 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Random Feature Attention
Mar 19, 2021
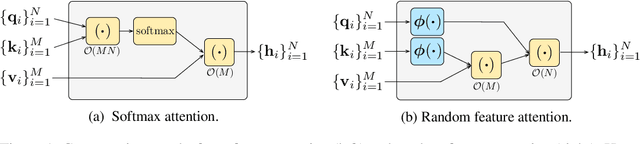
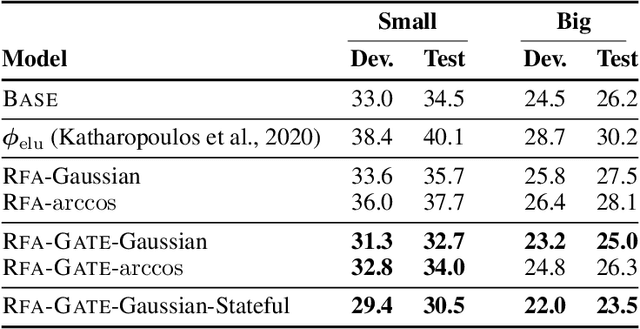
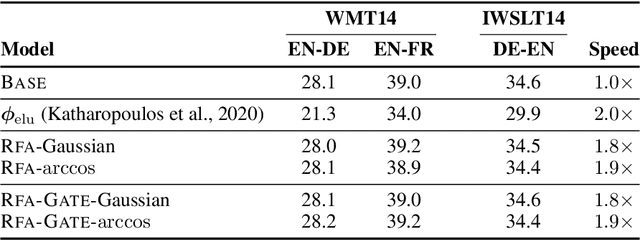
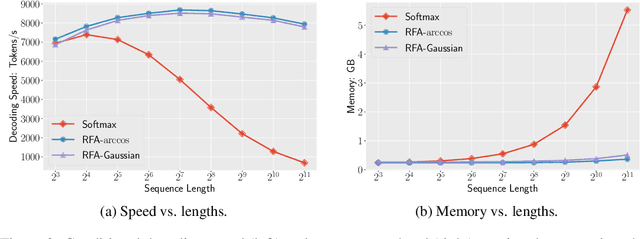
Transformers are state-of-the-art models for a variety of sequence modeling tasks. At their core is an attention function which models pairwise interactions between the inputs at every timestep. While attention is powerful, it does not scale efficiently to long sequences due to its quadratic time and space complexity in the sequence length. We propose RFA, a linear time and space attention that uses random feature methods to approximate the softmax function, and explore its application in transformers. RFA can be used as a drop-in replacement for conventional softmax attention and offers a straightforward way of learning with recency bias through an optional gating mechanism. Experiments on language modeling and machine translation demonstrate that RFA achieves similar or better performance compared to strong transformer baselines. In the machine translation experiment, RFA decodes twice as fast as a vanilla transformer. Compared to existing efficient transformer variants, RFA is competitive in terms of both accuracy and efficiency on three long text classification datasets. Our analysis shows that RFA's efficiency gains are especially notable on long sequences, suggesting that RFA will be particularly useful in tasks that require working with large inputs, fast decoding speed, or low memory footprints.
Differentiable Neural Architecture Search with Morphism-based Transformable Backbone Architectures
Jun 14, 2021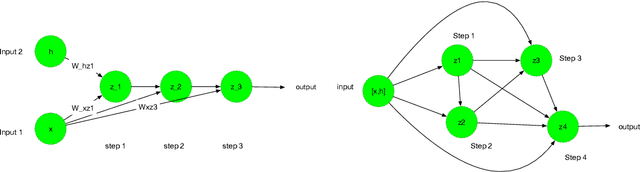

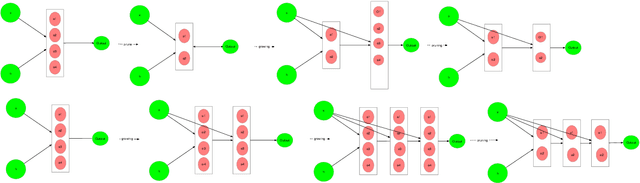
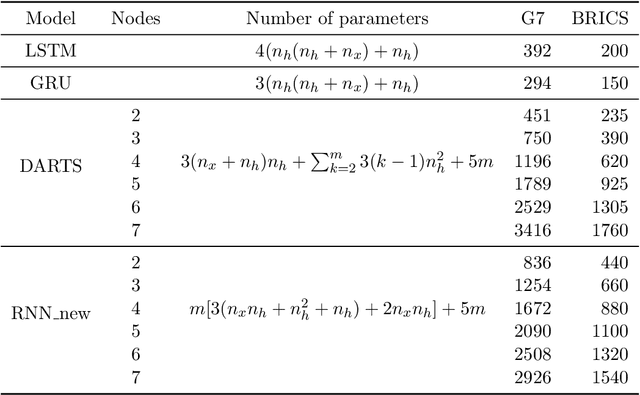
This study aims at making the architecture search process more adaptive for one-shot or online training. It is extended from the existing study on differentiable neural architecture search, and we made the backbone architecture transformable rather than fixed during the training process. As is known, differentiable neural architecture search (DARTS) requires a pre-defined over-parameterized backbone architecture, while its size is to be determined manually. Also, in DARTS backbone, Hadamard product of two elements is not introduced, which exists in both LSTM and GRU cells for recurrent nets. This study introduces a growing mechanism for differentiable neural architecture search based on network morphism. It enables growing of the cell structures from small size towards large size ones with one-shot training. Two modes can be applied in integrating the growing and original pruning process. We also implement a recently proposed two-input backbone architecture for recurrent neural networks. Initial experimental results indicate that our approach and the two-input backbone structure can be quite effective compared with other baseline architectures including LSTM, in a variety of learning tasks including multi-variate time series forecasting and language modeling. On the other hand, we find that dynamic network transformation is promising in improving the efficiency of differentiable architecture search.
Relative Positional Encoding for Transformers with Linear Complexity
May 18, 2021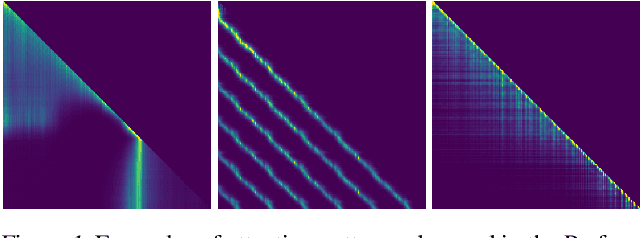
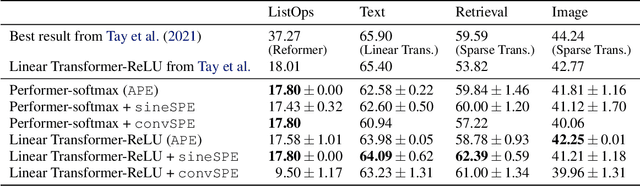

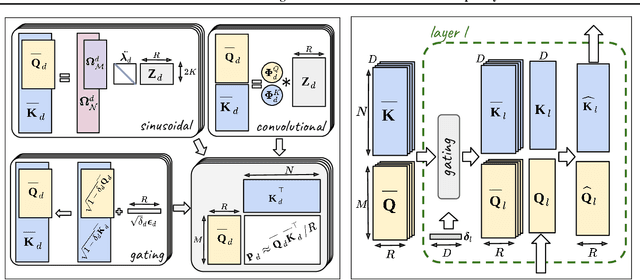
Recent advances in Transformer models allow for unprecedented sequence lengths, due to linear space and time complexity. In the meantime, relative positional encoding (RPE) was proposed as beneficial for classical Transformers and consists in exploiting lags instead of absolute positions for inference. Still, RPE is not available for the recent linear-variants of the Transformer, because it requires the explicit computation of the attention matrix, which is precisely what is avoided by such methods. In this paper, we bridge this gap and present Stochastic Positional Encoding as a way to generate PE that can be used as a replacement to the classical additive (sinusoidal) PE and provably behaves like RPE. The main theoretical contribution is to make a connection between positional encoding and cross-covariance structures of correlated Gaussian processes. We illustrate the performance of our approach on the Long-Range Arena benchmark and on music generation.
Fine-Grained $ε$-Margin Closed-Form Stabilization of Parametric Hawkes Processes
May 08, 2021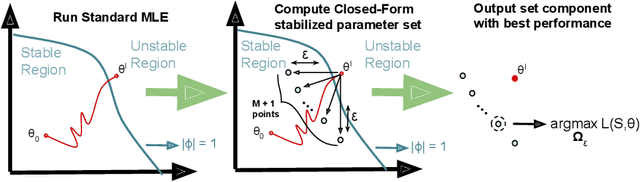
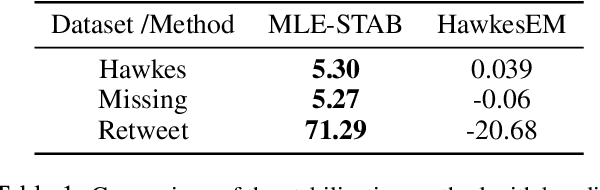
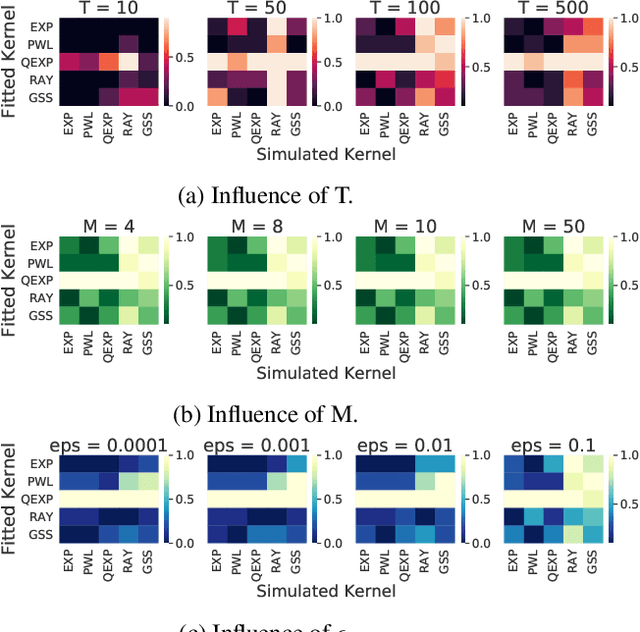

Hawkes Processes have undergone increasing popularity as default tools for modeling self- and mutually exciting interactions of discrete events in continuous-time event streams. A Maximum Likelihood Estimation (MLE) unconstrained optimization procedure over parametrically assumed forms of the triggering kernels of the corresponding intensity function are a widespread cost-effective modeling strategy, particularly suitable for data with few and/or short sequences. However, the MLE optimization lacks guarantees, except for strong assumptions on the parameters of the triggering kernels, and may lead to instability of the resulting parameters .In the present work, we show how a simple stabilization procedure improves the performance of the MLE optimization without these overly restrictive assumptions.This stabilized version of the MLE is shown to outperform traditional methods over sequences of several different lengths.
IA Planner: Motion Planning Using Instantaneous Analysis for Autonomous Vehicle in the Dense Dynamic Scenarios on Highways
Mar 19, 2021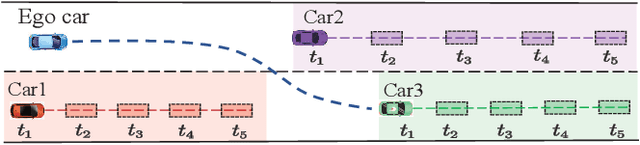
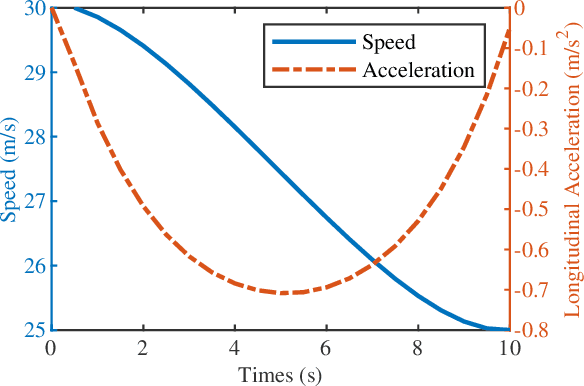
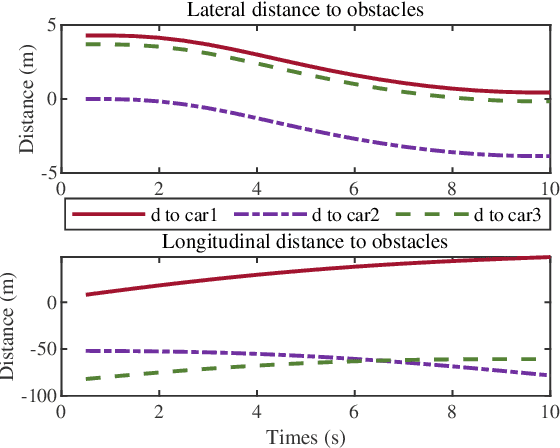

In dense and dynamic scenarios, planning a safe and comfortable trajectory is full of challenges when traffic participants are driving at high speed. The classic graph search and sampling methods first perform path planning and then configure the corresponding speed, which lacks a strategy to deal with the high-speed obstacles. Decoupling optimization methods perform motion planning in the S-L and S-T domains respectively. These methods require a large free configuration space to plan the lane change trajectory. In dense dynamic scenes, it is easy to cause the failure of trajectory planning and be cut in by others, causing slow driving speed and bring safety hazards. We analyze the collision relationship in the spatio-temporal domain, and propose an instantaneous analysis model which only analyzes the collision relationship at the same time. In the model, the collision-free constraints in 3D spatio-temporal domain is projected to the 2D space domain to remove redundant constraints and reduce computational complexity. Experimental results show that our method can plan a safe and comfortable lane-changing trajectory in dense dynamic scenarios. At the same time, it improves traffic efficiency and increases ride comfort.
MLPruning: A Multilevel Structured Pruning Framework for Transformer-based Models
May 30, 2021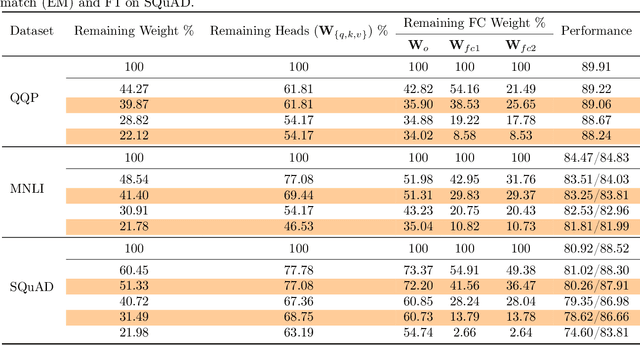
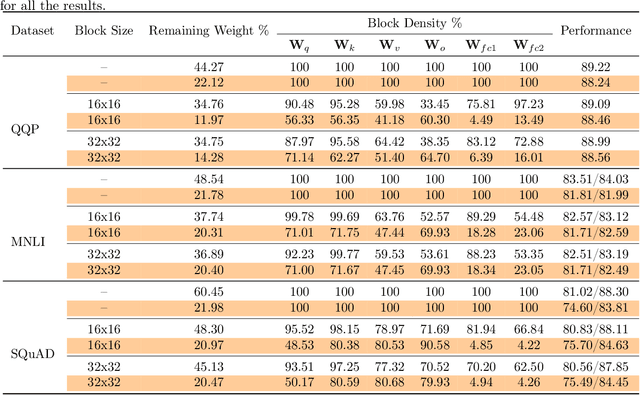
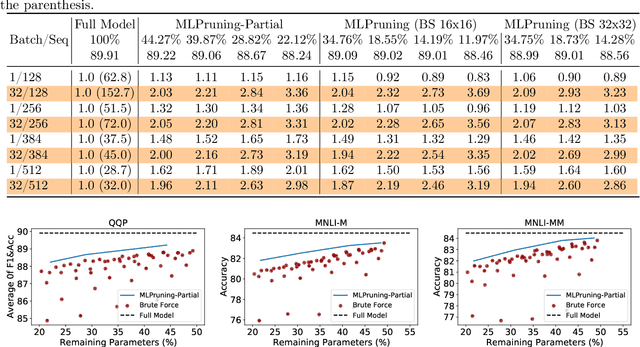
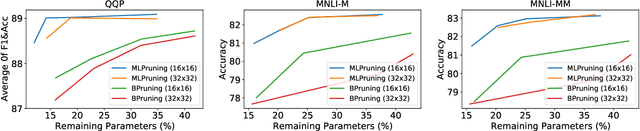
Pruning is an effective method to reduce the memory footprint and computational cost associated with large natural language processing models. However, current approaches either only explore head pruning, which has a limited pruning ratio, or only focus on unstructured pruning, which has negligible effects on the real inference time and/or power consumption. To address these challenges, we develop a novel MultiLevel structured Pruning (MLPruning) framework, which uses three different levels of structured pruning: head pruning, row pruning, and block-wise sparse pruning. We propose using a learnable Top-k threshold, which employs an adaptive regularization to adjust the regularization magnitude adaptively, to select appropriate pruning ratios for different weight matrices. We also propose a two-step pipeline to combine block-wise pruning with head/row pruning to achieve high structured pruning ratios with minimum accuracy degradation. Our empirical results show that for \bertbase, with \textapprox20\% of remaining weights, \OURS can achieve an accuracy that is comparable to the full model on QQP/MNLI/\squad, with up to \textapprox3.69x speedup. Our framework has been open sourced~\cite{codebase}.
Automation for Interpretable Machine Learning Through a Comparison of Loss Functions to Regularisers
Jun 07, 2021
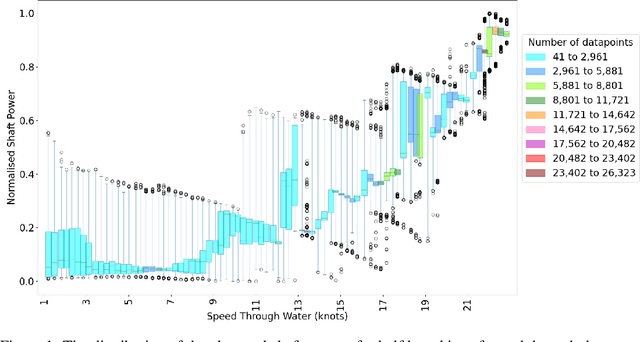
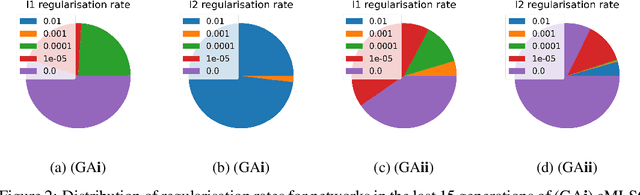
To increase the ubiquity of machine learning it needs to be automated. Automation is cost-effective as it allows experts to spend less time tuning the approach, which leads to shorter development times. However, while this automation produces highly accurate architectures, they can be uninterpretable, acting as `black-boxes' which produce low conventional errors but fail to model the underlying input-output relationships -- the ground truth. This paper explores the use of the Fit to Median Error measure in machine learning regression automation, using evolutionary computation in order to improve the approximation of the ground truth. When used alongside conventional error measures it improves interpretability by regularising learnt input-output relationships to the conditional median. It is compared to traditional regularisers to illustrate that the use of the Fit to Median Error produces regression neural networks which model more consistent input-output relationships. The problem considered is ship power prediction using a fuel-saving air lubrication system, which is highly stochastic in nature. The networks optimised for their Fit to Median Error are shown to approximate the ground truth more consistently, without sacrificing conventional Minkowski-r error values.
Forecasting Thermoacoustic Instabilities in Liquid Propellant Rocket Engines Using Multimodal Bayesian Deep Learning
Jul 01, 2021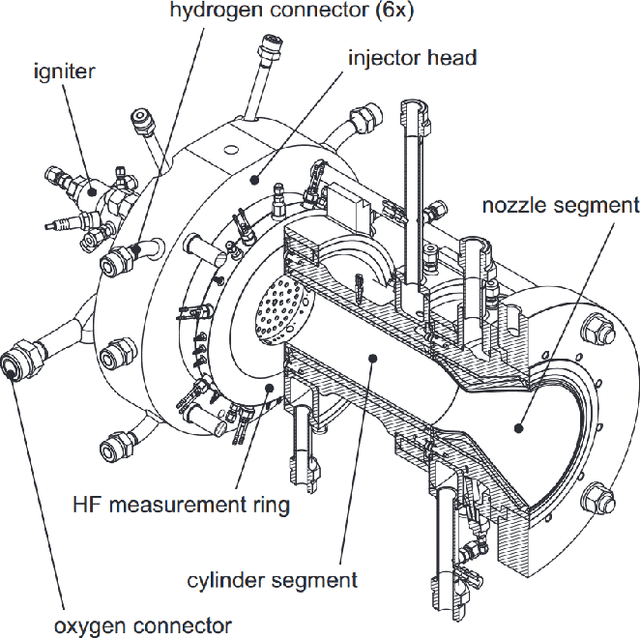
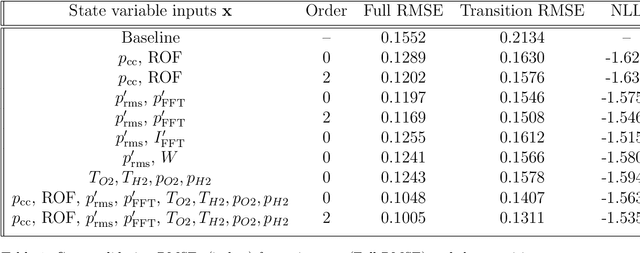
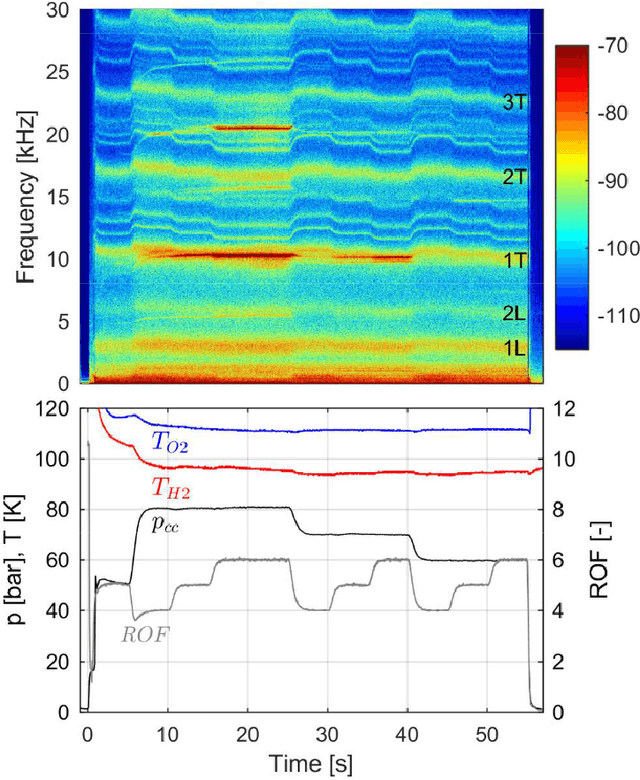

The 100 MW cryogenic liquid oxygen/hydrogen multi-injector combustor BKD operated by the DLR Institute of Space Propulsion is a research platform that allows the study of thermoacoustic instabilities under realistic conditions, representative of small upper stage rocket engines. We use data from BKD experimental campaigns in which the static chamber pressure and fuel-oxidizer ratio are varied such that the first tangential mode of the combustor is excited under some conditions. We train an autoregressive Bayesian neural network model to forecast the amplitude of the dynamic pressure time series, inputting multiple sensor measurements (injector pressure/ temperature measurements, static chamber pressure, high-frequency dynamic pressure measurements, high-frequency OH* chemiluminescence measurements) and future flow rate control signals. The Bayesian nature of our algorithms allows us to work with a dataset whose size is restricted by the expense of each experimental run, without making overconfident extrapolations. We find that the networks are able to accurately forecast the evolution of the pressure amplitude and anticipate instability events on unseen experimental runs 500 milliseconds in advance. We compare the predictive accuracy of multiple models using different combinations of sensor inputs. We find that the high-frequency dynamic pressure signal is particularly informative. We also use the technique of integrated gradients to interpret the influence of different sensor inputs on the model prediction. The negative log-likelihood of data points in the test dataset indicates that predictive uncertainties are well-characterized by our Bayesian model and simulating a sensor failure event results as expected in a dramatic increase in the epistemic component of the uncertainty.
Adaptive 3D descattering with a dynamic synthesis network
Jul 01, 2021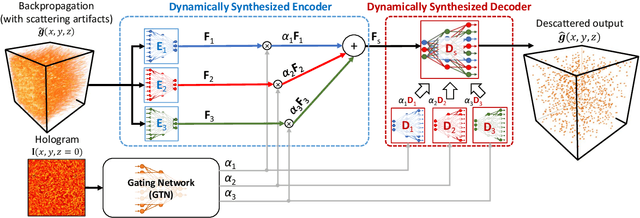
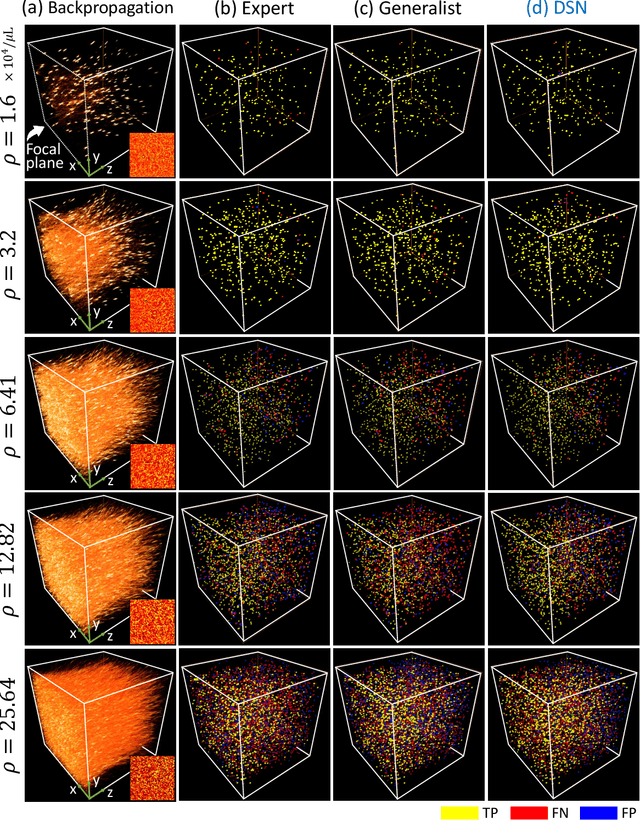
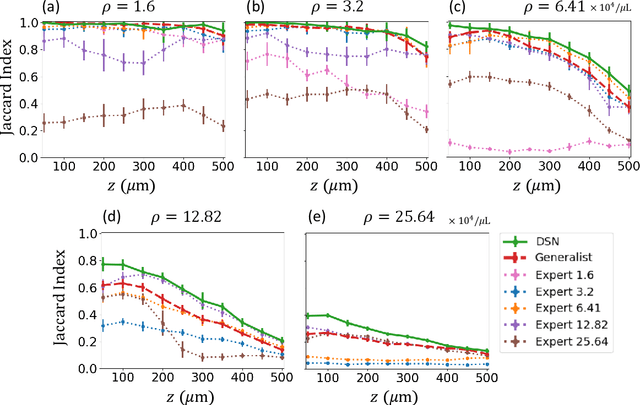
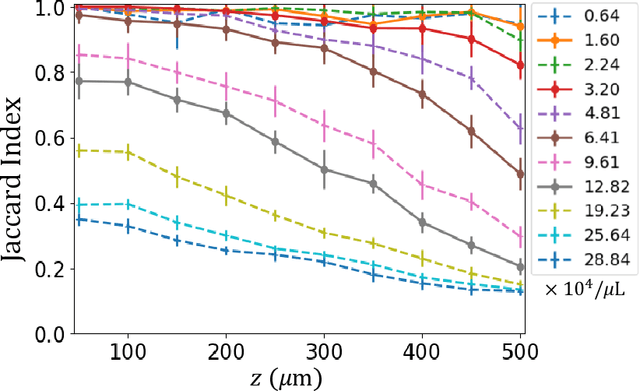
Deep learning has been broadly applied to imaging in scattering applications. A common framework is to train a "descattering" neural network for image recovery by removing scattering artifacts. To achieve the best results on a broad spectrum of scattering conditions, individual "expert" networks have to be trained for each condition. However, the performance of the expert sharply degrades when the scattering level at the testing time differs from the training. An alternative approach is to train a "generalist" network using data from a variety of scattering conditions. However, the generalist generally suffers from worse performance as compared to the expert trained for each scattering condition. Here, we develop a drastically different approach, termed dynamic synthesis network (DSN), that can dynamically adjust the model weights and adapt to different scattering conditions. The adaptability is achieved by a novel architecture that enables dynamically synthesizing a network by blending multiple experts using a gating network. Notably, our DSN adaptively removes scattering artifacts across a continuum of scattering conditions regardless of whether the condition has been used for the training, and consistently outperforms the generalist. By training the DSN entirely on a multiple-scattering simulator, we experimentally demonstrate the network's adaptability and robustness for 3D descattering in holographic 3D particle imaging. We expect the same concept can be adapted to many other imaging applications, such as denoising, and imaging through scattering media. Broadly, our dynamic synthesis framework opens up a new paradigm for designing highly adaptive deep learning and computational imaging techniques.
On the Skew-Symmetric Binary Sequences and the Merit Factor Problem
Jun 07, 2021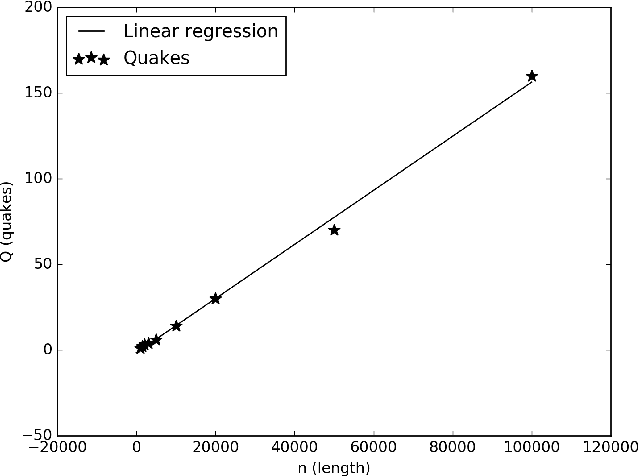
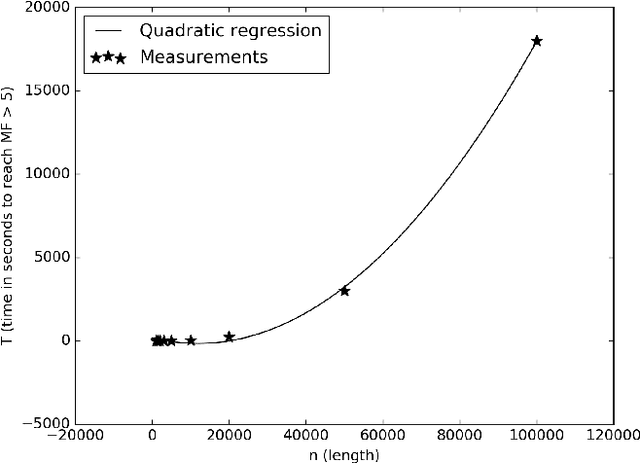
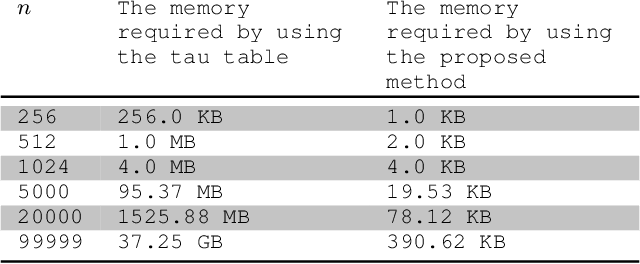
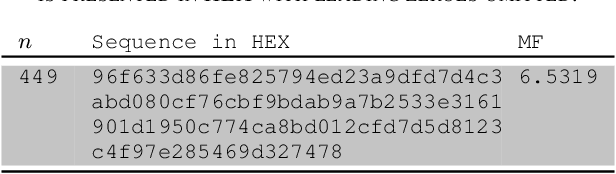
The merit factor problem is of practical importance to manifold domains, such as digital communications engineering, radars, system modulation, system testing, information theory, physics, chemistry. However, the merit factor problem is referenced as one of the most difficult optimization problems and it was further conjectured that stochastic search procedures will not yield merit factors higher than 5 for long binary sequences (sequences with lengths greater than 200). Some useful mathematical properties related to the flip operation of the skew-symmetric binary sequences are presented in this work. By exploiting those properties, the memory complexity of state-of-the-art stochastic merit factor optimization algorithms could be reduced from $O(n^2)$ to $O(n)$. As a proof of concept, a lightweight stochastic algorithm was constructed, which can optimize pseudo-randomly generated skew-symmetric binary sequences with long lengths (up to ${10}^5+1$) to skew-symmetric binary sequences with a merit factor greater than 5. An approximation of the required time is also provided. The numerical experiments suggest that the algorithm is universal and could be applied to skew-symmetric binary sequences with arbitrary lengths.