 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained $ε$-Margin Closed-Form Stabilization of Parametric Hawkes Processes
May 08, 2021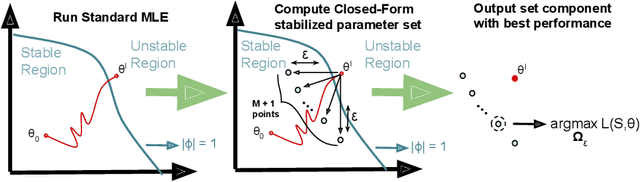
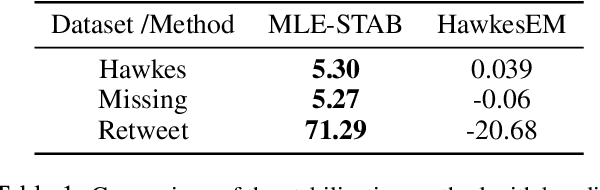
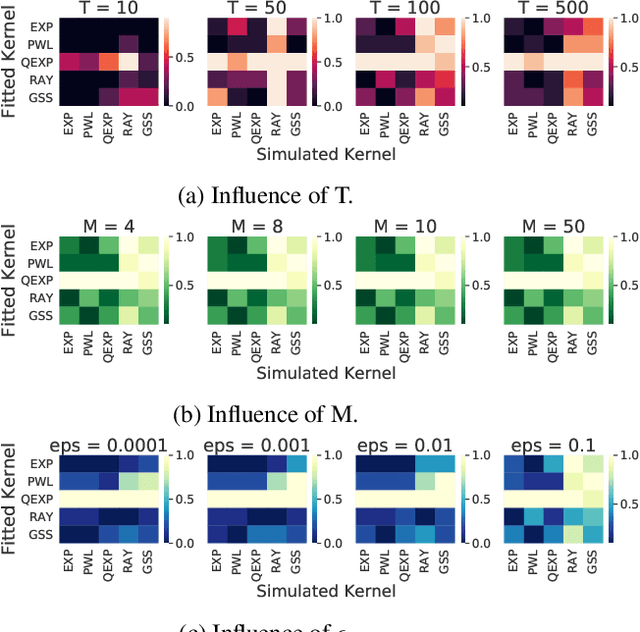

Hawkes Processes have undergone increasing popularity as default tools for modeling self- and mutually exciting interactions of discrete events in continuous-time event streams. A Maximum Likelihood Estimation (MLE) unconstrained optimization procedure over parametrically assumed forms of the triggering kernels of the corresponding intensity function are a widespread cost-effective modeling strategy, particularly suitable for data with few and/or short sequences. However, the MLE optimization lacks guarantees, except for strong assumptions on the parameters of the triggering kernels, and may lead to instability of the resulting parameters .In the present work, we show how a simple stabilization procedure improves the performance of the MLE optimization without these overly restrictive assumptions.This stabilized version of the MLE is shown to outperform traditional methods over sequences of several different lengths.
Hawkes Processes Modeling, Inference and Control: An Overview
Nov 26, 2020

Hawkes Processes are a type of point process which models self-excitement among time events. It has been used in a myriad of applications, ranging from finance and earthquakes to crime rates and social network activity analysis.Recently, a surge of different tools and algorithms have showed their way up to top-tier Machine Learning conferences. This work aims to give a broad view of the recent advances on the Hawkes Processes modeling and inference to a newcomer to the field.
Make Hawkes Processes Explainable by Decomposing Self-Triggering Kernels
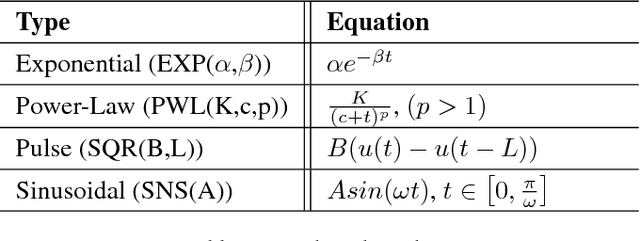
Sep 13, 2018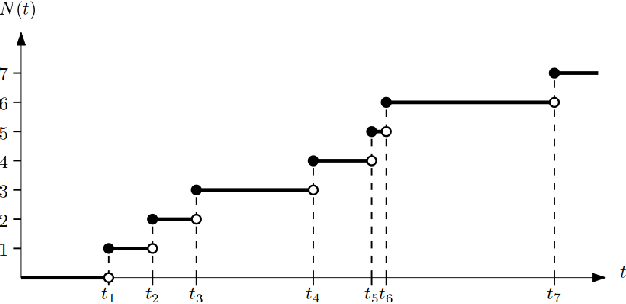
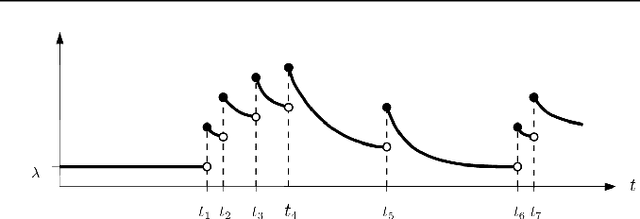
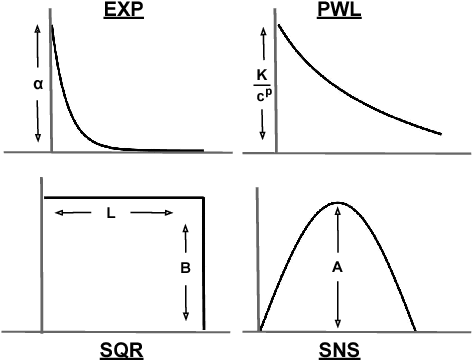
Hawkes Processes capture self-excitation and mutual-excitation between events when the arrival of an event makes future events more likely to happen. Identification of such temporal covariance can reveal the underlying structure to better predict future events. In this paper, we present a new framework to decompose discrete events with a composition of multiple self-triggering kernels. The composition scheme allows us to decompose empirical covariance densities into the sum or the product of base kernels which are easily interpretable. Here, we present the first multiplicative kernel composition methods for Hawkes Processes. We demonstrate that the new automatic kernel decomposition procedure outperforms the existing methods on the prediction of discrete events in real-world data.