 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$C^3$-Bench: The Things Real Disturbing LLM based Agent in Multi-Tasking
May 24, 2025Agents based on large language models leverage tools to modify environments, revolutionizing how AI interacts with the physical world. Unlike traditional NLP tasks that rely solely on historical dialogue for responses, these agents must consider more complex factors, such as inter-tool relationships, environmental feedback and previous decisions, when making choices. Current research typically evaluates agents via multi-turn dialogues. However, it overlooks the influence of these critical factors on agent behavior. To bridge this gap, we present an open-source and high-quality benchmark $C^3$-Bench. This benchmark integrates attack concepts and applies univariate analysis to pinpoint key elements affecting agent robustness. In concrete, we design three challenges: navigate complex tool relationships, handle critical hidden information and manage dynamic decision paths. Complementing these challenges, we introduce fine-grained metrics, innovative data collection algorithms and reproducible evaluation methods. Extensive experiments are conducted on 49 mainstream agents, encompassing general fast-thinking, slow-thinking and domain-specific models. We observe that agents have significant shortcomings in handling tool dependencies, long context information dependencies and frequent policy-type switching. In essence, $C^3$-Bench aims to expose model vulnerabilities through these challenges and drive research into the interpretability of agent performance. The benchmark is publicly available at https://github.com/yupeijei1997/C3-Bench.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Multi-Mission Tool Bench: Assessing the Robustness of LLM based Agents through Related and Dynamic Missions
Apr 03, 2025Large language models (LLMs) demonstrate strong potential as agents for tool invocation due to their advanced comprehension and planning capabilities. Users increasingly rely on LLM-based agents to solve complex missions through iterative interactions. However, existing benchmarks predominantly access agents in single-mission scenarios, failing to capture real-world complexity. To bridge this gap, we propose the Multi-Mission Tool Bench. In the benchmark, each test case comprises multiple interrelated missions. This design requires agents to dynamically adapt to evolving demands. Moreover, the proposed benchmark explores all possible mission-switching patterns within a fixed mission number. Specifically, we propose a multi-agent data generation framework to construct the benchmark. We also propose a novel method to evaluate the accuracy and efficiency of agent decisions with dynamic decision trees. Experiments on diverse open-source and closed-source LLMs reveal critical factors influencing agent robustness and provide actionable insights to the tool invocation society.
SE-Harris and eSUSAN: Asynchronous Event-Based Corner Detection Using Megapixel Resolution CeleX-V Camera
May 02, 2021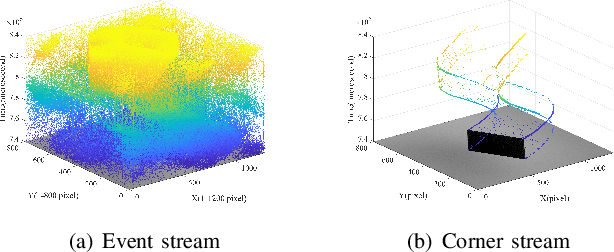
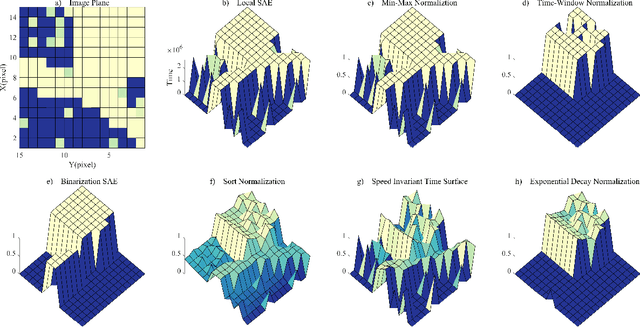
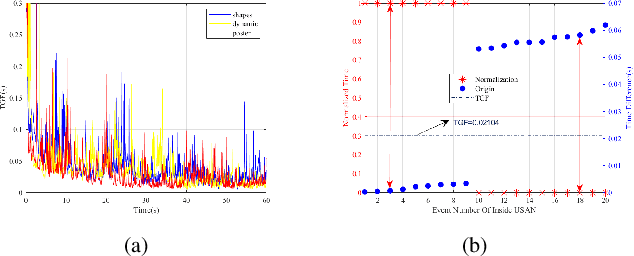
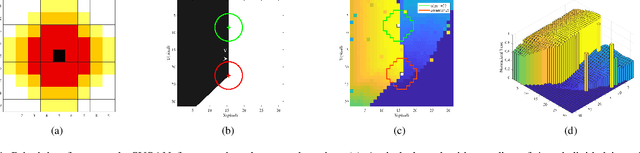
Event cameras are novel neuromorphic vision sensors with ultrahigh temporal resolution and low latency, both in the order of microseconds. Instead of image frames, event cameras generate an asynchronous event stream of per-pixel intensity changes with precise timestamps. The resulting sparse data structure impedes applying many conventional computer vision techniques to event streams, and specific algorithms should be designed to leverage the information provided by event cameras. We propose a corner detection algorithm, eSUSAN, inspired by the conventional SUSAN (smallest univalue segment assimilating nucleus) algorithm for corner detection. The proposed eSUSAN extracts the univalue segment assimilating nucleus from the circle kernel based on the similarity across timestamps and distinguishes corner events by the number of pixels in the nucleus area. Moreover, eSUSAN is fast enough to be applied to CeleX-V, the event camera with the highest resolution available. Based on eSUSAN, we also propose the SE-Harris corner detector, which uses adaptive normalization based on exponential decay to quickly construct a local surface of active events and the event-based Harris detector to refine the corners identified by eSUSAN. We evaluated the proposed algorithms on a public dataset and CeleX-V data. Both eSUSAN and SE-Harris exhibit higher real-time performance than existing algorithms while maintaining high accuracy and tracking performance.