 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Early Abandoning PrunedDTW and its application to similarity search
Oct 11, 2020
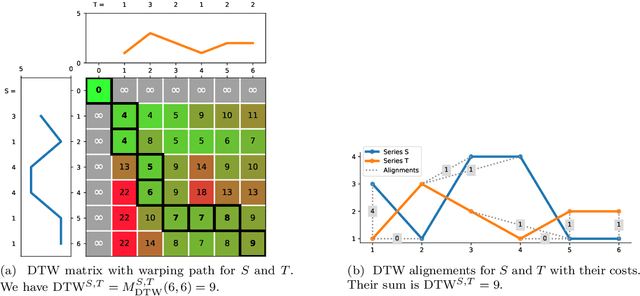

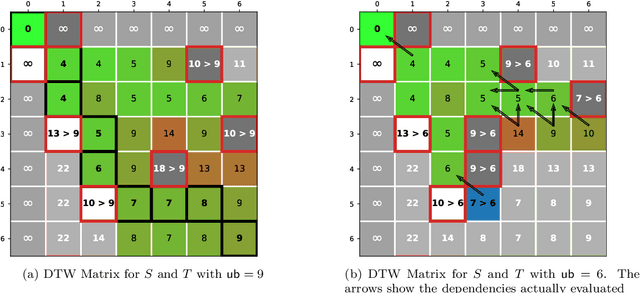
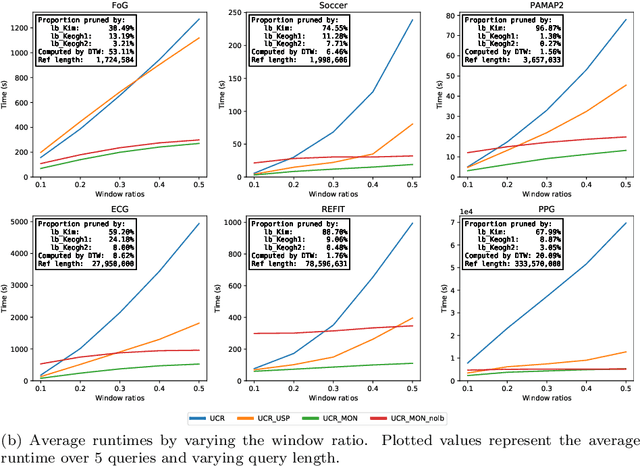
The Dynamic Time Warping ("DTW") distance is widely used in time series analysis, be it for classification, clustering or similarity search. However, its quadratic time complexity prevents it from scaling. Strategies, based on early abandoning DTW or skipping its computation altogether thanks to lower bounds, have been developed for certain use cases such as nearest neighbour search. But vectorization and approximation aside, no advance was made on DTW itself until recently with the introduction of PrunedDTW. This algorithm, able to prune unpromising alignments, was later fitted with early abandoning. We present a new version of PrunedDTW, "EAPrunedDTW", designed with early abandon in mind from the start, and able to early abandon faster than before. We show that EAPrunedDTW significantly improves the computation time of similarity search in the UCR Suite, and renders lower bounds dispensable.
Human activity recognition based on time series analysis using U-Net
Sep 20, 2018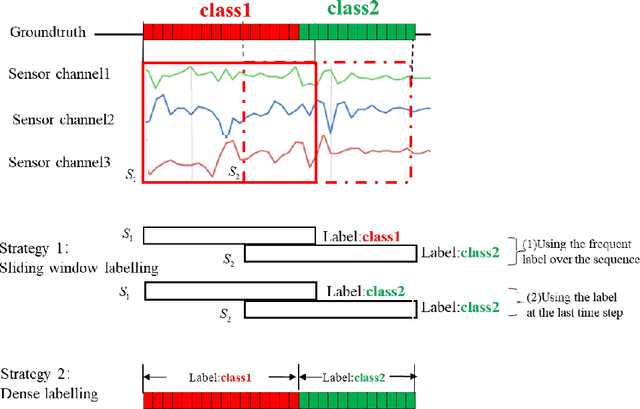
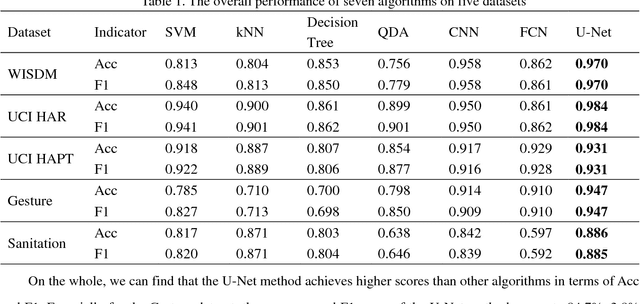
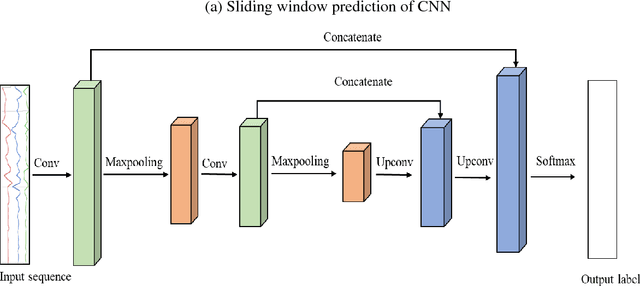
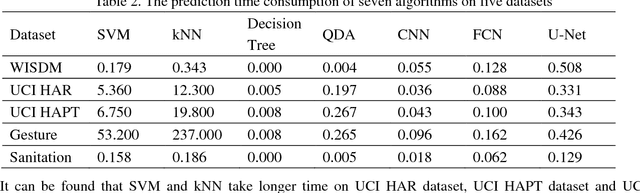
Traditional human activity recognition (HAR) based on time series adopts sliding window analysis method. This method faces the multi-class window problem which mistakenly labels different classes of sampling points within a window as a class. In this paper, a HAR algorithm based on U-Net is proposed to perform activity labeling and prediction at each sampling point. The activity data of the triaxial accelerometer is mapped into an image with the single pixel column and multi-channel which is input into the U-Net network for training and recognition. Our proposal can complete the pixel-level gesture recognition function. The method does not need manual feature extraction and can effectively identify short-term behaviors in long-term activity sequences. We collected the Sanitation dataset and tested the proposed scheme with four open data sets. The experimental results show that compared with Support Vector Machine (SVM), k-Nearest Neighbor (kNN), Decision Tree(DT), Quadratic Discriminant Analysis (QDA), Convolutional Neural Network (CNN) and Fully Convolutional Networks (FCN) methods, our proposal has the highest accuracy and F1-socre in each dataset, and has stable performance and high robustness. At the same time, after the U-Net has finished training, our proposal can achieve fast enough recognition speed.
Dynamic DNN Decomposition for Lossless Synergistic Inference
Jan 15, 2021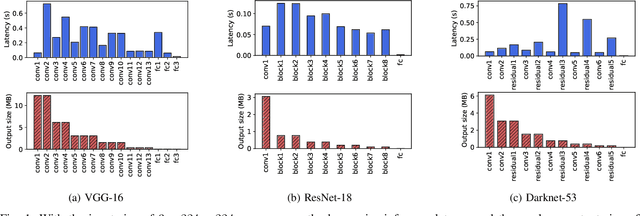

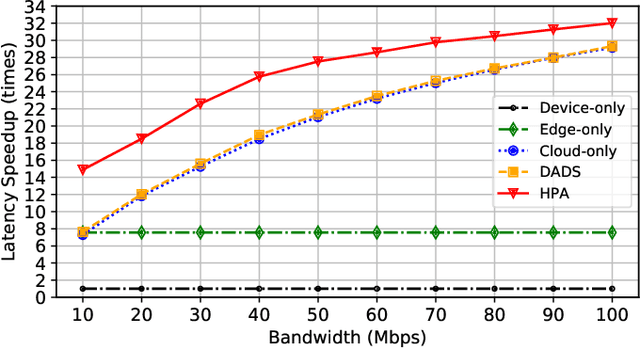
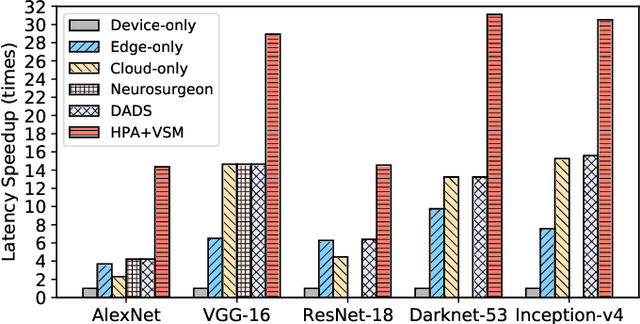
Deep neural networks (DNNs) sustain high performance in today's data processing applications. DNN inference is resource-intensive thus is difficult to fit into a mobile device. An alternative is to offload the DNN inference to a cloud server. However, such an approach requires heavy raw data transmission between the mobile device and the cloud server, which is not suitable for mission-critical and privacy-sensitive applications such as autopilot. To solve this problem, recent advances unleash DNN services using the edge computing paradigm. The existing approaches split a DNN into two parts and deploy the two partitions to computation nodes at two edge computing tiers. Nonetheless, these methods overlook collaborative device-edge-cloud computation resources. Besides, previous algorithms demand the whole DNN re-partitioning to adapt to computation resource changes and network dynamics. Moreover, for resource-demanding convolutional layers, prior works do not give a parallel processing strategy without loss of accuracy at the edge side. To tackle these issues, we propose D3, a dynamic DNN decomposition system for synergistic inference without precision loss. The proposed system introduces a heuristic algorithm named horizontal partition algorithm to split a DNN into three parts. The algorithm can partially adjust the partitions at run time according to processing time and network conditions. At the edge side, a vertical separation module separates feature maps into tiles that can be independently run on different edge nodes in parallel. Extensive quantitative evaluation of five popular DNNs illustrates that D3 outperforms the state-of-the-art counterparts up to 3.4 times in end-to-end DNN inference time and reduces backbone network communication overhead up to 3.68 times.
ResAtom System: Protein and Ligand Affinity Prediction Model Based on Deep Learning
Apr 17, 2021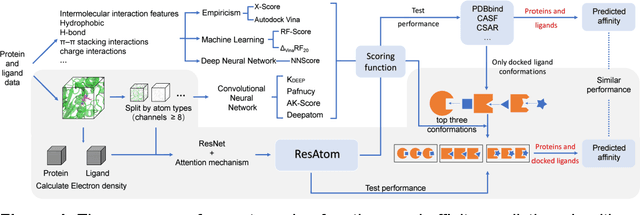
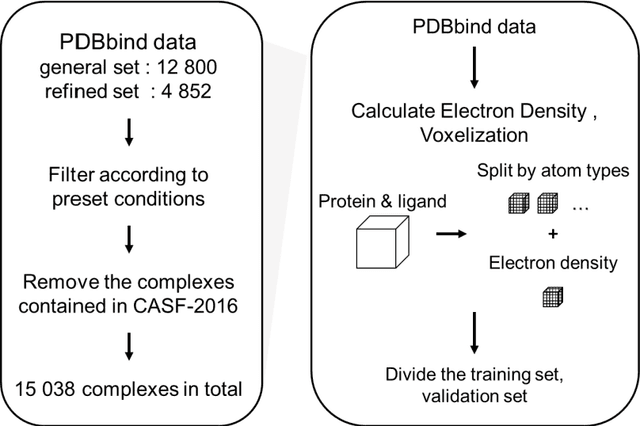
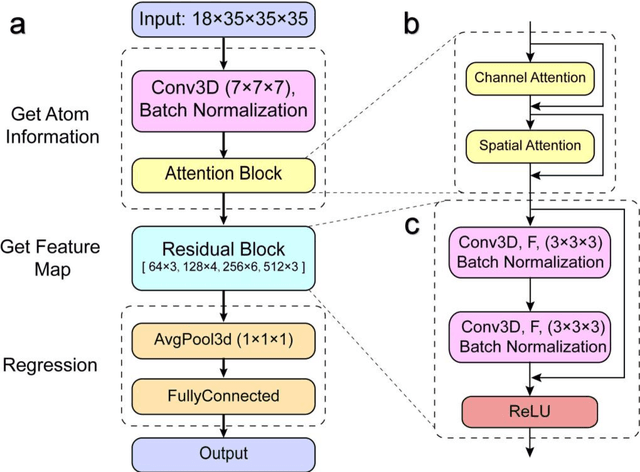
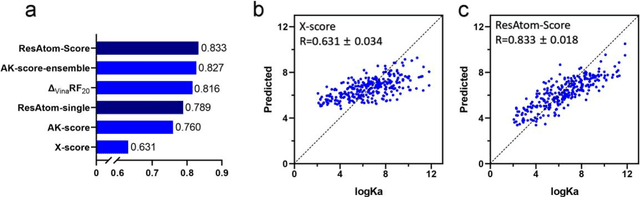
Motivation: Protein-ligand affinity prediction is an important part of structure-based drug design. It includes molecular docking and affinity prediction. Although molecular dynamics can predict affinity with high accuracy at present, it is not suitable for large-scale virtual screening. The existing affinity prediction and evaluation functions based on deep learning mostly rely on experimentally-determined conformations. Results: We build a predictive model of protein-ligand affinity through the ResNet neural network with added attention mechanism. The resulting ResAtom-Score model achieves Pearson's correlation coefficient R = 0.833 on the CASF-2016 benchmark test set. At the same time, we evaluated the performance of a variety of existing scoring functions in combination with ResAtom-Score in the absence of experimentally-determined conformations. The results show that the use of {\Delta}VinaRF20 in combination with ResAtom-Score can achieve affinity prediction close to scoring functions in the presence of experimentally-determined conformations. These results suggest that ResAtom system may be used for in silico screening of small molecule ligands with target proteins in the future. Availability: https://github.com/wyji001/ResAtom
TouchRoller: A Rolling Optical Tactile Sensor for Rapid Assessment of Large Surfaces
Feb 28, 2021

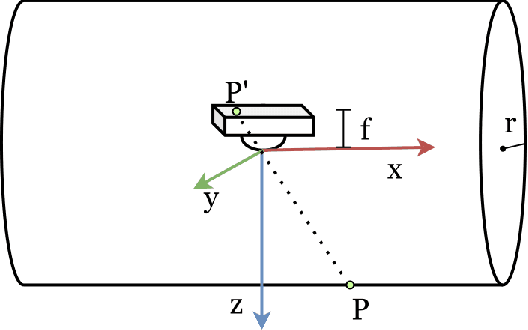

Tactile sensing is important for robots to perceive the world as it captures the texture and hardness of the object in contact and is robust to illumination and colour variances. However, due to the limited sensing area and the resistance of the fixed surface, current tactile sensors have to tap the tactile sensor on target object many times when assessing a large surface, i.e., pressing, lifting up and shifting to another region. This process is ineffective and time consuming. It is also undesirable to drag such sensors as this often damages the sensitive membrane of the sensor or the object. To address these problems, we propose a cylindrical optical tactile sensor named TouchRoller that can roll around its center axis. It maintains being in contact with the assessed surface throughout the entire motion, which allows for measuring the object continuously and effectively. Extensive experiments show that the TouchRoller sensor can cover a textured surface of 8cm*11cm in a short time of 10s, much more effectively than a flat optical tactile sensor (in 196s). The reconstructed map of the texture from the collected tactile images has a high Structural Similarity Index (SSIM) of 0.31 on average, when compared with the visual texture. In addition, the contacts on the sensor can be localised with a low localisation error, 2.63mm in the center regions and 7.66mm on average. The proposed sensor will enable the fast assessment of large surfaces with high-resolution tactile sensing, and also the effective collection of tactile images.
A Novel Genetic Search Scheme Based on Nature -- Inspired Evolutionary Algorithms for Self-Dual Codes
Dec 22, 2020
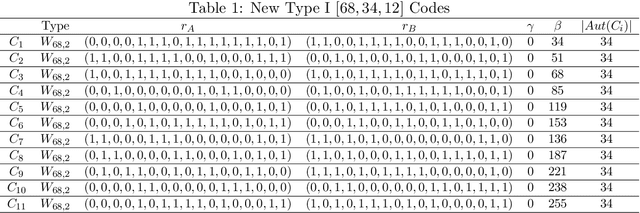
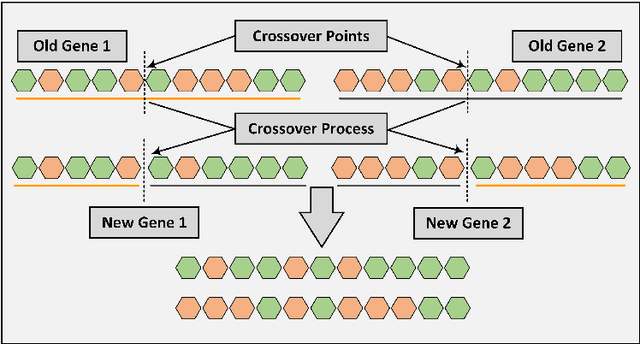
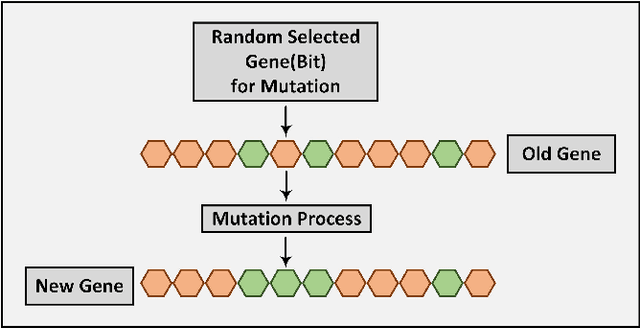
In this paper, a genetic algorithm, one of the evolutionary algorithms optimization methods, is used for the first time for the problem of finding extremal binary self-dual codes. We present a comparison of the computational times between a genetic algorithm and a linear search for different size search spaces and show that the genetic algorithm is capable of finding binary self-dual codes significantly faster than the linear search. Moreover, by employing a known matrix construction together with the genetic algorithm, we are able to obtain new binary self-dual codes of lengths 68 and 72 in a significantly short time. In particular, we obtain 11 new extremal binary self-dual codes of length 68 and 17 new binary self-dual codes of length 72.
An N Time-Slice Dynamic Chain Event Graph
Aug 17, 2018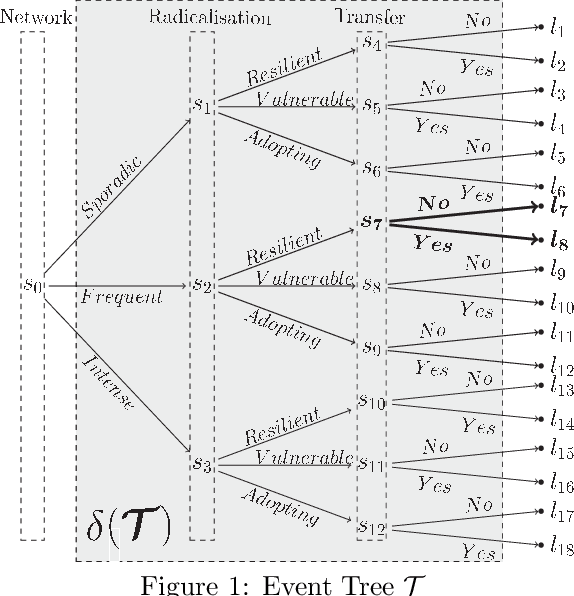
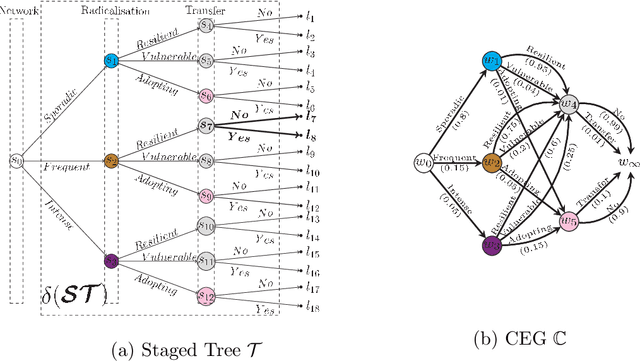
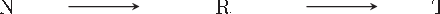
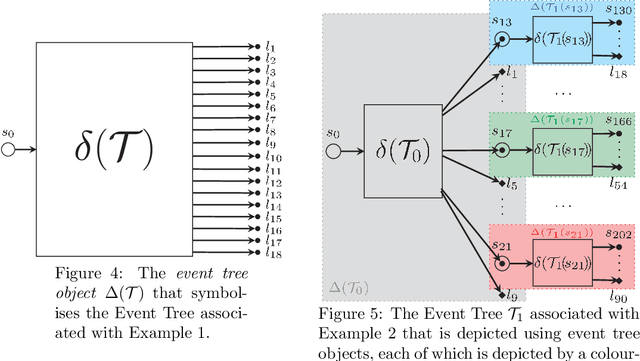
The Dynamic Chain Event Graph (DCEG) is able to depict many classes of discrete random processes exhibiting asymmetries in their developments and context-specific conditional probabilities structures. However, paradoxically, this very generality has so far frustrated its wide application. So in this paper we develop an object-oriented method to fully analyse a particularly useful and feasibly implementable new subclass of these graphical models called the N Time-Slice DCEG (NT-DCEG). After demonstrating a close relationship between an NT-DCEG and a specific class of Markov processes, we discuss how graphical modellers can exploit this connection to gain a deep understanding of their processes. We also show how to read from the topology of this graph context-specific independence statements that can then be checked by domain experts. Our methods are illustrated throughout using examples of dynamic multivariate processes describing inmate radicalisation in a prison.
Co-BERT: A Context-Aware BERT Retrieval Model Incorporating Local and Query-specific Context
Apr 17, 2021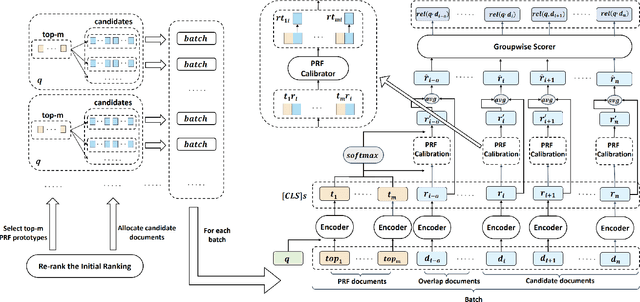
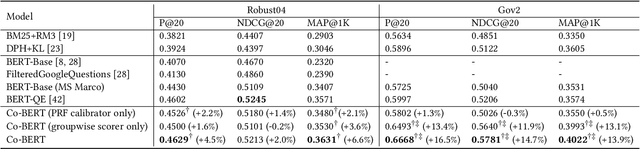
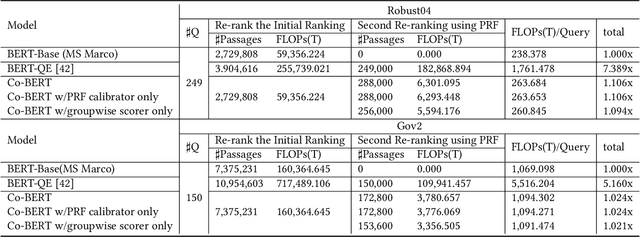

BERT-based text ranking models have dramatically advanced the state-of-the-art in ad-hoc retrieval, wherein most models tend to consider individual query-document pairs independently. In the mean time, the importance and usefulness to consider the cross-documents interactions and the query-specific characteristics in a ranking model have been repeatedly confirmed, mostly in the context of learning to rank. The BERT-based ranking model, however, has not been able to fully incorporate these two types of ranking context, thereby ignoring the inter-document relationships from the ranking and the differences among queries. To mitigate this gap, in this work, an end-to-end transformer-based ranking model, named Co-BERT, has been proposed to exploit several BERT architectures to calibrate the query-document representations using pseudo relevance feedback before modeling the relevance of a group of documents jointly. Extensive experiments on two standard test collections confirm the effectiveness of the proposed model in improving the performance of text re-ranking over strong fine-tuned BERT-Base baselines. We plan to make our implementation open source to enable further comparisons.
Local Granger Causality
Oct 26, 2020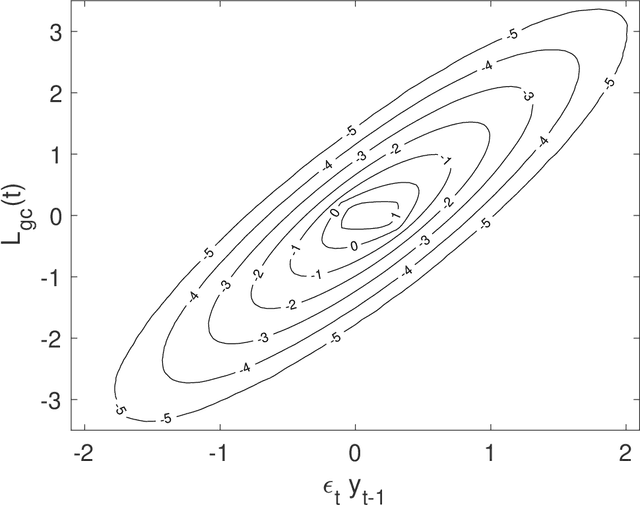
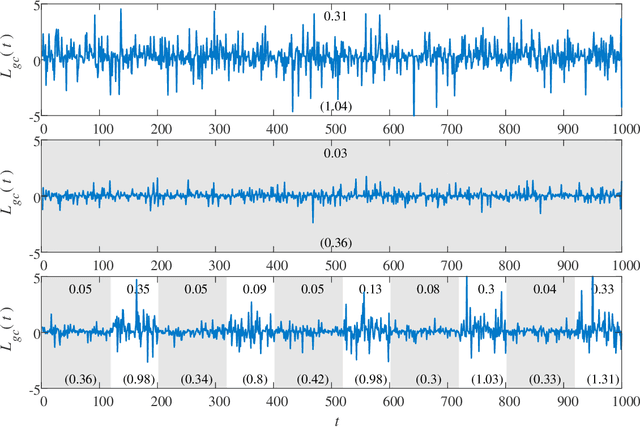
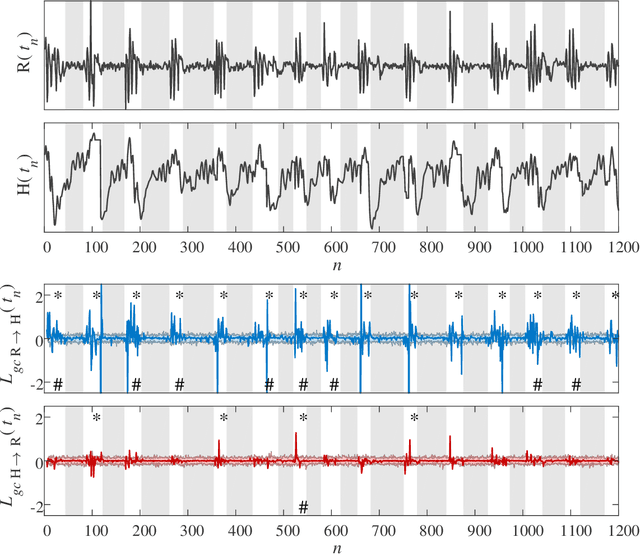
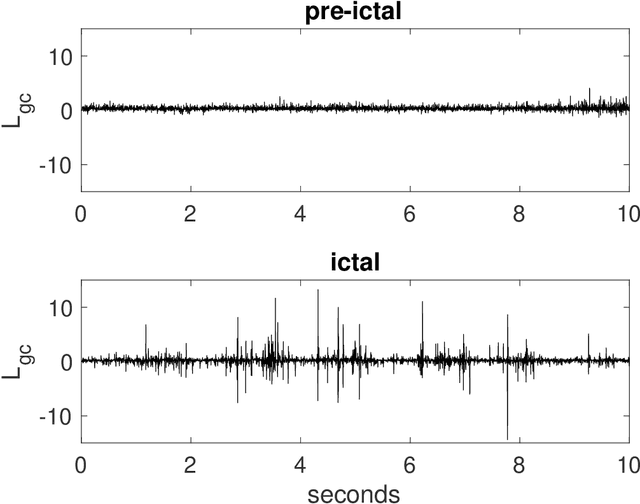
Granger causality is a statistical notion of causal influence based on prediction via vector autoregression. For Gaussian variables it is equivalent to transfer entropy, an information-theoretic measure of time-directed information transfer between jointly dependent processes. We exploit such equivalence and calculate exactly the 'local Granger causality', i.e. the profile of the information transfer at each discrete time point in Gaussian processes; in this frame Granger causality is the average of its local version. Our approach offers a robust and computationally fast method to follow the information transfer along the time history of linear stochastic processes, as well as of nonlinear complex systems studied in the Gaussian approximation.
Open Intent Discovery through Unsupervised Semantic Clustering and Dependency Parsing
Apr 25, 2021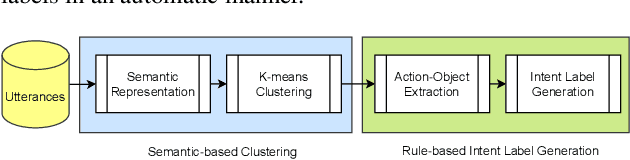

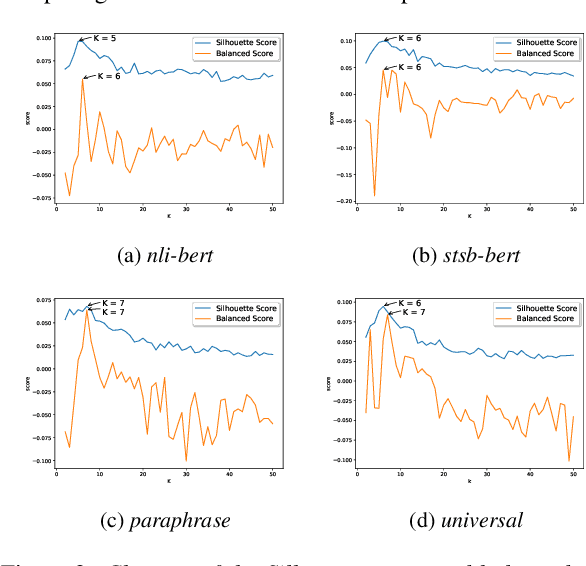

Intent understanding plays an important role in dialog systems, and is typically formulated as a supervised classification problem. However, it is challenging and time-consuming to design the intent labels manually to support a new domain. This paper proposes an unsupervised two-stage approach to discover intents and generate meaningful intent labels automatically from a collection of unlabeled utterances. In the first stage, we aim to generate a set of semantically coherent clusters where the utterances within each cluster convey the same intent. We obtain the utterance representation from various pre-trained sentence embeddings and present a metric of balanced score to determine the optimal number of clusters in K-means clustering. In the second stage, the objective is to generate an intent label automatically for each cluster. We extract the ACTION-OBJECT pair from each utterance using a dependency parser and take the most frequent pair within each cluster, e.g., book-restaurant, as the generated cluster label. We empirically show that the proposed unsupervised approach can generate meaningful intent labels automatically and achieves high precision and recall in utterance clustering and intent discovery.