 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardness of Learning Halfspaces with Massart Noise
Paper and Code
Dec 17, 2020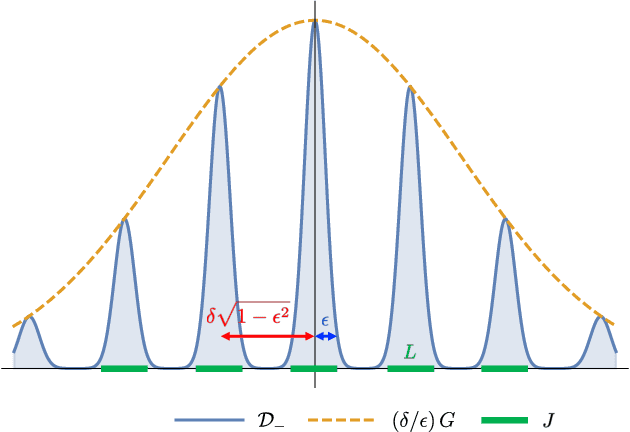
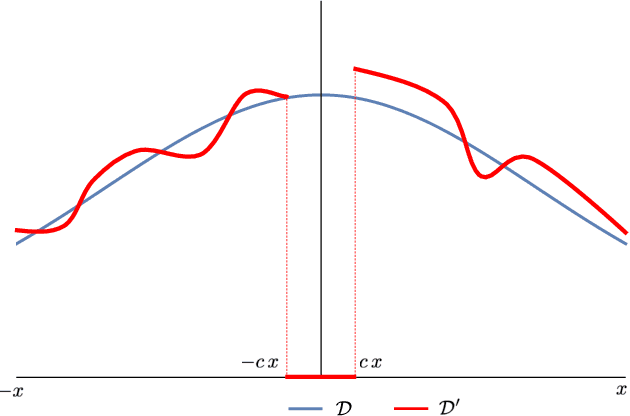
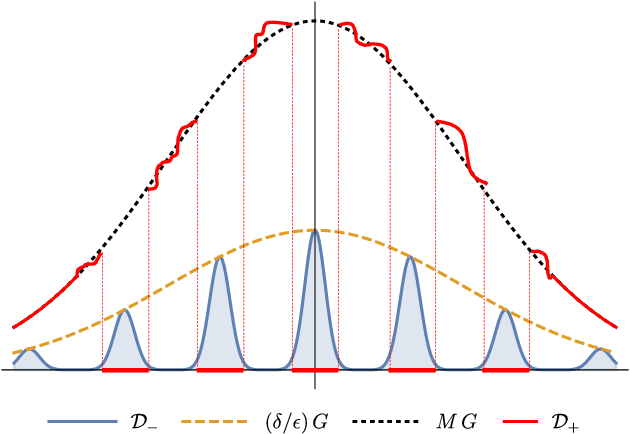
We study the complexity of PAC learning halfspaces in the presence of Massart (bounded) noise. Specifically, given labeled examples $(x, y)$ from a distribution $D$ on $\mathbb{R}^{n} \times \{ \pm 1\}$ such that the marginal distribution on $x$ is arbitrary and the labels are generated by an unknown halfspace corrupted with Massart noise at rate $\eta<1/2$, we want to compute a hypothesis with small misclassification error. Characterizing the efficient learnability of halfspaces in the Massart model has remained a longstanding open problem in learning theory. Recent work gave a polynomial-time learning algorithm for this problem with error $\eta+\epsilon$. This error upper bound can be far from the information-theoretically optimal bound of $\mathrm{OPT}+\epsilon$. More recent work showed that {\em exact learning}, i.e., achieving error $\mathrm{OPT}+\epsilon$, is hard in the Statistical Query (SQ) model. In this work, we show that there is an exponential gap between the information-theoretically optimal error and the best error that can be achieved by a polynomial-time SQ algorithm. In particular, our lower bound implies that no efficient SQ algorithm can approximate the optimal error within any polynomial factor.