 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
Apr 29, 2021
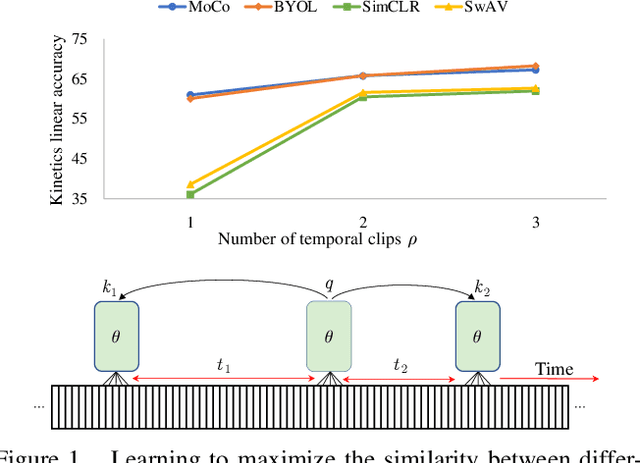

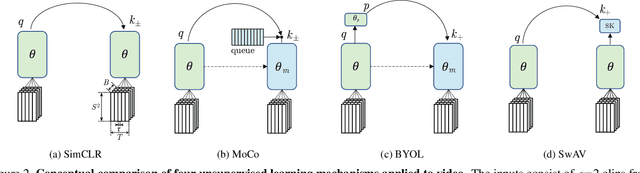
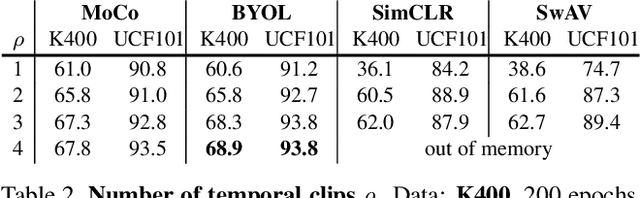
We present a large-scale study on unsupervised spatiotemporal representation learning from videos. With a unified perspective on four recent image-based frameworks, we study a simple objective that can easily generalize all these methods to space-time. Our objective encourages temporally-persistent features in the same video, and in spite of its simplicity, it works surprisingly well across: (i) different unsupervised frameworks, (ii) pre-training datasets, (iii) downstream datasets, and (iv) backbone architectures. We draw a series of intriguing observations from this study, e.g., we discover that encouraging long-spanned persistency can be effective even if the timespan is 60 seconds. In addition to state-of-the-art results in multiple benchmarks, we report a few promising cases in which unsupervised pre-training can outperform its supervised counterpart. Code is made available at https://github.com/facebookresearch/SlowFast
Deep neural network-based automatic metasurface design with a wide frequency range
Jan 22, 2021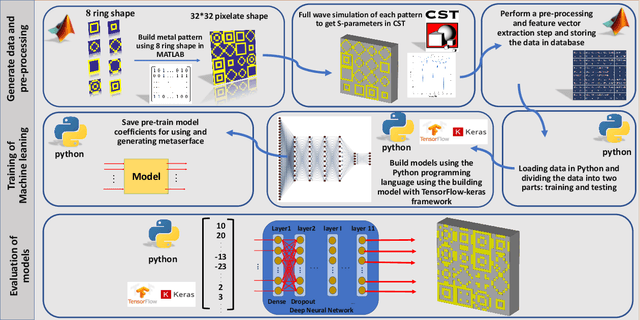
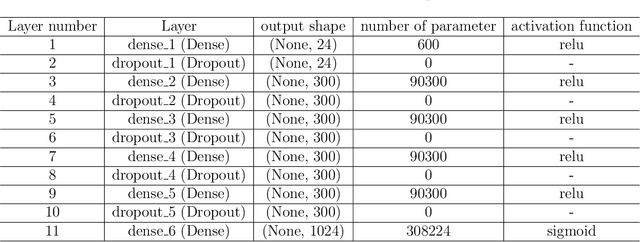
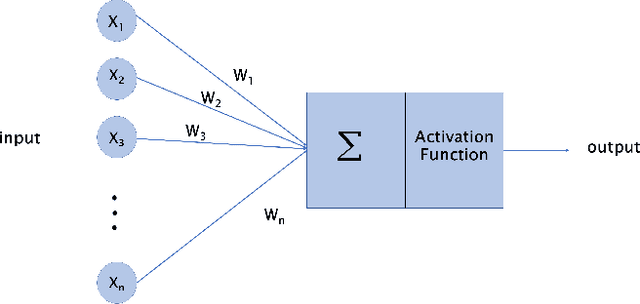
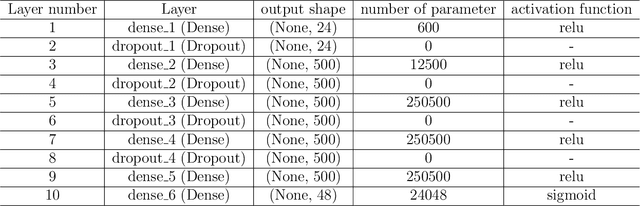
Beyond the scope of conventional metasurface which necessitates plenty of computational resources and time, an inverse design approach using machine learning algorithms promises an effective way for metasurfaces design. In this paper, benefiting from Deep Neural Network (DNN), an inverse design procedure of a metasurface in an ultra-wide working frequency band is presented where the output unit cell structure can be directly computed by a specified design target. To reach the highest working frequency, for training the DNN, we consider 8 ring-shaped patterns to generate resonant notches at a wide range of working frequencies from 4 to 45 GHz. We propose two network architectures. In one architecture, we restricted the output of the DNN, so the network can only generate the metasurface structure from the input of 8 ring-shaped patterns. This approach drastically reduces the computational time, while keeping the network's accuracy above 91\%. We show that our model based on DNN can satisfactorily generate the output metasurface structure with an average accuracy of over 90\% in both network architectures. Determination of the metasurface structure directly without time-consuming optimization procedures, having an ultra-wide working frequency, and high average accuracy equip an inspiring platform for engineering projects without the need for complex electromagnetic theory.
Medical Time Series Classification with Hierarchical Attention-based Temporal Convolutional Networks: A Case Study of Myotonic Dystrophy Diagnosis
Mar 28, 2019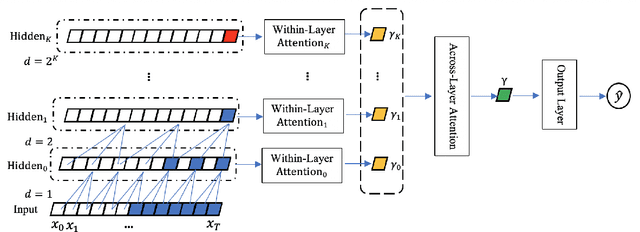
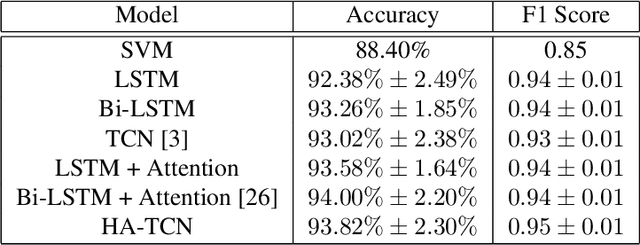
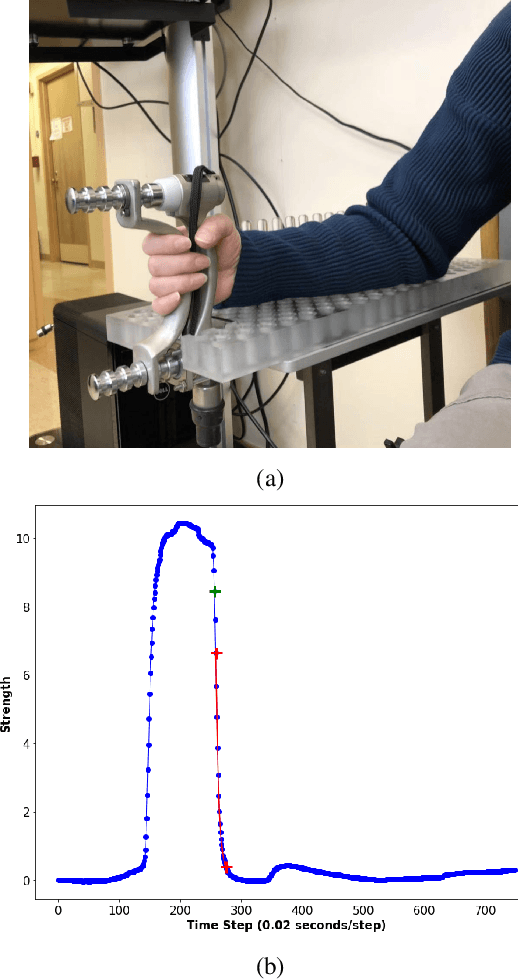
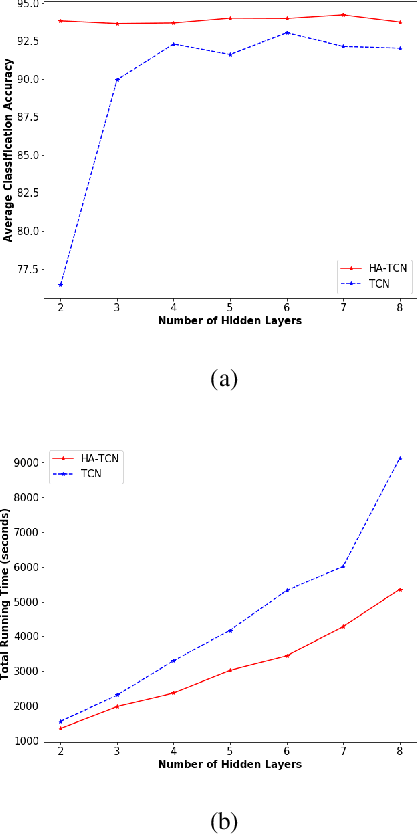
Myotonia, which refers to delayed muscle relaxation after contraction, is the main symptom of myotonic dystrophy patients. We propose a hierarchical attention-based temporal convolutional network (HA-TCN) for myotonic dystrohpy diagnosis from handgrip time series data, and introduce mechanisms that enable model explainability. We compare the performance of the HA-TCN model against that of benchmark TCN models, LSTM models with and without attention mechanisms, and SVM approaches with handcrafted features. In terms of classification accuracy and F1 score, we found all deep learning models have similar levels of performance, and they all outperform SVM. Further, the HA-TCN model outperforms its TCN counterpart with regards to computational efficiency regardless of network depth, and in terms of performance particularly when the number of hidden layers is small. Lastly, HA-TCN models can consistently identify relevant time series segments in the relaxation phase of the handgrip time series, and exhibit increased robustness to noise when compared to attention-based LSTM models.
Action4D: Real-time Action Recognition in the Crowd and Clutter
Jun 06, 2018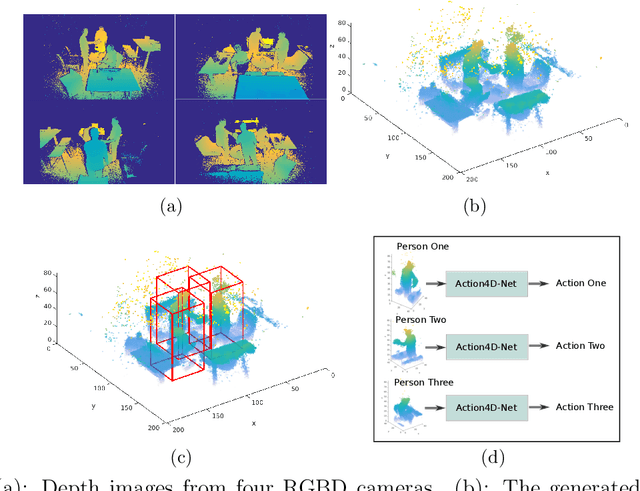
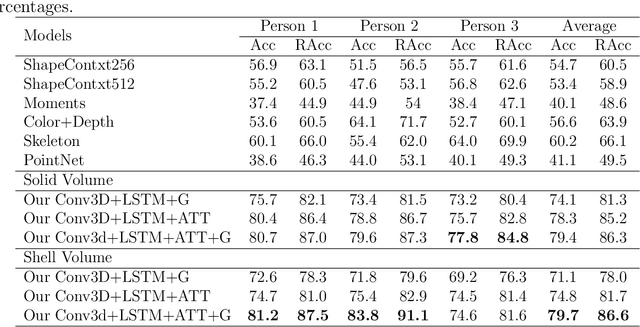
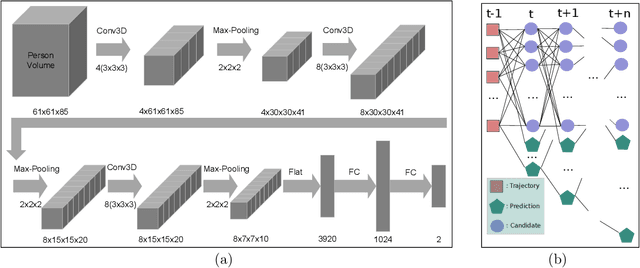
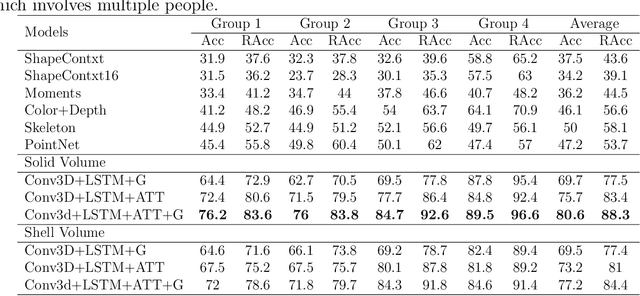
Recognizing every person's action in a crowded and cluttered environment is a challenging task. In this paper, we propose a real-time action recognition method, Action4D, which gives reliable and accurate results in the real-world settings. We propose to tackle the action recognition problem using a holistic 4D "scan" of a cluttered scene to include every detail about the people and environment. Recognizing multiple people's actions in the cluttered 4D representation is a new problem. In this paper, we propose novel methods to solve this problem. We propose a new method to track people in 4D, which can reliably detect and follow each person in real time. We propose a new deep neural network, the Action4D-Net, to recognize the action of each tracked person. The Action4D-Net's novel structure uses both the global feature and the focused attention to achieve state-of-the-art result. Our real-time method is invariant to camera view angles, resistant to clutter and able to handle crowd. The experimental results show that the proposed method is fast, reliable and accurate. Our method paves the way to action recognition in the real-world applications and is ready to be deployed to enable smart homes, smart factories and smart stores.
Surveillance of COVID-19 Pandemic using Social Media: A Reddit Study in North Carolina
Jun 07, 2021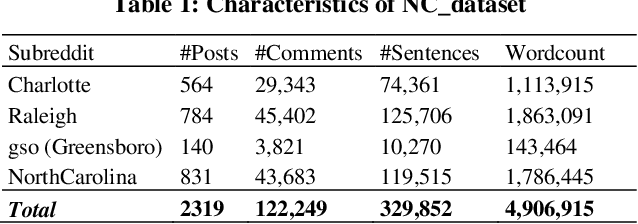
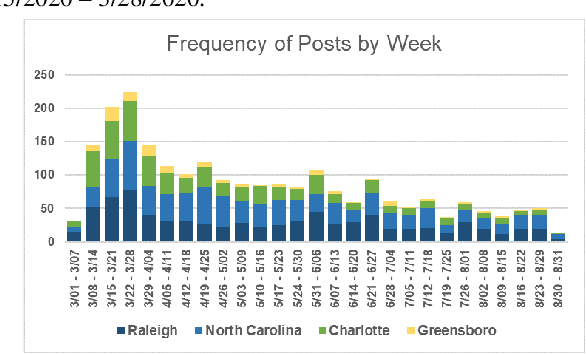
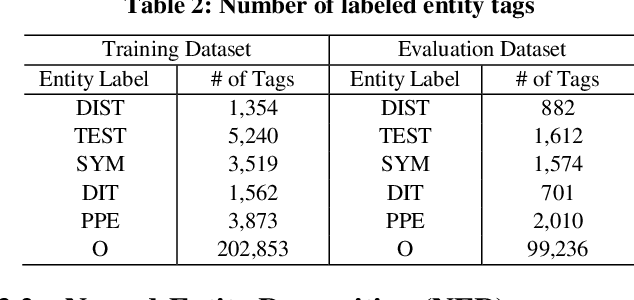
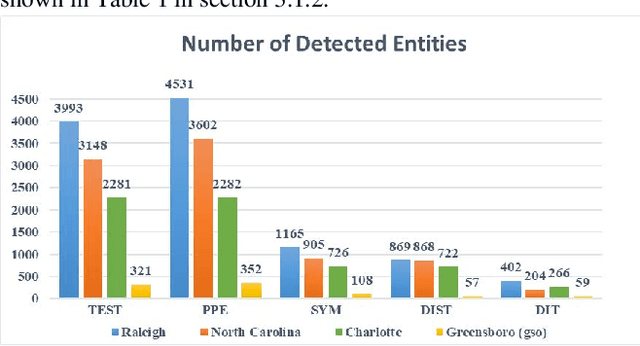
Coronavirus disease (COVID-19) pandemic has changed various aspects of people's lives and behaviors. At this stage, there are no other ways to control the natural progression of the disease than adopting mitigation strategies such as wearing masks, watching distance, and washing hands. Moreover, at this time of social distancing, social media plays a key role in connecting people and providing a platform for expressing their feelings. In this study, we tap into social media to surveil the uptake of mitigation and detection strategies, and capture issues and concerns about the pandemic. In particular, we explore the research question, "how much can be learned regarding the public uptake of mitigation strategies and concerns about COVID-19 pandemic by using natural language processing on Reddit posts?" After extracting COVID-related posts from the four largest subreddit communities of North Carolina over six months, we performed NLP-based preprocessing to clean the noisy data. We employed a custom Named-entity Recognition (NER) system and a Latent Dirichlet Allocation (LDA) method for topic modeling on a Reddit corpus. We observed that 'mask', 'flu', and 'testing' are the most prevalent named-entities for "Personal Protective Equipment", "symptoms", and "testing" categories, respectively. We also observed that the most discussed topics are related to testing, masks, and employment. The mitigation measures are the most prevalent theme of discussion across all subreddits.
Inferring the Reader: Guiding Automated Story Generation with Commonsense Reasoning
May 04, 2021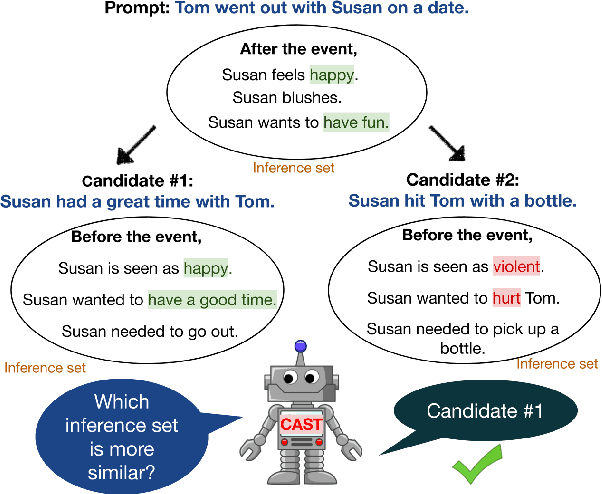



Transformer-based language model approaches to automated story generation currently provide state-of-the-art results. However, they still suffer from plot incoherence when generating narratives over time, and critically lack basic commonsense reasoning. Furthermore, existing methods generally focus only on single-character stories, or fail to track characters at all. To improve the coherence of generated narratives and to expand the scope of character-centric narrative generation, we introduce Commonsense-inference Augmented neural StoryTelling (CAST), a framework for introducing commonsense reasoning into the generation process while modeling the interaction between multiple characters. We find that our CAST method produces significantly more coherent and on-topic two-character stories, outperforming baselines in dimensions including plot plausibility and staying on topic. We also show how the CAST method can be used to further train language models that generate more coherent stories and reduce computation cost.
Field Evaluations of A Deep Learning-based Intelligent Spraying Robot with Flow Control for Pear Orchards
Feb 15, 2021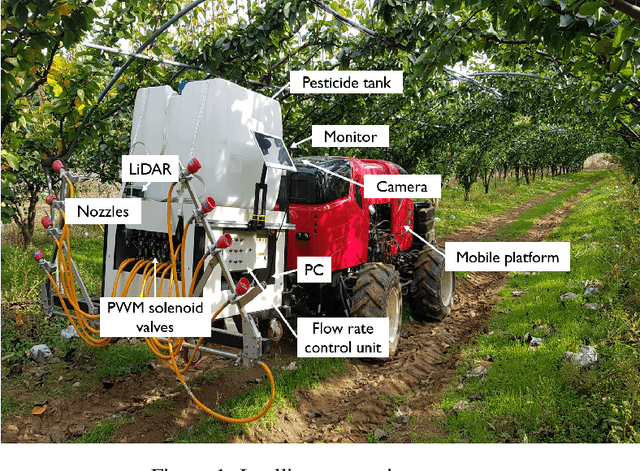


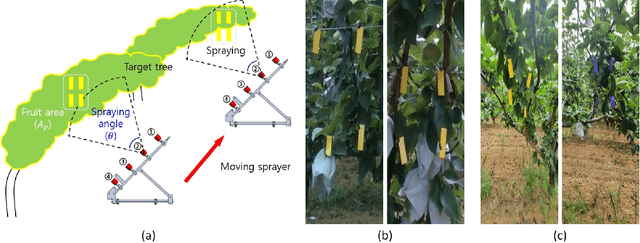
This paper proposes a variable flow control system in real time with deep learning using the segmentation of fruit trees in a pear orchard. The flow rate control in real time, undesired pressure fluctuation and theoretical modeling may differ from those in the real world. Therefore, two types of preliminary experiments were designed to examine the linear relationship of the flow rate modeling. Through a preliminary experiment, the parameters of the pulse width modulation (PWM) controller were optimized, and an actual field experiment was conducted to confirm the performance of the variable flow rate control system. As a result of the field experiment, the performance of the proposed system was satisfactory, as it showed that it could reduce pesticide use and the risk of pesticide exposure. Especially, since the field experiment was conducted in an unstructured environment, the proposed variable flow control system is expected to be sufficiently applicable to other orchards.
Coupled Analysis Dictionary Learning to inductively learn inversion: Application to real-time reconstruction of Biomedical signals
Dec 24, 2018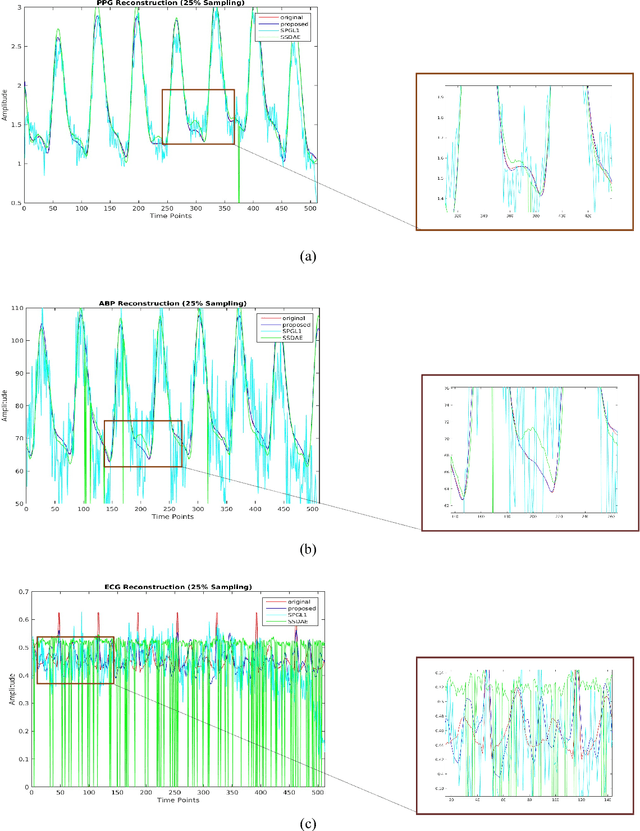
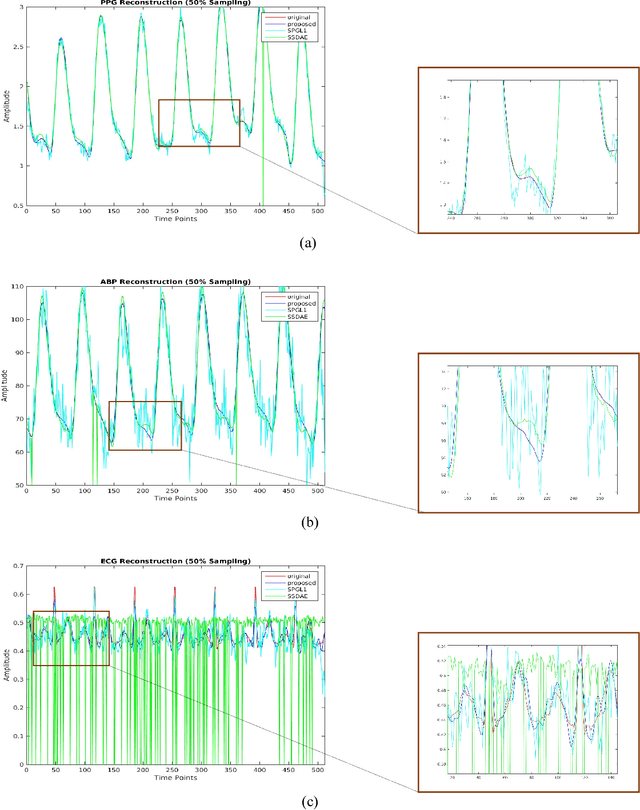
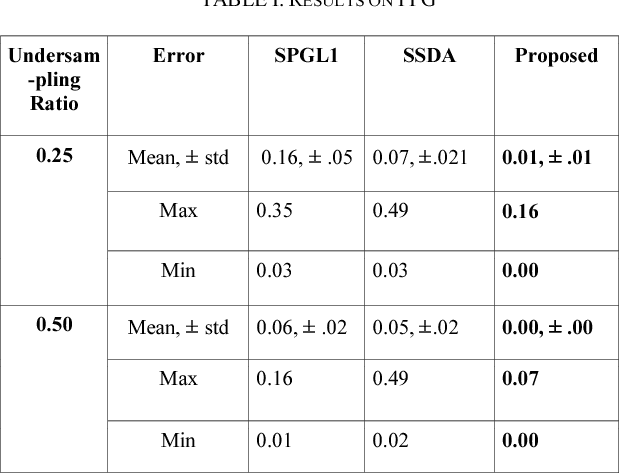
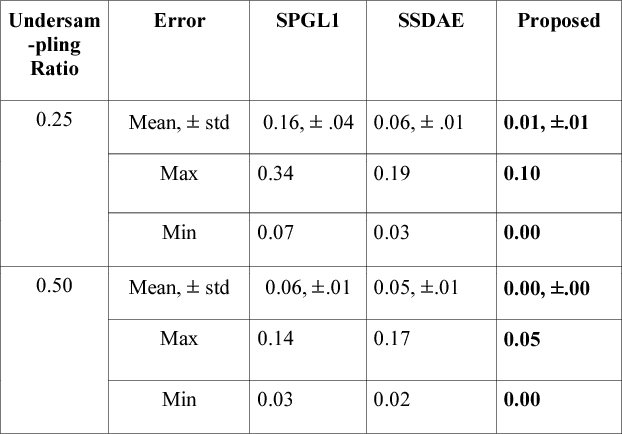
This work addresses the problem of reconstructing biomedical signals from their lower dimensional projections. Traditionally Compressed Sensing (CS) based techniques have been employed for this task. These are transductive inversion processes, the problem with these approaches is that the inversion is time-consuming and hence not suitable for real-time applications. With the recent advent of deep learning, Stacked Sparse Denoising Autoencoder (SSDAE) has been used for learning inversion in an inductive setup. The training period for inductive learning is large but is very fast during application -- capable of real-time speed. This work proposes a new approach for inductive learning of the inversion process. It is based on Coupled Analysis Dictionary Learning. Results on Biomedical signal reconstruction show that our proposed approach is very fast and yields result far better than CS and SSDAE.
Scorpion detection and classification systems based on computer vision and deep learning for health security purposes
May 31, 2021
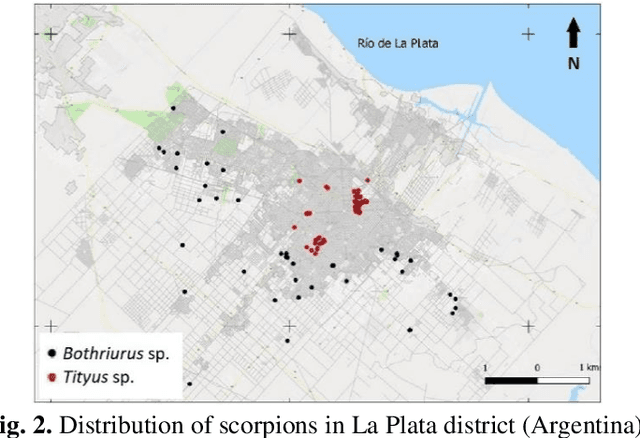
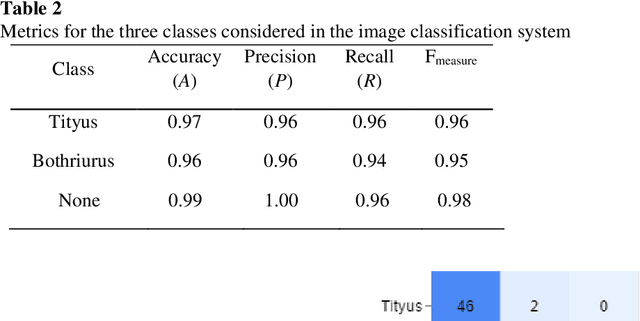
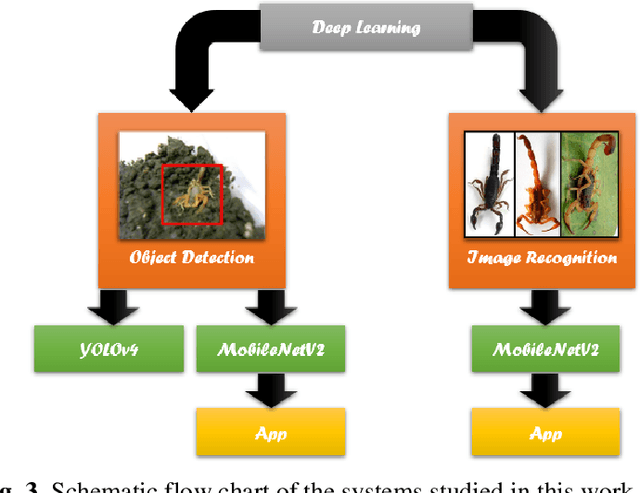
In this paper, two novel automatic and real-time systems for the detection and classification of two genera of scorpions found in La Plata city (Argentina) were developed using computer vision and deep learning techniques. The object detection technique was implemented with two different methods, YOLO (You Only Look Once) and MobileNet, based on the shape features of the scorpions. High accuracy values of 88% and 91%, and high recall values of 90% and 97%, have been achieved for both models, respectively, which guarantees that they can successfully detect scorpions. In addition, the MobileNet method has been shown to have excellent performance to detect scorpions within an uncontrolled environment and to perform multiple detections. The MobileNet model was also used for image classification in order to successfully distinguish between dangerous scorpion (Tityus) and non-dangerous scorpion (Bothriurus) with the purpose of providing a health security tool. Applications for smartphones were developed, with the advantage of the portability of the systems, which can be used as a help tool for emergency services, or for biological research purposes. The developed systems can be easily scalable to other genera and species of scorpions to extend the region where these applications can be used.
Self-supervised on Graphs: Contrastive, Generative,or Predictive
May 24, 2021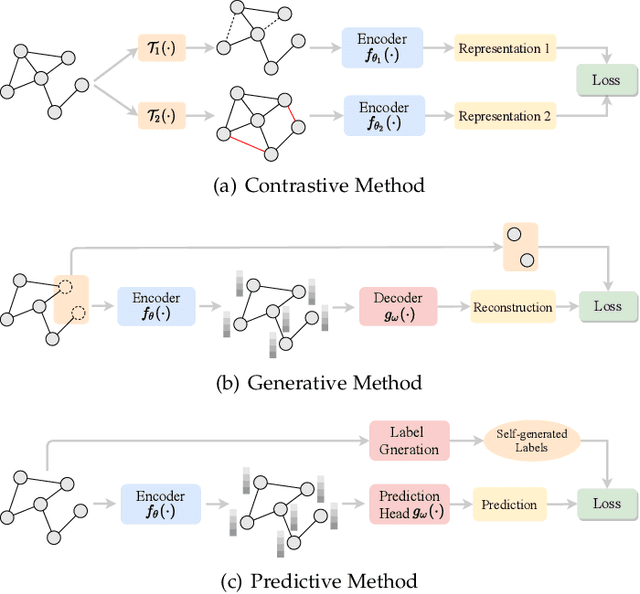
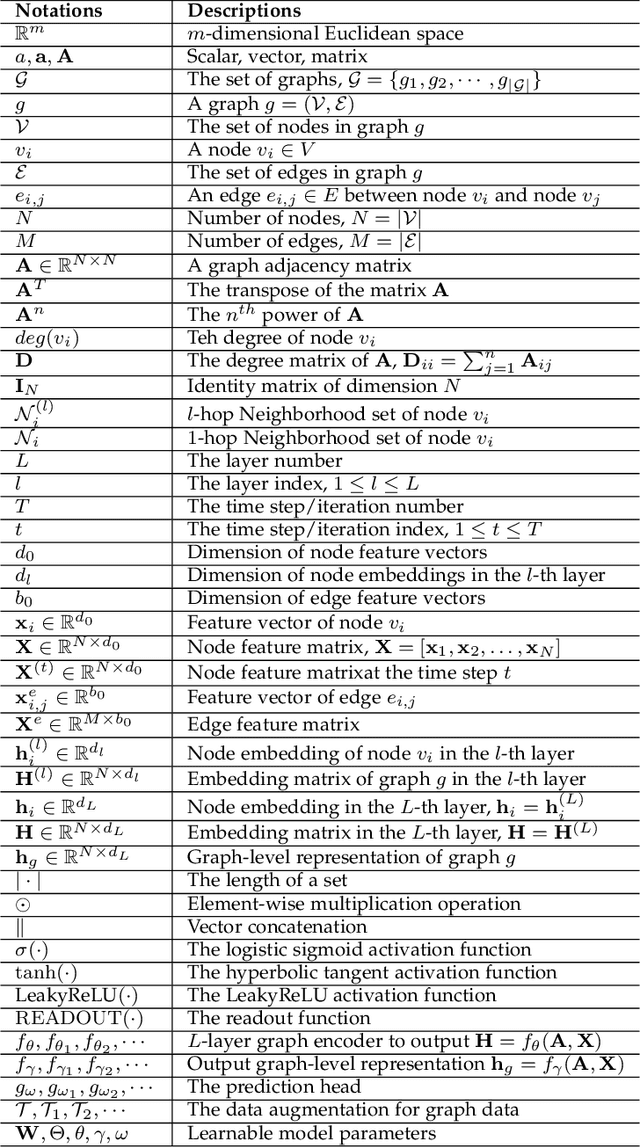
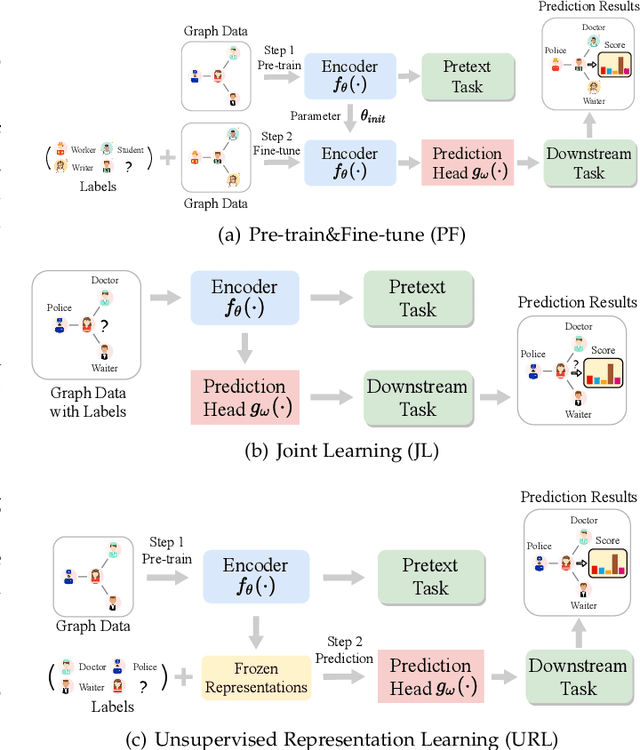
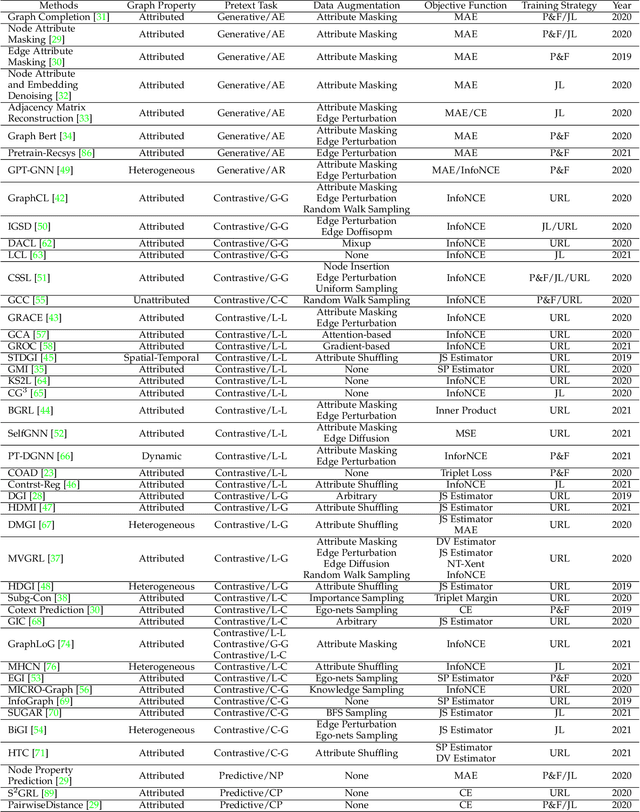
Deep learning on graphs has recently achieved remarkable success on a variety of tasks while such success relies heavily on the massive and carefully labeled data. However, precise annotations are generally very expensive and time-consuming. To address this problem, self-supervised learning (SSL) is emerging as a new paradigm for extracting informative knowledge through well-designed pretext tasks without relying on manual labels. In this survey, we extend the concept of SSL, which first emerged in the fields of computer vision and natural language processing, to present a timely and comprehensive review of the existing SSL techniques for graph data. Specifically, we divide existing graph SSL methods into three categories: contrastive, generative, and predictive. More importantly, unlike many other surveys that only provide a high-level description of published research, we present an additional mathematical summary of the existing works in a unified framework. Furthermore, to facilitate methodological development and empirical comparisons, we also summarize the commonly used datasets, evaluation metrics, downstream tasks, and open-source implementations of various algorithms. Finally, we discuss the technical challenges and potential future directions for improving graph self-supervised learning.