 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeShift: Unsupervised Gaze Estimation and Dataset for VR
Mar 08, 2026Gaze estimation is instrumental in modern virtual reality (VR) systems. Despite significant progress in remote-camera gaze estimation, VR gaze research remains constrained by data scarcity - particularly the lack of large-scale, accurately labeled datasets captured with the off-axis camera configurations typical of modern headsets. Gaze annotation is difficult since fixation on intended targets cannot be guaranteed. To address these challenges, we introduce VRGaze - the first large-scale off-axis gaze estimation dataset for VR - comprising 2.1 million near-eye infrared images collected from 68 participants. We further propose GazeShift, an attention-guided unsupervised framework for learning gaze representations without labeled data. Unlike prior redirection-based methods that rely on multi-view or 3D geometry, GazeShift is tailored to near-eye infrared imagery, achieving effective gaze-appearance disentanglement in a compact, real-time model. GazeShift embeddings can be optionally adapted to individual users via lightweight few-shot calibration, achieving a 1.84-degree mean error on VRGaze. On the remote-camera MPIIGaze dataset, the model achieves a 7.15-degree person-agnostic error, doing so with 10x fewer parameters and 35x fewer FLOPs than baseline methods. Deployed natively on a VR headset GPU, inference takes only 5 ms. Combined with demonstrated robustness to illumination changes, these results highlight GazeShift as a label-efficient, real-time solution for VR gaze tracking. Project code and the VRGaze dataset are released at https://github.com/gazeshift3/gazeshift.
Layer Folding: Neural Network Depth Reduction using Activation Linearization
Jun 17, 2021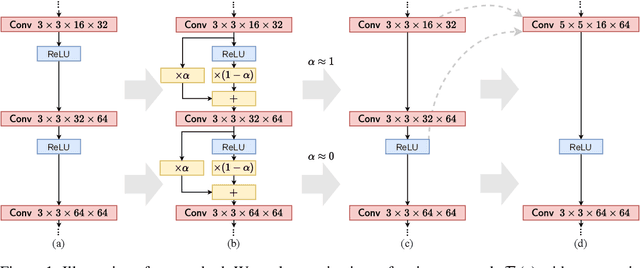

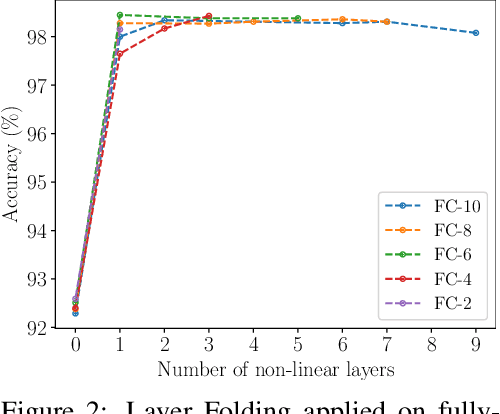

Despite the increasing prevalence of deep neural networks, their applicability in resource-constrained devices is limited due to their computational load. While modern devices exhibit a high level of parallelism, real-time latency is still highly dependent on networks' depth. Although recent works show that below a certain depth, the width of shallower networks must grow exponentially, we presume that neural networks typically exceed this minimal depth to accelerate convergence and incrementally increase accuracy. This motivates us to transform pre-trained deep networks that already exploit such advantages into shallower forms. We propose a method that learns whether non-linear activations can be removed, allowing to fold consecutive linear layers into one. We apply our method to networks pre-trained on CIFAR-10 and CIFAR-100 and find that they can all be transformed into shallower forms that share a similar depth. Finally, we use our method to provide more efficient alternatives to MobileNetV2 and EfficientNet-Lite architectures on the ImageNet classification task.