 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Sample Based Explanation Methods for NLP:Efficiency, Faithfulness, and Semantic Evaluation
Jun 09, 2021

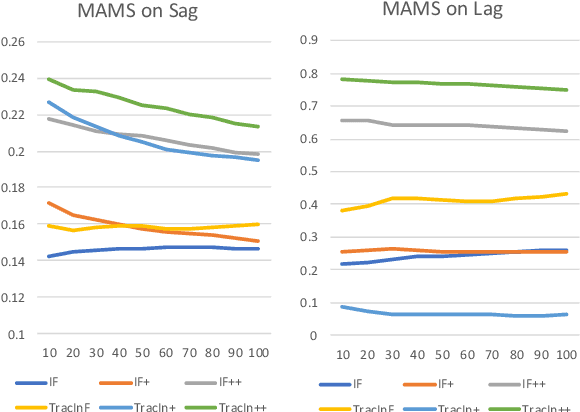

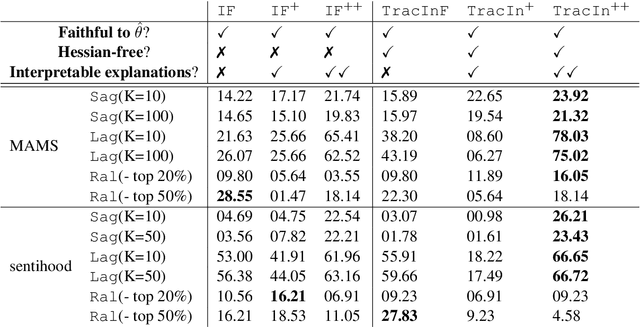
In the recent advances of natural language processing, the scale of the state-of-the-art models and datasets is usually extensive, which challenges the application of sample-based explanation methods in many aspects, such as explanation interpretability, efficiency, and faithfulness. In this work, for the first time, we can improve the interpretability of explanations by allowing arbitrary text sequences as the explanation unit. On top of this, we implement a hessian-free method with a model faithfulness guarantee. Finally, to compare our method with the others, we propose a semantic-based evaluation metric that can better align with humans' judgment of explanations than the widely adopted diagnostic or re-training measures. The empirical results on multiple real data sets demonstrate the proposed method's superior performance to popular explanation techniques such as Influence Function or TracIn on semantic evaluation.
Applying Deep Learning to Detect Traffic Accidents in Real Time Using Spatiotemporal Sequential Data
Dec 15, 2019

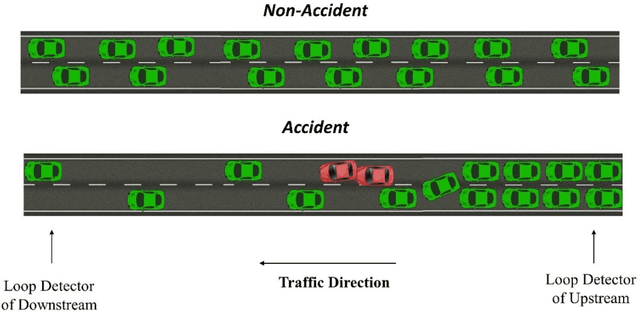
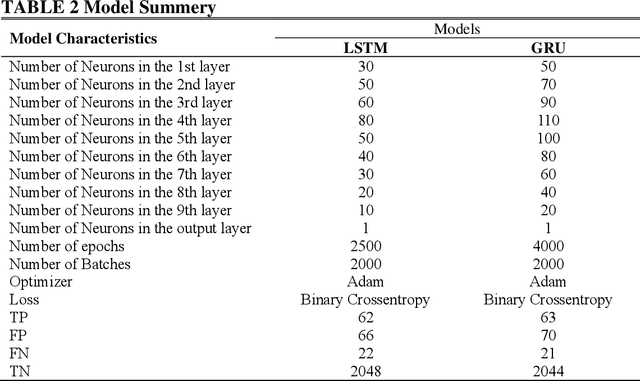
Accident detection is a vital part of traffic safety. Many road users suffer from traffic accidents, as well as their consequences such as delay, congestion, air pollution, and so on. In this study, we utilize two advanced deep learning techniques, Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs), to detect traffic accidents in Chicago. These two techniques are selected because they are known to perform well with sequential data (i.e., time series). The full dataset consists of 241 accident and 6,038 non-accident cases selected from Chicago expressway, and it includes traffic spatiotemporal data, weather condition data, and congestion status data. Moreover, because the dataset is imbalanced (i.e., the dataset contains many more non-accident cases than accident cases), Synthetic Minority Over-sampling Technique (SMOTE) is employed. Overall, the two models perform significantly well, both with an Area Under Curve (AUC) of 0.85. Nonetheless, the GRU model is observed to perform slightly better than LSTM model with respect to detection rate. The performance of both models is similar in terms of false alarm rate.
Structured Sentiment Analysis as Dependency Graph Parsing
May 30, 2021
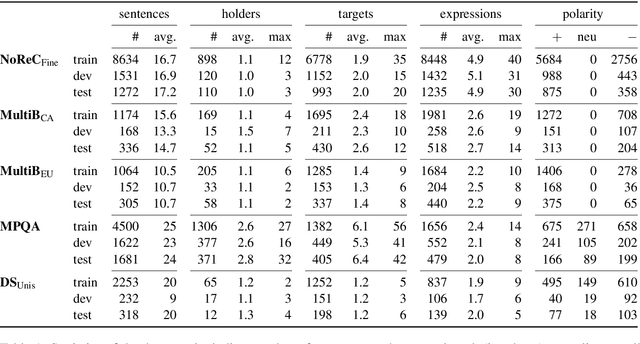
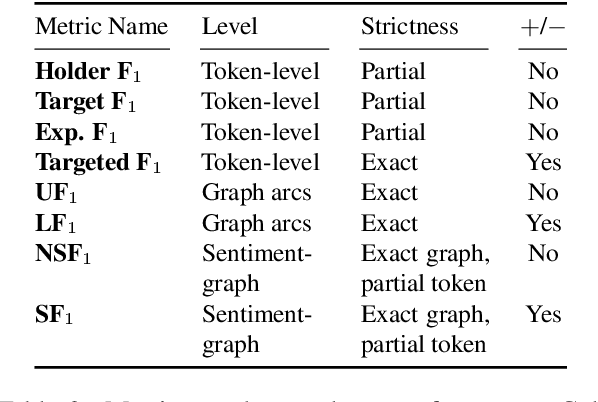
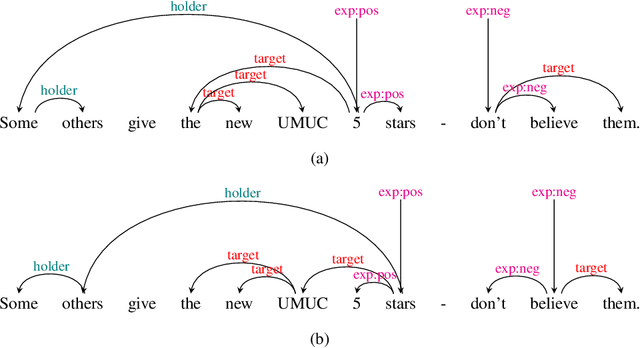
Structured sentiment analysis attempts to extract full opinion tuples from a text, but over time this task has been subdivided into smaller and smaller sub-tasks, e,g,, target extraction or targeted polarity classification. We argue that this division has become counterproductive and propose a new unified framework to remedy the situation. We cast the structured sentiment problem as dependency graph parsing, where the nodes are spans of sentiment holders, targets and expressions, and the arcs are the relations between them. We perform experiments on five datasets in four languages (English, Norwegian, Basque, and Catalan) and show that this approach leads to strong improvements over state-of-the-art baselines. Our analysis shows that refining the sentiment graphs with syntactic dependency information further improves results.
Deep Interpretable Criminal Charge Prediction and Algorithmic Bias
Jun 25, 2021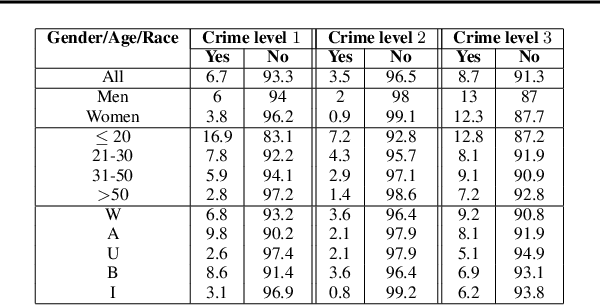
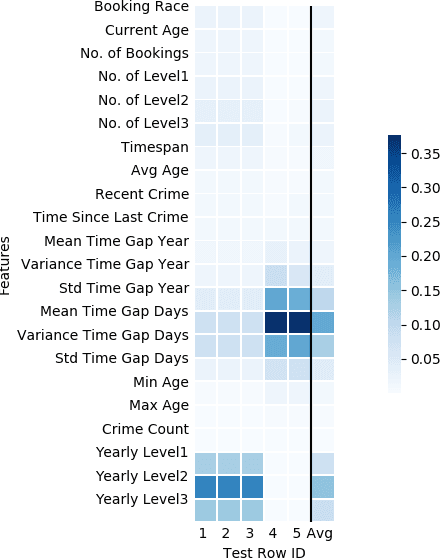
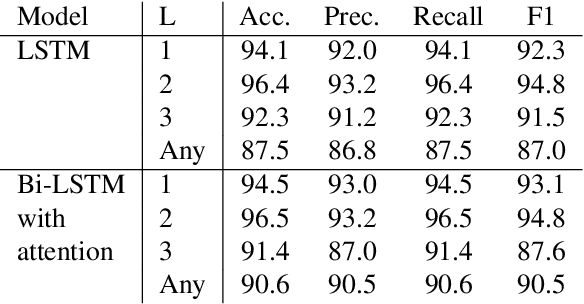
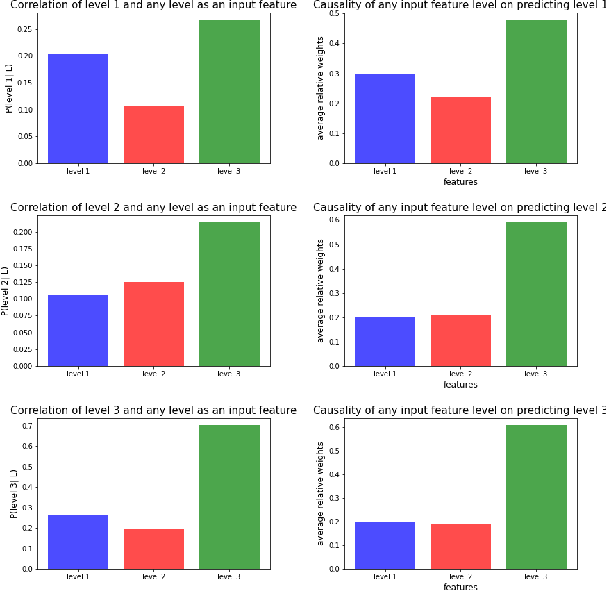
While predictive policing has become increasingly common in assisting with decisions in the criminal justice system, the use of these results is still controversial. Some software based on deep learning lacks accuracy (e.g., in F-1), and many decision processes are not transparent causing doubt about decision bias, such as perceived racial, age, and gender disparities. This paper addresses bias issues with post-hoc explanations to provide a trustable prediction of whether a person will receive future criminal charges given one's previous criminal records by learning temporal behavior patterns over twenty years. Bi-LSTM relieves the vanishing gradient problem, and attentional mechanisms allows learning and interpretation of feature importance. Our approach shows consistent and reliable prediction precision and recall on a real-life dataset. Our analysis of the importance of each input feature shows the critical causal impact on decision-making, suggesting that criminal histories are statistically significant factors, while identifiers, such as race, gender, and age, are not. Finally, our algorithm indicates that a suspect tends to gradually rather than suddenly increase crime severity level over time.
A Novel Deep Reinforcement Learning Based Stock Direction Prediction using Knowledge Graph and Community Aware Sentiments
Jul 02, 2021

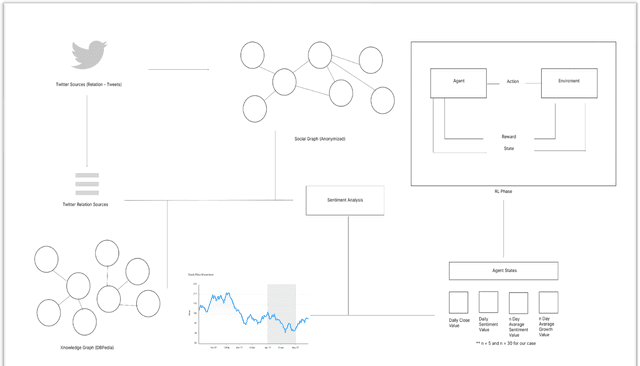
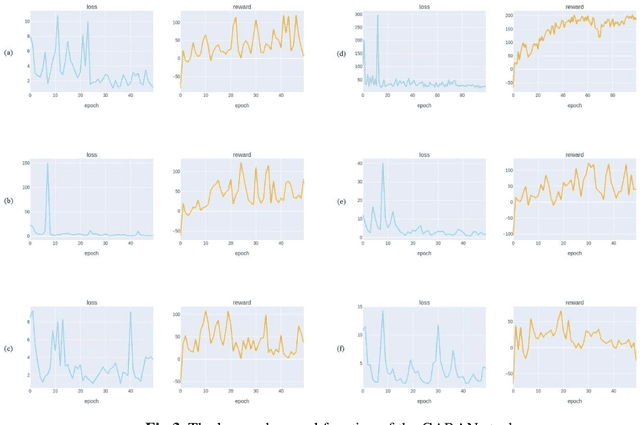
Stock market prediction has been an important topic for investors, researchers, and analysts. Because it is affected by too many factors, stock market prediction is a difficult task to handle. In this study, we propose a novel method that is based on deep reinforcement learning methodologies for the direction prediction of stocks using sentiments of community and knowledge graph. For this purpose, we firstly construct a social knowledge graph of users by analyzing relations between connections. After that, time series analysis of related stock and sentiment analysis is blended with deep reinforcement methodology. Turkish version of Bidirectional Encoder Representations from Transformers (BerTurk) is employed to analyze the sentiments of the users while deep Q-learning methodology is used for the deep reinforcement learning side of the proposed model to construct the deep Q network. In order to demonstrate the effectiveness of the proposed model, Garanti Bank (GARAN), Akbank (AKBNK), T\"urkiye \.I\c{s} Bankas{\i} (ISCTR) stocks in Istanbul Stock Exchange are used as a case study. Experiment results show that the proposed novel model achieves remarkable results for stock market prediction task.
To Schedule or not to Schedule: Extracting Task Specific Temporal Entities and Associated Negation Constraints
Nov 15, 2020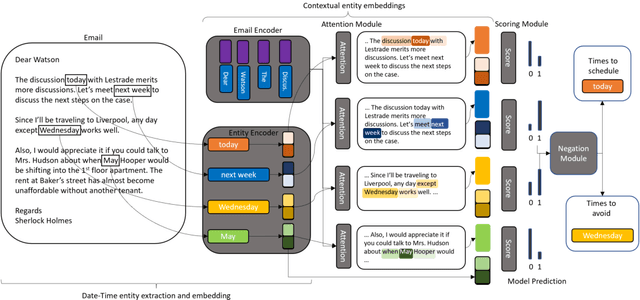
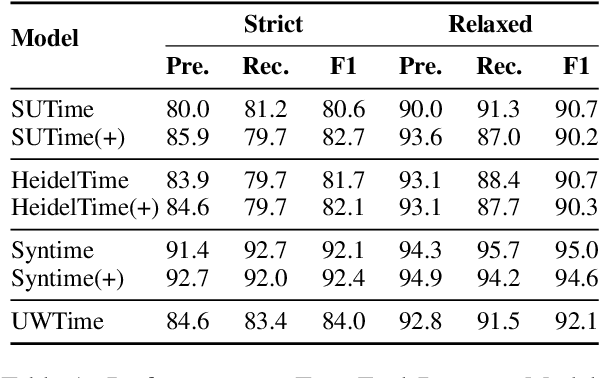
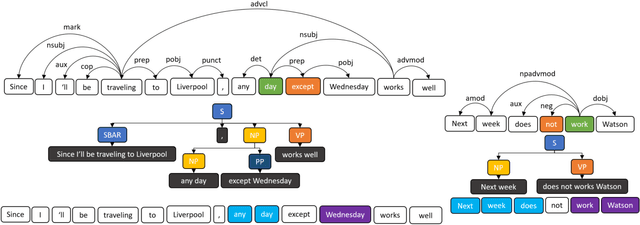
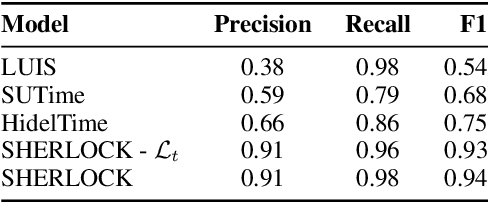
State of the art research for date-time entity extraction from text is task agnostic. Consequently, while the methods proposed in literature perform well for generic date-time extraction from texts, they don't fare as well on task specific date-time entity extraction where only a subset of the date-time entities present in the text are pertinent to solving the task. Furthermore, some tasks require identifying negation constraints associated with the date-time entities to correctly reason over time. We showcase a novel model for extracting task-specific date-time entities along with their negation constraints. We show the efficacy of our method on the task of date-time understanding in the context of scheduling meetings for an email-based digital AI scheduling assistant. Our method achieves an absolute gain of 19\% f-score points compared to baseline methods in detecting the date-time entities relevant to scheduling meetings and a 4\% improvement over baseline methods for detecting negation constraints over date-time entities.
Fusing RGBD Tracking and Segmentation Tree Sampling for Multi-Hypothesis Volumetric Segmentation
Apr 01, 2021
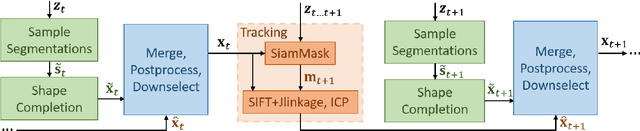


Despite rapid progress in scene segmentation in recent years, 3D segmentation methods are still limited when there is severe occlusion. The key challenge is estimating the segment boundaries of (partially) occluded objects, which are inherently ambiguous when considering only a single frame. In this work, we propose Multihypothesis Segmentation Tracking (MST), a novel method for volumetric segmentation in changing scenes, which allows scene ambiguity to be tracked and our estimates to be adjusted over time as we interact with the scene. Two main innovations allow us to tackle this difficult problem: 1) A novel way to sample possible segmentations from a segmentation tree; and 2) A novel approach to fusing tracking results with multiple segmentation estimates. These methods allow MST to track the segmentation state over time and incorporate new information, such as new objects being revealed. We evaluate our method on several cluttered tabletop environments in simulation and reality. Our results show that MST outperforms baselines in all tested scenes.
Layer Folding: Neural Network Depth Reduction using Activation Linearization
Jun 17, 2021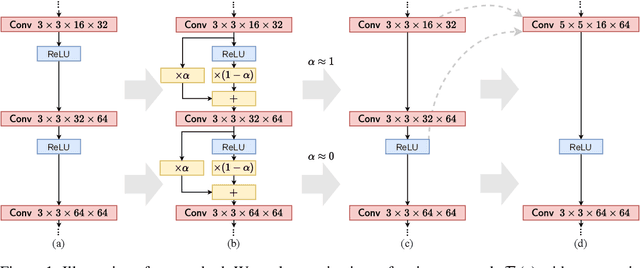

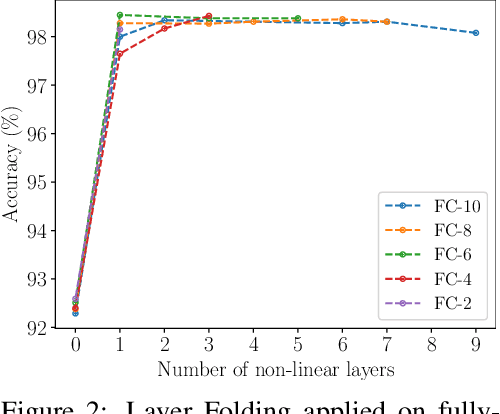

Despite the increasing prevalence of deep neural networks, their applicability in resource-constrained devices is limited due to their computational load. While modern devices exhibit a high level of parallelism, real-time latency is still highly dependent on networks' depth. Although recent works show that below a certain depth, the width of shallower networks must grow exponentially, we presume that neural networks typically exceed this minimal depth to accelerate convergence and incrementally increase accuracy. This motivates us to transform pre-trained deep networks that already exploit such advantages into shallower forms. We propose a method that learns whether non-linear activations can be removed, allowing to fold consecutive linear layers into one. We apply our method to networks pre-trained on CIFAR-10 and CIFAR-100 and find that they can all be transformed into shallower forms that share a similar depth. Finally, we use our method to provide more efficient alternatives to MobileNetV2 and EfficientNet-Lite architectures on the ImageNet classification task.
Decentralized, Hybrid MAC Design with Reduced State Information Exchange for Low-Delay IoT Applications
May 24, 2021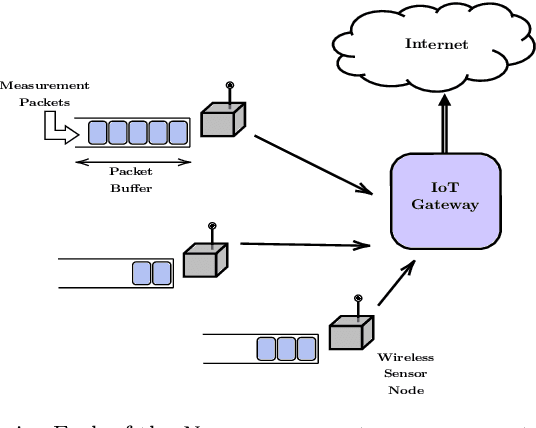

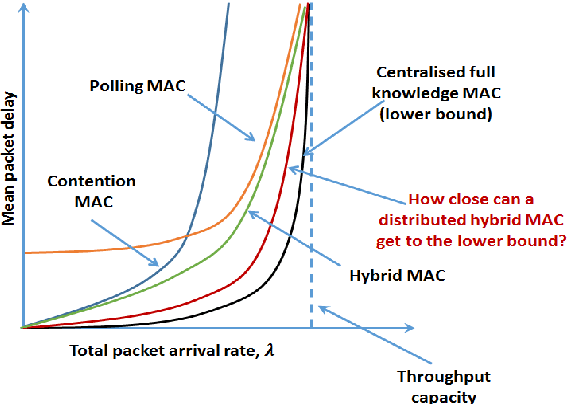

We consider a system of several collocated nodes sharing a time slotted wireless channel, and seek a MAC that (i) provides low mean delay, (ii) has distributed control (i.e., there is no central scheduler), and (iii) does not require explicit exchange of state information or control signals. The design of such MAC protocols must keep in mind the need for contention access at light traffic, and scheduled access in heavy traffic, leading to the long-standing interest in hybrid, adaptive MACs. We first propose EZMAC, a simple extension of an existing decentralized, hybrid MAC called ZMAC. Next, motivated by our results on delay and throughput optimality in partially observed, constrained queuing networks, we develop another decentralized MAC protocol that we term QZMAC. A method to improve the short-term fairness of QZMAC is proposed and analysed, and the resulting modified algorithm is shown to possess better fairness properties than QZMAC. The theory developed to reduce delay is also shown to work %with different traffic types (batch arrivals, for example) and even in the presence of transmission errors and fast fading. Extensions to handle time critical traffic (alarms, for example) and hidden nodes are also discussed. Practical implementation issues, such as handling Clear Channel Assessment (CCA) errors, are outlined. We implement and demonstrate the performance of QZMAC on a test bed consisting of CC2420 based Crossbow telosB motes, running the 6TiSCH communication stack on the Contiki operating system over the 2.4GHz ISM band. Finally, using simulations, we show that both protocols achieve mean delays much lower than those achieved by ZMAC, and QZMAC provides mean delays very close to the minimum achievable in this setting, i.e., that of the centralized complete knowledge scheduler.
Online Learning Probabilistic Event Calculus Theories in Answer Set Programming
Mar 31, 2021


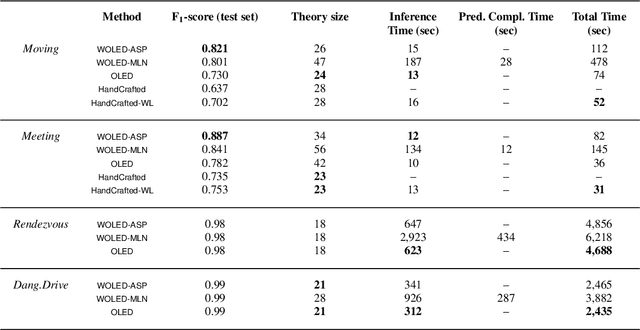
Complex Event Recognition (CER) systems detect event occurrences in streaming time-stamped input using predefined event patterns. Logic-based approaches are of special interest in CER, since, via Statistical Relational AI, they combine uncertainty-resilient reasoning with time and change, with machine learning, thus alleviating the cost of manual event pattern authoring. We present a system based on Answer Set Programming (ASP), capable of probabilistic reasoning with complex event patterns in the form of weighted rules in the Event Calculus, whose structure and weights are learnt online. We compare our ASP-based implementation with a Markov Logic-based one and with a number of state-of-the-art batch learning algorithms on CER datasets for activity recognition, maritime surveillance and fleet management. Our results demonstrate the superiority of our novel approach, both in terms of efficiency and predictive performance. This paper is under consideration for publication in Theory and Practice of Logic Programming (TPLP).