 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-view data capture for dynamic object reconstruction using handheld augmented reality mobiles
Mar 20, 2021
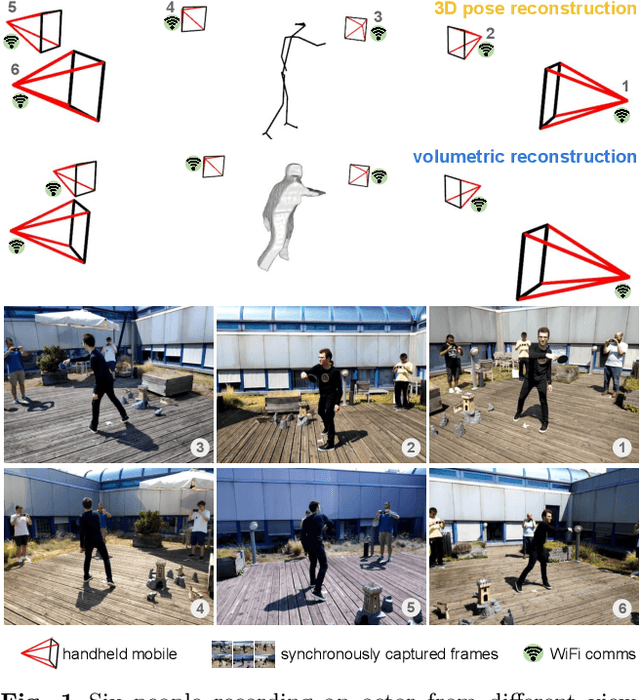

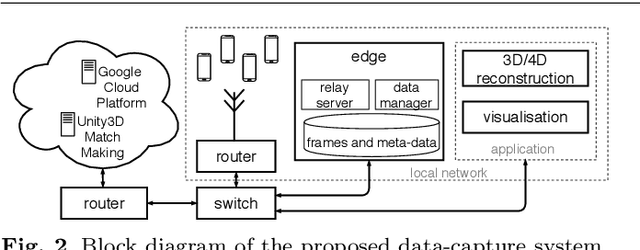

We propose a system to capture nearly-synchronous frame streams from multiple and moving handheld mobiles that is suitable for dynamic object 3D reconstruction. Each mobile executes Simultaneous Localisation and Mapping on-board to estimate its pose, and uses a wireless communication channel to send or receive synchronisation triggers. Our system can harvest frames and mobile poses in real time using a decentralised triggering strategy and a data-relay architecture that can be deployed either at the Edge or in the Cloud. We show the effectiveness of our system by employing it for 3D skeleton and volumetric reconstructions. Our triggering strategy achieves equal performance to that of an NTP-based synchronisation approach, but offers higher flexibility, as it can be adjusted online based on application needs. We created a challenging new dataset, namely 4DM, that involves six handheld augmented reality mobiles recording an actor performing sports actions outdoors. We validate our system on 4DM, analyse its strengths and limitations, and compare its modules with alternative ones.
Spectral Machine Learning for Pancreatic Mass Imaging Classification
May 03, 2021
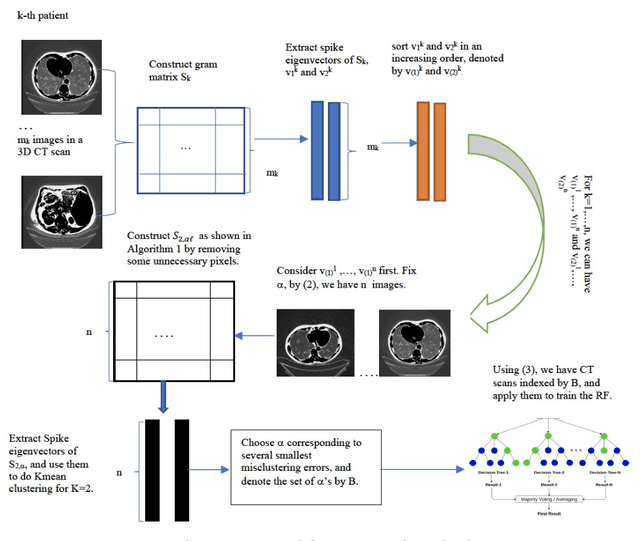
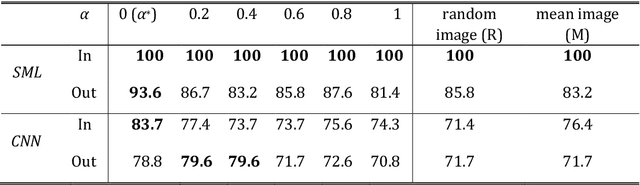
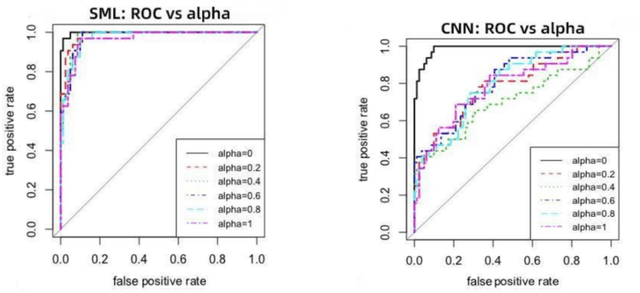
We present a novel spectral machine learning (SML) method in screening for pancreatic mass using CT imaging. Our algorithm is trained with approximately 30,000 images from 250 patients (50 patients with normal pancreas and 200 patients with abnormal pancreas findings) based on public data sources. A test accuracy of 94.6 percents was achieved in the out-of-sample diagnosis classification based on a total of approximately 15,000 images from 113 patients, whereby 26 out of 32 patients with normal pancreas and all 81 patients with abnormal pancreas findings were correctly diagnosed. SML is able to automatically choose fundamental images (on average 5 or 9 images for each patient) in the diagnosis classification and achieve the above mentioned accuracy. The computational time is 75 seconds for diagnosing 113 patients in a laptop with standard CPU running environment. Factors that influenced high performance of a well-designed integration of spectral learning and machine learning included: 1) use of eigenvectors corresponding to several of the largest eigenvalues of sample covariance matrix (spike eigenvectors) to choose input attributes in classification training, taking into account only the fundamental information of the raw images with less noise; 2) removal of irrelevant pixels based on mean-level spectral test to lower the challenges of memory capacity and enhance computational efficiency while maintaining superior classification accuracy; 3) adoption of state-of-the-art machine learning classification, gradient boosting and random forest. Our methodology showcases practical utility and improved accuracy of image diagnosis in pancreatic mass screening in the era of AI.
VID-WIN: Fast Video Event Matching with Query-Aware Windowing at the Edge for the Internet of Multimedia Things
Apr 27, 2021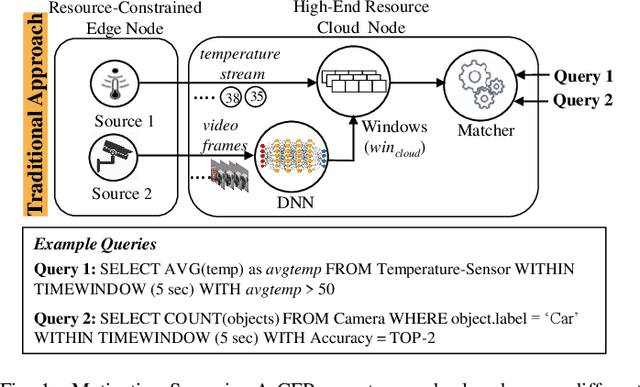
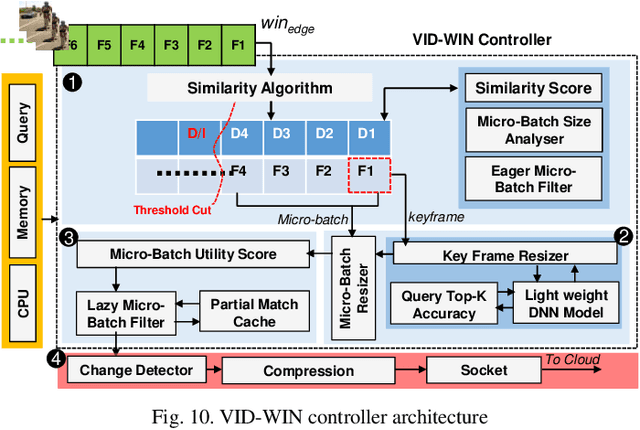
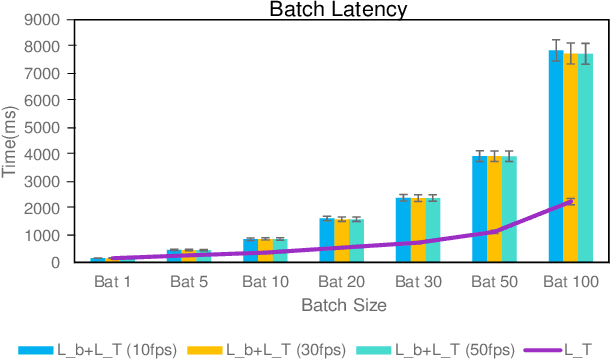
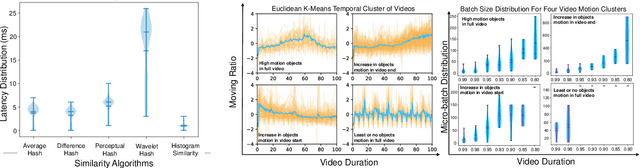
Efficient video processing is a critical component in many IoMT applications to detect events of interest. Presently, many window optimization techniques have been proposed in event processing with an underlying assumption that the incoming stream has a structured data model. Videos are highly complex due to the lack of any underlying structured data model. Video stream sources such as CCTV cameras and smartphones are resource-constrained edge nodes. At the same time, video content extraction is expensive and requires computationally intensive Deep Neural Network (DNN) models that are primarily deployed at high-end (or cloud) nodes. This paper presents VID-WIN, an adaptive 2-stage allied windowing approach to accelerate video event analytics in an edge-cloud paradigm. VID-WIN runs parallelly across edge and cloud nodes and performs the query and resource-aware optimization for state-based complex event matching. VID-WIN exploits the video content and DNN input knobs to accelerate the video inference process across nodes. The paper proposes a novel content-driven micro-batch resizing, queryaware caching and micro-batch based utility filtering strategy of video frames under resource-constrained edge nodes to improve the overall system throughput, latency, and network usage. Extensive evaluations are performed over five real-world datasets. The experimental results show that VID-WIN video event matching achieves ~2.3X higher throughput with minimal latency and ~99% bandwidth reduction compared to other baselines while maintaining query-level accuracy and resource bounds.
Multi-Robot Pickup and Delivery via Distributed Resource Allocation
Apr 06, 2021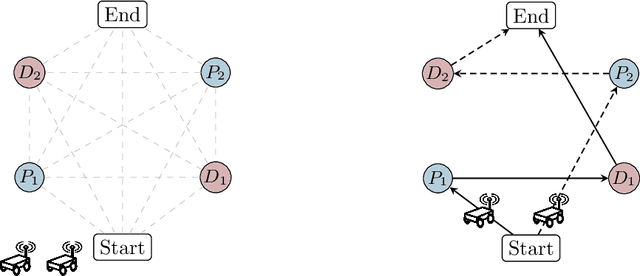
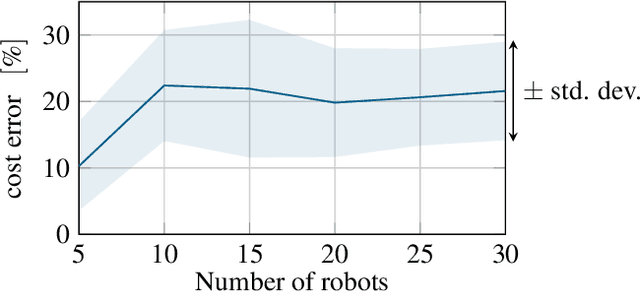
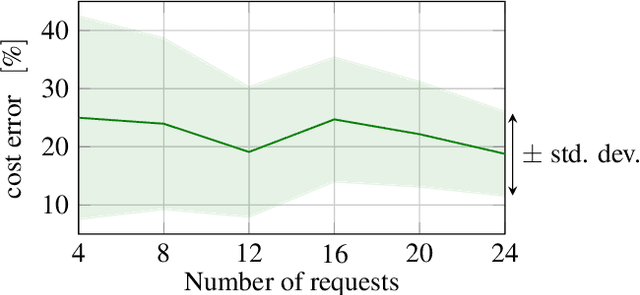
In this paper, we consider a large-scale instance of the classical Pickup-and-Delivery Vehicle Routing Problem (PDVRP) that must be solved by a network of mobile cooperating robots. Robots must self-coordinate and self-allocate a set of pickup/delivery tasks while minimizing a given cost figure. This results in a large, challenging Mixed-Integer Linear Problem that must be cooperatively solved without a central coordinator. We propose a distributed algorithm based on a primal decomposition approach that provides a feasible solution to the problem in finite time. An interesting feature of the proposed scheme is that each robot computes only its portion of solution, thereby preserving privacy of sensible information. The algorithm also exhibits attractive scalability properties that guarantee solvability of the problem even in large networks. To the best of our knowledge, this is the first attempt to provide a scalable distributed solution to the problem. The algorithm is first tested through Gazebo simulations on a ROS 2 platform, highlighting the effectiveness of the proposed solution. Finally, experiments on a real testbed with a team of ground and aerial robots are provided.
Fooling LiDAR Perception via Adversarial Trajectory Perturbation
Mar 29, 2021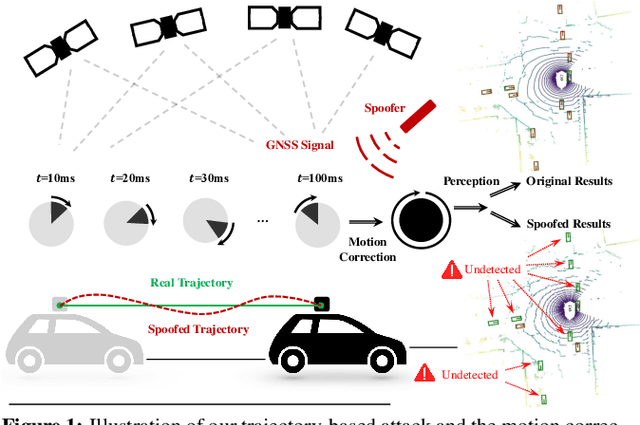
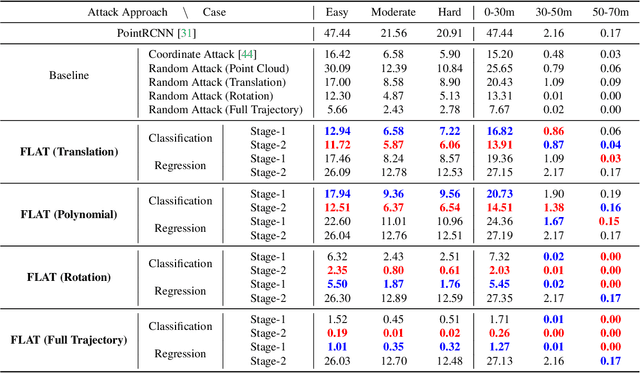
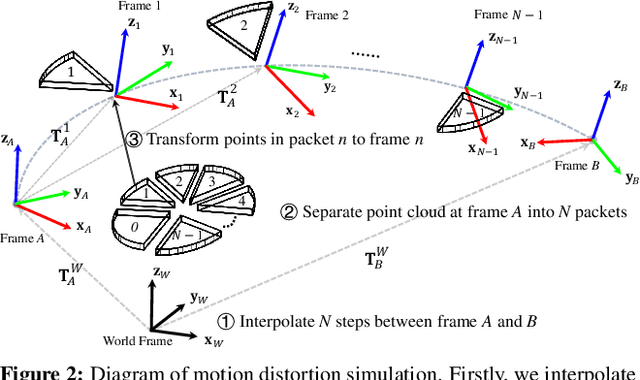
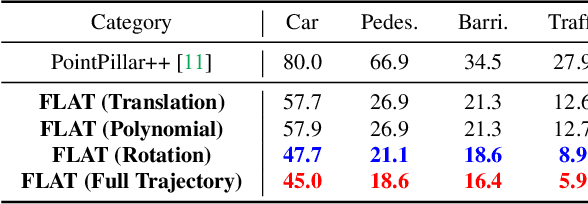
LiDAR point clouds collected from a moving vehicle are functions of its trajectories, because the sensor motion needs to be compensated to avoid distortions. When autonomous vehicles are sending LiDAR point clouds to deep networks for perception and planning, could the motion compensation consequently become a wide-open backdoor in those networks, due to both the adversarial vulnerability of deep learning and GPS-based vehicle trajectory estimation that is susceptible to wireless spoofing? We demonstrate such possibilities for the first time: instead of directly attacking point cloud coordinates which requires tampering with the raw LiDAR readings, only adversarial spoofing of a self-driving car's trajectory with small perturbations is enough to make safety-critical objects undetectable or detected with incorrect positions. Moreover, polynomial trajectory perturbation is developed to achieve a temporally-smooth and highly-imperceptible attack. Extensive experiments on 3D object detection have shown that such attacks not only lower the performance of the state-of-the-art detectors effectively, but also transfer to other detectors, raising a red flag for the community. The code is available on https://ai4ce.github.io/FLAT/.
Energy-Constrained Delivery of Goods with Drones Under Varying Wind Conditions
Dec 17, 2020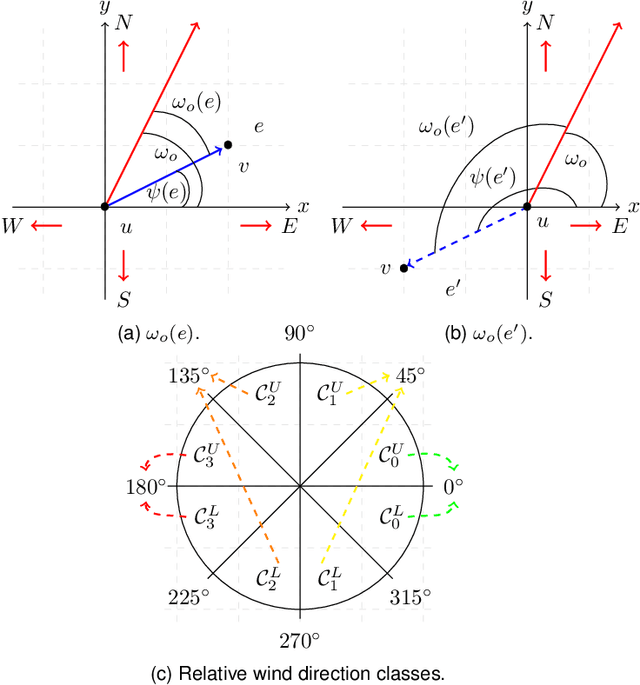
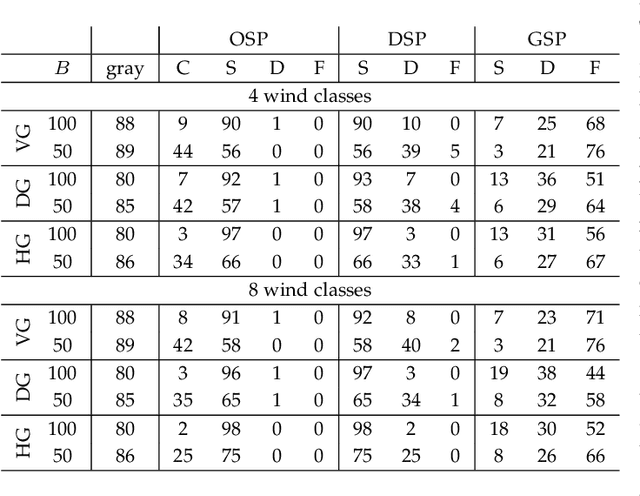
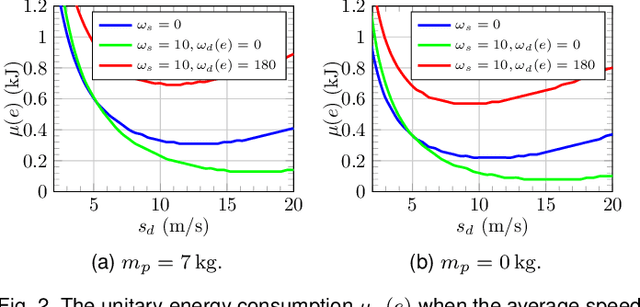
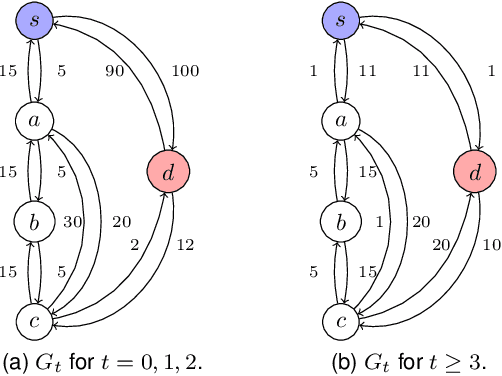
In this paper, we study the feasibility of sending drones to deliver goods from a depot to a customer by solving what we call the Mission-Feasibility Problem (MFP). Due to payload constraints, the drone can serve only one customer at a time. To this end, we propose a novel framework based on time-dependent cost graphs to properly model the MFP and tackle the delivery dynamics. When the drone moves in the delivery area, the global wind may change thereby affecting the drone's energy consumption, which in turn can increase or decrease. This issue is addressed by designing three algorithms, namely: (i) compute the route of minimum energy once, at the beginning of the mission, (ii) dynamically reconsider the most convenient trip towards the destination, and (iii) dynamically select only the best local choice. We evaluate the performance of our algorithms on both synthetic and real-world data. The changes in the drone's energy consumption are reflected by changes in the cost of the edges of the graphs. The algorithms receive the new costs every time the drone flies over a new vertex, and they have no full knowledge in advance of the weights. We compare them in terms of the percentage of missions that are completed with success (the drone delivers the goods and comes back to the depot), with delivered (the drone delivers the goods but cannot come back to the depot), and with failure (the drone neither delivers the goods nor comes back to the depot).
* typo author's name
3D Dilated Multi-Fiber Network for Real-time Brain Tumor Segmentation in MRI
Apr 06, 2019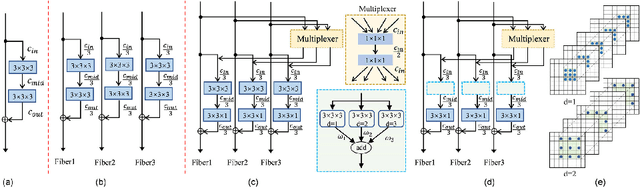
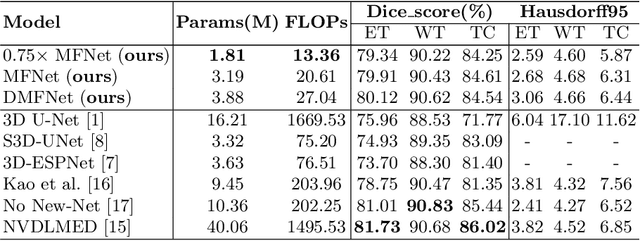
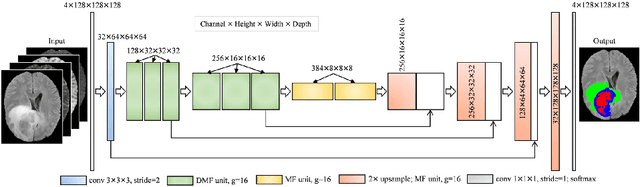
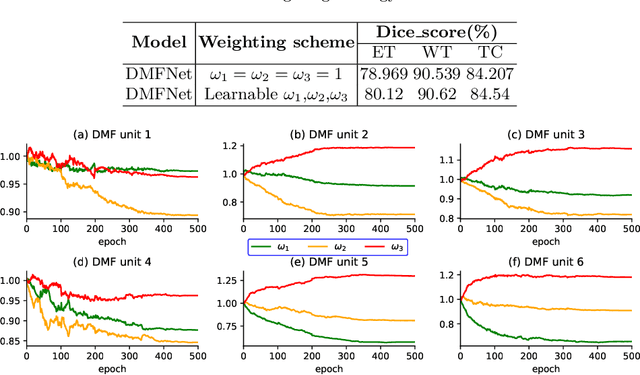
Brain tumor segmentation plays a pivotal role in medical image processing. In this work, we aim to segment brain MRI volumes. 3D convolution neural networks (CNN) such as 3D U-Net and V-Net employing 3D convolutions to capture the correlation between adjacent slices have achieved impressive segmentation results. However, these 3D CNN architectures come with high computational overheads due to multiple layers of 3D convolutions, which may make these models prohibitive for practical large-scale applications. To this end, we propose a highly efficient 3D CNN to achieve real-time dense volumetric segmentation. The network leverages the 3D multi-fiber unit which consists of an ensemble of lightweight 3D convolutional networks to significantly reduce the computational cost. Moreover, 3D dilated convolutions are used to build multi-scale feature representations. Extensive experimental results on the BraTS-2018 challenge dataset show that the proposed architecture greatly reduces computation cost while maintaining high accuracy for brain tumor segmentation. Our code will be released soon.
Structural Health Monitoring system with Narrowband IoT and MEMS sensors
Apr 27, 2021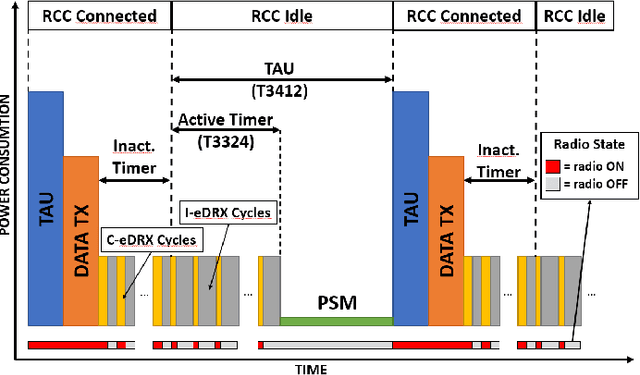
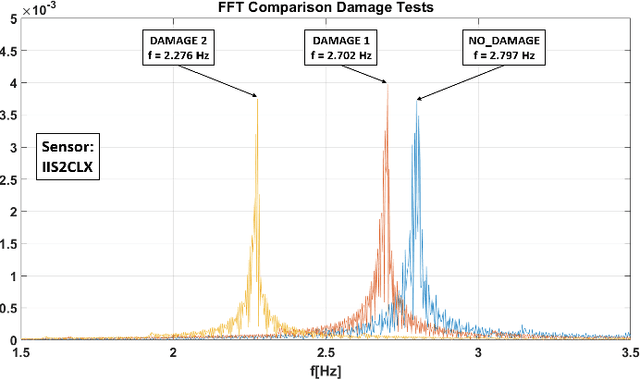
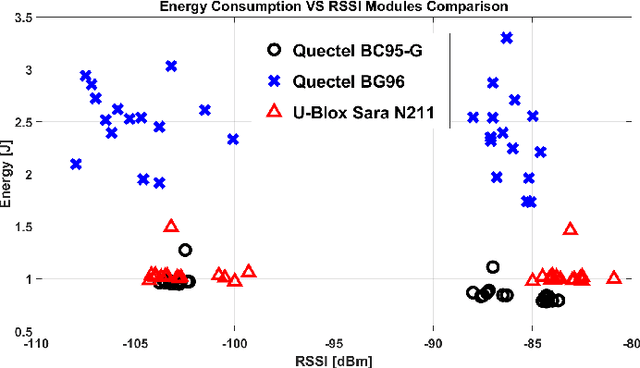
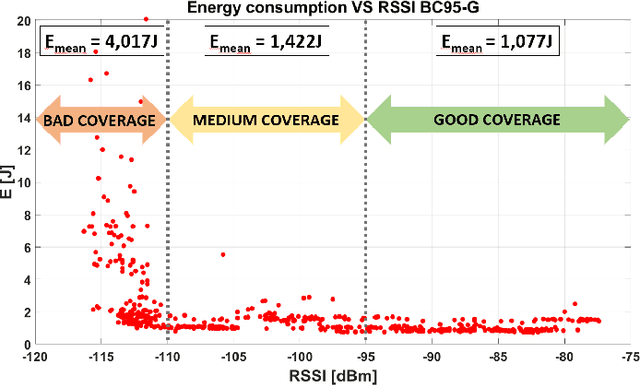
Monitoring of civil infrastructures is critically needed to track aging, damages and ultimately to prevent severe failures which can endanger many lives. The ability to monitor in a continuous and fine-grained fashion the integrity of a wide variety of buildings, referred to as structural health monitoring, with low-cost, long-term and continuous measurements is essential from both an economic and a life-safety standpoint. To address these needs, we propose a low-cost wireless sensor node specifically designed to support modal analysis over extended periods of time with long-range connectivity at low power consumption. Our design uses very cost-effective MEMS accelerometers and exploits the Narrowband IoT protocol (NB-IoT) to establish long-distance connection with 4G infrastructure networks. Long-range wireless connectivity, cabling-free installation and multi-year lifetime are a unique combination of features, not available, to the best of our knowledge, in any commercial or research device. We discuss in detail the hardware architecture and power management of the node. Experimental tests demonstrate a lifetime of more than ten years with a 17000 mAh battery or completely energy-neutral operation with a small solar panel (60 mm x 120 mm). Further, we validate measurement accuracy and confirm the feasibility of modal analysis with the MEMS sensors: compared with a high-precision instrument based on a piezoelectric transducer, our sensor node achieves a maximum difference of 0.08% at a small fraction of the cost and power consumption.
UAV Communications for Sustainable Federated Learning
Mar 20, 2021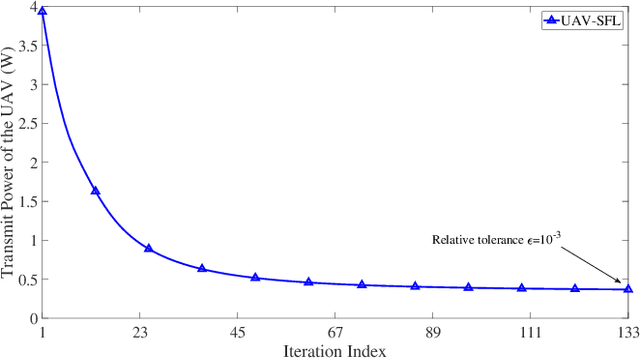
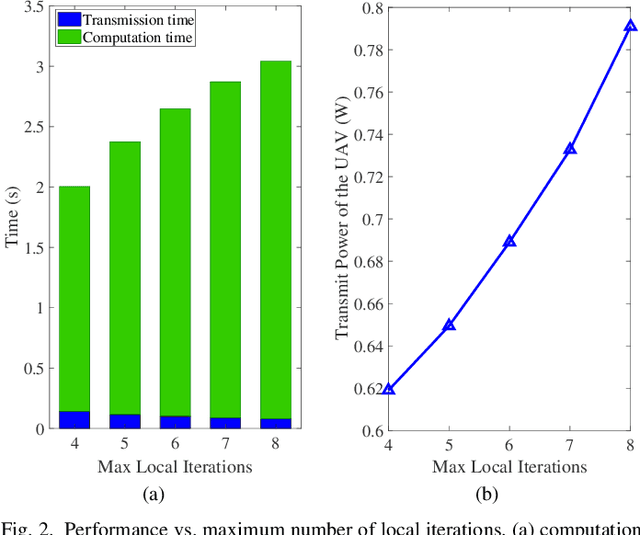
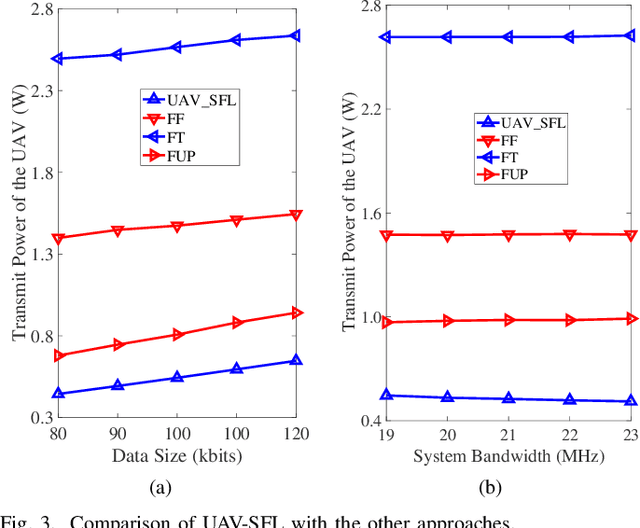
Federated learning (FL), invented by Google in 2016, has become a hot research trend. However, enabling FL in wireless networks has to overcome the limited battery challenge of mobile users. In this regard, we propose to apply unmanned aerial vehicle (UAV)-empowered wireless power transfer to enable sustainable FL-based wireless networks. The objective is to maximize the UAV transmit power efficiency, via a joint optimization of transmission time and bandwidth allocation, power control, and the UAV placement. Directly solving the formulated problem is challenging, due to the coupling of variables. Hence, we leverage the decomposition technique and a successive convex approximation approach to develop an efficient algorithm, namely UAV for sustainable FL (UAV-SFL). Finally, simulations illustrate the potential of our proposed UAV-SFL approach in providing a sustainable solution for FL-based wireless networks, and in reducing the UAV transmit power by 32.95%, 63.18%, and 78.81% compared with the benchmarks.
Stereo CenterNet based 3D Object Detection for Autonomous Driving
Mar 20, 2021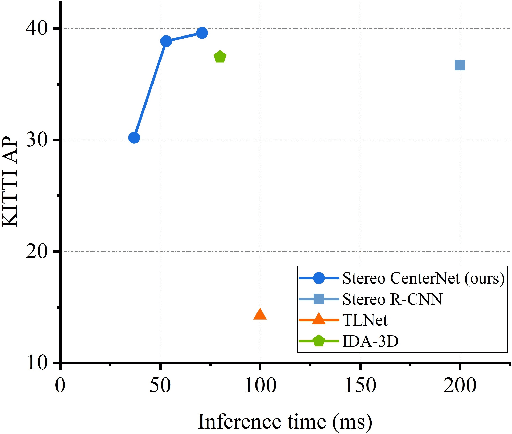
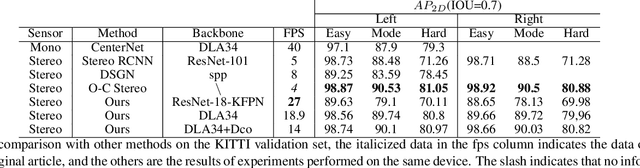
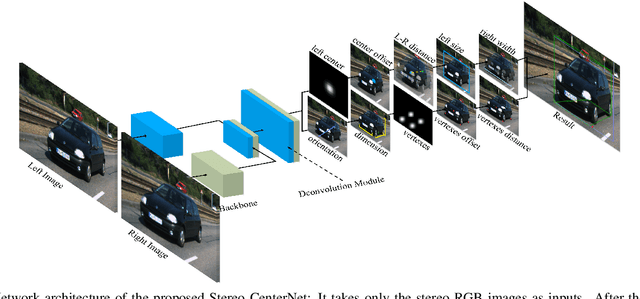
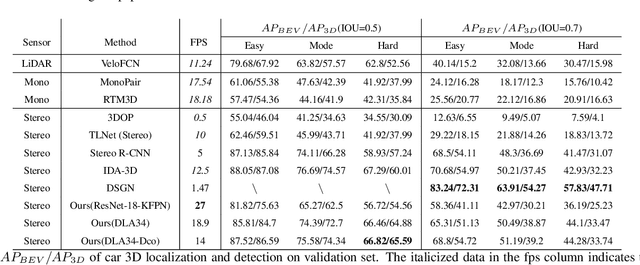
In recent years, 3D detection based on stereo cameras has made great progress, but most state-of-the-art methods use anchor-based 2D detection or depth estimation to solve this problem. However, the high computational cost makes these methods difficult to meet real-time performance. In this work, we propose a 3D object detection method using geometric information in stereo images, called Stereo CenterNet. Stereo CenterNet predicts the four semantic key points of the 3D bounding box of the object in space and uses 2D left right boxes, 3D dimension, orientation and key points to restore the bounding box of the object in the 3D space. Then, we use an improved photometric alignment module to further optimize the position of the 3D bounding box. Experiments conducted on the KITTI dataset show that our method achieves the best speed-accuracy trade-off compared with the state-of-the-art methods based on stereo geometry.