 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Co-BERT: A Context-Aware BERT Retrieval Model Incorporating Local and Query-specific Context
Apr 17, 2021
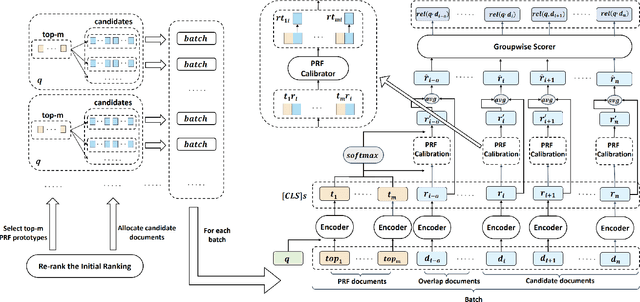
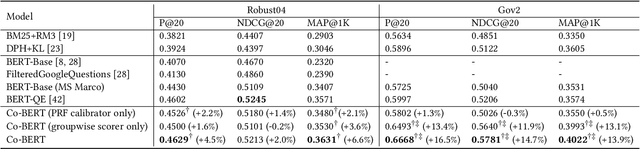
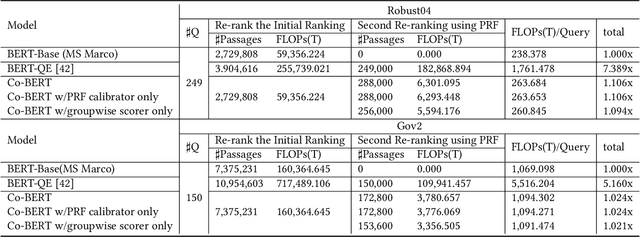

BERT-based text ranking models have dramatically advanced the state-of-the-art in ad-hoc retrieval, wherein most models tend to consider individual query-document pairs independently. In the mean time, the importance and usefulness to consider the cross-documents interactions and the query-specific characteristics in a ranking model have been repeatedly confirmed, mostly in the context of learning to rank. The BERT-based ranking model, however, has not been able to fully incorporate these two types of ranking context, thereby ignoring the inter-document relationships from the ranking and the differences among queries. To mitigate this gap, in this work, an end-to-end transformer-based ranking model, named Co-BERT, has been proposed to exploit several BERT architectures to calibrate the query-document representations using pseudo relevance feedback before modeling the relevance of a group of documents jointly. Extensive experiments on two standard test collections confirm the effectiveness of the proposed model in improving the performance of text re-ranking over strong fine-tuned BERT-Base baselines. We plan to make our implementation open source to enable further comparisons.
ROS-Neuro Integration of Deep Convolutional Autoencoders for EEG Signal Compression in Real-time BCIs
Aug 31, 2020

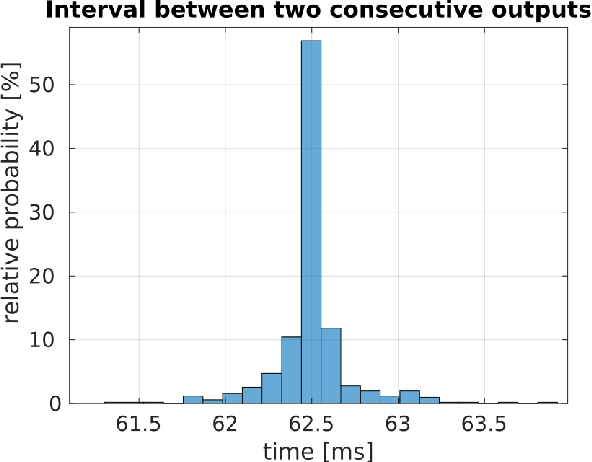
Typical EEG-based BCI applications require the computation of complex functions over the noisy EEG channels to be carried out in an efficient way. Deep learning algorithms are capable of learning flexible nonlinear functions directly from data, and their constant processing latency is perfect for their deployment into online BCI systems. However, it is crucial for the jitter of the processing system to be as low as possible, in order to avoid unpredictable behaviour that can ruin the system's overall usability. In this paper, we present a novel encoding method, based on on deep convolutional autoencoders, that is able to perform efficient compression of the raw EEG inputs. We deploy our model in a ROS-Neuro node, thus making it suitable for the integration in ROS-based BCI and robotic systems in real world scenarios. The experimental results show that our system is capable to generate meaningful compressed encoding preserving to original information contained in the raw input. They also show that the ROS-Neuro node is able to produce such encodings at a steady rate, with minimal jitter. We believe that our system can represent an important step towards the development of an effective BCI processing pipeline fully standardized in ROS-Neuro framework.
shapeDTW: shape Dynamic Time Warping
Jun 06, 2016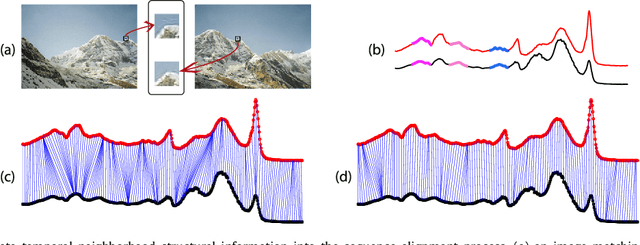
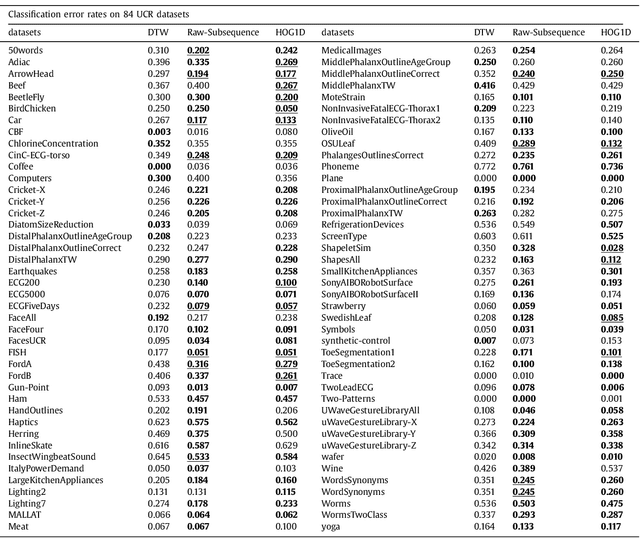
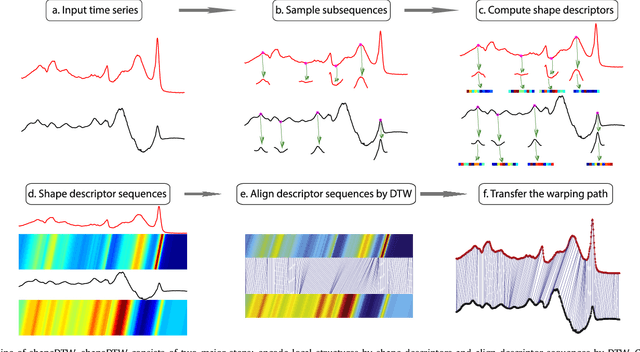
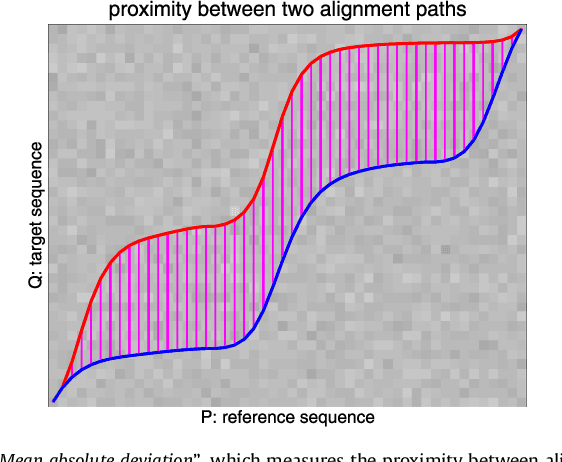
Dynamic Time Warping (DTW) is an algorithm to align temporal sequences with possible local non-linear distortions, and has been widely applied to audio, video and graphics data alignments. DTW is essentially a point-to-point matching method under some boundary and temporal consistency constraints. Although DTW obtains a global optimal solution, it does not necessarily achieve locally sensible matchings. Concretely, two temporal points with entirely dissimilar local structures may be matched by DTW. To address this problem, we propose an improved alignment algorithm, named shape Dynamic Time Warping (shapeDTW), which enhances DTW by taking point-wise local structural information into consideration. shapeDTW is inherently a DTW algorithm, but additionally attempts to pair locally similar structures and to avoid matching points with distinct neighborhood structures. We apply shapeDTW to align audio signal pairs having ground-truth alignments, as well as artificially simulated pairs of aligned sequences, and obtain quantitatively much lower alignment errors than DTW and its two variants. When shapeDTW is used as a distance measure in a nearest neighbor classifier (NN-shapeDTW) to classify time series, it beats DTW on 64 out of 84 UCR time series datasets, with significantly improved classification accuracies. By using a properly designed local structure descriptor, shapeDTW improves accuracies by more than 10% on 18 datasets. To the best of our knowledge, shapeDTW is the first distance measure under the nearest neighbor classifier scheme to significantly outperform DTW, which had been widely recognized as the best distance measure to date. Our code is publicly accessible at: https://github.com/jiapingz/shapeDTW.
Neural Decomposition of Time-Series Data for Effective Generalization
Jun 05, 2017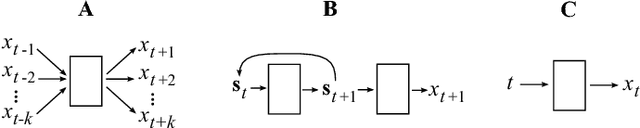
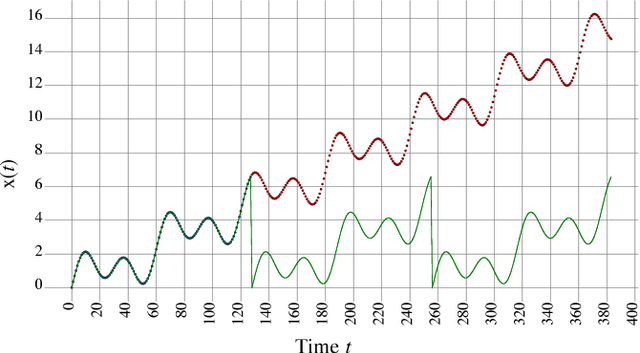
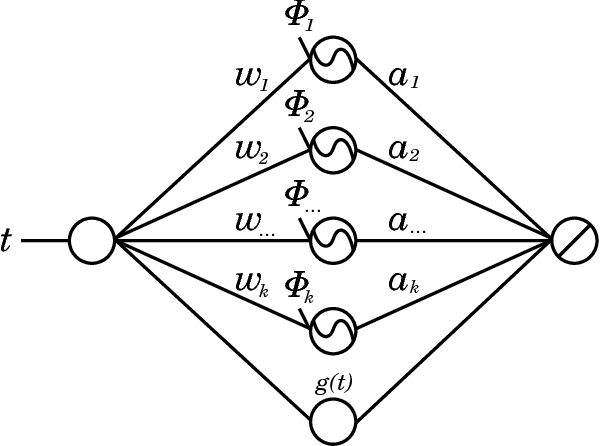
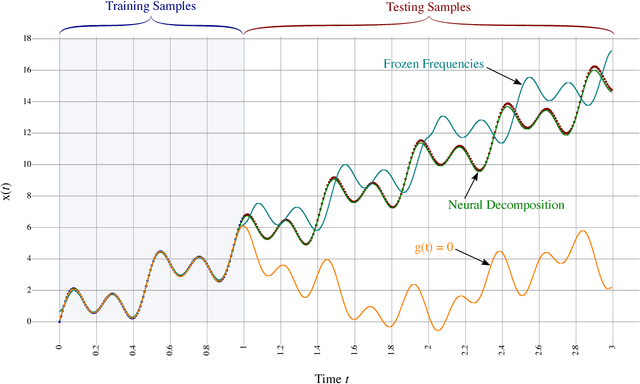
We present a neural network technique for the analysis and extrapolation of time-series data called Neural Decomposition (ND). Units with a sinusoidal activation function are used to perform a Fourier-like decomposition of training samples into a sum of sinusoids, augmented by units with nonperiodic activation functions to capture linear trends and other nonperiodic components. We show how careful weight initialization can be combined with regularization to form a simple model that generalizes well. Our method generalizes effectively on the Mackey-Glass series, a dataset of unemployment rates as reported by the U.S. Department of Labor Statistics, a time-series of monthly international airline passengers, the monthly ozone concentration in downtown Los Angeles, and an unevenly sampled time-series of oxygen isotope measurements from a cave in north India. We find that ND outperforms popular time-series forecasting techniques including LSTM, echo state networks, ARIMA, SARIMA, SVR with a radial basis function, and Gashler and Ashmore's model.
* 13 pages, 11 figures, IEEE TNNLS Preprint
Dynamic imaging using deep generative SToRM (Gen-SToRM) model
Jan 29, 2021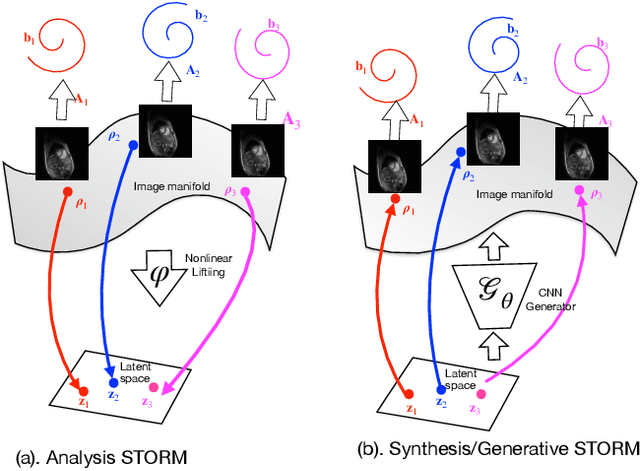
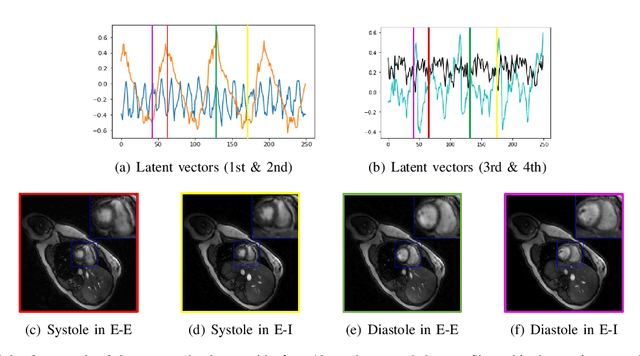
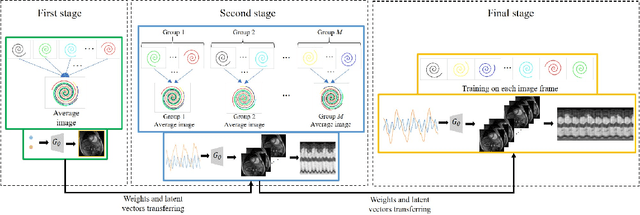
We introduce a generative smoothness regularization on manifolds (SToRM) model for the recovery of dynamic image data from highly undersampled measurements. The model assumes that the images in the dataset are non-linear mappings of low-dimensional latent vectors. We use the deep convolutional neural network (CNN) to represent the non-linear transformation. The parameters of the generator as well as the low-dimensional latent vectors are jointly estimated only from the undersampled measurements. This approach is different from the traditional CNN approaches that require extensive fully sampled training data. We penalize the norm of the gradients of the non-linear mapping to constrain the manifold to be smooth, while temporal gradients of the latent vectors are penalized to obtain a smoothly varying time-series. The proposed scheme brings in the spatial regularization provided by the convolutional network. The main benefit of the proposed scheme is the improvement in image quality and the orders of magnitude reduction in memory demand compared to traditional manifold models. To minimize the computational complexity of the algorithm, we introduce an efficient progressive training in time approach and an approximate cost function. These approaches speed up the image reconstructions and offers better reconstruction performance.
Open Intent Discovery through Unsupervised Semantic Clustering and Dependency Parsing
Apr 25, 2021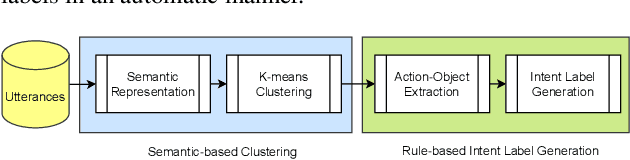

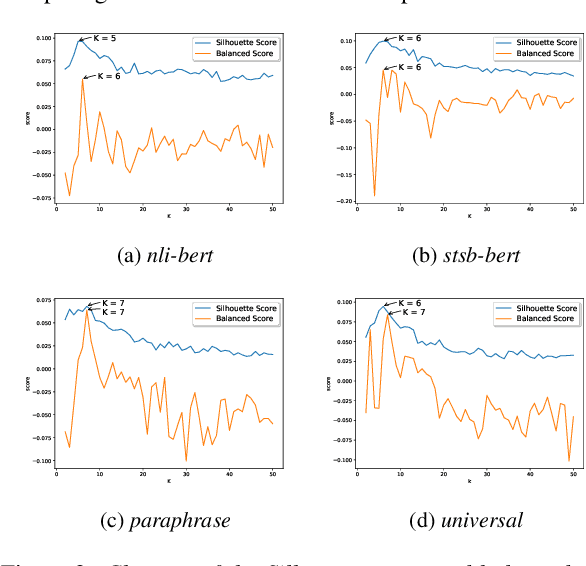

Intent understanding plays an important role in dialog systems, and is typically formulated as a supervised classification problem. However, it is challenging and time-consuming to design the intent labels manually to support a new domain. This paper proposes an unsupervised two-stage approach to discover intents and generate meaningful intent labels automatically from a collection of unlabeled utterances. In the first stage, we aim to generate a set of semantically coherent clusters where the utterances within each cluster convey the same intent. We obtain the utterance representation from various pre-trained sentence embeddings and present a metric of balanced score to determine the optimal number of clusters in K-means clustering. In the second stage, the objective is to generate an intent label automatically for each cluster. We extract the ACTION-OBJECT pair from each utterance using a dependency parser and take the most frequent pair within each cluster, e.g., book-restaurant, as the generated cluster label. We empirically show that the proposed unsupervised approach can generate meaningful intent labels automatically and achieves high precision and recall in utterance clustering and intent discovery.
Temp-Frustum Net: 3D Object Detection with Temporal Fusion
Apr 25, 2021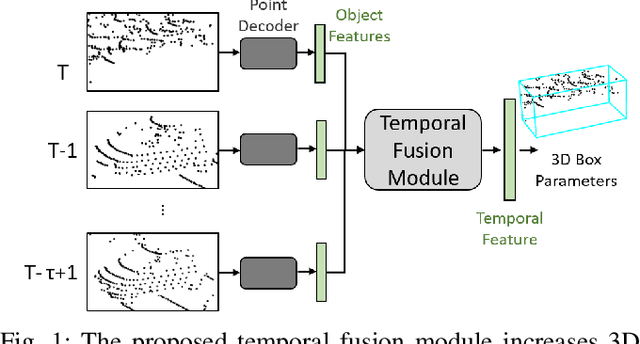
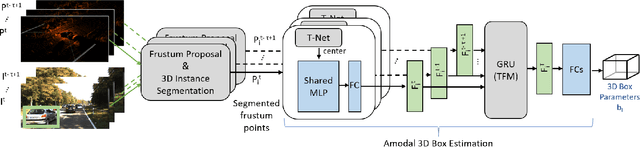


3D object detection is a core component of automated driving systems. State-of-the-art methods fuse RGB imagery and LiDAR point cloud data frame-by-frame for 3D bounding box regression. However, frame-by-frame 3D object detection suffers from noise, field-of-view obstruction, and sparsity. We propose a novel Temporal Fusion Module (TFM) to use information from previous time-steps to mitigate these problems. First, a state-of-the-art frustum network extracts point cloud features from raw RGB and LiDAR point cloud data frame-by-frame. Then, our TFM module fuses these features with a recurrent neural network. As a result, 3D object detection becomes robust against single frame failures and transient occlusions. Experiments on the KITTI object tracking dataset show the efficiency of the proposed TFM, where we obtain ~6%, ~4%, and ~6% improvements on Car, Pedestrian, and Cyclist classes, respectively, compared to frame-by-frame baselines. Furthermore, ablation studies reinforce that the subject of improvement is temporal fusion and show the effects of different placements of TFM in the object detection pipeline. Our code is open-source and available at https://gitlab.lrz.de/emec_ercelik/temp-frustnet.
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Apr 08, 2021
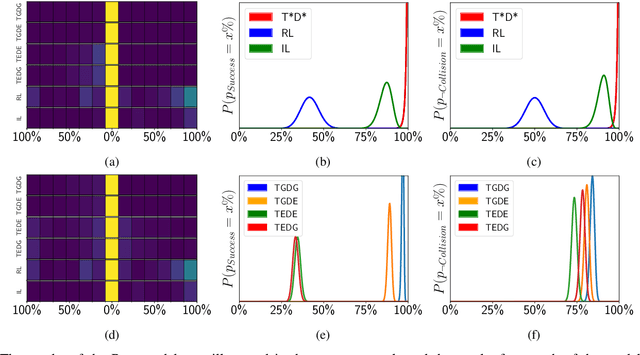
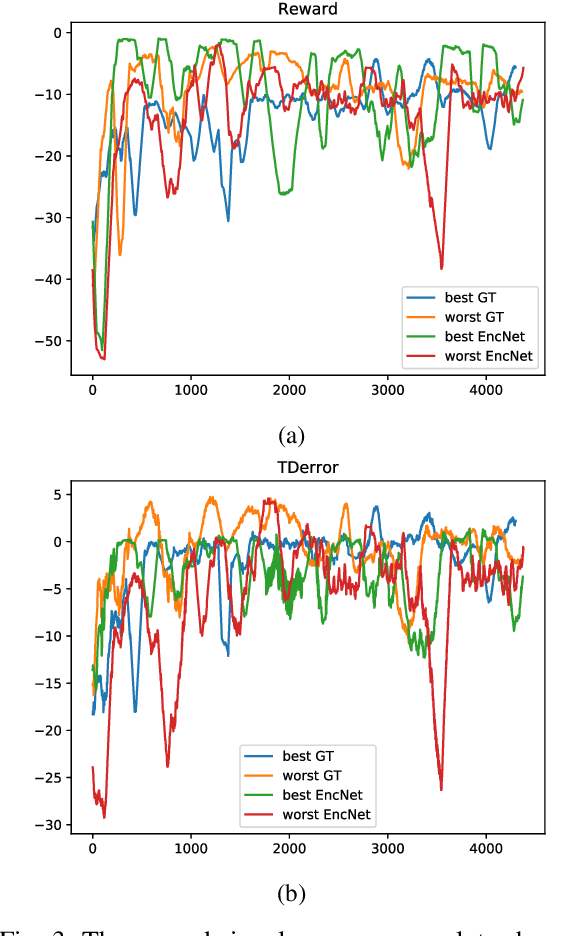

In this paper, we present a state-of-the-art reinforcement learning method for autonomous driving. Our approach employs temporal difference learning in a Bayesian framework to learn vehicle control signals from sensor data. The agent has access to images from a forward facing camera, which are preprocessed to generate semantic segmentation maps. We trained our system using both ground truth and estimated semantic segmentation input. Based on our observations from a large set of experiments, we conclude that training the system on ground truth input data leads to better performance than training the system on estimated input even if estimated input is used for evaluation. The system is trained and evaluated in a realistic simulated urban environment using the CARLA simulator. The simulator also contains a benchmark that allows for comparing to other systems and methods. The required training time of the system is shown to be lower and the performance on the benchmark superior to competing approaches.
Real-time Convolutional Neural Networks for Emotion and Gender Classification
Oct 20, 2017

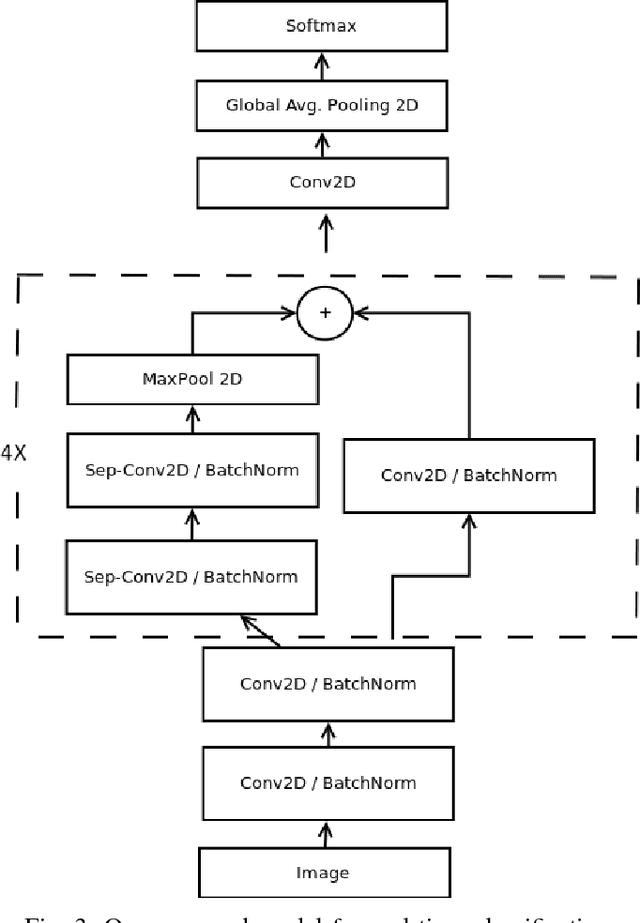
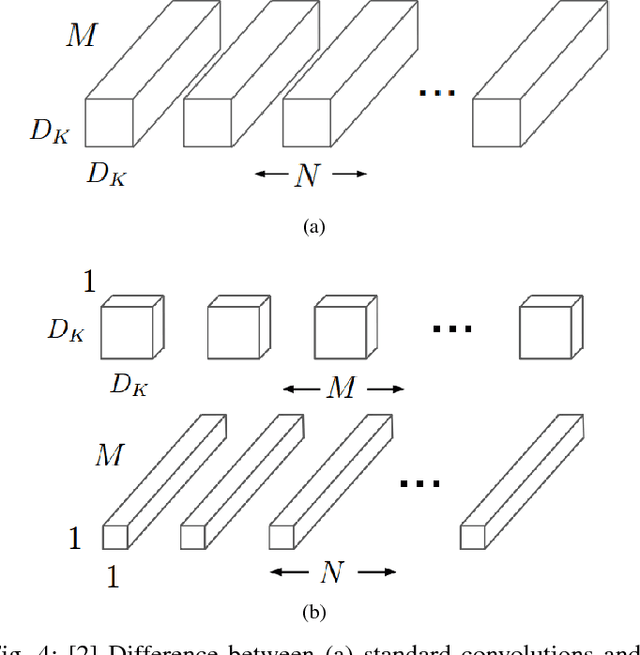
In this paper we propose an implement a general convolutional neural network (CNN) building framework for designing real-time CNNs. We validate our models by creating a real-time vision system which accomplishes the tasks of face detection, gender classification and emotion classification simultaneously in one blended step using our proposed CNN architecture. After presenting the details of the training procedure setup we proceed to evaluate on standard benchmark sets. We report accuracies of 96% in the IMDB gender dataset and 66% in the FER-2013 emotion dataset. Along with this we also introduced the very recent real-time enabled guided back-propagation visualization technique. Guided back-propagation uncovers the dynamics of the weight changes and evaluates the learned features. We argue that the careful implementation of modern CNN architectures, the use of the current regularization methods and the visualization of previously hidden features are necessary in order to reduce the gap between slow performances and real-time architectures. Our system has been validated by its deployment on a Care-O-bot 3 robot used during RoboCup@Home competitions. All our code, demos and pre-trained architectures have been released under an open-source license in our public repository.
SE-Harris and eSUSAN: Asynchronous Event-Based Corner Detection Using Megapixel Resolution CeleX-V Camera
May 02, 2021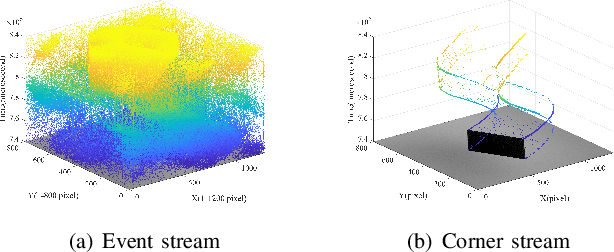
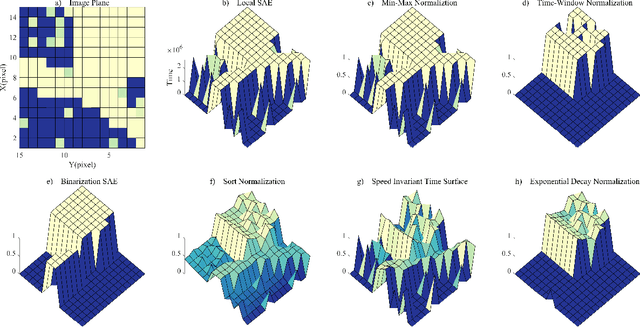
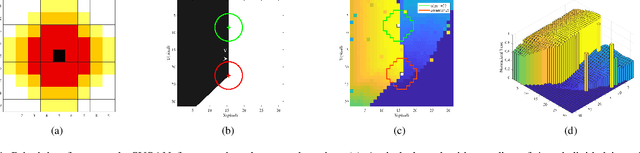
Event cameras are novel neuromorphic vision sensors with ultrahigh temporal resolution and low latency, both in the order of microseconds. Instead of image frames, event cameras generate an asynchronous event stream of per-pixel intensity changes with precise timestamps. The resulting sparse data structure impedes applying many conventional computer vision techniques to event streams, and specific algorithms should be designed to leverage the information provided by event cameras. We propose a corner detection algorithm, eSUSAN, inspired by the conventional SUSAN (smallest univalue segment assimilating nucleus) algorithm for corner detection. The proposed eSUSAN extracts the univalue segment assimilating nucleus from the circle kernel based on the similarity across timestamps and distinguishes corner events by the number of pixels in the nucleus area. Moreover, eSUSAN is fast enough to be applied to CeleX-V, the event camera with the highest resolution available. Based on eSUSAN, we also propose the SE-Harris corner detector, which uses adaptive normalization based on exponential decay to quickly construct a local surface of active events and the event-based Harris detector to refine the corners identified by eSUSAN. We evaluated the proposed algorithms on a public dataset and CeleX-V data. Both eSUSAN and SE-Harris exhibit higher real-time performance than existing algorithms while maintaining high accuracy and tracking performance.