 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box language model explanation by context length probing
Dec 30, 2022



The increasingly widespread adoption of large language models has highlighted the need for improving their explainability. We present context length probing, a novel explanation technique for causal language models, based on tracking the predictions of a model as a function of the length of available context, and allowing to assign differential importance scores to different contexts. The technique is model-agnostic and does not rely on access to model internals beyond computing token-level probabilities. We apply context length probing to large pre-trained language models and offer some initial analyses and insights, including the potential for studying long-range dependencies. The source code and a demo of the method are available.
Relative Positional Encoding for Transformers with Linear Complexity
Jun 10, 2021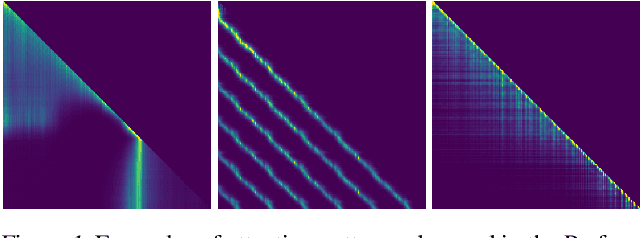
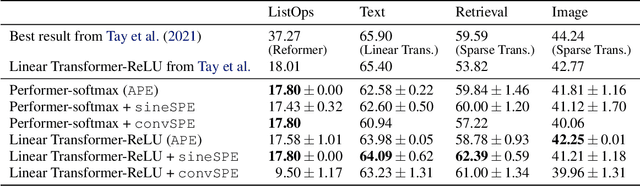

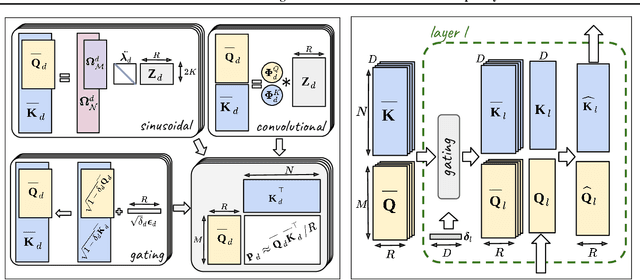
Recent advances in Transformer models allow for unprecedented sequence lengths, due to linear space and time complexity. In the meantime, relative positional encoding (RPE) was proposed as beneficial for classical Transformers and consists in exploiting lags instead of absolute positions for inference. Still, RPE is not available for the recent linear-variants of the Transformer, because it requires the explicit computation of the attention matrix, which is precisely what is avoided by such methods. In this paper, we bridge this gap and present Stochastic Positional Encoding as a way to generate PE that can be used as a replacement to the classical additive (sinusoidal) PE and provably behaves like RPE. The main theoretical contribution is to make a connection between positional encoding and cross-covariance structures of correlated Gaussian processes. We illustrate the performance of our approach on the Long-Range Arena benchmark and on music generation.
AI in the media and creative industries
May 10, 2019Thanks to the Big Data revolution and increasing computing capacities, Artificial Intelligence (AI) has made an impressive revival over the past few years and is now omnipresent in both research and industry. The creative sectors have always been early adopters of AI technologies and this continues to be the case. As a matter of fact, recent technological developments keep pushing the boundaries of intelligent systems in creative applications: the critically acclaimed movie "Sunspring", released in 2016, was entirely written by AI technology, and the first-ever Music Album, called "Hello World", produced using AI has been released this year. Simultaneously, the exploratory nature of the creative process is raising important technical challenges for AI such as the ability for AI-powered techniques to be accurate under limited data resources, as opposed to the conventional "Big Data" approach, or the ability to process, analyse and match data from multiple modalities (text, sound, images, etc.) at the same time. The purpose of this white paper is to understand future technological advances in AI and their growing impact on creative industries. This paper addresses the following questions: Where does AI operate in creative Industries? What is its operative role? How will AI transform creative industries in the next ten years? This white paper aims to provide a realistic perspective of the scope of AI actions in creative industries, proposes a vision of how this technology could contribute to research and development works in such context, and identifies research and development challenges.
Speech enhancement with variational autoencoders and alpha-stable distributions
Feb 08, 2019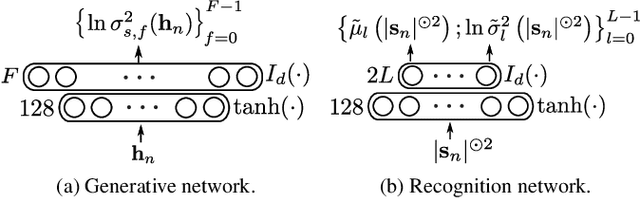
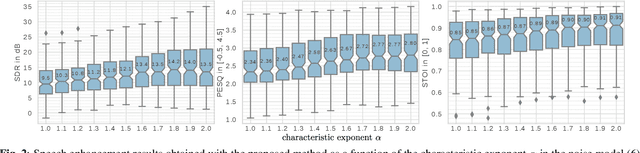
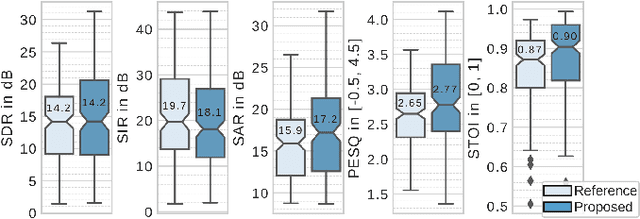
This paper focuses on single-channel semi-supervised speech enhancement. We learn a speaker-independent deep generative speech model using the framework of variational autoencoders. The noise model remains unsupervised because we do not assume prior knowledge of the noisy recording environment. In this context, our contribution is to propose a noise model based on alpha-stable distributions, instead of the more conventional Gaussian non-negative matrix factorization approach found in previous studies. We develop a Monte Carlo expectation-maximization algorithm for estimating the model parameters at test time. Experimental results show the superiority of the proposed approach both in terms of perceptual quality and intelligibility of the enhanced speech signal.
* 5 pages, 3 figures, audio examples and code available online : https://team.inria.fr/perception/research/icassp2019-asvae/. arXiv admin note: text overlap with arXiv:1811.06713
Sliced-Wasserstein Flows: Nonparametric Generative Modeling via Optimal Transport and Diffusions
Jun 21, 2018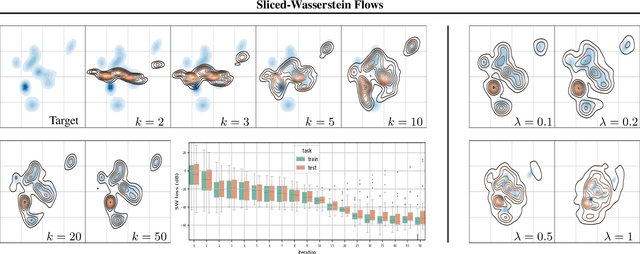
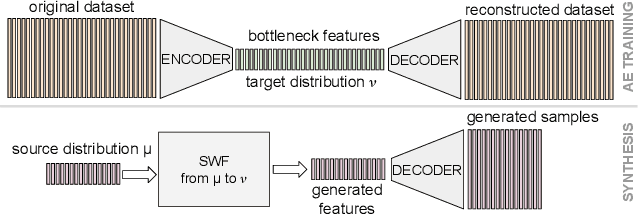


By building up on the recent theory that established the connection between implicit generative modeling and optimal transport, in this study, we propose a novel parameter-free algorithm for learning the underlying distributions of complicated datasets and sampling from them. The proposed algorithm is based on a functional optimization problem, which aims at finding a measure that is close to the data distribution as much as possible and also expressive enough for generative modeling purposes. We formulate the problem as a gradient flow in the space of probability measures. The connections between gradient flows and stochastic differential equations let us develop a computationally efficient algorithm for solving the optimization problem, where the resulting algorithm resembles the recent dynamics-based Markov Chain Monte Carlo algorithms. We provide formal theoretical analysis where we prove finite-time error guarantees for the proposed algorithm. Our experimental results support our theory and shows that our algorithm is able to capture the structure of challenging distributions.
Blind Source Separation Using Mixtures of Alpha-Stable Distributions
Feb 12, 2018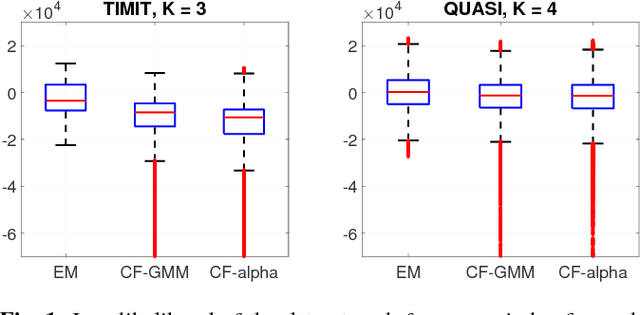
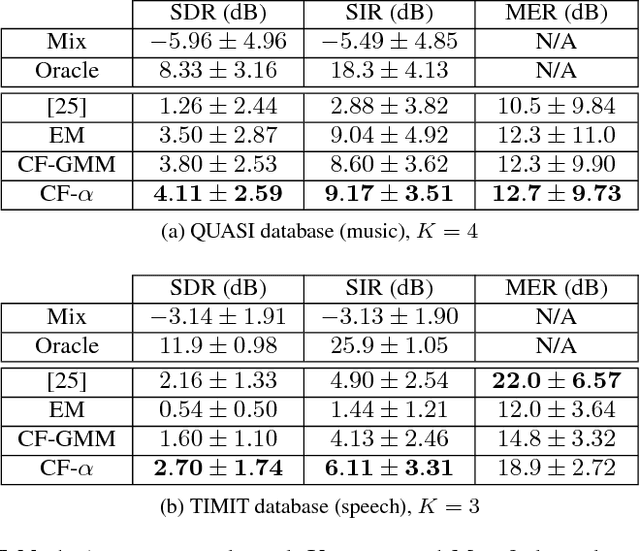
We propose a new blind source separation algorithm based on mixtures of alpha-stable distributions. Complex symmetric alpha-stable distributions have been recently showed to better model audio signals in the time-frequency domain than classical Gaussian distributions thanks to their larger dynamic range. However, inference of these models is notoriously hard to perform because their probability density functions do not have a closed-form expression in general. Here, we introduce a novel method for estimating mixture of alpha-stable distributions based on characteristic function matching. We apply this to the blind estimation of binary masks in individual frequency bands from multichannel convolutive audio mixes. We show that the proposed method yields better separation performance than Gaussian-based binary-masking methods.