 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explaining Deep Learning Models for Structured Data using Layer-Wise Relevance Propagation
Nov 26, 2020

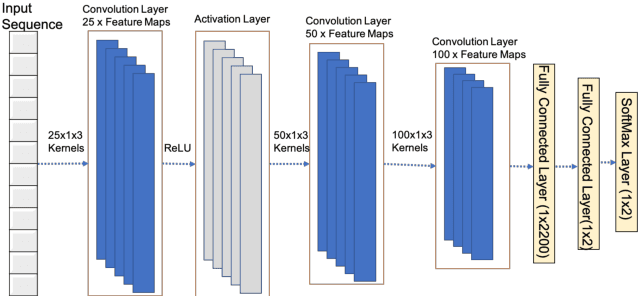
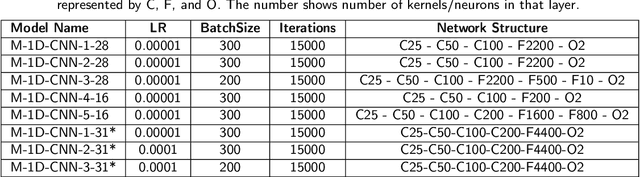
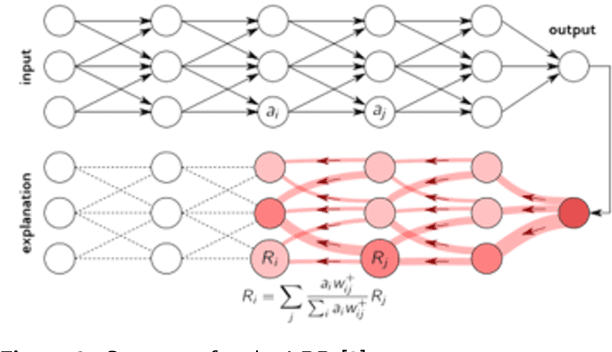
Trust and credibility in machine learning models is bolstered by the ability of a model to explain itsdecisions. While explainability of deep learning models is a well-known challenge, a further chal-lenge is clarity of the explanation itself, which must be interpreted by downstream users. Layer-wiseRelevance Propagation (LRP), an established explainability technique developed for deep models incomputer vision, provides intuitive human-readable heat maps of input images. We present the novelapplication of LRP for the first time with structured datasets using a deep neural network (1D-CNN),for Credit Card Fraud detection and Telecom Customer Churn prediction datasets. We show how LRPis more effective than traditional explainability concepts of Local Interpretable Model-agnostic Ex-planations (LIME) and Shapley Additive Explanations (SHAP) for explainability. This effectivenessis both local to a sample level and holistic over the whole testing set. We also discuss the significantcomputational time advantage of LRP (1-2s) over LIME (22s) and SHAP (108s), and thus its poten-tial for real time application scenarios. In addition, our validation of LRP has highlighted features forenhancing model performance, thus opening up a new area of research of using XAI as an approachfor feature subset selection
Link Prediction on N-ary Relational Data Based on Relatedness Evaluation
Apr 21, 2021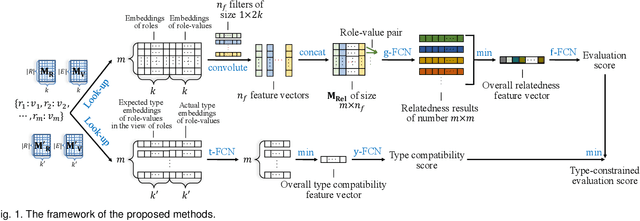


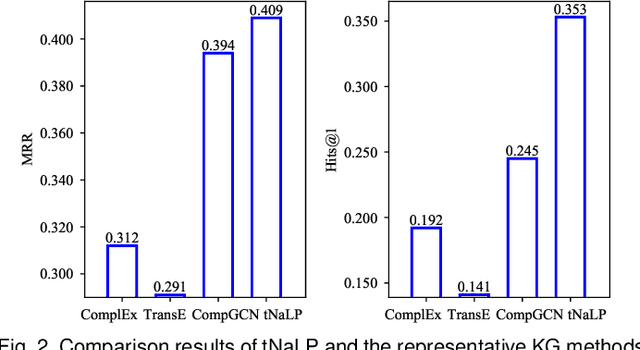
With the overwhelming popularity of Knowledge Graphs (KGs), researchers have poured attention to link prediction to fill in missing facts for a long time. However, they mainly focus on link prediction on binary relational data, where facts are usually represented as triples in the form of (head entity, relation, tail entity). In practice, n-ary relational facts are also ubiquitous. When encountering such facts, existing studies usually decompose them into triples by introducing a multitude of auxiliary virtual entities and additional triples. These conversions result in the complexity of carrying out link prediction on n-ary relational data. It has even proven that they may cause loss of structure information. To overcome these problems, in this paper, we represent each n-ary relational fact as a set of its role and role-value pairs. We then propose a method called NaLP to conduct link prediction on n-ary relational data, which explicitly models the relatedness of all the role and role-value pairs in an n-ary relational fact. We further extend NaLP by introducing type constraints of roles and role-values without any external type-specific supervision, and proposing a more reasonable negative sampling mechanism. Experimental results validate the effectiveness and merits of the proposed methods.
FD-JCAS Techniques for mmWave HetNets: Ginibre Point Process Modeling and Analysis
Apr 21, 2021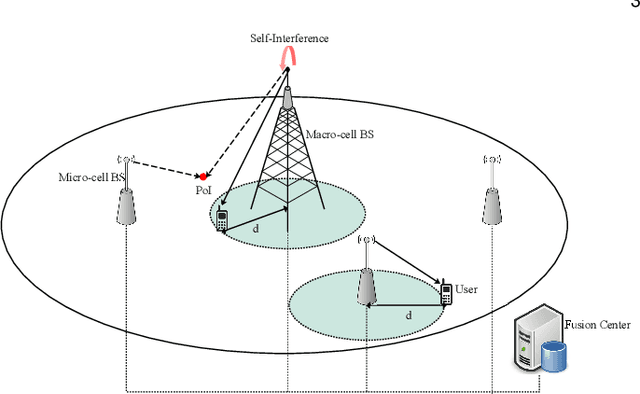
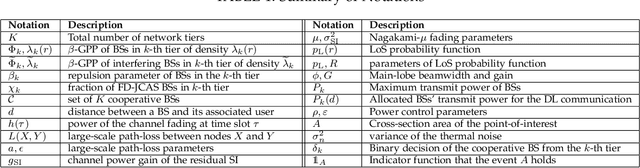
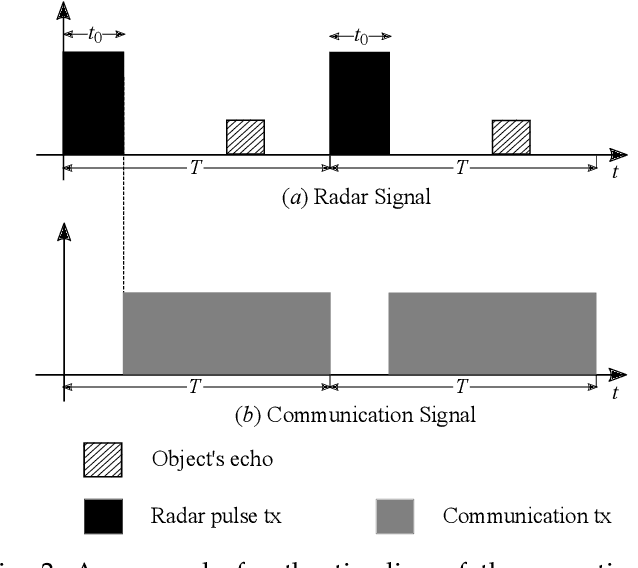
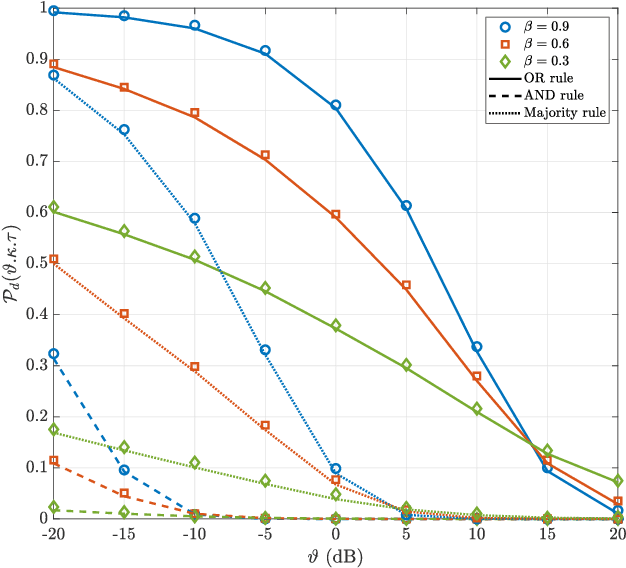
In this paper, we study the co-design of full-duplex (FD) radio with joint communication and radar sensing (JCAS) techniques in millimeter-wave (mmWave) heterogeneous networks (HetNets). Spectral co-existence of radar and communication systems causes mutual interference between the two systems, compromising both the data exchange and sensing capabilities. Focusing on the detection performance, we propose a cooperative detection technique, which exploits the sensing information from multiple base stations (BSs), aiming at enhancing the probability of successfully detecting an object. Three combining rules are considered, namely the \textit{OR}, the \textit{Majority} and the \textit{AND} rule. In real-world network scenarios, the locations of the BSs are spatially correlated, exhibiting a repulsive behavior. Therefore, we model the spatial distribution of the BSs as a $\beta$-Ginibre point process ($\beta$-GPP), which can characterize the repulsion among the BSs. By using stochastic geometry tools, analytical expressions for the detection performance of $\beta$-GPP-based FD-JCAS systems are expressed for each of the considered combining rule. Furthermore, by considering temporal interference correlation, we evaluate the probability of successfully detecting an object over two different time slots. Our results demonstrate that our proposed technique can significantly improve the detection performance when compared to the conventional non-cooperative technique.
Dynamic survival prediction in intensive care units from heterogeneous time series without the need for variable selection or pre-processing
Sep 17, 2019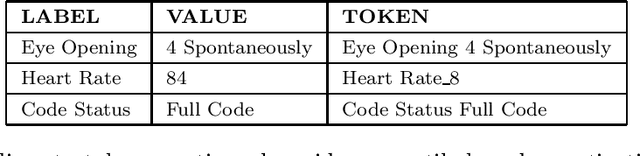
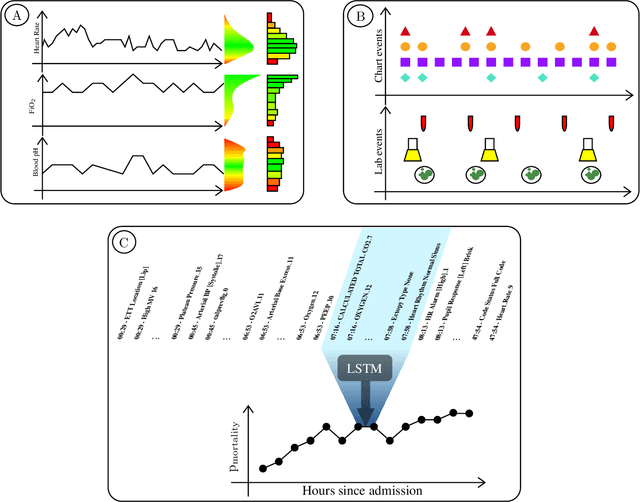
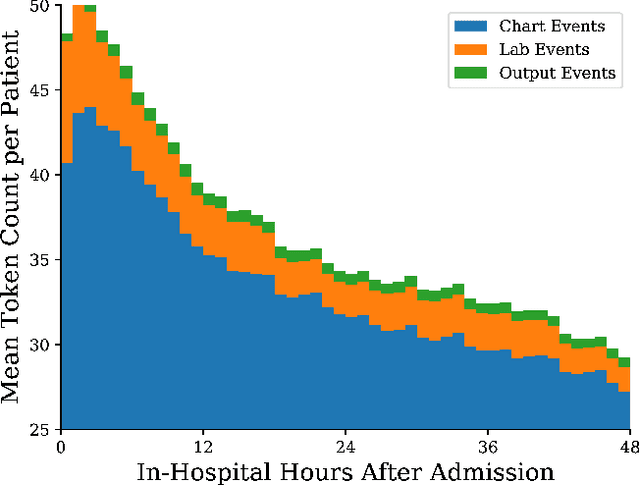
We present a machine learning pipeline and model that uses the entire uncurated EHR for prediction of in-hospital mortality at arbitrary time intervals, using all available chart, lab and output events, without the need for pre-processing or feature engineering. Data for more than 45,000 American ICU patients from the MIMIC-III database were used to develop an ICU mortality prediction model. All chart, lab and output events were treated by the model in the same manner inspired by Natural Language Processing (NLP). Patient events were discretized by percentile and mapped to learnt embeddings before being passed to a Recurrent Neural Network (RNN) to provide early prediction of in-patient mortality risk. We compared mortality predictions with the Simplified Acute Physiology Score II (SAPS II) and the Oxford Acute Severity of Illness Score (OASIS). Data were split into an independent test set (10%) and a ten-fold cross-validation was carried out during training to avoid overfitting. 13,233 distinct variables with heterogeneous data types were included without manual selection or pre-processing. Recordings in the first few hours of a patient's stay were found to be strongly predictive of mortality, outperforming models using SAPS II and OASIS scores within just 2 hours and achieving a state of the art Area Under the Receiver Operating Characteristic (AUROC) value of 0.80 (95% CI 0.79-0.80) at 12 hours vs 0.70 and 0.66 for SAPS II and OASIS at 24 hours respectively. Our model achieves a very strong performance of AUROC 0.86 (95% CI 0.85-0.86) for in-patient mortality prediction after 48 hours on the MIMIC-III dataset. Predictive performance increases over the first 48 hours of the ICU stay, but suffers from diminishing returns, providing rationale for time-limited trials of critical care and suggesting that the timing of decision making can be optimised and individualised.
Model-aided Deep Reinforcement Learning for Sample-efficient UAV Trajectory Design in IoT Networks
Apr 21, 2021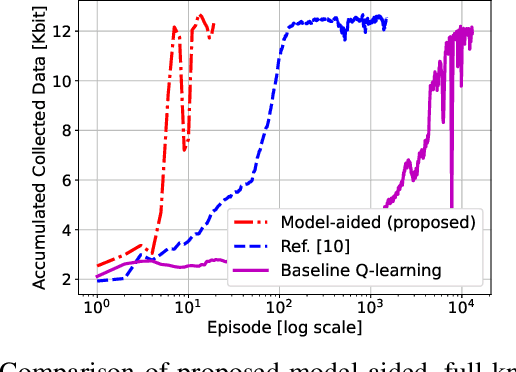
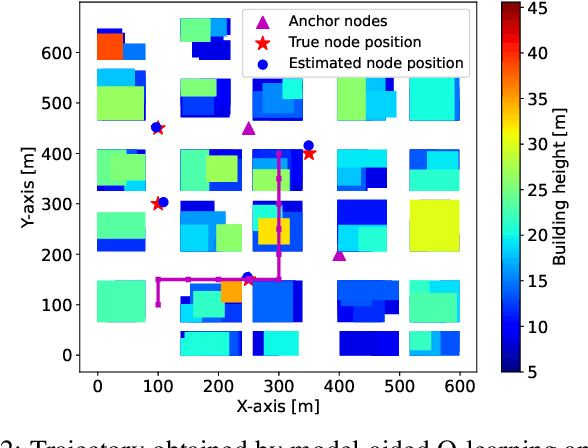
Deep Reinforcement Learning (DRL) has become a prominent paradigm to design trajectories for autonomous unmanned aerial vehicles (UAV) used as flying access points in the context of cellular or Internet of Things (IoT) connectivity. However, the prohibitively high training data demand severely restricts the applicability of RL-based trajectory planning in real-world missions. We propose a model-aided deep Q-learning approach that, in contrast to previous work, requires a minimum of expensive training data samples and is able to guide a flight-time restricted UAV on a data harvesting mission without prior knowledge of wireless channel characteristics and limited knowledge of wireless node locations. By exploiting some known reference wireless node positions and channel gain measurements, we seek to learn a model of the environment by estimating unknown node positions and learning the wireless channel characteristics. Interaction with the model allows us to train a deep Q-network (DQN) to approximate the optimal UAV control policy. We show that in comparison with standard DRL approaches, the proposed model-aided approach requires at least one order of magnitude less training data samples to reach identical data collection performance, hence offering a first step towards making DRL a viable solution to the problem.
Can a Transformer Pass the Wug Test? Tuning Copying Bias in Neural Morphological Inflection Models
Apr 13, 2021
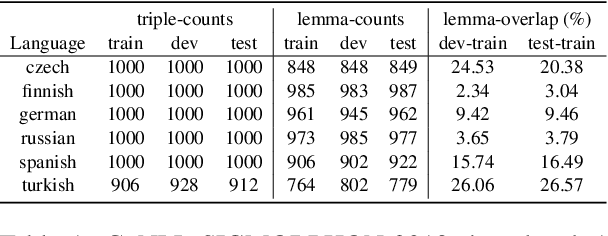
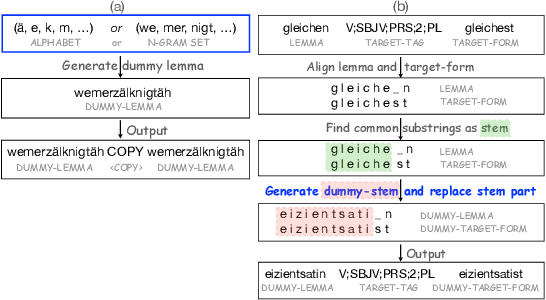
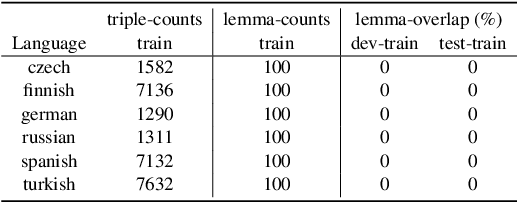
Deep learning sequence models have been successfully applied to the task of morphological inflection. The results of the SIGMORPHON shared tasks in the past several years indicate that such models can perform well, but only if the training data cover a good amount of different lemmata, or if the lemmata that are inflected at test time have also been seen in training, as has indeed been largely the case in these tasks. Surprisingly, standard models such as the Transformer almost completely fail at generalizing inflection patterns when asked to inflect previously unseen lemmata -- i.e. under "wug test"-like circumstances. While established data augmentation techniques can be employed to alleviate this shortcoming by introducing a copying bias through hallucinating synthetic new word forms using the alphabet in the language at hand, we show that, to be more effective, the hallucination process needs to pay attention to substrings of syllable-like length rather than individual characters or stems. We report a significant performance improvement with our substring-based hallucination model over previous data hallucination methods when training and test data do not overlap in their lemmata.
Two-Stage Facility Location Games with Strategic Clients and Facilities
May 04, 2021
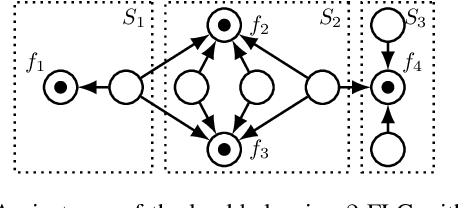
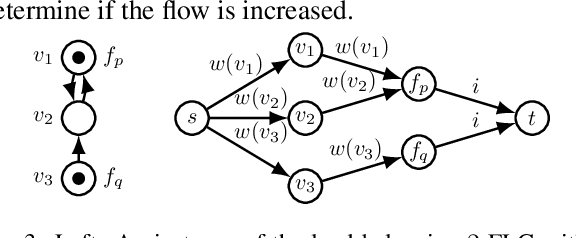
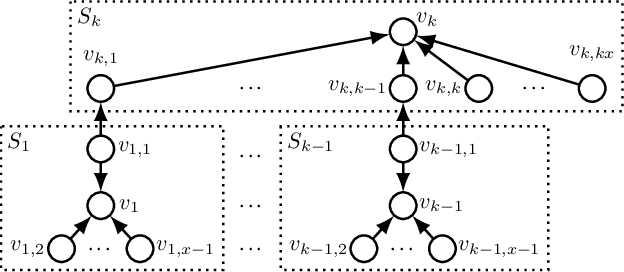
We consider non-cooperative facility location games where both facilities and clients act strategically and heavily influence each other. This contrasts established game-theoretic facility location models with non-strategic clients that simply select the closest opened facility. In our model, every facility location has a set of attracted clients and each client has a set of shopping locations and a weight that corresponds to her spending capacity. Facility agents selfishly select a location for opening their facility to maximize the attracted total spending capacity, whereas clients strategically decide how to distribute their spending capacity among the opened facilities in their shopping range. We focus on a natural client behavior similar to classical load balancing: our selfish clients aim for a distribution that minimizes their maximum waiting times for getting serviced, where a facility's waiting time corresponds to its total attracted client weight. We show that subgame perfect equilibria exist and give almost tight constant bounds on the Price of Anarchy and the Price of Stability, which even hold for a broader class of games with arbitrary client behavior. Since facilities and clients influence each other, it is crucial for the facilities to anticipate the selfish clients' behavior when selecting their location. For this, we provide an efficient algorithm that also implies an efficient check for equilibrium. Finally, we show that computing a socially optimal facility placement is NP-hard and that this result holds for all feasible client weight distributions.
DeepTravel: a Neural Network Based Travel Time Estimation Model with Auxiliary Supervision
Feb 06, 2018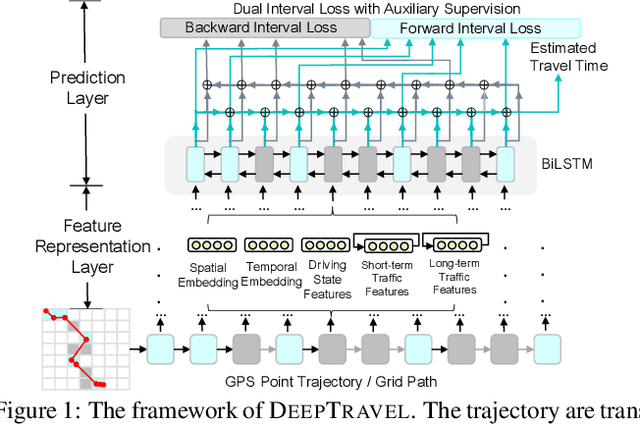
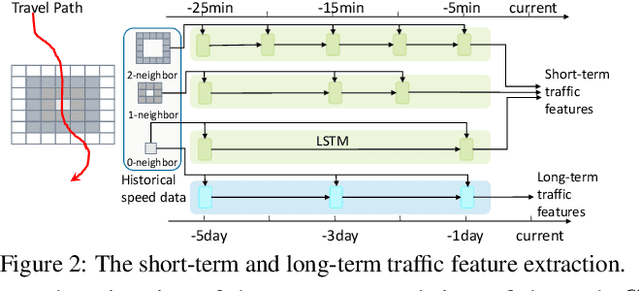
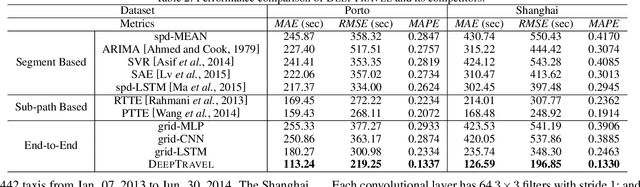
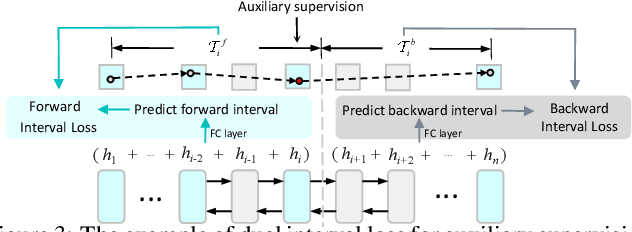
Estimating the travel time of a path is of great importance to smart urban mobility. Existing approaches are either based on estimating the time cost of each road segment which are not able to capture many cross-segment complex factors, or designed heuristically in a non-learning-based way which fail to utilize the existing abundant temporal labels of the data, i.e., the time stamp of each trajectory point. In this paper, we leverage on new development of deep neural networks and propose a novel auxiliary supervision model, namely DeepTravel, that can automatically and effectively extract different features, as well as make full use of the temporal labels of the trajectory data. We have conducted comprehensive experiments on real datasets to demonstrate the out-performance of DeepTravel over existing approaches.
Neural Path Planning: Fixed Time, Near-Optimal Path Generation via Oracle Imitation
Apr 25, 2019
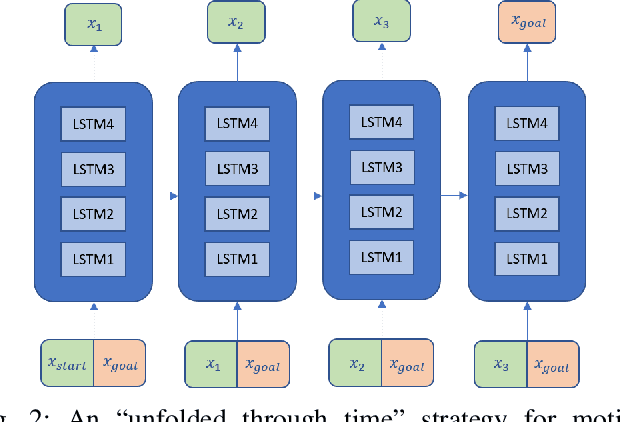
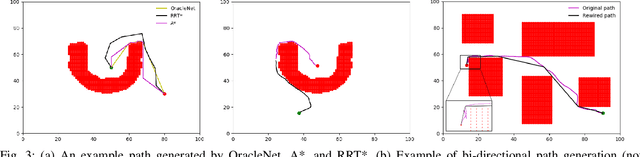
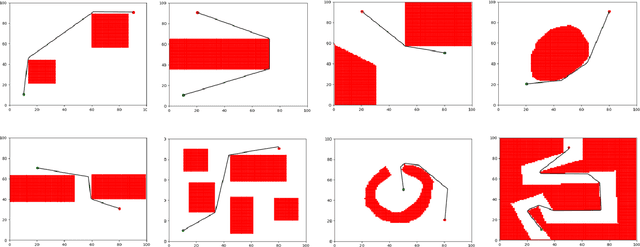
Fast and efficient path generation is critical for robots operating in complex environments. This motion planning problem is often performed in a robot's actuation or configuration space, where popular pathfinding methods such as A*, RRT*, get exponentially more computationally expensive to execute as the dimensionality increases or the spaces become more cluttered and complex. On the other hand, if one were to save the entire set of paths connecting all pair of locations in the configuration space a priori, one would run out of memory very quickly. In this work, we introduce a novel way of producing fast and optimal motion plans for static environments by using a stepping neural network approach, called OracleNet. OracleNet uses Recurrent Neural Networks to determine end-to-end trajectories in an iterative manner that implicitly generates optimal motion plans with minimal loss in performance in a compact form. The algorithm is straightforward in implementation while consistently generating near-optimal paths in a single, iterative, end-to-end roll-out. In practice, OracleNet generally has fixed-time execution regardless of the configuration space complexity while outperforming popular pathfinding algorithms in complex environments and higher dimensions
Real-time Driver Drowsiness Detection for Android Application Using Deep Neural Networks Techniques
Nov 05, 2018
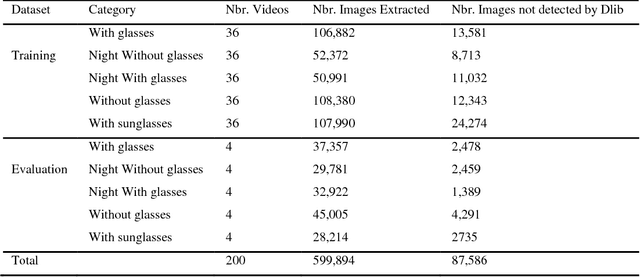


Road crashes and related forms of accidents are a common cause of injury and death among the human population. According to 2015 data from the World Health Organization, road traffic injuries resulted in approximately 1.25 million deaths worldwide, i.e. approximately every 25 seconds an individual will experience a fatal crash. While the cost of traffic accidents in Europe is estimated at around 160 billion Euros, driver drowsiness accounts for approximately 100,000 accidents per year in the United States alone as reported by The American National Highway Traffic Safety Administration (NHTSA). In this paper, a novel approach towards real-time drowsiness detection is proposed. This approach is based on a deep learning method that can be implemented on Android applications with high accuracy. The main contribution of this work is the compression of heavy baseline model to a lightweight model. Moreover, minimal network structure is designed based on facial landmark key point detection to recognize whether the driver is drowsy. The proposed model is able to achieve an accuracy of more than 80%. Keywords: Driver Monitoring System; Drowsiness Detection; Deep Learning; Real-time Deep Neural Network; Android.