 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomation for Interpretable Machine Learning Through a Comparison of Loss Functions to Regularisers
Jun 07, 2021
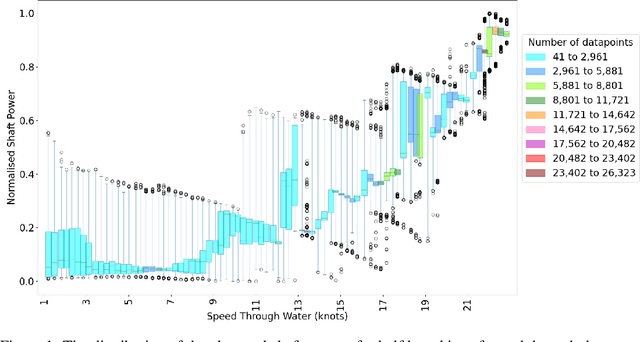
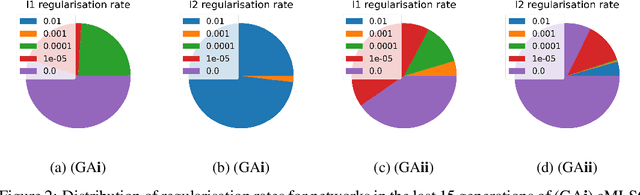
To increase the ubiquity of machine learning it needs to be automated. Automation is cost-effective as it allows experts to spend less time tuning the approach, which leads to shorter development times. However, while this automation produces highly accurate architectures, they can be uninterpretable, acting as `black-boxes' which produce low conventional errors but fail to model the underlying input-output relationships -- the ground truth. This paper explores the use of the Fit to Median Error measure in machine learning regression automation, using evolutionary computation in order to improve the approximation of the ground truth. When used alongside conventional error measures it improves interpretability by regularising learnt input-output relationships to the conditional median. It is compared to traditional regularisers to illustrate that the use of the Fit to Median Error produces regression neural networks which model more consistent input-output relationships. The problem considered is ship power prediction using a fuel-saving air lubrication system, which is highly stochastic in nature. The networks optimised for their Fit to Median Error are shown to approximate the ground truth more consistently, without sacrificing conventional Minkowski-r error values.
Towards Error Measures which Influence a Learners Inductive Bias to the Ground Truth
May 04, 2021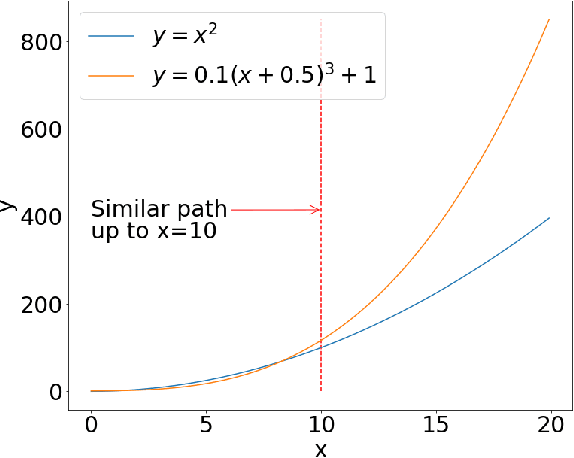
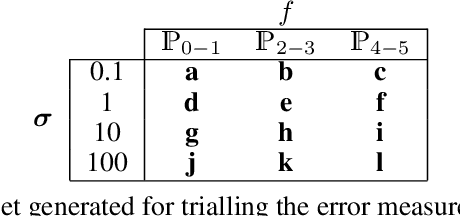
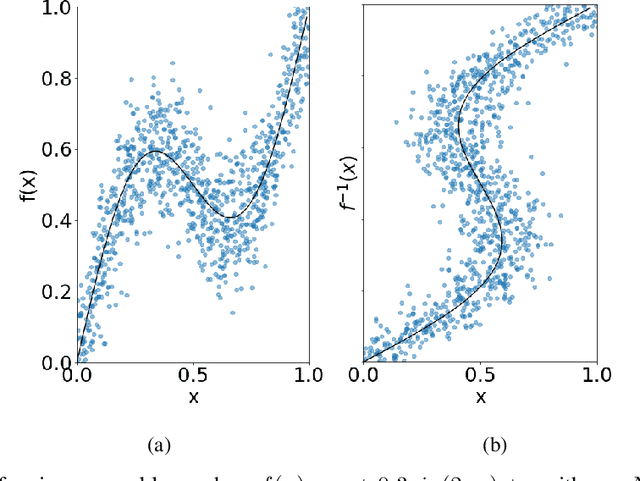
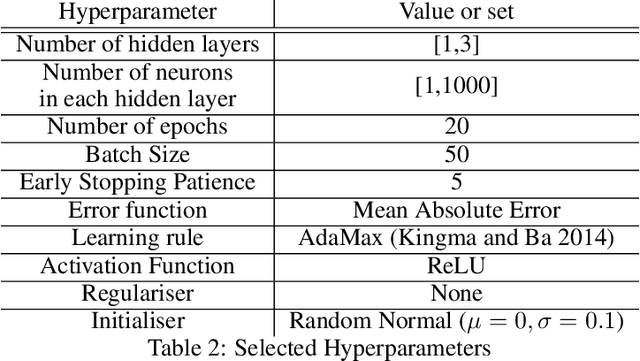
Artificial intelligence is applied in a range of sectors, and is relied upon for decisions requiring a high level of trust. For regression methods, trust is increased if they approximate the true input-output relationships and perform accurately outside the bounds of the training data. But often performance off-test-set is poor, especially when data is sparse. This is because the conditional average, which in many scenarios is a good approximation of the `ground truth', is only modelled with conventional Minkowski-r error measures when the data set adheres to restrictive assumptions, with many real data sets violating these. To combat this there are several methods that use prior knowledge to approximate the `ground truth'. However, prior knowledge is not always available, and this paper investigates how error measures affect the ability for a regression method to model the `ground truth' in these scenarios. Current error measures are shown to create an unhelpful bias and a new error measure is derived which does not exhibit this behaviour. This is tested on 36 representative data sets with different characteristics, showing that it is more consistent in determining the `ground truth' and in giving improved predictions in regions beyond the range of the training data.
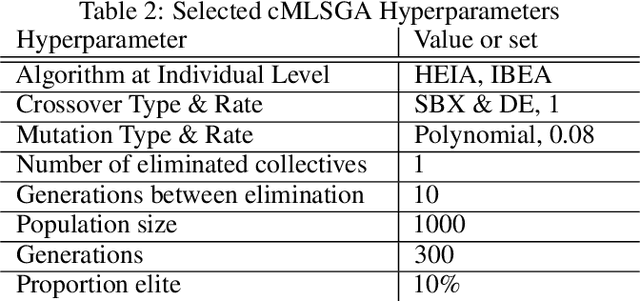
cMLSGA: A Co-Evolutionary Multi-Level Selection Genetic Algorithm for Multi-Objective Optimization
Apr 22, 2021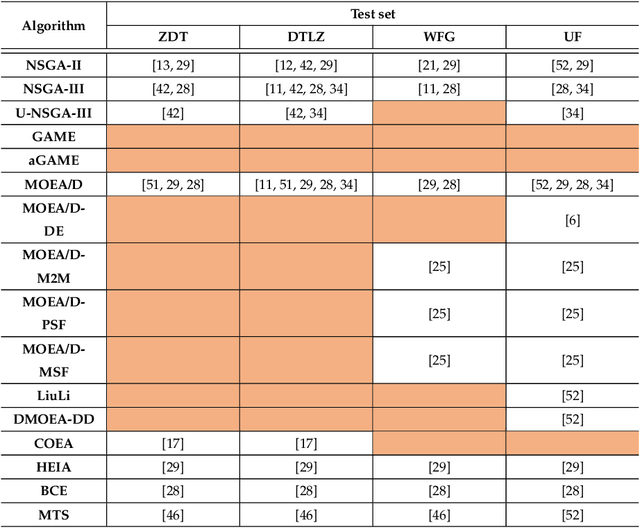
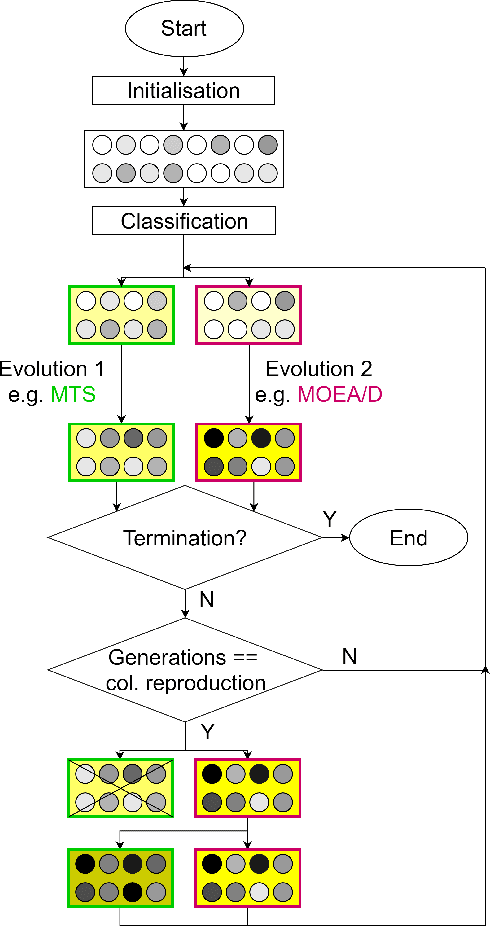
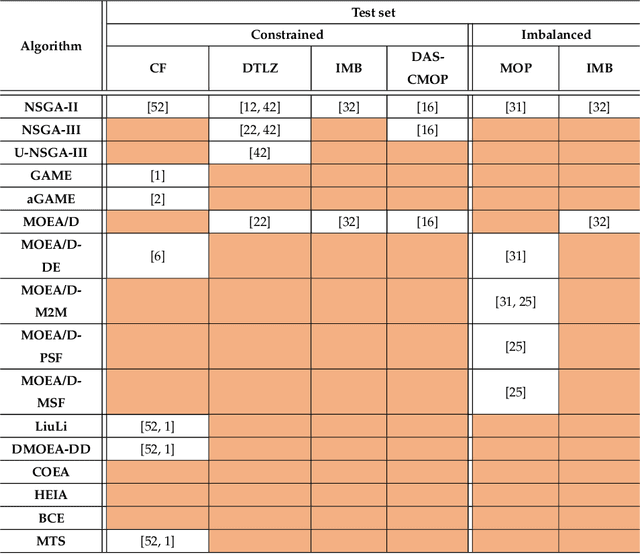
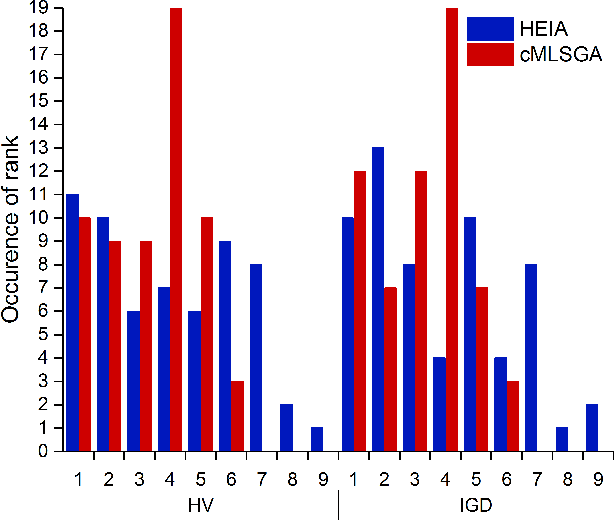
In practical optimisation the dominant characteristics of the problem are often not known prior. Therefore, there is a need to develop general solvers as it is not always possible to tailor a specialised approach to each application. The hybrid form of Multi-Level Selection Genetic Algorithm (MLSGA) already shows good performance on range of problems due to its diversity-first approach, which is rare among Evolutionary Algorithms. To increase the generality of its performance this paper proposes a distinct set of co-evolutionary mechanisms, which defines co-evolution as competition between collectives rather than individuals. This distinctive approach to co-evolutionary provides less regular communication between sub-populations and different fitness definitions between individuals and collectives. This encourages the collectives to act more independently creating a unique sub-regional search, leading to the development of co-evolutionary MLSGA (cMLSGA). To test this methodology nine genetic algorithms are selected to generate several variants of cMLSGA, which incorporates these approaches at the individual level. The new mechanisms are tested on over 100 different functions and benchmarked against the 9 state-of-the-art competitors in order to find the best general solver. The results show that the diversity of co-evolutionary approaches is more important than their individual performances. This allows the selection of two competing algorithms that improve the generality of cMLSGA, without large loss of performance on any specific problem type. When compared to the state-of-the-art, the proposed methodology is the most universal and robust, leading to an algorithm more likely to solve complex problems with limited knowledge about the search space.