 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Early Abandoning and Pruning for Elastic Distances
Feb 10, 2021
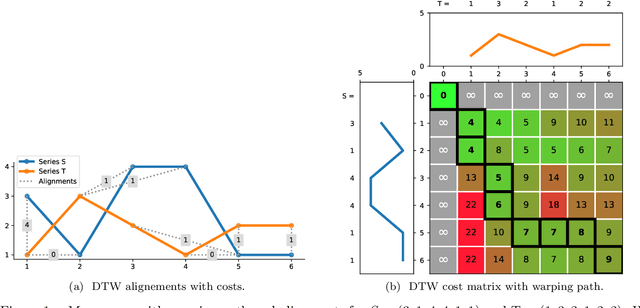
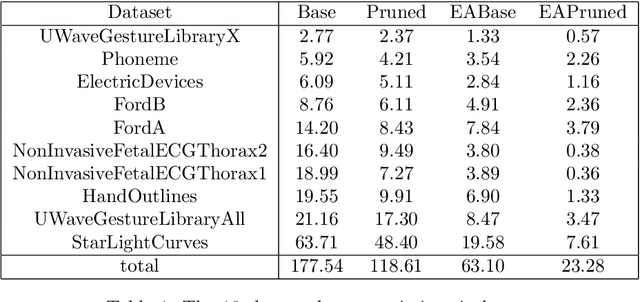
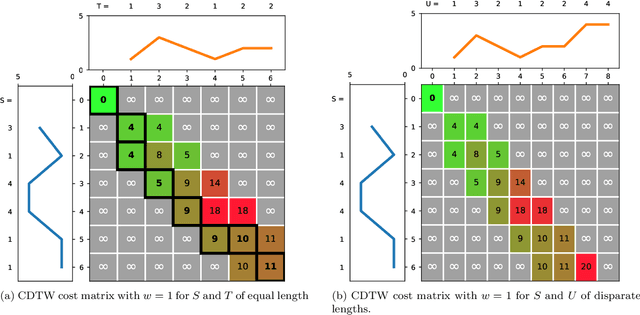
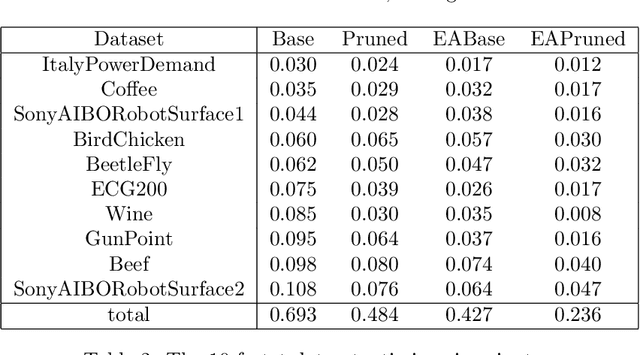
Elastic distances are key tools for time series analysis. Straightforward implementations require O(n2)space and time complexities, preventing many applications from scaling to long series. Much work hasbeen devoted in speeding up these applications, mostly with the development of lower bounds, allowing to avoid costly distance computations when a given threshold is exceeded. This threshold also allows to early abandon the computation of the distance itself. Another approach, developed for DTW, is to prune parts of the computation. All these techniques are orthogonal to each other. In this work, we develop a new generic strategy, "EAPruned", that tightly integrates pruning with early abandoning. We apply it to DTW, CDTW, WDTW, ERP, MSM and TWE, showing substantial speedup in NN1-like scenarios. Pruning also shows substantial speedup for some distances, benefiting applications such as clustering where all pairwise distances are required and hence early abandoning is not applicable. We release our implementation as part of a new C++ library for time series classification, along with easy to usePython/Numpy bindings.
Lighting Enhancement Aids Reconstruction of Colonoscopic Surfaces
Mar 18, 2021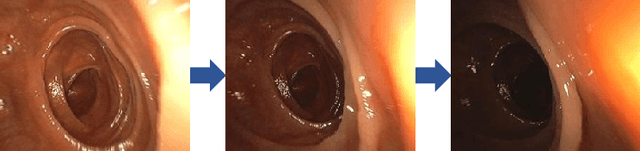
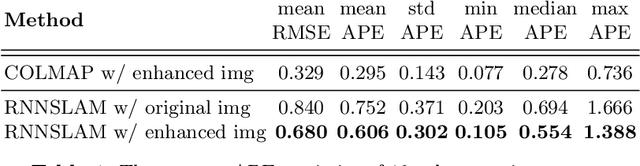

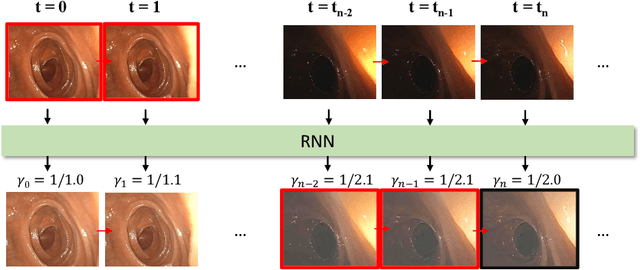
High screening coverage during colonoscopy is crucial to effectively prevent colon cancer. Previous work has allowed alerting the doctor to unsurveyed regions by reconstructing the 3D colonoscopic surface from colonoscopy videos in real-time. However, the lighting inconsistency of colonoscopy videos can cause a key component of the colonoscopic reconstruction system, the SLAM optimization, to fail. In this work we focus on the lighting problem in colonoscopy videos. To successfully improve the lighting consistency of colonoscopy videos, we have found necessary a lighting correction that adapts to the intensity distribution of recent video frames. To achieve this in real-time, we have designed and trained an RNN network. This network adapts the gamma value in a gamma-correction process. Applied in the colonoscopic surface reconstruction system, our light-weight model significantly boosts the reconstruction success rate, making a larger proportion of colonoscopy video segments reconstructable and improving the reconstruction quality of the already reconstructed segments.
Lithography Hotspot Detection via Heterogeneous Federated Learning with Local Adaptation
Jul 09, 2021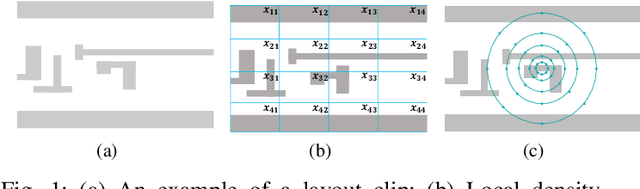
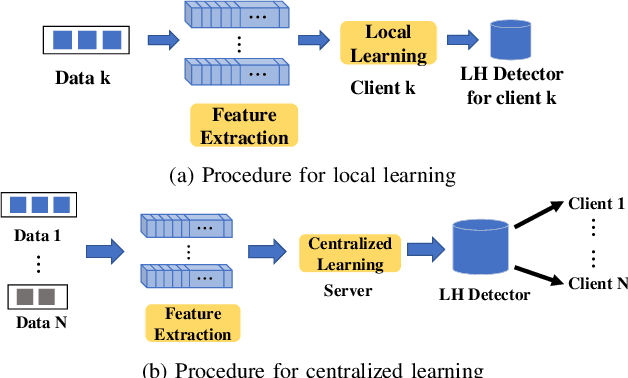
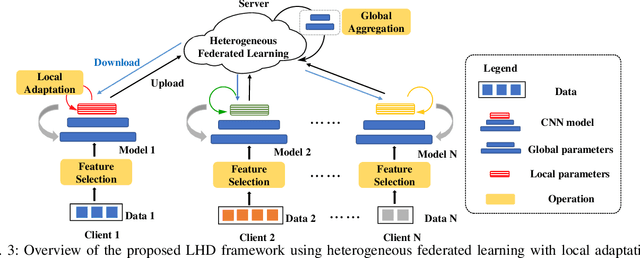
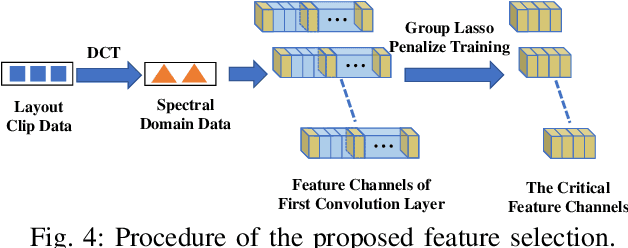
As technology scaling is approaching the physical limit, lithography hotspot detection has become an essential task in design for manufacturability. While the deployment of pattern matching or machine learning in hotspot detection can help save significant simulation time, such methods typically demand for non-trivial quality data to build the model, which most design houses are short of. Moreover, the design houses are also unwilling to directly share such data with the other houses to build a unified model, which can be ineffective for the design house with unique design patterns due to data insufficiency. On the other hand, with data homogeneity in each design house, the locally trained models can be easily over-fitted, losing generalization ability and robustness. In this paper, we propose a heterogeneous federated learning framework for lithography hotspot detection that can address the aforementioned issues. On one hand, the framework can build a more robust centralized global sub-model through heterogeneous knowledge sharing while keeping local data private. On the other hand, the global sub-model can be combined with a local sub-model to better adapt to local data heterogeneity. The experimental results show that the proposed framework can overcome the challenge of non-independent and identically distributed (non-IID) data and heterogeneous communication to achieve very high performance in comparison to other state-of-the-art methods while guaranteeing a good convergence rate in various scenarios.
Machine Learning for Real-World Evidence Analysis of COVID-19 Pharmacotherapy
Jul 19, 2021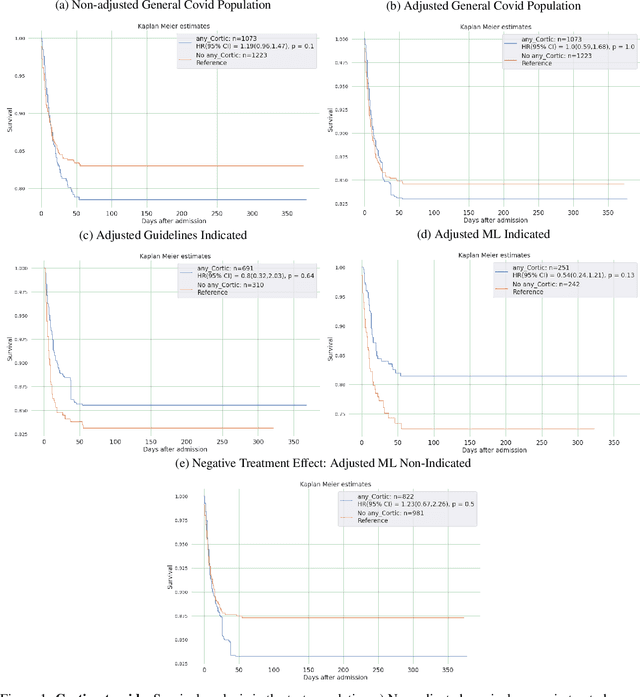
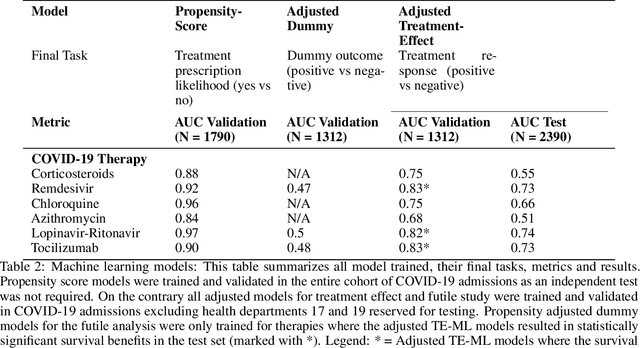
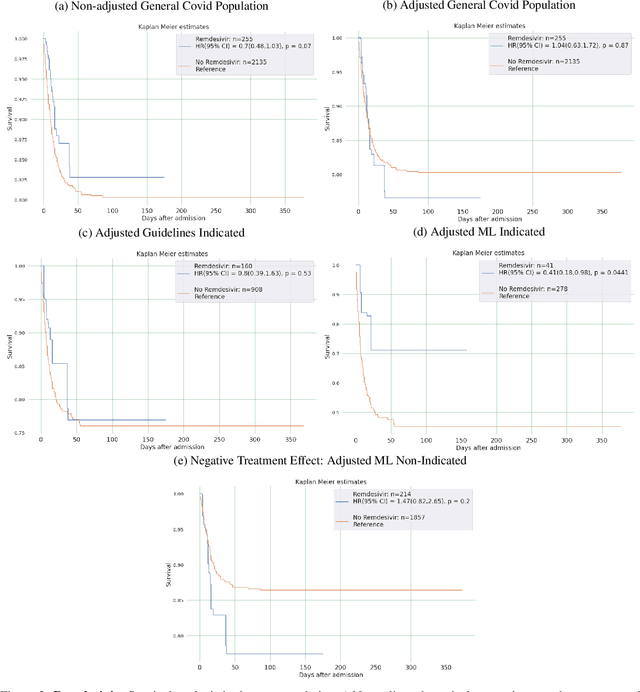
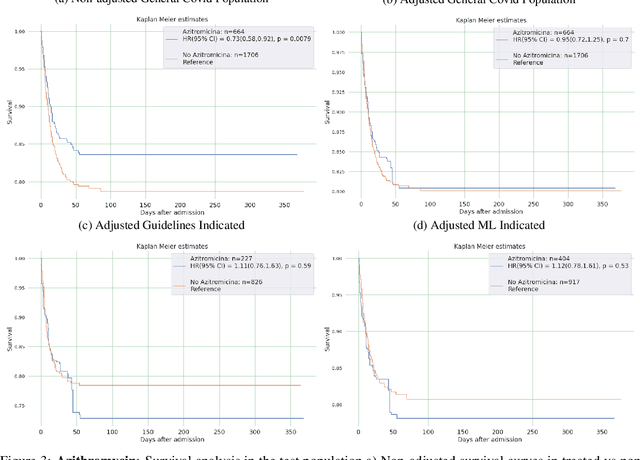
Introduction: Real-world data generated from clinical practice can be used to analyze the real-world evidence (RWE) of COVID-19 pharmacotherapy and validate the results of randomized clinical trials (RCTs). Machine learning (ML) methods are being used in RWE and are promising tools for precision-medicine. In this study, ML methods are applied to study the efficacy of therapies on COVID-19 hospital admissions in the Valencian Region in Spain. Methods: 5244 and 1312 COVID-19 hospital admissions - dated between January 2020 and January 2021 from 10 health departments, were used respectively for training and validation of separate treatment-effect models (TE-ML) for remdesivir, corticosteroids, tocilizumab, lopinavir-ritonavir, azithromycin and chloroquine/hydroxychloroquine. 2390 admissions from 2 additional health departments were reserved as an independent test to analyze retrospectively the survival benefits of therapies in the population selected by the TE-ML models using cox-proportional hazard models. TE-ML models were adjusted using treatment propensity scores to control for pre-treatment confounding variables associated to outcome and further evaluated for futility. ML architecture was based on boosted decision-trees. Results: In the populations identified by the TE-ML models, only Remdesivir and Tocilizumab were significantly associated with an increase in survival time, with hazard ratios of 0.41 (P = 0.04) and 0.21 (P = 0.001), respectively. No survival benefits from chloroquine derivatives, lopinavir-ritonavir and azithromycin were demonstrated. Tools to explain the predictions of TE-ML models are explored at patient-level as potential tools for personalized decision making and precision medicine. Conclusion: ML methods are suitable tools toward RWE analysis of COVID-19 pharmacotherapies. Results obtained reproduce published results on RWE and validate the results from RCTs.
OpReg-Boost: Learning to Accelerate Online Algorithms with Operator Regression
May 27, 2021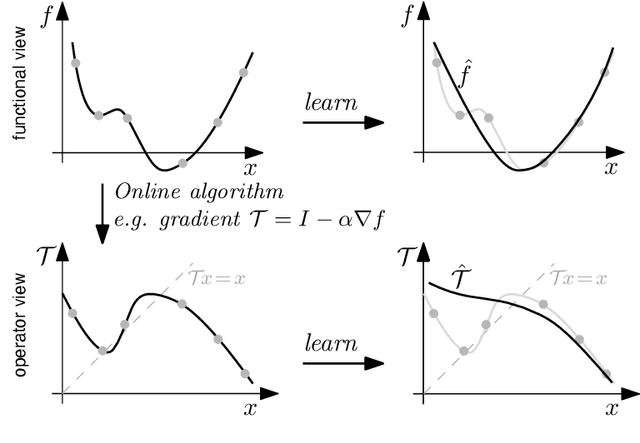
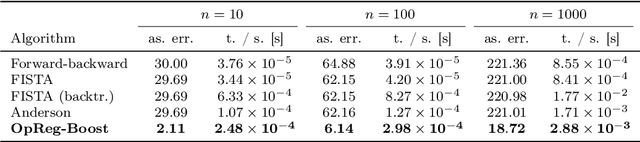
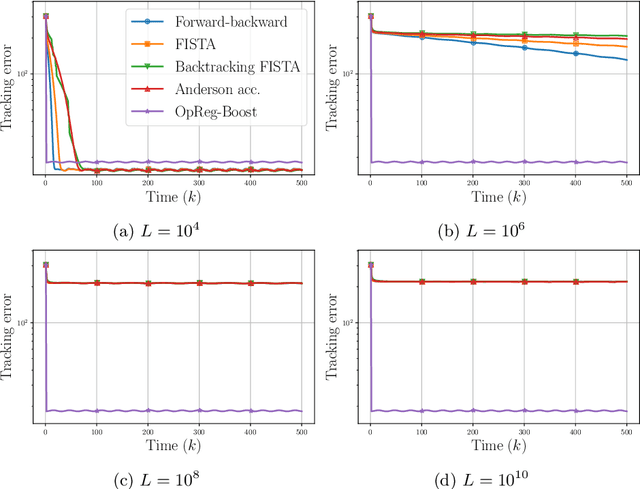
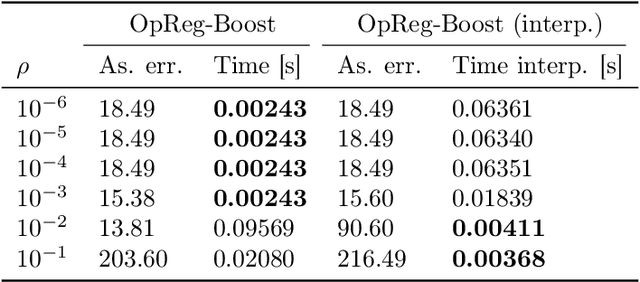
This paper presents a new regularization approach -- termed OpReg-Boost -- to boost the convergence and lessen the asymptotic error of online optimization and learning algorithms. In particular, the paper considers online algorithms for optimization problems with a time-varying (weakly) convex composite cost. For a given online algorithm, OpReg-Boost learns the closest algorithmic map that yields linear convergence; to this end, the learning procedure hinges on the concept of operator regression. We show how to formalize the operator regression problem and propose a computationally-efficient Peaceman-Rachford solver that exploits a closed-form solution of simple quadratically-constrained quadratic programs (QCQPs). Simulation results showcase the superior properties of OpReg-Boost w.r.t. the more classical forward-backward algorithm, FISTA, and Anderson acceleration, and with respect to its close relative convex-regression-boost (CvxReg-Boost) which is also novel but less performing.
Tetrad: Actively Secure 4PC for Secure Training and Inference
Jun 05, 2021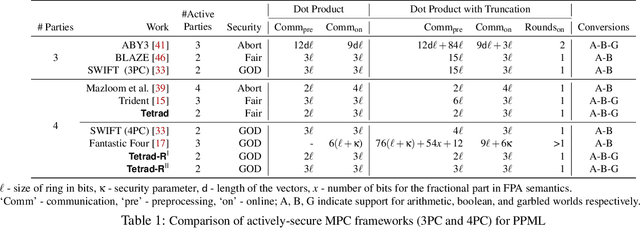



In this work, we design an efficient mixed-protocol framework, Tetrad, with applications to privacy-preserving machine learning. It is designed for the four-party setting with at most one active corruption and supports rings. Our fair multiplication protocol requires communicating only 5 ring elements improving over the state-of-the-art protocol of Trident (Chaudhari et al. NDSS'20). The technical highlights of Tetrad include efficient (a) truncation without any overhead, (b) multi-input multiplication protocols for arithmetic and boolean worlds, (c) garbled-world, tailor-made for the mixed-protocol framework, and (d) conversion mechanisms to switch between the computation styles. The fair framework is also extended to provide robustness without inflating the costs. The competence of Tetrad is tested with benchmarks for deep neural networks such as LeNet and VGG16 and support vector machines. One variant of our framework aims at minimizing the execution time, while the other focuses on the monetary cost. We observe improvements up to 6x over Trident across these parameters.
JPGNet: Joint Predictive Filtering and Generative Network for Image Inpainting
Jul 24, 2021

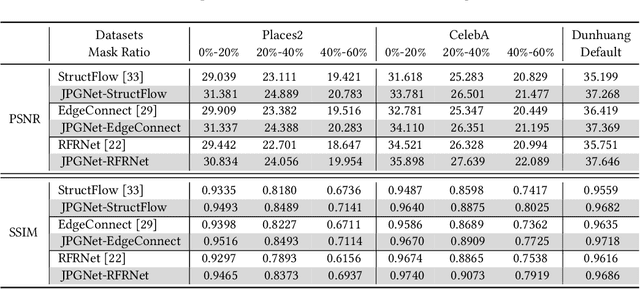
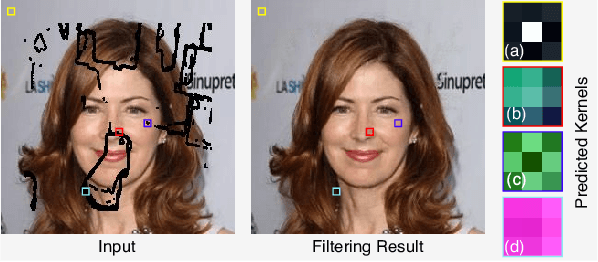
Image inpainting aims to restore the missing regions and make the recovery results identical to the originally complete image, which is different from the common generative task emphasizing the naturalness of generated images. Nevertheless, existing works usually regard it as a pure generation problem and employ cutting-edge generative techniques to address it. The generative networks fill the main missing parts with realistic contents but usually distort the local structures. In this paper, we formulate image inpainting as a mix of two problems, i.e., predictive filtering and deep generation. Predictive filtering is good at preserving local structures and removing artifacts but falls short to complete the large missing regions. The deep generative network can fill the numerous missing pixels based on the understanding of the whole scene but hardly restores the details identical to the original ones. To make use of their respective advantages, we propose the joint predictive filtering and generative network (JPGNet) that contains three branches: predictive filtering & uncertainty network (PFUNet), deep generative network, and uncertainty-aware fusion network (UAFNet). The PFUNet can adaptively predict pixel-wise kernels for filtering-based inpainting according to the input image and output an uncertainty map. This map indicates the pixels should be processed by filtering or generative networks, which is further fed to the UAFNet for a smart combination between filtering and generative results. Note that, our method as a novel framework for the image inpainting problem can benefit any existing generation-based methods. We validate our method on three public datasets, i.e., Dunhuang, Places2, and CelebA, and demonstrate that our method can enhance three state-of-the-art generative methods (i.e., StructFlow, EdgeConnect, and RFRNet) significantly with the slightly extra time cost.
Improving Automated Evaluation of Open Domain Dialog via Diverse Reference Augmentation
Jun 05, 2021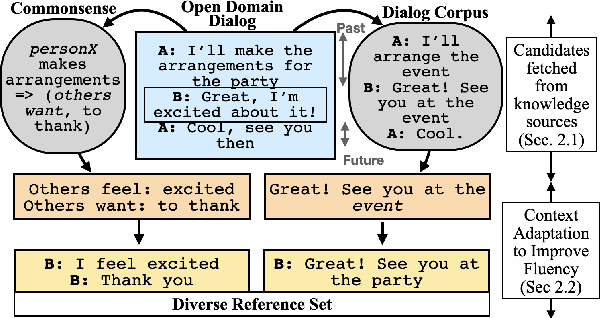



Multiple different responses are often plausible for a given open domain dialog context. Prior work has shown the importance of having multiple valid reference responses for meaningful and robust automated evaluations. In such cases, common practice has been to collect more human written references. However, such collection can be expensive, time consuming, and not easily scalable. Instead, we propose a novel technique for automatically expanding a human generated reference to a set of candidate references. We fetch plausible references from knowledge sources, and adapt them so that they are more fluent in context of the dialog instance in question. More specifically, we use (1) a commonsense knowledge base to elicit a large number of plausible reactions given the dialog history (2) relevant instances retrieved from dialog corpus, using similar past as well as future contexts. We demonstrate that our automatically expanded reference sets lead to large improvements in correlations of automated metrics with human ratings of system outputs for DailyDialog dataset.
HemCNN: Deep Learning enables decoding of fNIRS cortical signals in hand grip motor tasks
Mar 09, 2021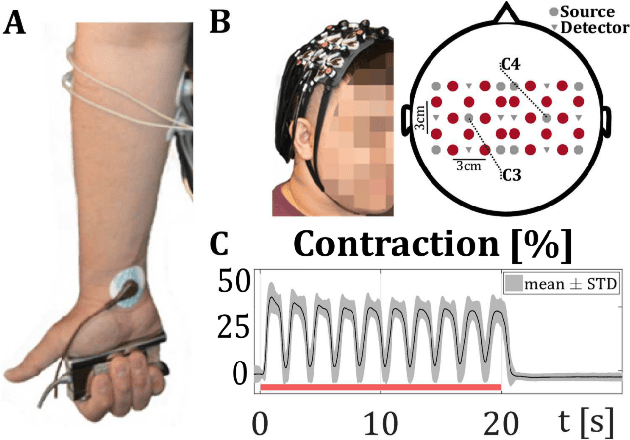
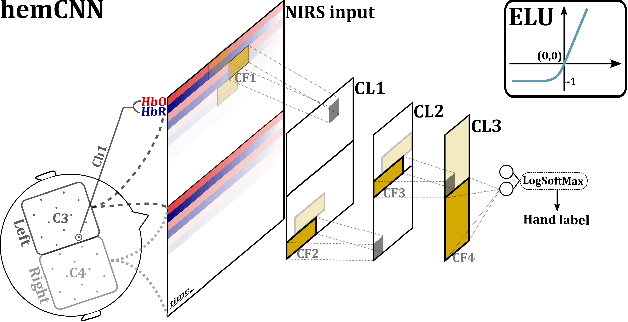
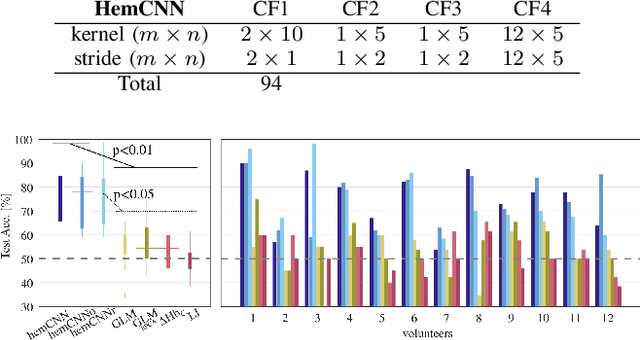
We solve the fNIRS left/right hand force decoding problem using a data-driven approach by using a convolutional neural network architecture, the HemCNN. We test HemCNN's decoding capabilities to decode in a streaming way the hand, left or right, from fNIRS data. HemCNN learned to detect which hand executed a grasp at a naturalistic hand action speed of $~1\,$Hz, outperforming standard methods. Since HemCNN does not require baseline correction and the convolution operation is invariant to time translations, our method can help to unlock fNIRS for a variety of real-time tasks. Mobile brain imaging and mobile brain machine interfacing can benefit from this to develop real-world neuroscience and practical human neural interfacing based on BOLD-like signals for the evaluation, assistance and rehabilitation of force generation, such as fusion of fNIRS with EEG signals.
Impact of data-splits on generalization: Identifying COVID-19 from cough and context
Jun 05, 2021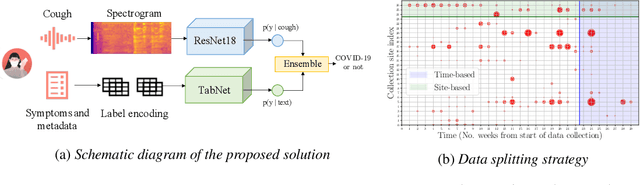

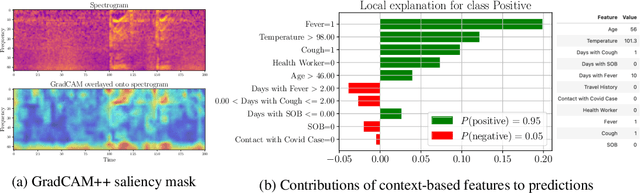
Rapidly scaling screening, testing and quarantine has shown to be an effective strategy to combat the COVID-19 pandemic. We consider the application of deep learning techniques to distinguish individuals with COVID from non-COVID by using data acquirable from a phone. Using cough and context (symptoms and meta-data) represent such a promising approach. Several independent works in this direction have shown promising results. However, none of them report performance across clinically relevant data splits. Specifically, the performance where the development and test sets are split in time (retrospective validation) and across sites (broad validation). Although there is meaningful generalization across these splits the performance significantly varies (up to 0.1 AUC score). In addition, we study the performance of symptomatic and asymptomatic individuals across these three splits. Finally, we show that our model focuses on meaningful features of the input, cough bouts for cough and relevant symptoms for context. The code and checkpoints are available at https://github.com/WadhwaniAI/cough-against-covid