 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
All NLP Tasks Are Generation Tasks: A General Pretraining Framework
Mar 18, 2021
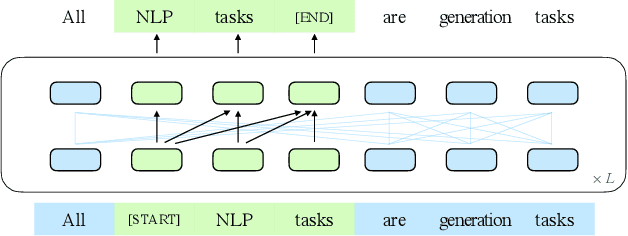
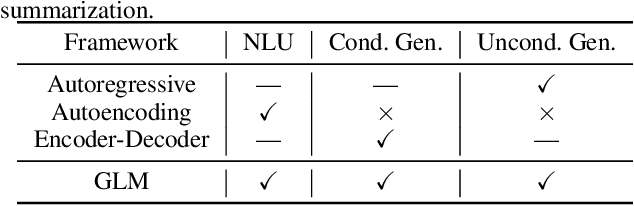
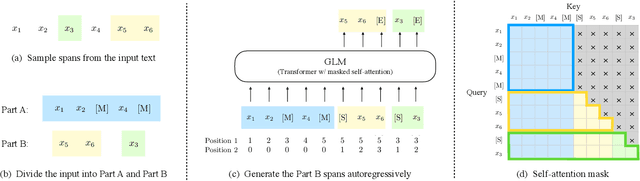
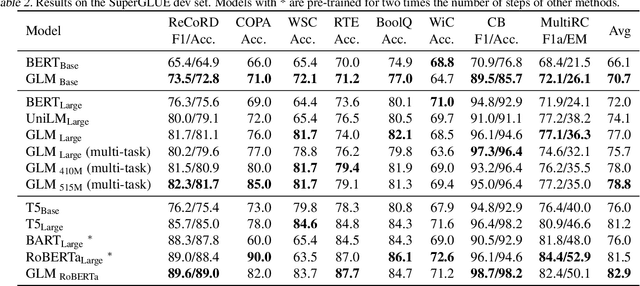
There have been various types of pretraining architectures including autoregressive models (e.g., GPT), autoencoding models (e.g., BERT), and encoder-decoder models (e.g., T5). On the other hand, NLP tasks are different in nature, with three main categories being classification, unconditional generation, and conditional generation. However, none of the pretraining frameworks performs the best for all tasks, which introduces inconvenience for model development and selection. We propose a novel pretraining framework GLM (General Language Model) to address this challenge. Compared to previous work, our architecture has three major benefits: (1) it performs well on classification, unconditional generation, and conditional generation tasks with one single pretrained model; (2) it outperforms BERT-like models on classification due to improved pretrain-finetune consistency; (3) it naturally handles variable-length blank filling which is crucial for many downstream tasks. Empirically, GLM substantially outperforms BERT on the SuperGLUE natural language understanding benchmark with the same amount of pre-training data. Moreover, GLM with 1.25x parameters of BERT-Large achieves the best performance in NLU, conditional and unconditional generation at the same time, which demonstrates its generalizability to different downstream tasks.
Localization of Cochlear Implant Electrodes from Cone Beam Computed Tomography using Particle Belief Propagation
Mar 18, 2021
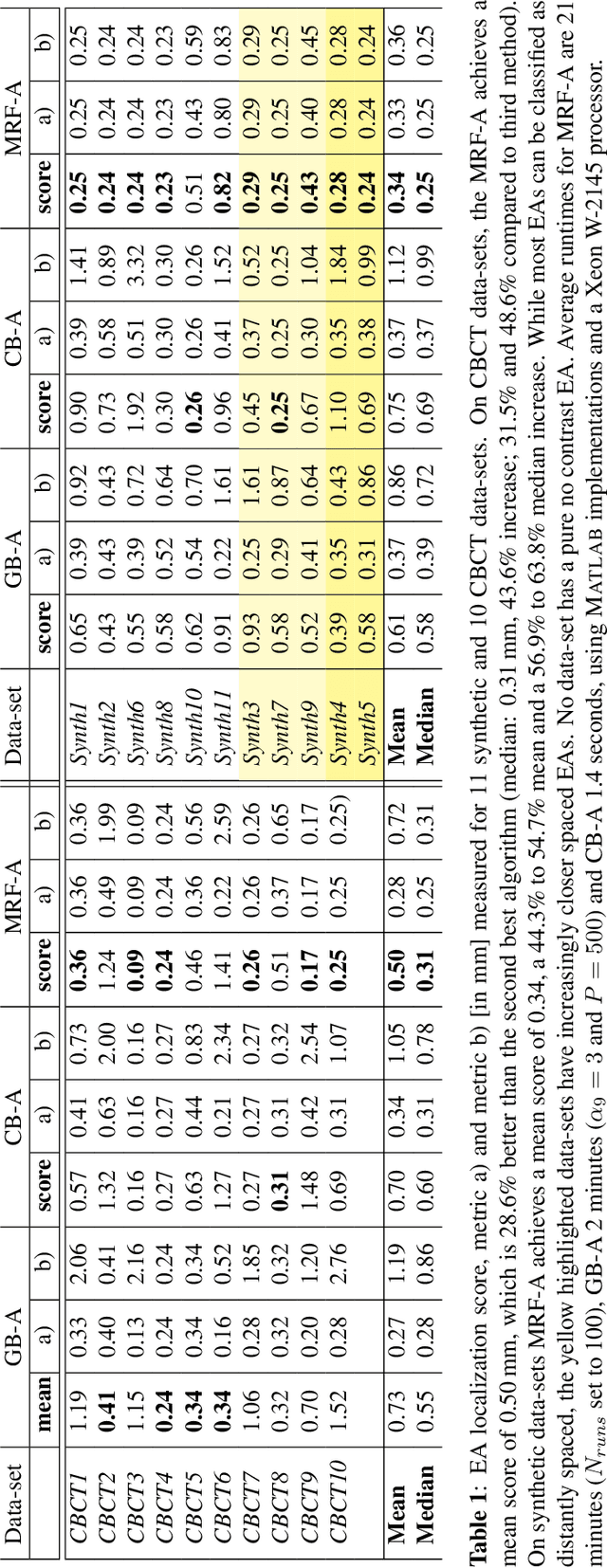
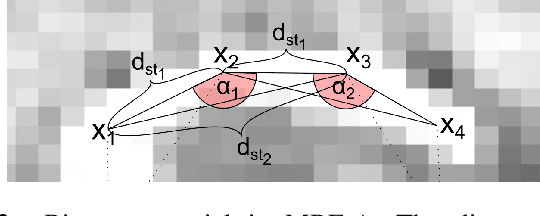
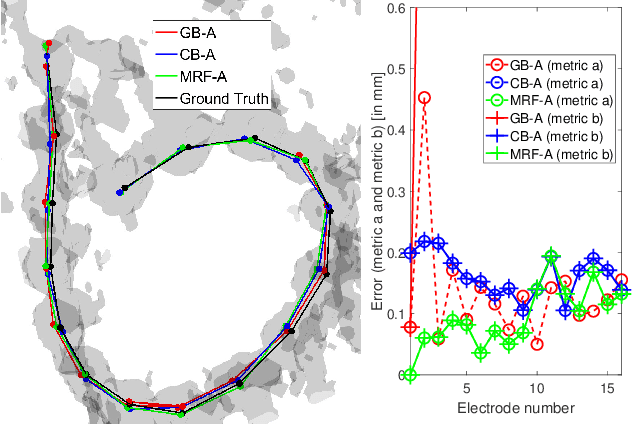
Cochlear implants (CIs) are implantable medical devices that can restore the hearing sense of people suffering from profound hearing loss. The CI uses a set of electrode contacts placed inside the cochlea to stimulate the auditory nerve with current pulses. The exact location of these electrodes may be an important parameter to improve and predict the performance with these devices. Currently the methods used in clinics to characterize the geometry of the cochlea as well as to estimate the electrode positions are manual, error-prone and time consuming. We propose a Markov random field (MRF) model for CI electrode localization for cone beam computed tomography (CBCT) data-sets. Intensity and shape of electrodes are included as prior knowledge as well as distance and angles between contacts. MRF inference is based on slice sampling particle belief propagation and guided by several heuristics. A stochastic search finds the best maximum a posteriori estimation among sampled MRF realizations. We evaluate our algorithm on synthetic and real CBCT data-sets and compare its performance with two state of the art algorithms. An increase of localization precision up to 31.5% (mean), or 48.6% (median) respectively, on real CBCT data-sets is shown.
Optimising Long-Term Outcomes using Real-World Fluent Objectives: An Application to Football
Feb 18, 2021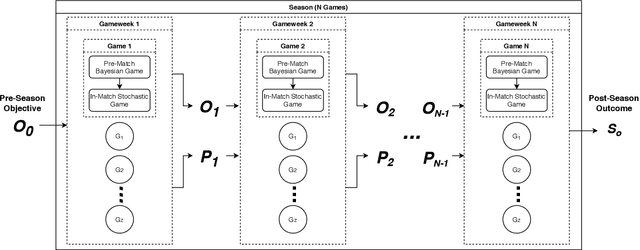
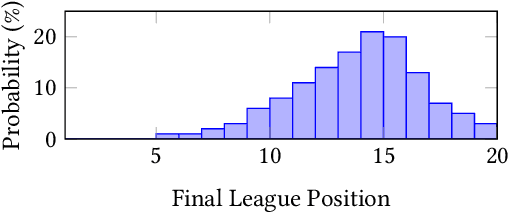
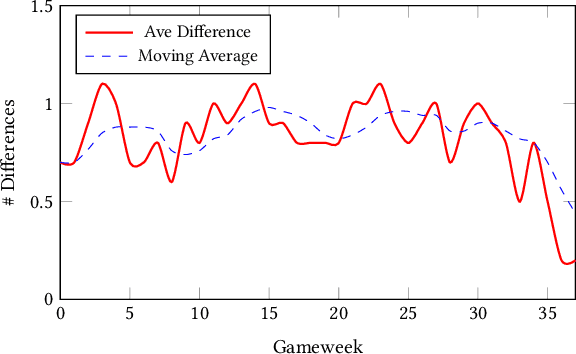
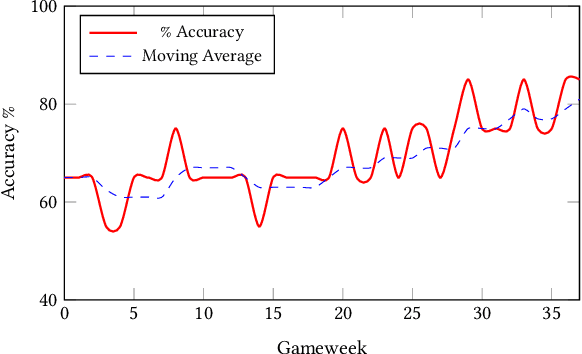
In this paper, we present a novel approach for optimising long-term tactical and strategic decision-making in football (soccer) by encapsulating events in a league environment across a given time frame. We model the teams' objectives for a season and track how these evolve as games unfold to give a fluent objective that can aid in decision-making games. We develop Markov chain Monte Carlo and deep learning-based algorithms that make use of the fluent objectives in order to learn from prior games and other games in the environment and increase the teams' long-term performance. Simulations of our approach using real-world datasets from 760 matches shows that by using optimised tactics with our fluent objective and prior games, we can on average increase teams mean expected finishing distribution in the league by up to 35.6%.
Real-time Kinematic Ground Truth for the Oxford RobotCar Dataset
Feb 24, 2020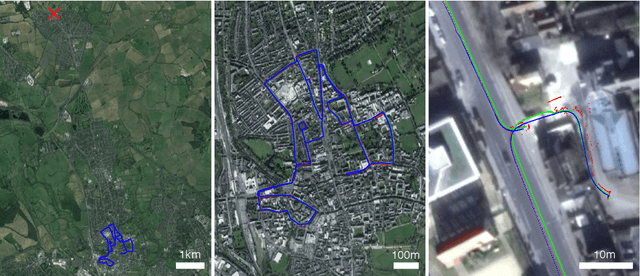

We describe the release of reference data towards a challenging long-term localisation and mapping benchmark based on the large-scale Oxford RobotCar Dataset. The release includes 72 traversals of a route through Oxford, UK, gathered in all illumination, weather and traffic conditions, and is representative of the conditions an autonomous vehicle would be expected to operate reliably in. Using post-processed raw GPS, IMU, and static GNSS base station recordings, we have produced a globally-consistent centimetre-accurate ground truth for the entire year-long duration of the dataset. Coupled with a planned online benchmarking service, we hope to enable quantitative evaluation and comparison of different localisation and mapping approaches focusing on long-term autonomy for road vehicles in urban environments challenged by changing weather.
Multi-Group Multicast Beamforming by Superiorized Projections onto Convex Sets
Feb 23, 2021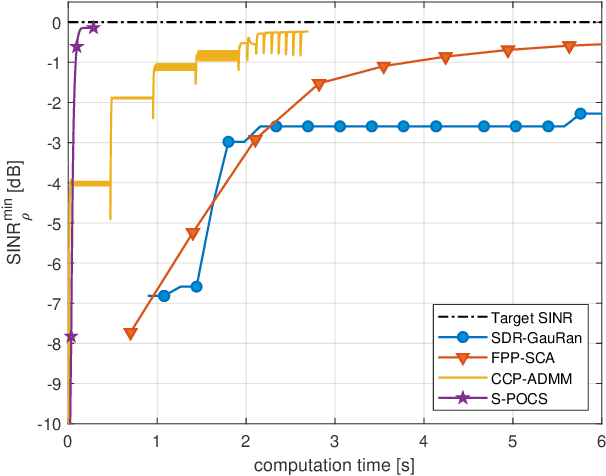
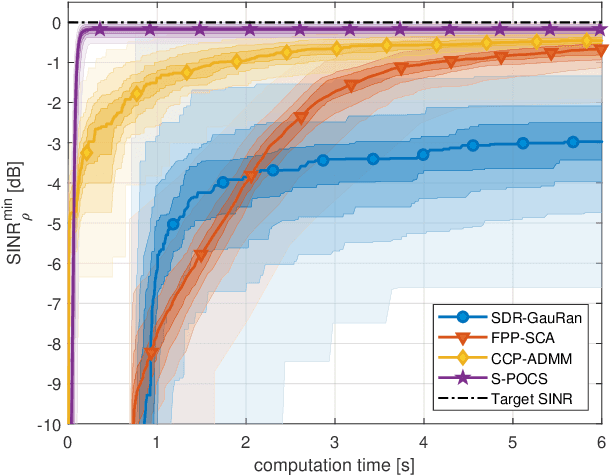
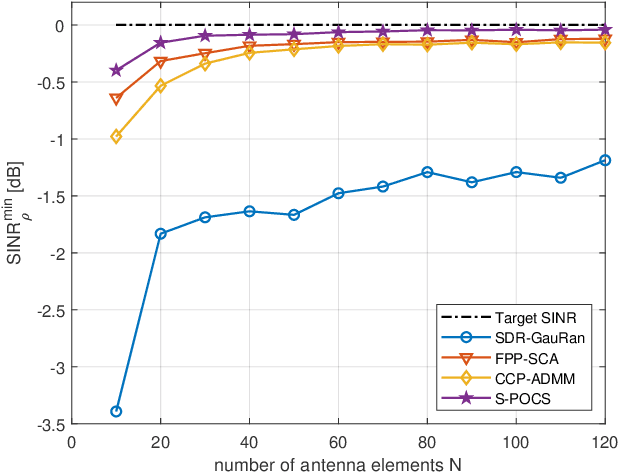
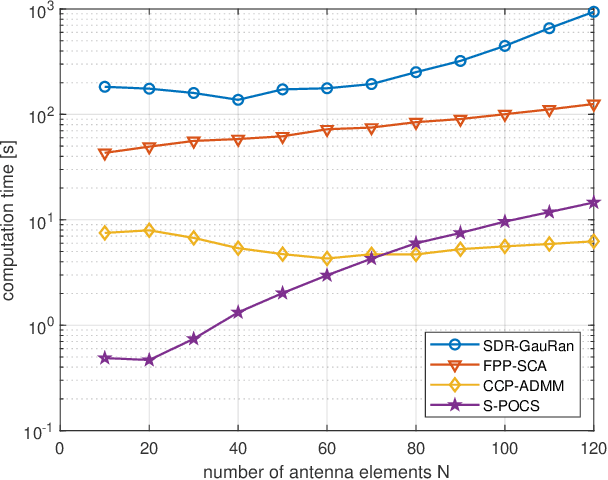
In this paper, we propose an iterative algorithm to address the nonconvex multi-group multicast beamforming problem with quality-of-service constraints and per-antenna power constraints. We formulate a convex relaxation of the problem as a semidefinite program in a real Hilbert space, which allows us to approximate a point in the feasible set by iteratively applying a bounded perturbation resilient fixed-point mapping. Inspired by the superiorization methodology, we use this mapping as a basic algorithm, and we add in each iteration a small perturbation with the intent to reduce the objective value and the distance to nonconvex rank-constraint sets. We prove that the sequence of perturbations is bounded, so the algorithm is guaranteed to converge to a feasible point of the relaxed semidefinite program. Simulations show that the proposed approach outperforms existing algorithms in terms of both computation time and approximation gap in many cases.
Parameter Experimental Analysis of the Reservoirs Observers using Echo State Network Approach
Sep 28, 2020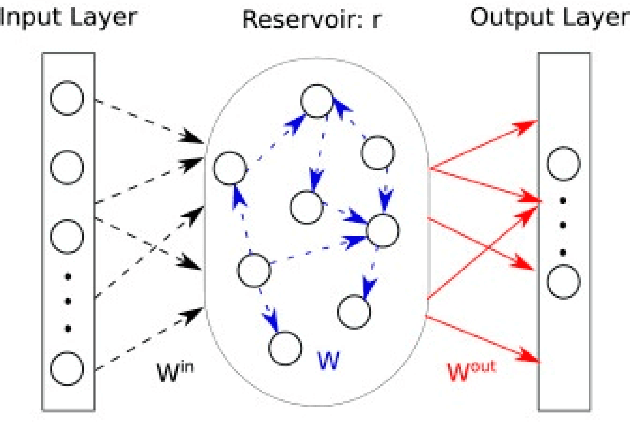
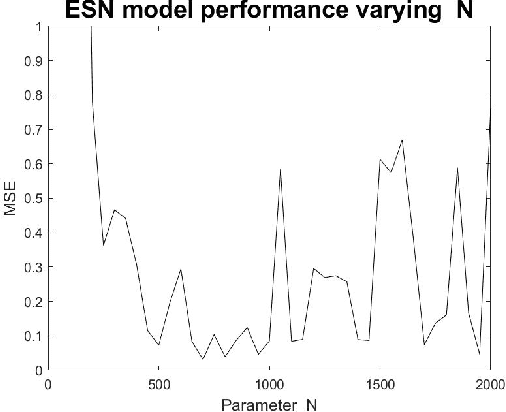
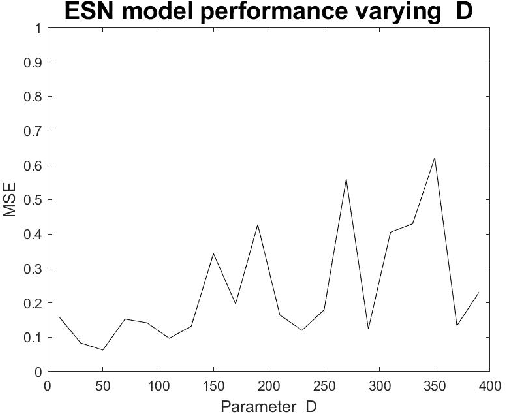
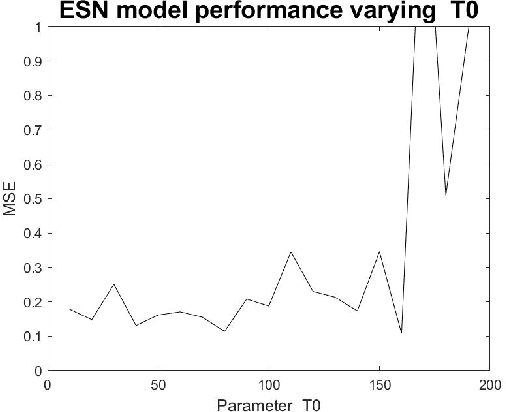
Dynamical systems has a variety of applications for the new information generated during the time. Many phenomenons like physical, chemical or social are not static, then an analysis over the time is necessary. In this work, an experimental analysis of parameters of the model Echo State Network is performed and the influence of the kind of Complex Network is explored to understand the influence on the performance. The experiments are performed using the Rossler attractor.
A Methodology for Approaching the Integration of Complex Robotics Systems Illustrated through a Bi-manual Manipulation Case-Study
Mar 18, 2021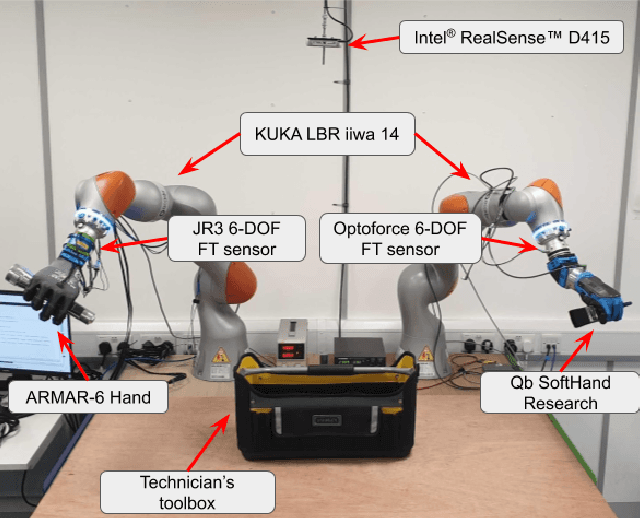
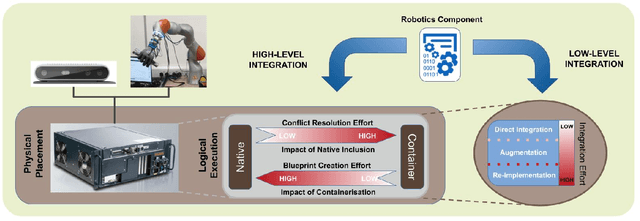
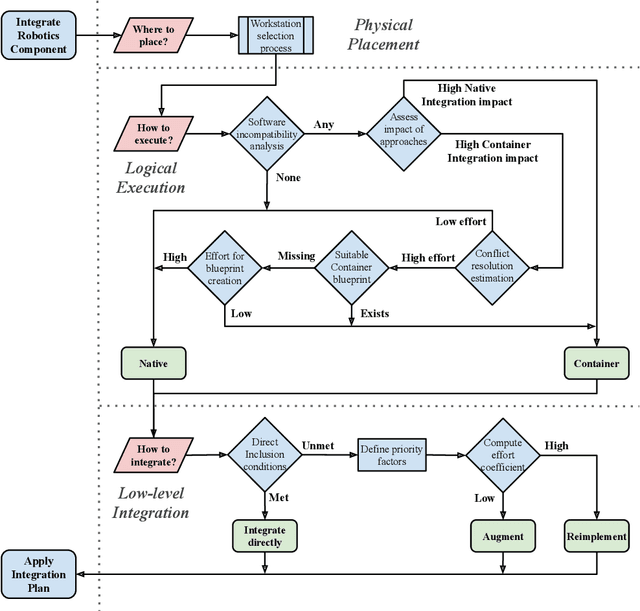

The multidisciplinarity of robotics creates a need for robust integration methodologies that can facilitate the adoption of state-of-the-art research components in an industrial application. Unfortunately, there are no clear, community accepted guidelines or standards that define the integration of such components in a single robotic system. In this paper, we propose a methodology that assesses the software components of a candidate system on the basis of the effort required to integrate them and the impact their integration will have on a target system. We demonstrate how this methodology can be applied using an industrial tool packing system as an example. The system integrates a wide range of both in-house and third-party research outputs and software components. We prove the effectiveness of our approach by evaluating system performance with an experimental benchmark that assesses the robustness, reliability and operational speed of the system for the given packing task. We also demonstrate how our methodology can be used to predict the amount of integration time required for a component. The proposed integration methodology can be applied to any robotic system to facilitate its transition from the research to an industrial environment.
Hardness of Learning Halfspaces with Massart Noise
Dec 17, 2020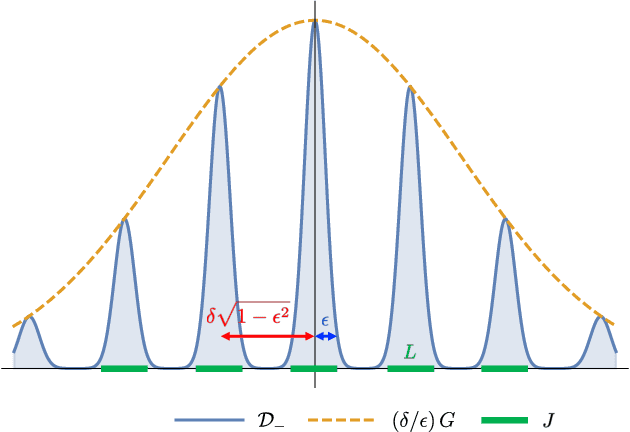
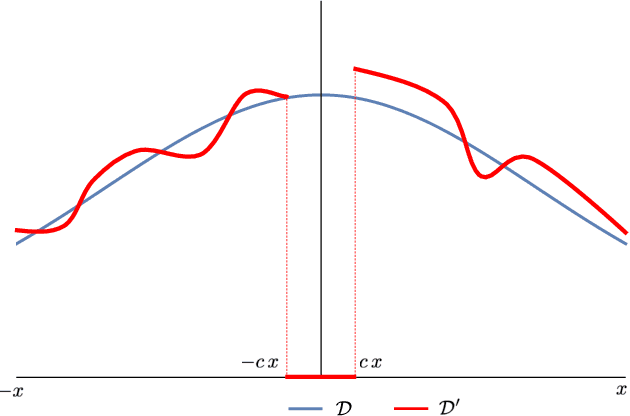
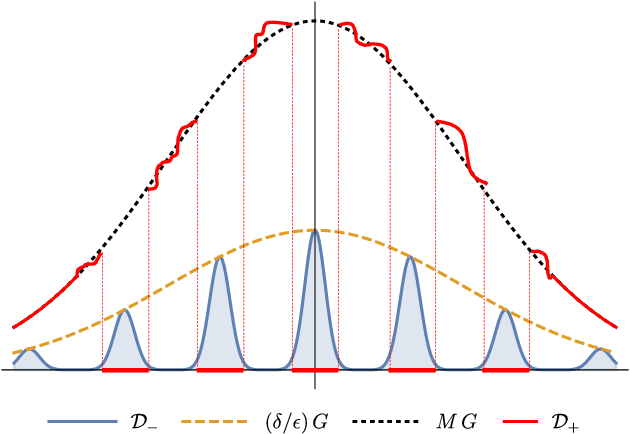
We study the complexity of PAC learning halfspaces in the presence of Massart (bounded) noise. Specifically, given labeled examples $(x, y)$ from a distribution $D$ on $\mathbb{R}^{n} \times \{ \pm 1\}$ such that the marginal distribution on $x$ is arbitrary and the labels are generated by an unknown halfspace corrupted with Massart noise at rate $\eta<1/2$, we want to compute a hypothesis with small misclassification error. Characterizing the efficient learnability of halfspaces in the Massart model has remained a longstanding open problem in learning theory. Recent work gave a polynomial-time learning algorithm for this problem with error $\eta+\epsilon$. This error upper bound can be far from the information-theoretically optimal bound of $\mathrm{OPT}+\epsilon$. More recent work showed that {\em exact learning}, i.e., achieving error $\mathrm{OPT}+\epsilon$, is hard in the Statistical Query (SQ) model. In this work, we show that there is an exponential gap between the information-theoretically optimal error and the best error that can be achieved by a polynomial-time SQ algorithm. In particular, our lower bound implies that no efficient SQ algorithm can approximate the optimal error within any polynomial factor.
Ultra-Fast Shapelets for Time Series Classification
Mar 17, 2015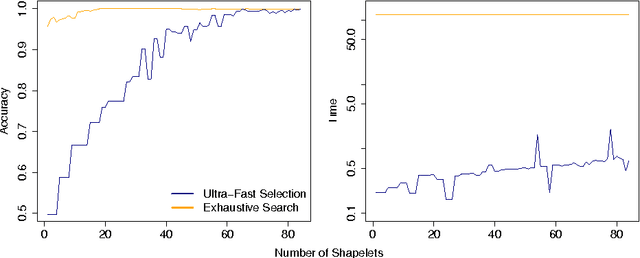
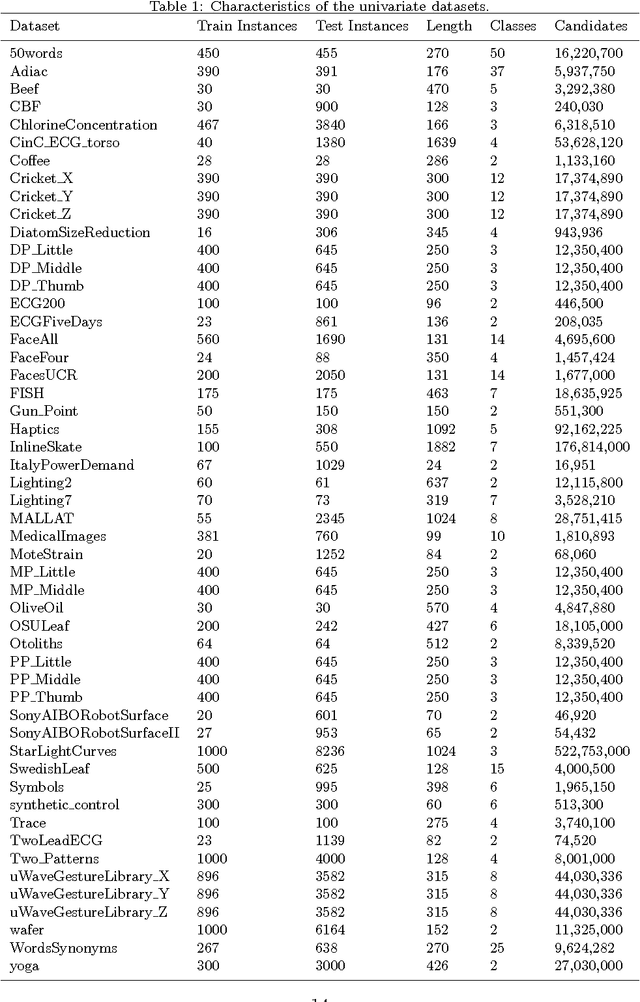
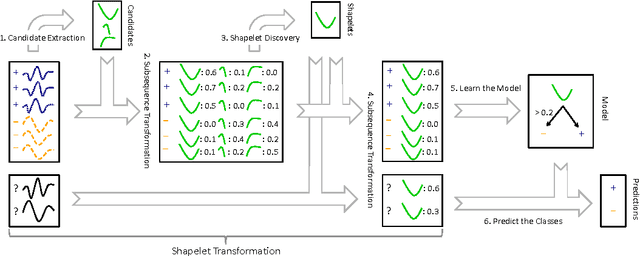
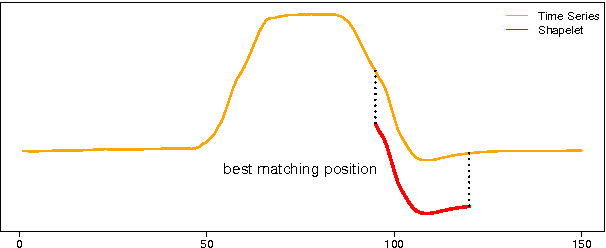
Time series shapelets are discriminative subsequences and their similarity to a time series can be used for time series classification. Since the discovery of time series shapelets is costly in terms of time, the applicability on long or multivariate time series is difficult. In this work we propose Ultra-Fast Shapelets that uses a number of random shapelets. It is shown that Ultra-Fast Shapelets yield the same prediction quality as current state-of-the-art shapelet-based time series classifiers that carefully select the shapelets by being by up to three orders of magnitudes. Since this method allows a ultra-fast shapelet discovery, using shapelets for long multivariate time series classification becomes feasible. A method for using shapelets for multivariate time series is proposed and Ultra-Fast Shapelets is proven to be successful in comparison to state-of-the-art multivariate time series classifiers on 15 multivariate time series datasets from various domains. Finally, time series derivatives that have proven to be useful for other time series classifiers are investigated for the shapelet-based classifiers. It is shown that they have a positive impact and that they are easy to integrate with a simple preprocessing step, without the need of adapting the shapelet discovery algorithm.
Assessing the effect of advertising expenditures upon sales: a Bayesian structural time series model
Apr 23, 2018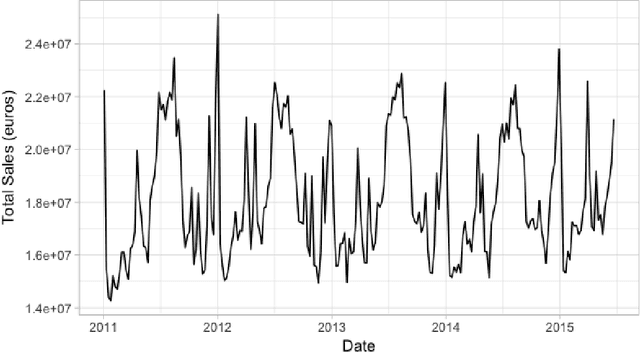
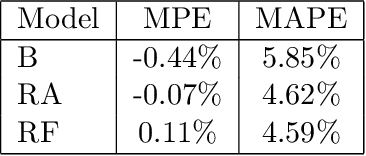
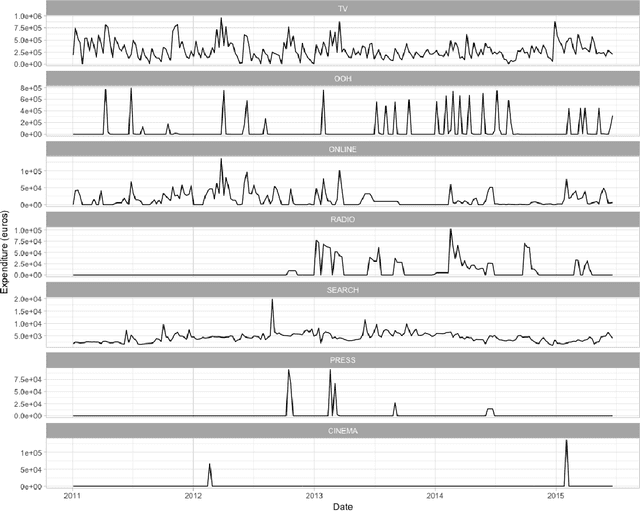
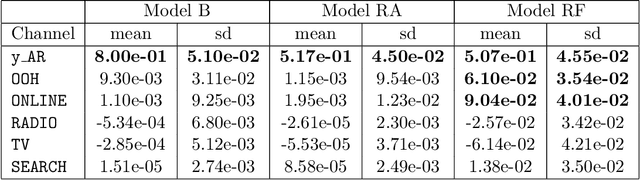
We propose a robust implementation of the Nerlove--Arrow model using a Bayesian structural time series model to explain the relationship between advertising expenditures of a country-wide fast-food franchise network with its weekly sales. Thanks to the flexibility and modularity of the model, it is well suited to generalization to other markets or situations. Its Bayesian nature facilitates incorporating \emph{a priori} information (the manager's views), which can be updated with relevant data. This aspect of the model will be used to present a strategy of budget scheduling across time and channels.