 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rapidly adapting robot swarms with Swarm Map-based Bayesian Optimisation
Dec 21, 2020
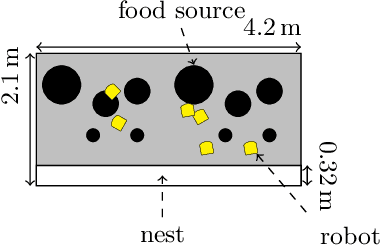
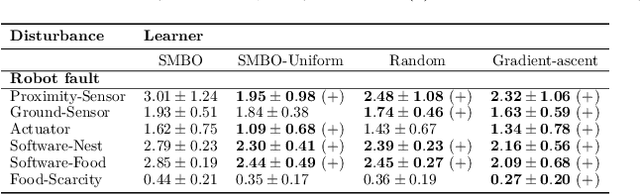
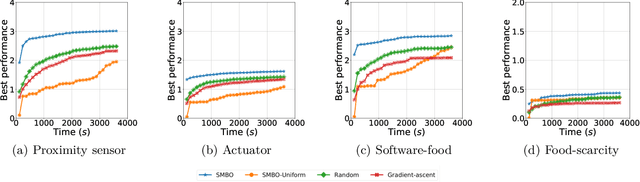
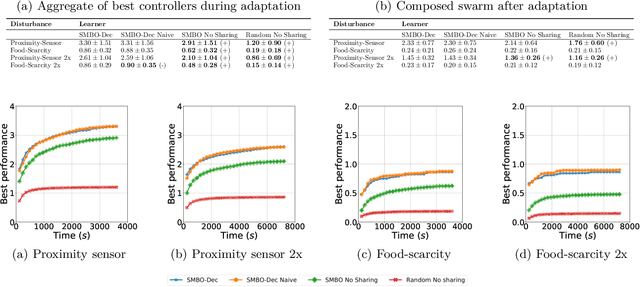
Rapid performance recovery from unforeseen environmental perturbations remains a grand challenge in swarm robotics. To solve this challenge, we investigate a behaviour adaptation approach, where one searches an archive of controllers for potential recovery solutions. To apply behaviour adaptation in swarm robotic systems, we propose two algorithms: (i) Swarm Map-based Optimisation (SMBO), which selects and evaluates one controller at a time, for a homogeneous swarm, in a centralised fashion; and (ii) Swarm Map-based Optimisation Decentralised (SMBO-Dec), which performs an asynchronous batch-based Bayesian optimisation to simultaneously explore different controllers for groups of robots in the swarm. We set up foraging experiments with a variety of disturbances: injected faults to proximity sensors, ground sensors, and the actuators of individual robots, with 100 unique combinations for each type. We also investigate disturbances in the operating environment of the swarm, where the swarm has to adapt to drastic changes in the number of resources available in the environment, and to one of the robots behaving disruptively towards the rest of the swarm, with 30 unique conditions for each such perturbation. The viability of SMBO and SMBO-Dec is demonstrated, comparing favourably to variants of random search and gradient descent, and various ablations, and improving performance up to 80% compared to the performance at the time of fault injection within at most 30 evaluations.
Encoding Defensive Driving as a Dynamic Nash Game
Nov 09, 2020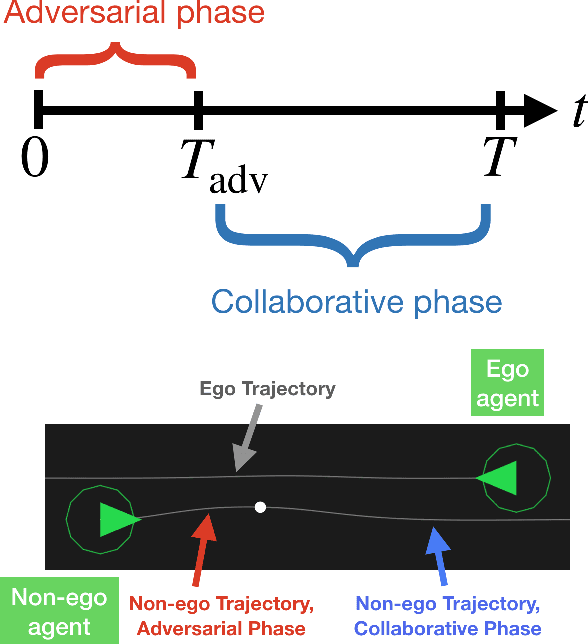
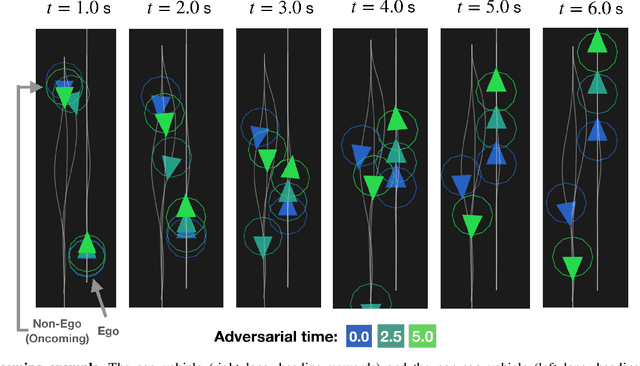
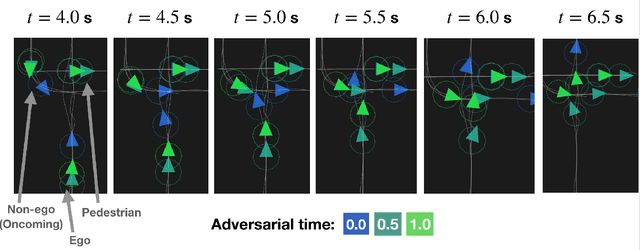
Robots deployed in real-world environments should operate safely in a robust manner. In scenarios where an "ego" agent navigates in an environment with multiple other "non-ego" agents, two modes of safety are commonly proposed: adversarial robustness and probabilistic constraint satisfaction. However, while the former is generally computationally-intractable and leads to overconservative solutions, the latter typically relies on strong distributional assumptions and ignores strategic coupling between agents. To avoid these drawbacks, we present a novel formulation of robustness within the framework of general sum dynamic game theory, modeled on defensive driving. More precisely, we inject the ego's cost function with an adversarial phase, a time interval during which other agents are assumed to be temporarily distracted, to robustify the ego agent's trajectory against other agents' potentially dangerous behavior during this time. We demonstrate the effectiveness of our new formulation in encoding safety via multiple traffic scenarios.
Visual diagnosis of the Varroa destructor parasitic mite in honeybees using object detector techniques
Feb 26, 2021
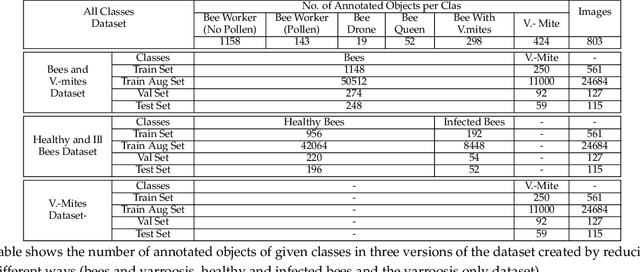

The Varroa destructor mite is one of the most dangerous Honey Bee (Apis mellifera) parasites worldwide and the bee colonies have to be regularly monitored in order to control its spread. Here we present an object detector based method for health state monitoring of bee colonies. This method has the potential for online measurement and processing. In our experiment, we compare the YOLO and SSD object detectors along with the Deep SVDD anomaly detector. Based on the custom dataset with 600 ground-truth images of healthy and infected bees in various scenes, the detectors reached a high F1 score up to 0.874 in the infected bee detection and up to 0.727 in the detection of the Varroa Destructor mite itself. The results demonstrate the potential of this approach, which will be later used in the real-time computer vision based honey bee inspection system. To the best of our knowledge, this study is the first one using object detectors for this purpose. We expect that performance of those object detectors will enable us to inspect the health status of the honey bee colonies.
Depth extraction from a single compressive hologram
Feb 26, 2021

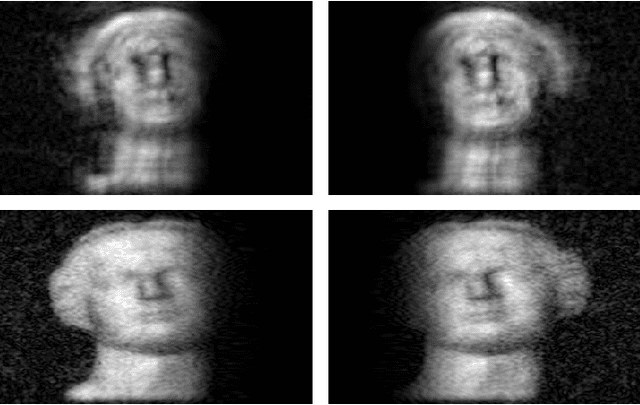

We propose a novel method that records a single compressive hologram in a short time and extracts the depth of a scene from that hologram using a stereo disparity technique. The method is verified with numerical simulations, but there is no restriction on adapting this into an optical experiment. In the simulations, a computer-generated hologram is first sampled with random binary patterns, and measurements are utilized in a recovery algorithm to form a compressive hologram. The compressive hologram is then divided into two parts (two apertures), and these parts are separately reconstructed to form a stereo image pair. The pair is eventually utilized in stereo disparity method for depth map extraction. The depth maps of the compressive holograms with the sampling rates of 2, 25, and 50 percent are compared with the depth map extracted from the original hologram, on which compressed sensing is not applied. It is demonstrated that the depth profiles obtained from the compressive holograms are in very good agreement with the depth profile obtained from the original hologram despite the data reduction.
Answer Identification in Collaborative Organizational Group Chat
Nov 04, 2020


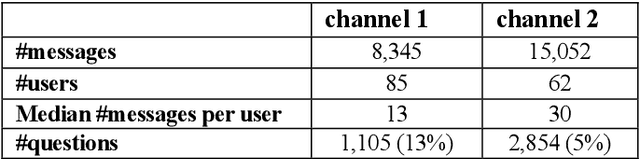
We present a simple unsupervised approach for answer identification in organizational group chat. In recent years, organizational group chat is on the rise enabling asynchronous text-based collaboration between co-workers in different locations and time zones. Finding answers to questions is often critical for work efficiency. However, group chat is characterized by intertwined conversations and 'always on' availability, making it hard for users to pinpoint answers to questions they care about in real-time or search for answers in retrospective. In addition, structural and lexical characteristics differ between chat groups, making it hard to find a 'one model fits all' approach. Our Kernel Density Estimation (KDE) based clustering approach termed Ans-Chat implicitly learns discussion patterns as a means for answer identification, thus eliminating the need to channel-specific tagging. Empirical evaluation shows that this solution outperforms other approached.
Capture the Bot: Using Adversarial Examples to Improve CAPTCHA Robustness to Bot Attacks
Nov 04, 2020



To this date, CAPTCHAs have served as the first line of defense preventing unauthorized access by (malicious) bots to web-based services, while at the same time maintaining a trouble-free experience for human visitors. However, recent work in the literature has provided evidence of sophisticated bots that make use of advancements in machine learning (ML) to easily bypass existing CAPTCHA-based defenses. In this work, we take the first step to address this problem. We introduce CAPTURE, a novel CAPTCHA scheme based on adversarial examples. While typically adversarial examples are used to lead an ML model astray, with CAPTURE, we attempt to make a "good use" of such mechanisms. Our empirical evaluations show that CAPTURE can produce CAPTCHAs that are easy to solve by humans while at the same time, effectively thwarting ML-based bot solvers.
ATM Cash demand forecasting in an Indian Bank with chaos and deep learning
Aug 24, 2020

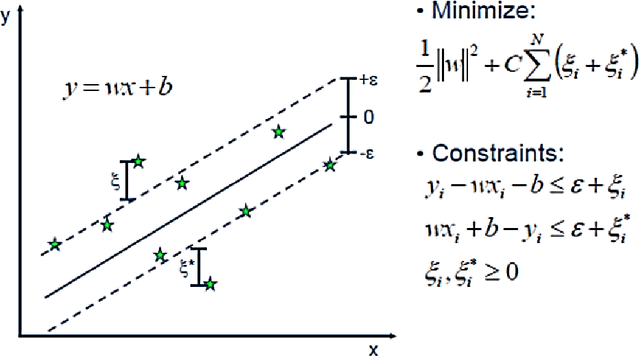
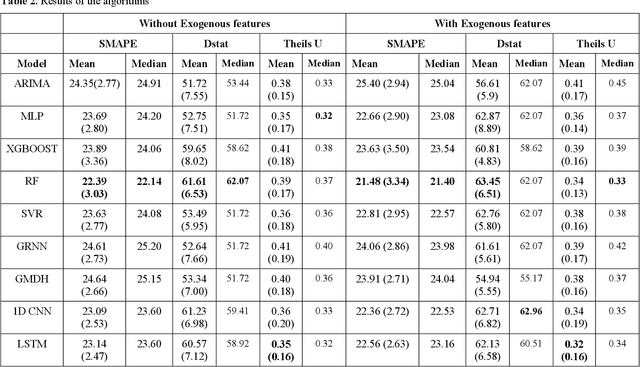
This paper proposes to model chaos in the ATM cash withdrawal time series of a big Indian bank and forecast the withdrawals using deep learning methods. It also considers the importance of day-of-the-week and includes it as a dummy exogenous variable. We first modelled the chaos present in the withdrawal time series by reconstructing the state space of each series using the lag, and embedding dimension found using an auto-correlation function and Cao's method. This process converts the uni-variate time series into multi variate time series. The "day-of-the-week" is converted into seven features with the help of one-hot encoding. Then these seven features are augmented to the multivariate time series. For forecasting the future cash withdrawals, using algorithms namely ARIMA, random forest (RF), support vector regressor (SVR), multi-layer perceptron (MLP), group method of data handling (GMDH), general regression neural network (GRNN), long short term memory neural network and 1-dimensional convolutional neural network. We considered a daily cash withdrawals data set from an Indian commercial bank. After modelling chaos and adding exogenous features to the data set, we observed improvements in the forecasting for all models. Even though the random forest (RF) yielded better Symmetric Mean Absolute Percentage Error (SMAPE) value, deep learning algorithms, namely LSTM and 1D CNN, showed similar performance compared to RF, based on t-test.
When Bots Take Over the Stock Market: Evasion Attacks Against Algorithmic Traders
Oct 19, 2020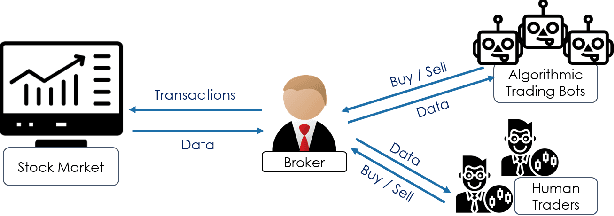
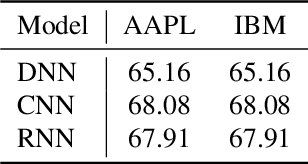
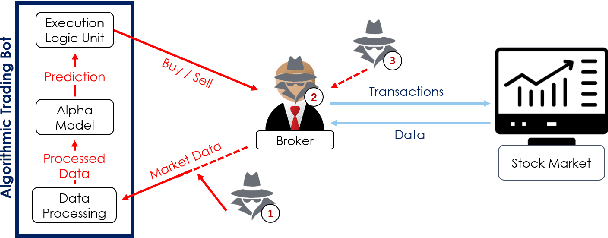
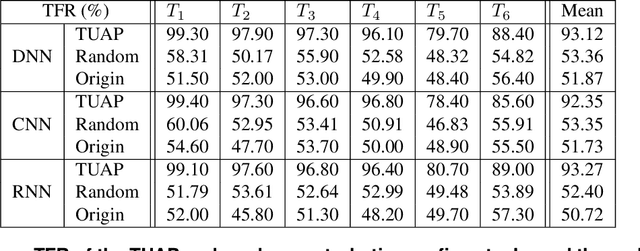
In recent years, machine learning has become prevalent in numerous tasks, including algorithmic trading. Stock market traders utilize learning models to predict the market's behavior and execute an investment strategy accordingly. However, learning models have been shown to be susceptible to input manipulations called adversarial examples. Yet, the trading domain remains largely unexplored in the context of adversarial learning. This is mainly because of the rapid changes in the market which impair the attacker's ability to create a real-time attack. In this study, we present a realistic scenario in which an attacker gains control of an algorithmic trading bots by manipulating the input data stream in real-time. The attacker creates an universal perturbation that is agnostic to the target model and time of use, while also remaining imperceptible. We evaluate our attack on a real-world market data stream and target three different trading architectures. We show that our perturbation can fool the model at future unseen data points, in both white-box and black-box settings. We believe these findings should serve as an alert to the finance community about the threats in this area and prompt further research on the risks associated with using automated learning models in the finance domain.
Efficient Client Contribution Evaluation for Horizontal Federated Learning
Feb 26, 2021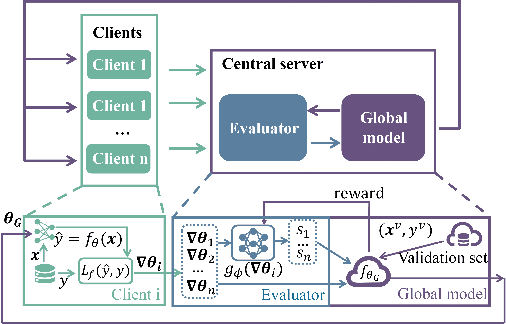

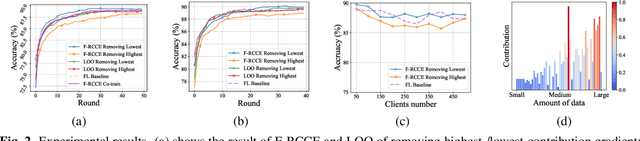
In federated learning (FL), fair and accurate measurement of the contribution of each federated participant is of great significance. The level of contribution not only provides a rational metric for distributing financial benefits among federated participants, but also helps to discover malicious participants that try to poison the FL framework. Previous methods for contribution measurement were based on enumeration over possible combination of federated participants. Their computation costs increase drastically with the number of participants or feature dimensions, making them inapplicable in practical situations. In this paper an efficient method is proposed to evaluate the contributions of federated participants. This paper focuses on the horizontal FL framework, where client servers calculate parameter gradients over their local data, and upload the gradients to the central server. Before aggregating the client gradients, the central server train a data value estimator of the gradients using reinforcement learning techniques. As shown by experimental results, the proposed method consistently outperforms the conventional leave-one-out method in terms of valuation authenticity as well as time complexity.
Pruning neural networks: is it time to nip it in the bud?
Oct 10, 2018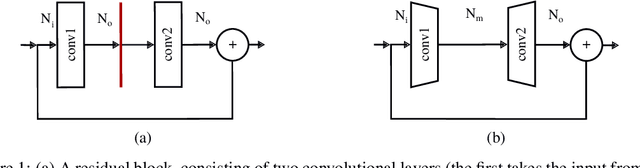
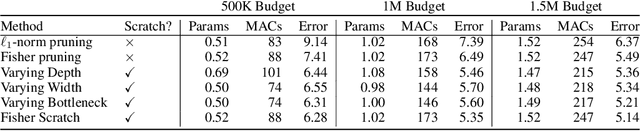
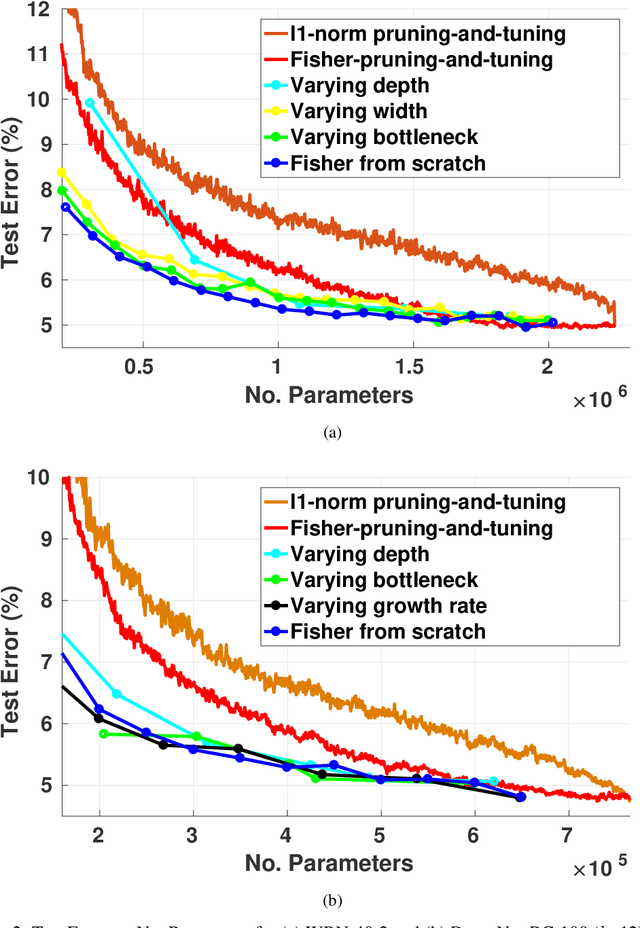
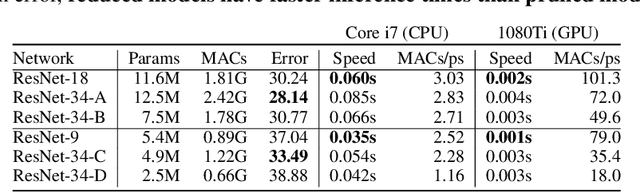
Pruning is a popular technique for compressing a neural network: a large pre-trained network is fine-tuned while connections are successively removed. However, the value of pruning has largely evaded scrutiny. In this extended abstract, we examine residual networks obtained through Fisher-pruning and make two interesting observations. First, when time-constrained, it is better to train a simple, smaller network from scratch than prune a large network. Second, it is the architectures obtained through the pruning process --- not the learnt weights ---that prove valuable. Such architectures are powerful when trained from scratch. Furthermore, these architectures are easy to approximate without any further pruning: we can prune once and obtain a family of new, scalable network architectures for different memory requirements.