 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Meta-learning PINN loss functions
Jul 12, 2021
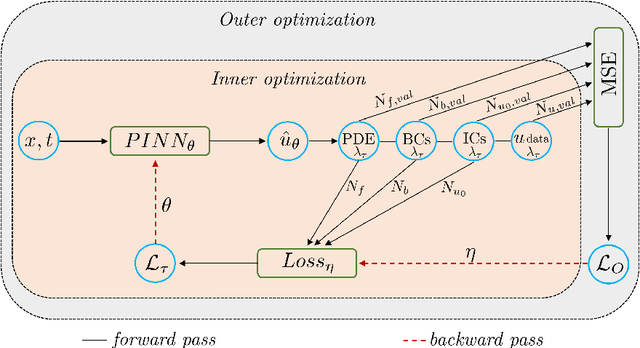

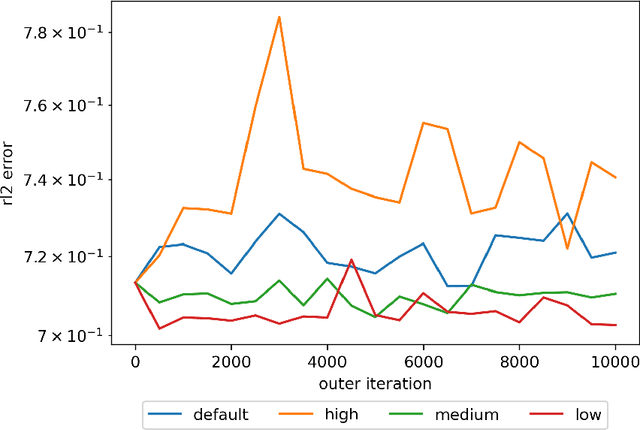
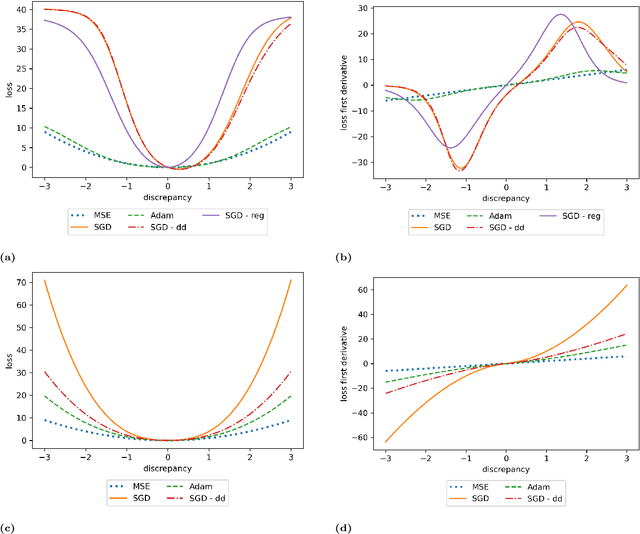
We propose a meta-learning technique for offline discovery of physics-informed neural network (PINN) loss functions. We extend earlier works on meta-learning, and develop a gradient-based meta-learning algorithm for addressing diverse task distributions based on parametrized partial differential equations (PDEs) that are solved with PINNs. Furthermore, based on new theory we identify two desirable properties of meta-learned losses in PINN problems, which we enforce by proposing a new regularization method or using a specific parametrization of the loss function. In the computational examples, the meta-learned losses are employed at test time for addressing regression and PDE task distributions. Our results indicate that significant performance improvement can be achieved by using a shared-among-tasks offline-learned loss function even for out-of-distribution meta-testing. In this case, we solve for test tasks that do not belong to the task distribution used in meta-training, and we also employ PINN architectures that are different from the PINN architecture used in meta-training. To better understand the capabilities and limitations of the proposed method, we consider various parametrizations of the loss function and describe different algorithm design options and how they may affect meta-learning performance.
Recent advances in Bayesian optimization with applications to parameter reconstruction in optical nano-metrology
Jul 12, 2021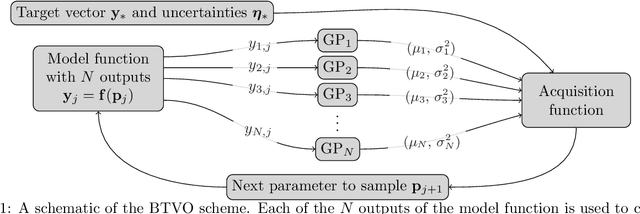
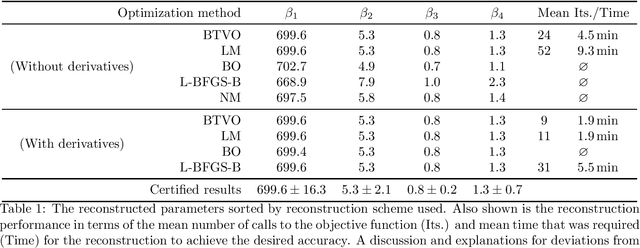
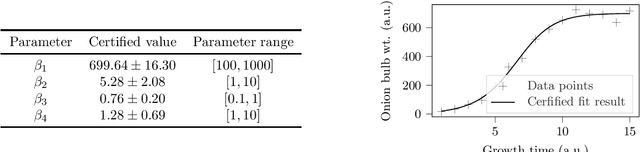
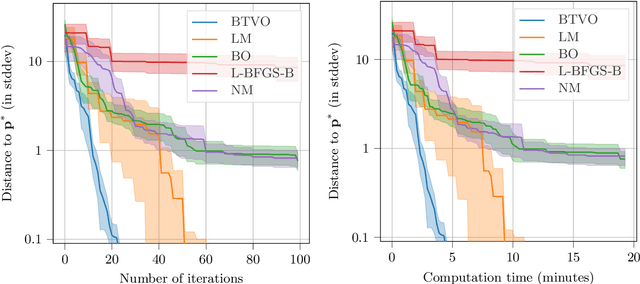
Parameter reconstruction is a common problem in optical nano metrology. It generally involves a set of measurements, to which one attempts to fit a numerical model of the measurement process. The model evaluation typically involves to solve Maxwell's equations and is thus time consuming. This makes the reconstruction computationally demanding. Several methods exist for fitting the model to the measurements. On the one hand, Bayesian optimization methods for expensive black-box optimization enable an efficient reconstruction by training a machine learning model of the squared sum of deviations. On the other hand, curve fitting algorithms, such as the Levenberg-Marquardt method, take the deviations between all model outputs and corresponding measurement values into account which enables a fast local convergence. In this paper we present a Bayesian Target Vector Optimization scheme which combines these two approaches. We compare the performance of the presented method against a standard Levenberg-Marquardt-like algorithm, a conventional Bayesian optimization scheme, and the L-BFGS-B and Nelder-Mead simplex algorithms. As a stand-in for problems from nano metrology, we employ a non-linear least-square problem from the NIST Standard Reference Database. We find that the presented method generally uses fewer calls of the model function than any of the competing schemes to achieve similar reconstruction performance.
* Proceedings article, SPIE conference "Modeling Aspects in Optical Metrology VIII"
Is It Time to Redefine the Classification Task for Deep Neural Networks?
Oct 11, 2020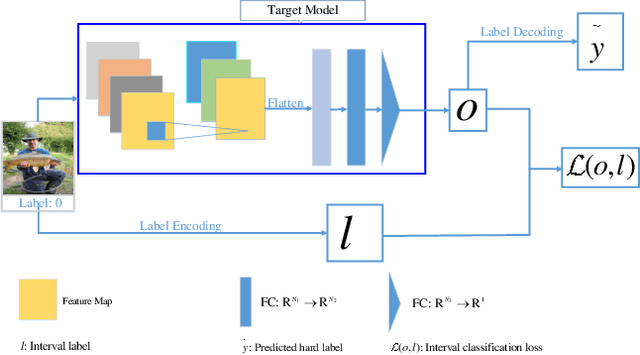

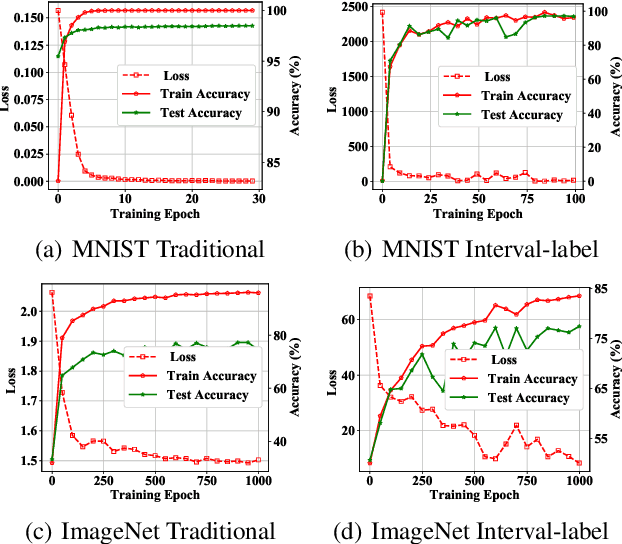

Deep neural networks (DNNs) is demonstrated to be vulnerable to the adversarial example, which is generated by adding small adversarial perturbation into the original legitimate example to cause the wrong outputs of DNNs. Nowadays, most works focus on the robustness of the deep model, while few works pay attention to the robustness of the learning task itself defined on DNNs. So we redefine this issue as the robustness of deep neural learning system. A deep neural learning system consists of the deep model and the learning task defined on the deep model. Moreover, the deep model is usually a deep neural network, involving the model architecture, data, training loss and training algorithm. We speculate that the vulnerability of the deep learning system also roots in the learning task itself. This paper defines the interval-label classification task for the deep classification system, whose labels are predefined non-overlapping intervals, instead of a fixed value (hard label) or probability vector (soft label). The experimental results demonstrate that the interval-label classification task is more robust than the traditional classification task while retaining accuracy.
Multi-Moments in Time: Learning and Interpreting Models for Multi-Action Video Understanding
Nov 04, 2019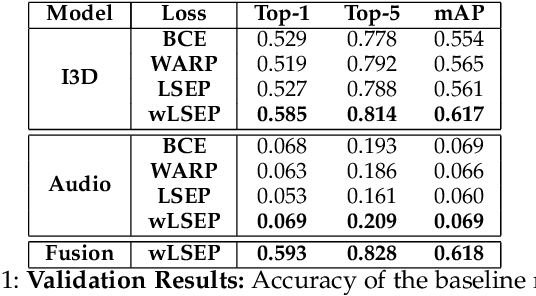


An event happening in the world is often made of different activities and actions that can unfold simultaneously or sequentially within a few seconds. However, most large-scale datasets built to train models for action recognition provide a single label per video clip. Consequently, models can be incorrectly penalized for classifying actions that exist in the videos but are not explicitly labeled and do not learn the full spectrum of information that would be mandatory to more completely comprehend different events and eventually learn causality between them. Towards this goal, we augmented the existing video dataset, Moments in Time (MiT), to include over two million action labels for over one million three second videos. This multi-label dataset introduces novel challenges on how to train and analyze models for multi-action detection. Here, we present baseline results for multi-action recognition using loss functions adapted for long tail multi-label learning and provide improved methods for visualizing and interpreting models trained for multi-label action detection.
Trinity: A No-Code AI platform for complex spatial datasets
Jun 28, 2021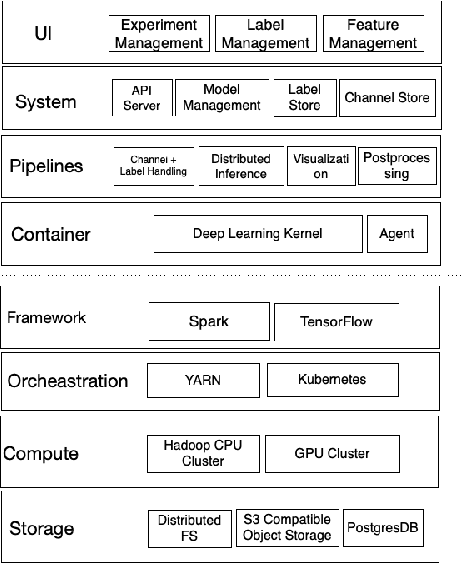
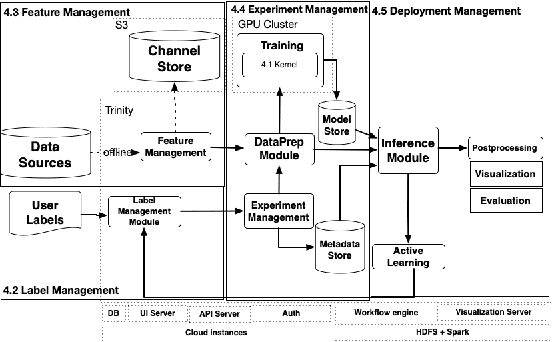
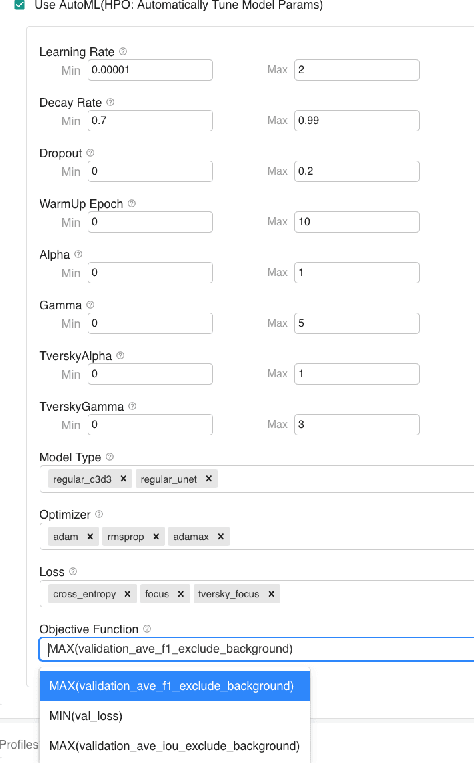

We present a no-code Artificial Intelligence (AI) platform called Trinity with the main design goal of enabling both machine learning researchers and non-technical geospatial domain experts to experiment with domain-specific signals and datasets for solving a variety of complex problems on their own. This versatility to solve diverse problems is achieved by transforming complex Spatio-temporal datasets to make them consumable by standard deep learning models, in this case, Convolutional Neural Networks (CNNs), and giving the ability to formulate disparate problems in a standard way, eg. semantic segmentation. With an intuitive user interface, a feature store that hosts derivatives of complex feature engineering, a deep learning kernel, and a scalable data processing mechanism, Trinity provides a powerful platform for domain experts to share the stage with scientists and engineers in solving business-critical problems. It enables quick prototyping, rapid experimentation and reduces the time to production by standardizing model building and deployment. In this paper, we present our motivation behind Trinity and its design along with showcasing sample applications to motivate the idea of lowering the bar to using AI.
Nominal Unification and Matching of Higher Order Expressions with Recursive Let
Feb 16, 2021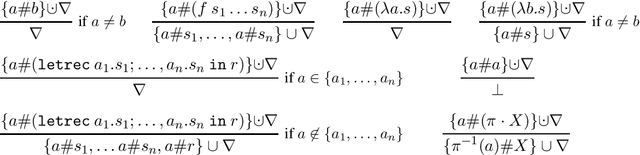


A sound and complete algorithm for nominal unification of higher-order expressions with a recursive let is described, and shown to run in nondeterministic polynomial time. We also explore specializations like nominal letrec-matching for expressions, for DAGs, and for garbage-free expressions and determine their complexity. Finally, we also provide a nominal unification algorithm for higher-order expressions with recursive let and atom-variables, where we show that it also runs in nondeterministic polynomial time.
Is Automated Topic Model Evaluation Broken?: The Incoherence of Coherence
Jul 05, 2021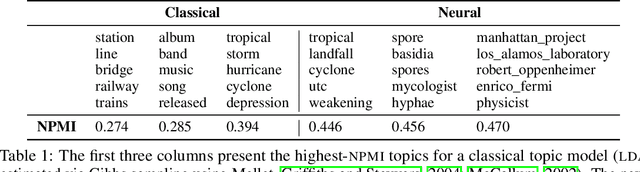


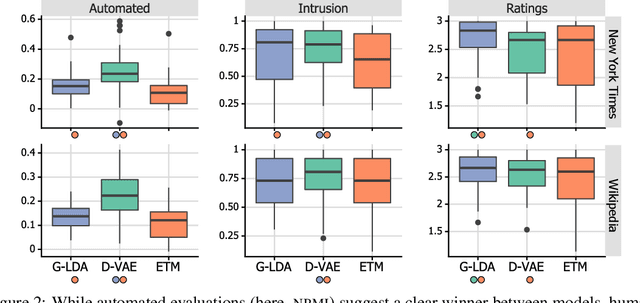
Topic model evaluation, like evaluation of other unsupervised methods, can be contentious. However, the field has coalesced around automated estimates of topic coherence, which rely on the frequency of word co-occurrences in a reference corpus. Recent models relying on neural components surpass classical topic models according to these metrics. At the same time, unlike classical models, the practice of neural topic model evaluation suffers from a validation gap: automatic coherence for neural models has not been validated using human experimentation. In addition, as we show via a meta-analysis of topic modeling literature, there is a substantial standardization gap in the use of automated topic modeling benchmarks. We address both the standardization gap and the validation gap. Using two of the most widely used topic model evaluation datasets, we assess a dominant classical model and two state-of-the-art neural models in a systematic, clearly documented, reproducible way. We use automatic coherence along with the two most widely accepted human judgment tasks, namely, topic rating and word intrusion. Automated evaluation will declare one model significantly different from another when corresponding human evaluations do not, calling into question the validity of fully automatic evaluations independent of human judgments.
Fast Crack Detection Using Convolutional Neural Network
May 23, 2021



To improve the efficiency and reduce the labour cost of the renovation process, this study presents a lightweight Convolutional Neural Network (CNN)-based architecture to extract crack-like features, such as cracks and joints. Moreover, Transfer Learning (TF) method was used to save training time while offering comparable prediction results. For three different objectives: 1) Detection of the concrete cracks; 2) Detection of natural stone cracks; 3) Differentiation between joints and cracks in natural stone; We built a natural stone dataset with joints and cracks information as complementary for the concrete benchmark dataset. As the results show, our model is demonstrated as an effective tool for industry use.
Evaluating Online and Offline Accuracy Traversal Algorithms for k-Complete Neural Network Architectures
Jan 16, 2021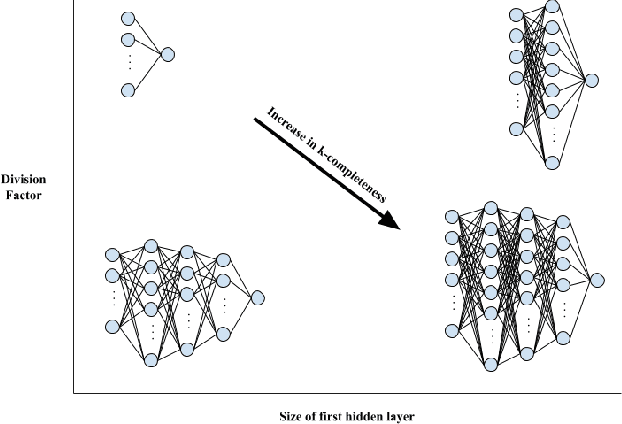
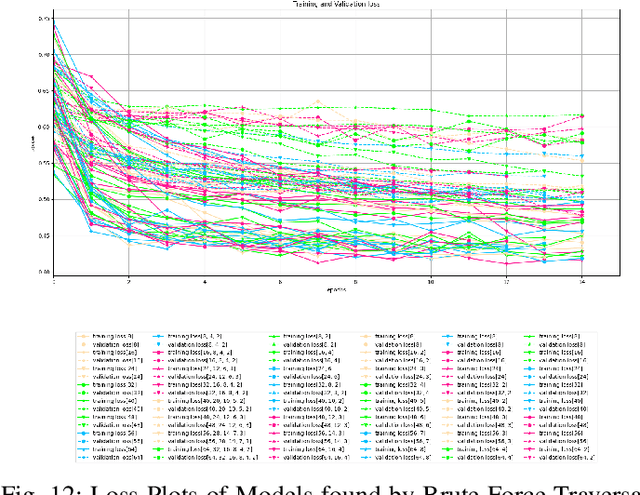
Architecture sizes for neural networks have been studied widely and several search methods have been offered to find the best architecture size in the shortest amount of time possible. In this paper, we study compact neural network architectures for binary classification and investigate improvements in speed and accuracy when favoring overcomplete architecture candidates that have a very high-dimensional representation of the input. We hypothesize that an overcomplete model architecture that creates a relatively high-dimensional representation of the input will be not only be more accurate but would also be easier and faster to find. In an NxM search space, we propose an online traversal algorithm that finds the best architecture candidate in O(1) time for best case and O(N) amortized time for average case for any compact binary classification problem by using k-completeness as heuristics in our search. The two other offline search algorithms we implement are brute force traversal and diagonal traversal, which both find the best architecture candidate in O(NxM) time. We compare our new algorithm to brute force and diagonal searching as a baseline and report search time improvement of 52.1% over brute force and of 15.4% over diagonal search to find the most accurate neural network architecture when given the same dataset. In all cases discussed in the paper, our online traversal algorithm can find an accurate, if not better, architecture in significantly shorter amount of time.
Linear systems with neural network nonlinearities: Improved stability analysis via acausal Zames-Falb multipliers
Mar 31, 2021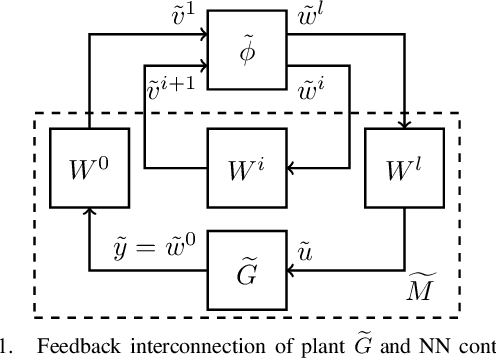
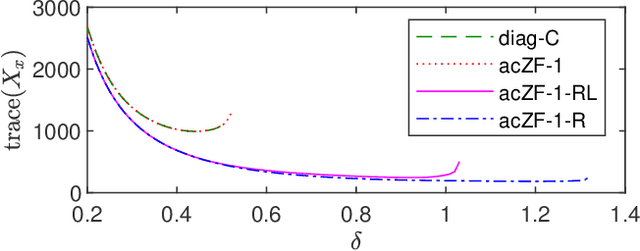
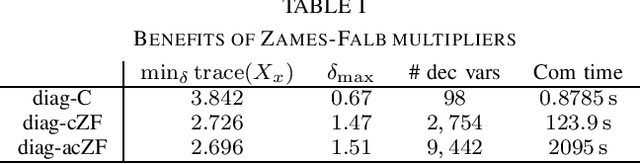
In this paper, we analyze the stability of feedback interconnections of a linear time-invariant system with a neural network nonlinearity in discrete time. Our analysis is based on abstracting neural networks using integral quadratic constraints (IQCs), exploiting the sector-bounded and slope-restricted structure of the underlying activation functions. In contrast to existing approaches, we leverage the full potential of dynamic IQCs to describe the nonlinear activation functions in a less conservative fashion. To be precise, we consider multipliers based on the full-block Yakubovich / circle criterion in combination with acausal Zames-Falb multipliers, leading to linear matrix inequality based stability certificates. Our approach provides a flexible and versatile framework for stability analysis of feedback interconnections with neural network nonlinearities, allowing to trade off computational efficiency and conservatism. Finally, we provide numerical examples that demonstrate the applicability of the proposed framework and the achievable improvements over previous approaches.