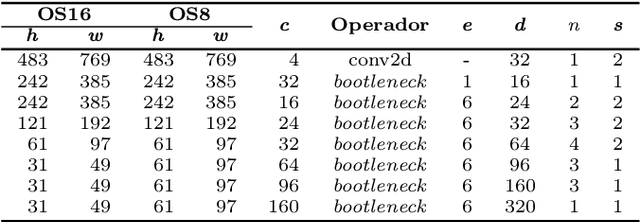


This work proposes a perception system for autonomous vehicles and advanced driver assistance specialized on unpaved roads and off-road environments. In this research, the authors have investigated the behavior of Deep Learning algorithms applied to semantic segmentation of off-road environments and unpaved roads under differents adverse conditions of visibility. Almost 12,000 images of different unpaved and off-road environments were collected and labeled. It was assembled an off-road proving ground exclusively for its development. The proposed dataset also contains many adverse situations such as rain, dust, and low light. To develop the system, we have used convolutional neural networks trained to segment obstacles and areas where the car can pass through. We developed a Configurable Modular Segmentation Network (CMSNet) framework to help create different architectures arrangements and test them on the proposed dataset. Besides, we also have ported some CMSNet configurations by removing and fusing many layers using TensorRT, C++, and CUDA to achieve embedded real-time inference and allow field tests. The main contributions of this work are: a new dataset for unpaved roads and off-roads environments containing many adverse conditions such as night, rain, and dust; a CMSNet framework; an investigation regarding the feasibility of applying deep learning to detect region where the vehicle can pass through when there is no clear boundary of the track; a study of how our proposed segmentation algorithms behave in different severity levels of visibility impairment; and an evaluation of field tests carried out with semantic segmentation architectures ported for real-time inference.
Characterizing Technical Debt and Antipatterns in AI-Based Systems: A Systematic Mapping Study
Mar 17, 2021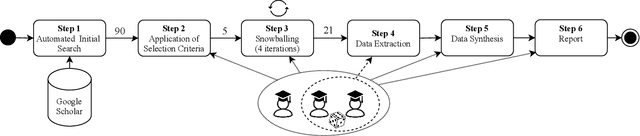
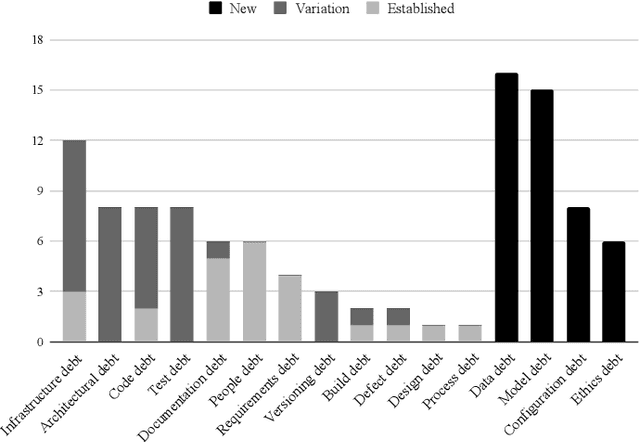
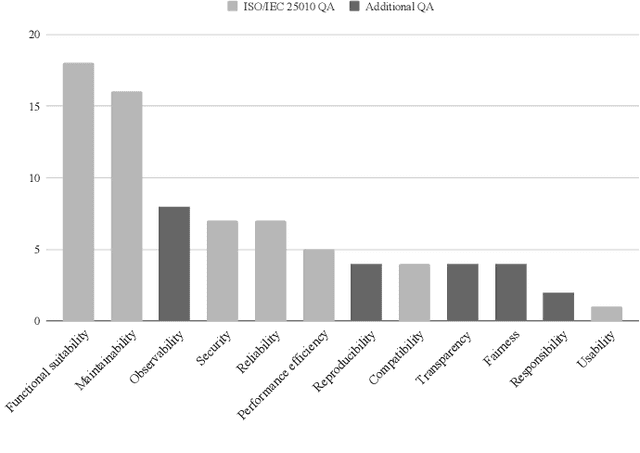
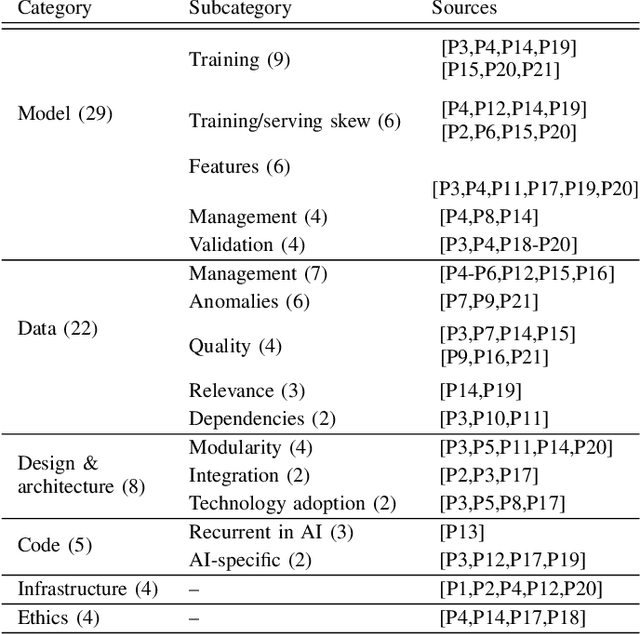
Background: With the rising popularity of Artificial Intelligence (AI), there is a growing need to build large and complex AI-based systems in a cost-effective and manageable way. Like with traditional software, Technical Debt (TD) will emerge naturally over time in these systems, therefore leading to challenges and risks if not managed appropriately. The influence of data science and the stochastic nature of AI-based systems may also lead to new types of TD or antipatterns, which are not yet fully understood by researchers and practitioners. Objective: The goal of our study is to provide a clear overview and characterization of the types of TD (both established and new ones) that appear in AI-based systems, as well as the antipatterns and related solutions that have been proposed. Method: Following the process of a systematic mapping study, 21 primary studies are identified and analyzed. Results: Our results show that (i) established TD types, variations of them, and four new TD types (data, model, configuration, and ethics debt) are present in AI-based systems, (ii) 72 antipatterns are discussed in the literature, the majority related to data and model deficiencies, and (iii) 46 solutions have been proposed, either to address specific TD types, antipatterns, or TD in general. Conclusions: Our results can support AI professionals with reasoning about and communicating aspects of TD present in their systems. Additionally, they can serve as a foundation for future research to further our understanding of TD in AI-based systems.
Accelerating Recursive Partition-Based Causal Structure Learning
Feb 23, 2021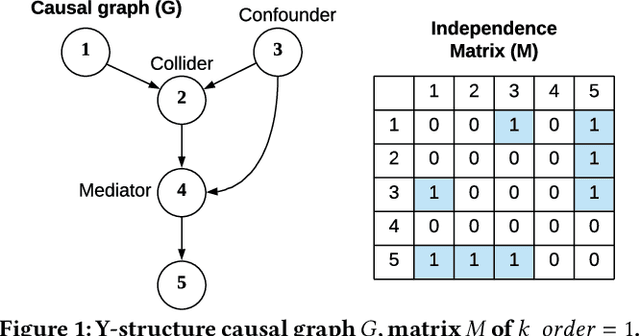
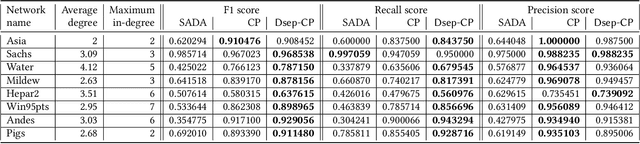
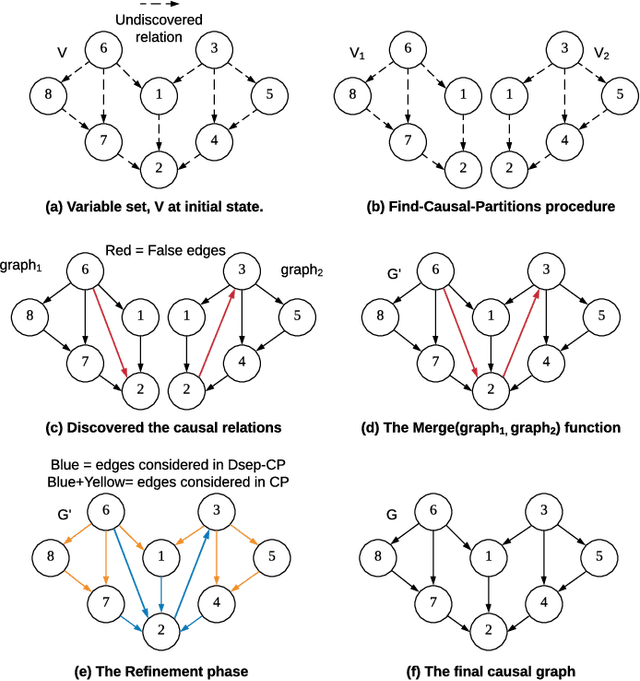
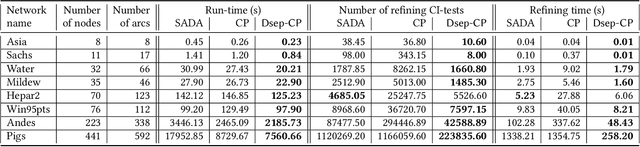
Causal structure discovery from observational data is fundamental to the causal understanding of autonomous systems such as medical decision support systems, advertising campaigns and self-driving cars. This is essential to solve well-known causal decision making and prediction problems associated with those real-world applications. Recently, recursive causal discovery algorithms have gained particular attention among the research community due to their ability to provide good results by using Conditional Independent (CI) tests in smaller sub-problems. However, each of such algorithms needs a refinement function to remove undesired causal relations of the discovered graphs. Notably, with the increase of the problem size, the computation cost (i.e., the number of CI-tests) of the refinement function makes an algorithm expensive to deploy in practice. This paper proposes a generic causal structure refinement strategy that can locate the undesired relations with a small number of CI-tests, thus speeding up the algorithm for large and complex problems. We theoretically prove the correctness of our algorithm. We then empirically evaluate its performance against the state-of-the-art algorithms in terms of solution quality and completion time in synthetic and real datasets.
A Lane-Changing Prediction Method Based on Temporal Convolution Network
Nov 01, 2020
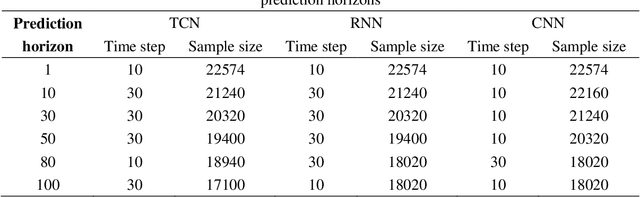
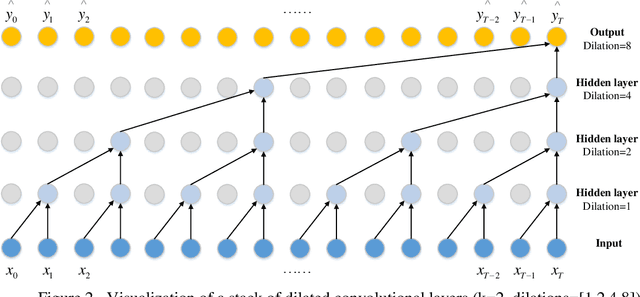
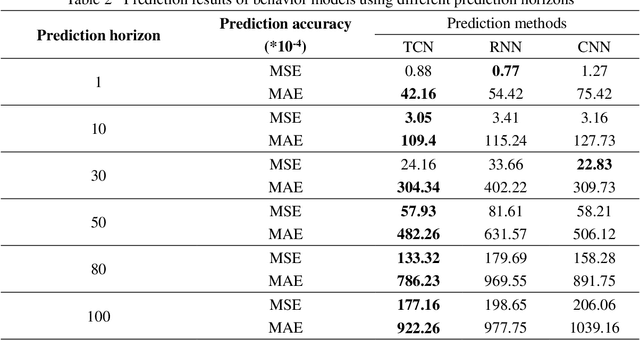
Lane-changing is an important driving behavior and unreasonable lane changes can result in potentially dangerous traffic collisions. Advanced Driver Assistance System (ADAS) can assist drivers to change lanes safely and efficiently. To capture the stochastic time series of lane-changing behavior, this study proposes a temporal convolutional network (TCN) to predict the long-term lane-changing trajectory and behavior. In addition, the convolutional neural network (CNN) and recurrent neural network (RNN) methods are considered as the benchmark models to demonstrate the learning ability of the TCN. The lane-changing dataset was collected by the driving simulator. The prediction performance of TCN is demonstrated from three aspects: different input variables, different input dimensions and different driving scenarios. Prediction results show that the TCN can accurately predict the long-term lane-changing trajectory and driving behavior with shorter computational time compared with two benchmark models. The TCN can provide accurate lane-changing prediction, which is one key information for the development of accurate ADAS.
DAFAR: Defending against Adversaries by Feedback-Autoencoder Reconstruction
Mar 17, 2021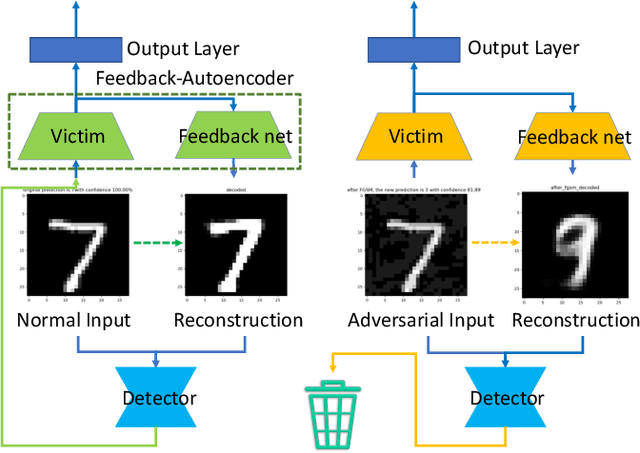
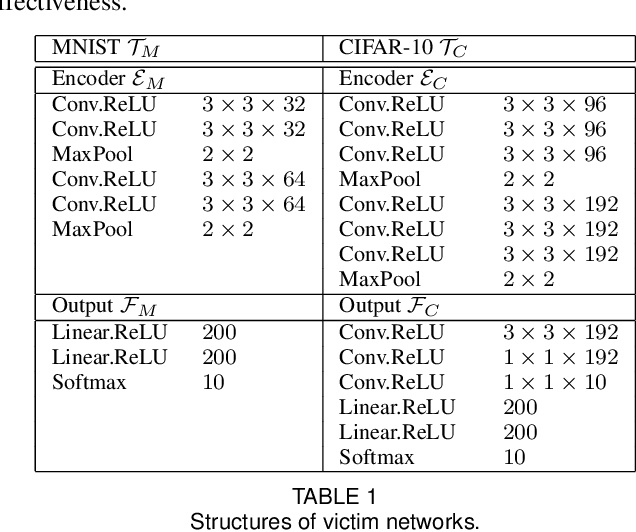
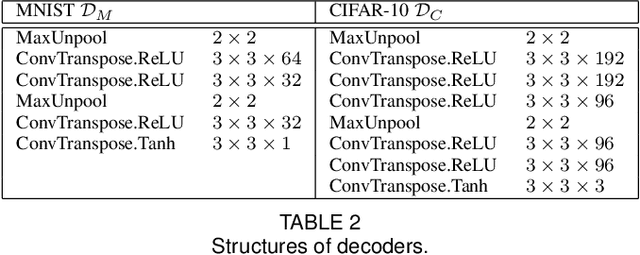
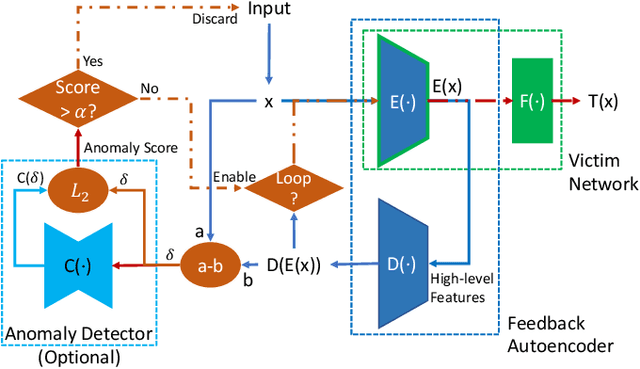
Deep learning has shown impressive performance on challenging perceptual tasks and has been widely used in software to provide intelligent services. However, researchers found deep neural networks vulnerable to adversarial examples. Since then, many methods are proposed to defend against adversaries in inputs, but they are either attack-dependent or shown to be ineffective with new attacks. And most of existing techniques have complicated structures or mechanisms that cause prohibitively high overhead or latency, impractical to apply on real software. We propose DAFAR, a feedback framework that allows deep learning models to detect/purify adversarial examples in high effectiveness and universality, with low area and time overhead. DAFAR has a simple structure, containing a victim model, a plug-in feedback network, and a detector. The key idea is to import the high-level features from the victim model's feature extraction layers into the feedback network to reconstruct the input. This data stream forms a feedback autoencoder. For strong attacks, it transforms the imperceptible attack on the victim model into the obvious reconstruction-error attack on the feedback autoencoder directly, which is much easier to detect; for weak attacks, the reformation process destroys the structure of adversarial examples. Experiments are conducted on MNIST and CIFAR-10 data-sets, showing that DAFAR is effective against popular and arguably most advanced attacks without losing performance on legitimate samples, with high effectiveness and universality across attack methods and parameters.
Semi-Synchronous Federated Learning
Feb 04, 2021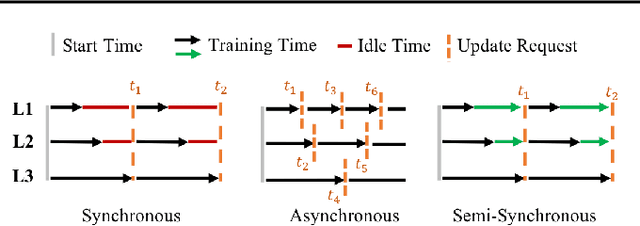



There are situations where data relevant to a machine learning problem are distributed among multiple locations that cannot share the data due to regulatory, competitiveness, or privacy reasons. For example, data present in users' cellphones, manufacturing data of companies in a given industrial sector, or medical records located at different hospitals. Federated Learning (FL) provides an approach to learn a joint model over all the available data across silos. In many cases, participating sites have different data distributions and computational capabilities. In these heterogeneous environments previous approaches exhibit poor performance: synchronous FL protocols are communication efficient, but have slow learning convergence; conversely, asynchronous FL protocols have faster convergence, but at a higher communication cost. Here we introduce a novel Semi-Synchronous Federated Learning protocol that mixes local models periodically with minimal idle time and fast convergence. We show through extensive experiments that our approach significantly outperforms previous work in data and computationally heterogeneous environments.
Anytime Sampling for Autoregressive Models via Ordered Autoencoding
Feb 23, 2021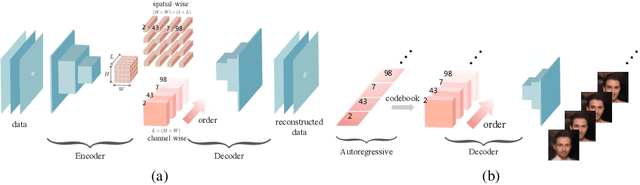

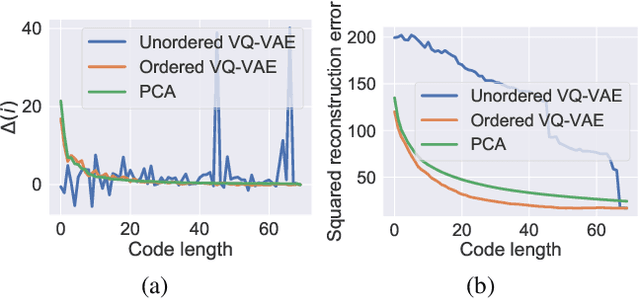
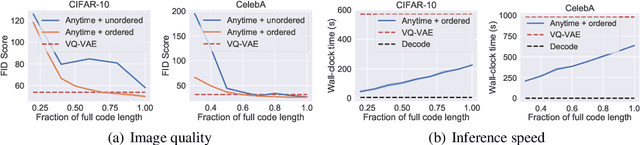
Autoregressive models are widely used for tasks such as image and audio generation. The sampling process of these models, however, does not allow interruptions and cannot adapt to real-time computational resources. This challenge impedes the deployment of powerful autoregressive models, which involve a slow sampling process that is sequential in nature and typically scales linearly with respect to the data dimension. To address this difficulty, we propose a new family of autoregressive models that enables anytime sampling. Inspired by Principal Component Analysis, we learn a structured representation space where dimensions are ordered based on their importance with respect to reconstruction. Using an autoregressive model in this latent space, we trade off sample quality for computational efficiency by truncating the generation process before decoding into the original data space. Experimentally, we demonstrate in several image and audio generation tasks that sample quality degrades gracefully as we reduce the computational budget for sampling. The approach suffers almost no loss in sample quality (measured by FID) using only 60\% to 80\% of all latent dimensions for image data. Code is available at https://github.com/Newbeeer/Anytime-Auto-Regressive-Model .
Bayesian Algorithms for Decentralized Stochastic Bandits
Oct 20, 2020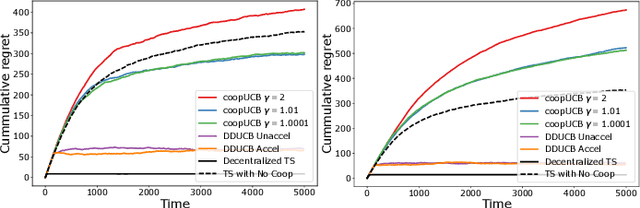
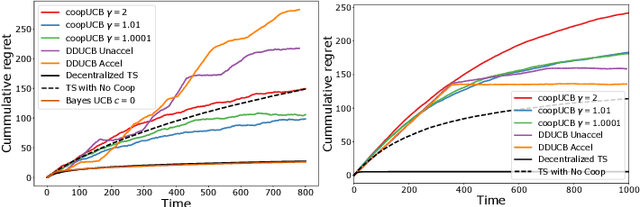
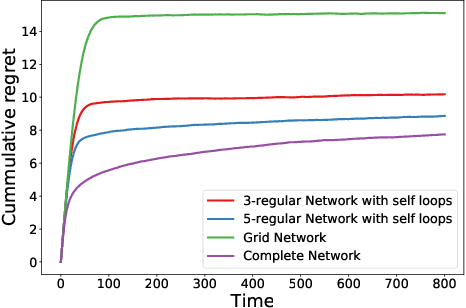
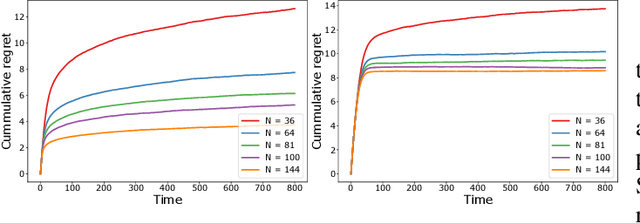
We study a decentralized cooperative multi-agent multi-armed bandit problem with $K$ arms and $N$ agents connected over a network. In our model, each arm's reward distribution is same for all agents, and rewards are drawn independently across agents and over time steps. In each round, agents choose an arm to play and subsequently send a message to their neighbors. The goal is to minimize cumulative regret averaged over the entire network. We propose a decentralized Bayesian multi-armed bandit framework that extends single-agent Bayesian bandit algorithms to the decentralized setting. Specifically, we study an information assimilation algorithm that can be combined with existing Bayesian algorithms, and using this, we propose a decentralized Thompson Sampling algorithm and decentralized Bayes-UCB algorithm. We analyze the decentralized Thompson Sampling algorithm under Bernoulli rewards and establish a problem-dependent upper bound on the cumulative regret. We show that regret incurred scales logarithmically over the time horizon with constants that match those of an optimal centralized agent with access to all observations across the network. Our analysis also characterizes the cumulative regret in terms of the network structure. Through extensive numerical studies, we show that our extensions of Thompson Sampling and Bayes-UCB incur lesser cumulative regret than the state-of-art algorithms inspired by the Upper Confidence Bound algorithm. We implement our proposed decentralized Thompson Sampling under gossip protocol, and over time-varying networks, where each communication link has a fixed probability of failure.
A Multi-Modal Respiratory Disease Exacerbation Prediction Technique Based on a Spatio-Temporal Machine Learning Architecture
Mar 03, 2021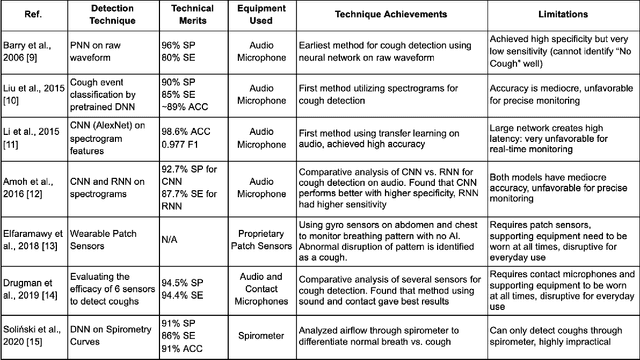
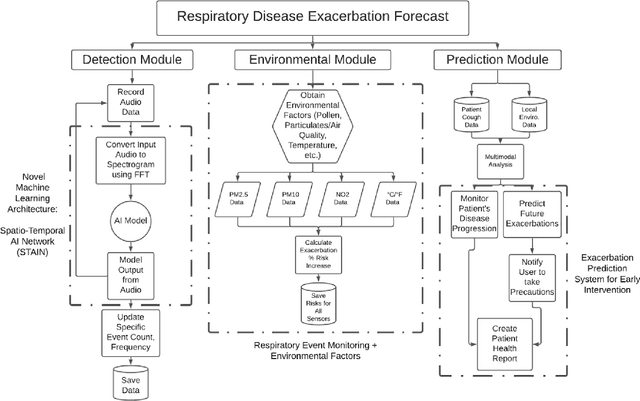
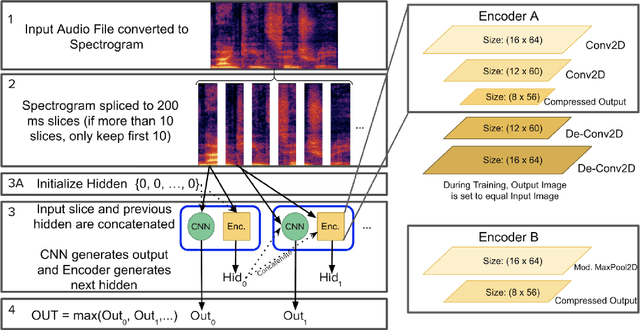
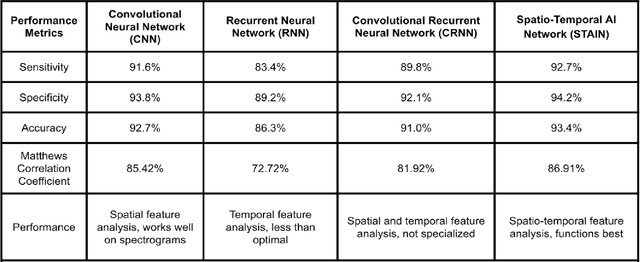
Chronic respiratory diseases, such as chronic obstructive pulmonary disease and asthma, are a serious health crisis, affecting a large number of people globally and inflicting major costs on the economy. Current methods for assessing the progression of respiratory symptoms are either subjective and inaccurate, or complex and cumbersome, and do not incorporate environmental factors. Lacking predictive assessments and early intervention, unexpected exacerbations can lead to hospitalizations and high medical costs. This work presents a multi-modal solution for predicting the exacerbation risks of respiratory diseases, such as COPD, based on a novel spatio-temporal machine learning architecture for real-time and accurate respiratory events detection, and tracking of local environmental and meteorological data and trends. The proposed new machine learning architecture blends key attributes of both convolutional and recurrent neural networks, allowing extraction of both spatial and temporal features encoded in respiratory sounds, thereby leading to accurate classification and tracking of symptoms. Combined with the data from environmental and meteorological sensors, and a predictive model based on retrospective medical studies, this solution can assess and provide early warnings of respiratory disease exacerbations. This research will improve the quality of patients' lives through early medical intervention, thereby reducing hospitalization rates and medical costs.