 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Technical Report: Quality Assessment Tool for Machine Learning with Clinical CT
Jul 27, 2021
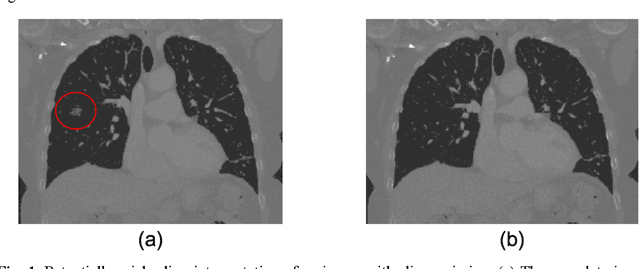

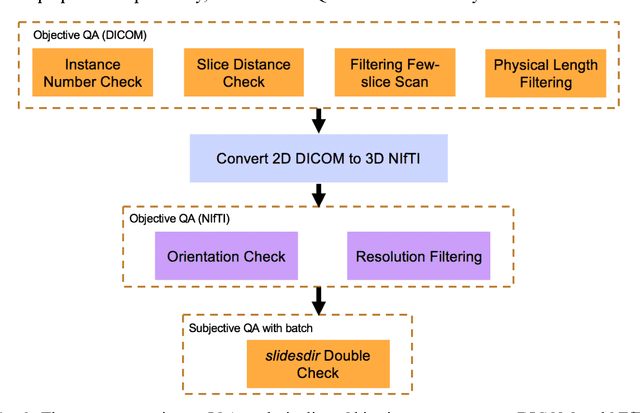

Image Quality Assessment (IQA) is important for scientific inquiry, especially in medical imaging and machine learning. Potential data quality issues can be exacerbated when human-based workflows use limited views of the data that may obscure digital artifacts. In practice, multiple factors such as network issues, accelerated acquisitions, motion artifacts, and imaging protocol design can impede the interpretation of image collections. The medical image processing community has developed a wide variety of tools for the inspection and validation of imaging data. Yet, IQA of computed tomography (CT) remains an under-recognized challenge, and no user-friendly tool is commonly available to address these potential issues. Here, we create and illustrate a pipeline specifically designed to identify and resolve issues encountered with large-scale data mining of clinically acquired CT data. Using the widely studied National Lung Screening Trial (NLST), we have identified approximately 4% of image volumes with quality concerns out of 17,392 scans. To assess robustness, we applied the proposed pipeline to our internal datasets where we find our tool is generalizable to clinically acquired medical images. In conclusion, the tool has been useful and time-saving for research study of clinical data, and the code and tutorials are publicly available at https://github.com/MASILab/QA_tool.
Light Lies: Optical Adversarial Attack
Jul 14, 2021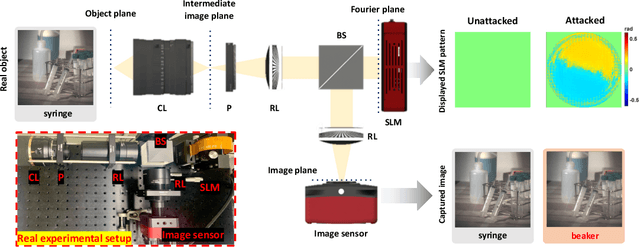

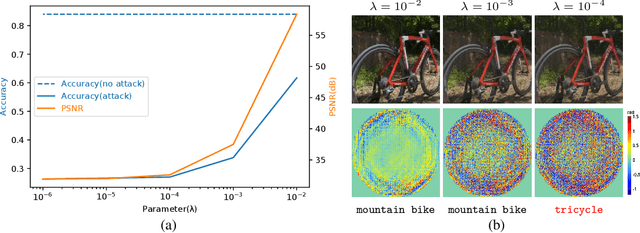
A significant amount of work has been done on adversarial attacks that inject imperceptible noise to images to deteriorate the image classification performance of deep models. However, most of the existing studies consider attacks in the digital (pixel) domain where an image acquired by an image sensor with sampling and quantization has been recorded. This paper, for the first time, introduces an optical adversarial attack, which physically alters the light field information arriving at the image sensor so that the classification model yields misclassification. More specifically, we modulate the phase of the light in the Fourier domain using a spatial light modulator placed in the photographic system. The operative parameters of the modulator are obtained by gradient-based optimization to maximize cross-entropy and minimize distortions. We present experiments based on both simulation and a real hardware optical system, from which the feasibility of the proposed optical attack is demonstrated. It is also verified that the proposed attack is completely different from common optical-domain distortions such as spherical aberration, defocus, and astigmatism in terms of both perturbation patterns and classification results.
Incremental cluster validity index-guided online learning for performance and robustness to presentation order
Aug 17, 2021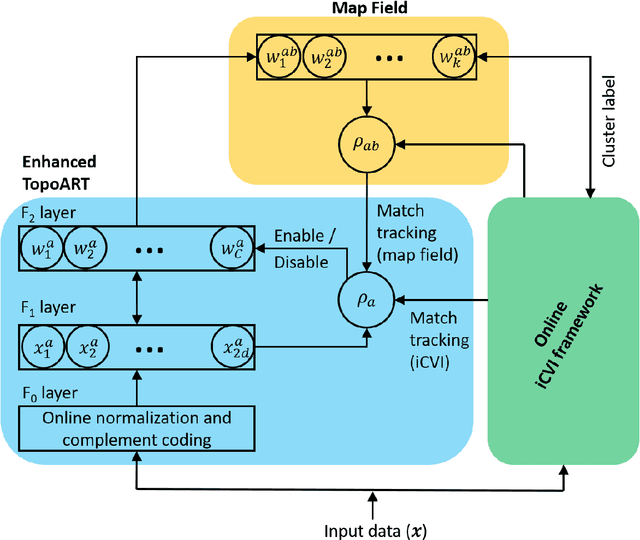
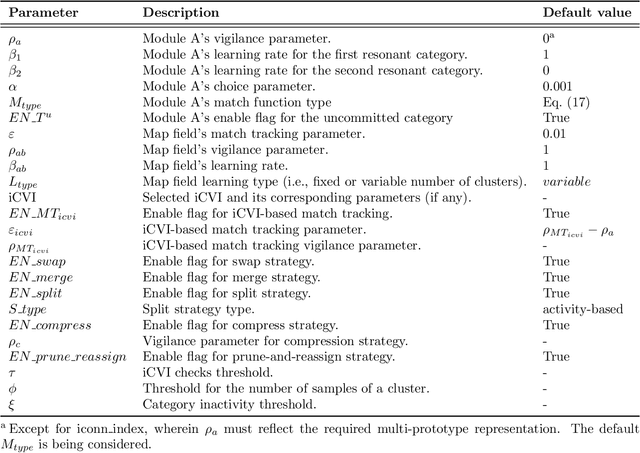
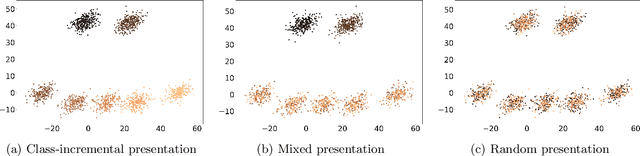
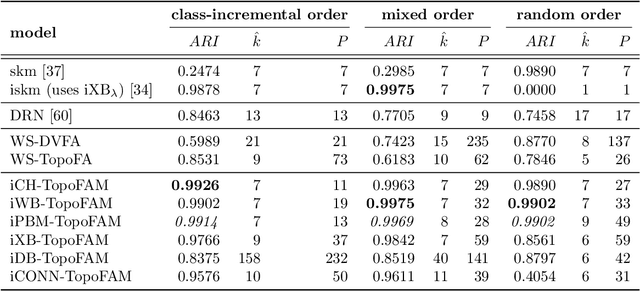
In streaming data applications incoming samples are processed and discarded, therefore, intelligent decision-making is crucial for the performance of lifelong learning systems. In addition, the order in which samples arrive may heavily affect the performance of online (and offline) incremental learners. The recently introduced incremental cluster validity indices (iCVIs) provide valuable aid in addressing such class of problems. Their primary use-case has been cluster quality monitoring; nonetheless, they have been very recently integrated in a streaming clustering method to assist the clustering task itself. In this context, the work presented here introduces the first adaptive resonance theory (ART)-based model that uses iCVIs for unsupervised and semi-supervised online learning. Moreover, it shows for the first time how to use iCVIs to regulate ART vigilance via an iCVI-based match tracking mechanism. The model achieves improved accuracy and robustness to ordering effects by integrating an online iCVI framework as module B of a topological adaptive resonance theory predictive mapping (TopoARTMAP) -- thereby being named iCVI-TopoARTMAP -- and by employing iCVI-driven post-processing heuristics at the end of each learning step. The online iCVI framework provides assignments of input samples to clusters at each iteration in accordance to any of several iCVIs. The iCVI-TopoARTMAP maintains useful properties shared by ARTMAP models, such as stability, immunity to catastrophic forgetting, and the many-to-one mapping capability via the map field module. The performance (unsupervised and semi-supervised) and robustness to presentation order (unsupervised) of iCVI-TopoARTMAP were evaluated via experiments with a synthetic data set and deep embeddings of a real-world face image data set.
A Learning-Based Fast Uplink Grant for Massive IoT via Support Vector Machines and Long Short-Term Memory
Aug 02, 2021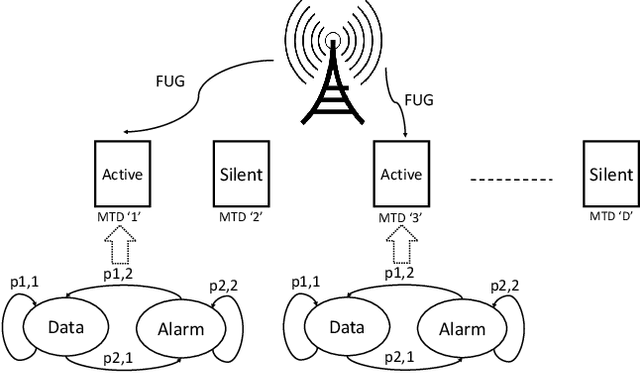
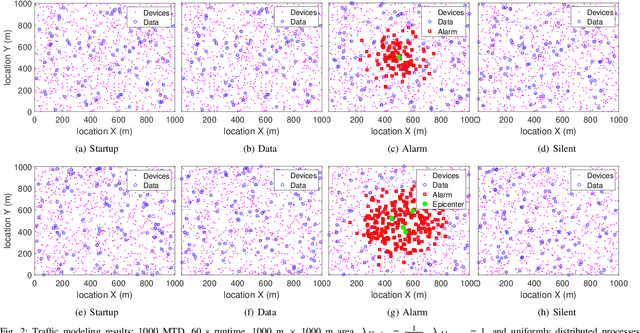
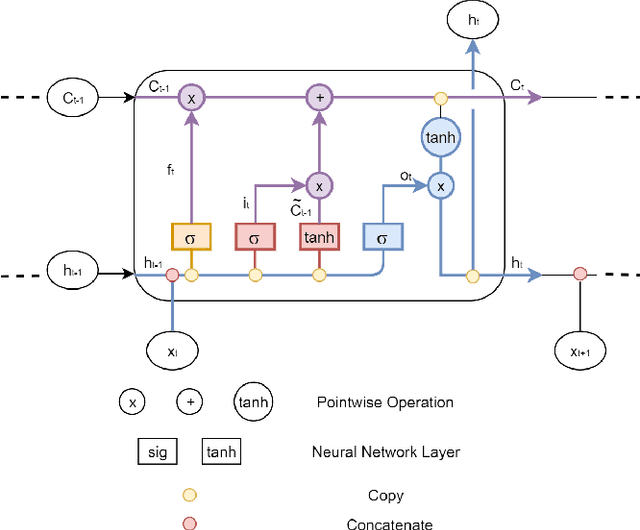
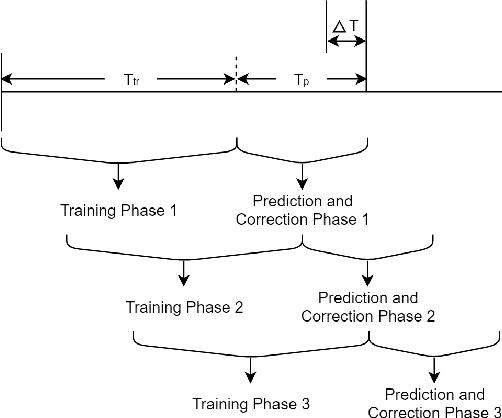
The current random access (RA) allocation techniques suffer from congestion and high signaling overhead while serving massive machine type communication (mMTC) applications. To this end, 3GPP introduced the need to use fast uplink grant (FUG) allocation in order to reduce latency and increase reliability for smart internet-of-things (IoT) applications with strict QoS constraints. We propose a novel FUG allocation based on support vector machine (SVM), First, MTC devices are prioritized using SVM classifier. Second, LSTM architecture is used for traffic prediction and correction techniques to overcome prediction errors. Both results are used to achieve an efficient resource scheduler in terms of the average latency and total throughput. A Coupled Markov Modulated Poisson Process (CMMPP) traffic model with mixed alarm and regular traffic is applied to compare the proposed FUG allocation to other existing allocation techniques. In addition, an extended traffic model based CMMPP is used to evaluate the proposed algorithm in a more dense network. We test the proposed scheme using real-time measurement data collected from the Numenta Anomaly Benchmark (NAB) database. Our simulation results show the proposed model outperforms the existing RA allocation schemes by achieving the highest throughput and the lowest access delay of the order of 1 ms by achieving prediction accuracy of 98 $\%$ when serving the target massive and critical MTC applications with a limited number of resources.
Neural Style Transfer Enhanced Training Support For Human Activity Recognition
Jul 27, 2021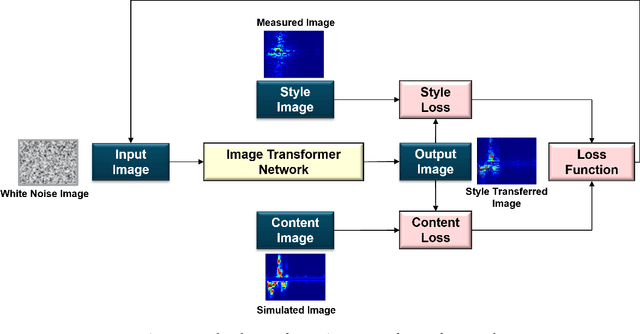
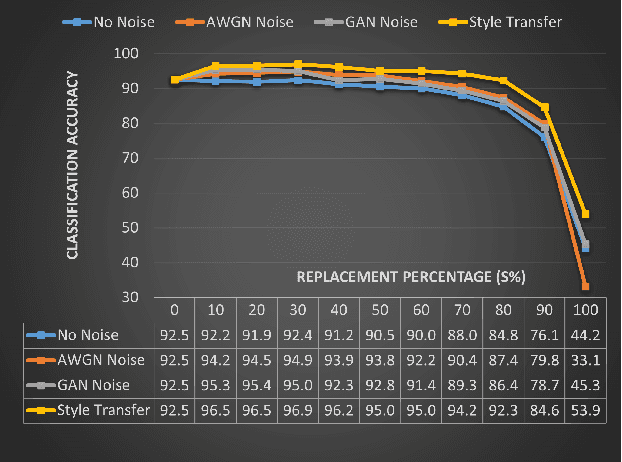
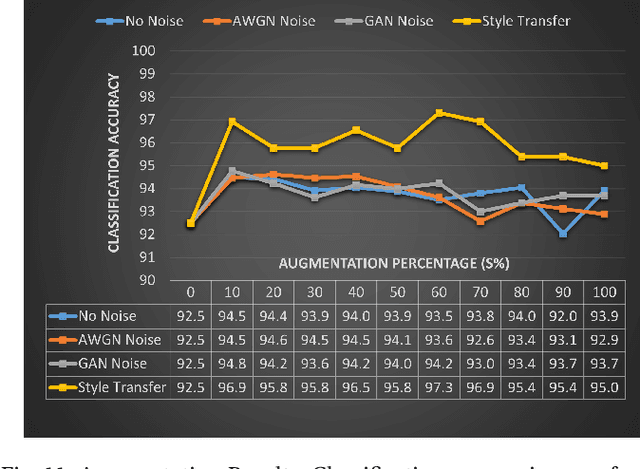
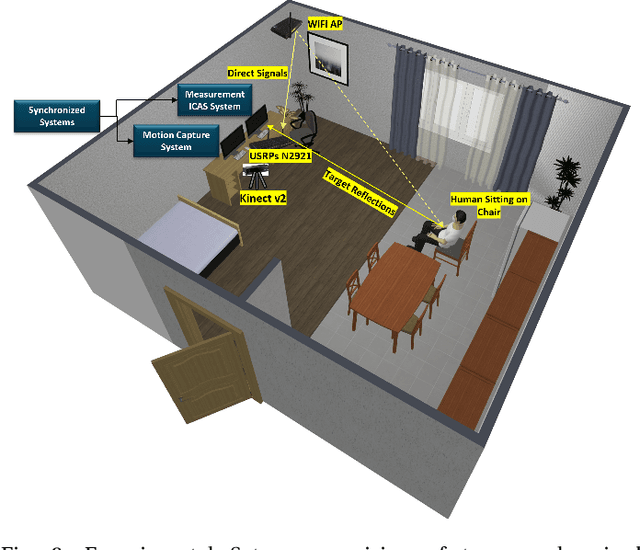
This work presents an application of Integrated sensing and communication (ISAC) system for monitoring human activities directly related to healthcare. Real-time monitoring of humans can assist professionals in providing healthy living enabling technologies to ensure the health, safety, and well-being of people of all age groups. To enhance the human activity recognition performance of the ISAC system, we propose to use synthetic data generated through our human micro-Doppler simulator, SimHumalator to augment our limited measurement data. We generate a more realistic micro-Doppler signature dataset using a style-transfer neural network. The proposed network extracts environmental effects such as noise, multipath, and occlusions effects directly from the measurement data and transfers these features to our clean simulated signatures. This results in more realistic-looking signatures qualitatively and quantitatively. We use these enhanced signatures to augment our measurement data and observe an improvement in the classification performance by 5% compared to no augmentation case. Further, we benchmark the data augmentation performance of the style transferred signatures with three other synthetic datasets -- clean simulated spectrograms (no environmental effects), simulated data with added AWGN noise, and simulated data with GAN generated noise. The results indicate that style transferred simulated signatures well captures environmental factors more than any other synthetic dataset.
Real-time Tracking-by-Detection of Human Motion in RGB-D Camera Networks
Jul 28, 2019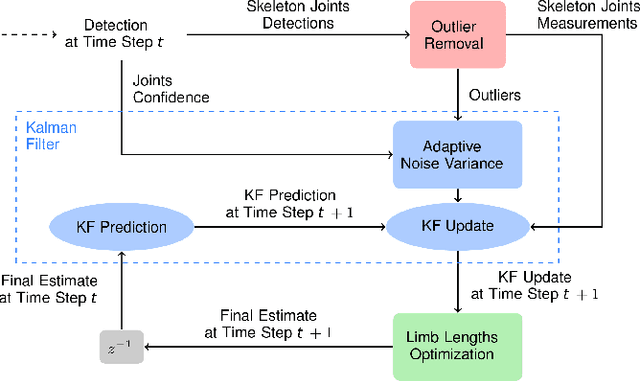
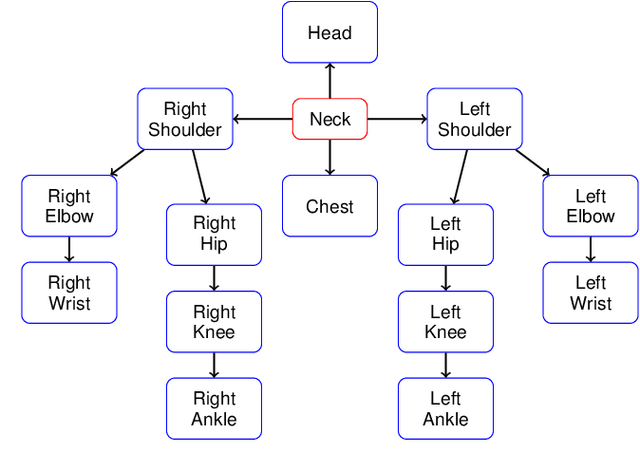
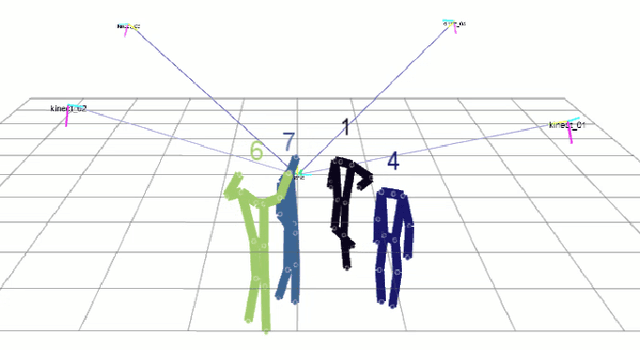
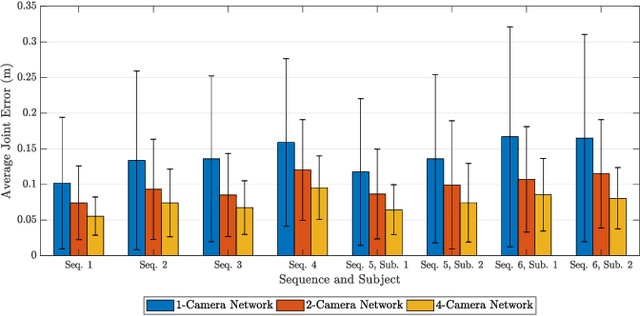
This paper presents a novel real-time tracking system capable of improving body pose estimation algorithms in distributed camera networks. The first stage of our approach introduces a linear Kalman filter operating at the body joints level, used to fuse single-view body poses coming from different detection nodes of the network and to ensure temporal consistency between them. The second stage, instead, refines the Kalman filter estimates by fitting a hierarchical model of the human body having constrained link sizes in order to ensure the physical consistency of the tracking. The effectiveness of the proposed approach is demonstrated through a broad experimental validation, performed on a set of sequences whose ground truth references are generated by a commercial marker-based motion capture system. The obtained results show how the proposed system outperforms the considered state-of-the-art approaches, granting accurate and reliable estimates. Moreover, the developed methodology constrains neither the number of persons to track, nor the number, position, synchronization, frame-rate, and manufacturer of the RGB-D cameras used. Finally, the real-time performances of the system are of paramount importance for a large number of real-world applications.
Florida Wildlife Camera Trap Dataset
Jun 23, 2021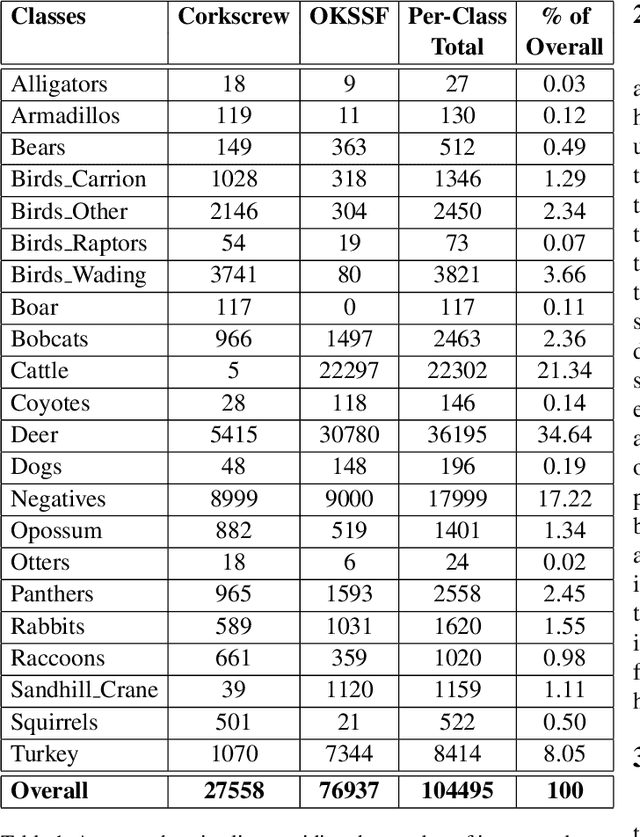

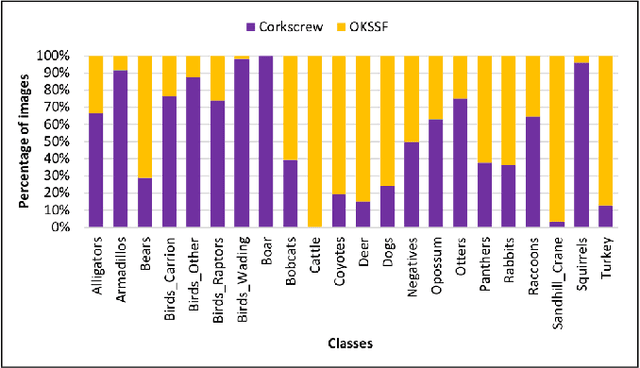

Trail camera imagery has increasingly gained popularity amongst biologists for conservation and ecological research. Minimal human interference required to operate camera traps allows capturing unbiased species activities. Several studies - based on human and wildlife interactions, migratory patterns of various species, risk of extinction in endangered populations - are limited by the lack of rich data and the time-consuming nature of manually annotating trail camera imagery. We introduce a challenging wildlife camera trap classification dataset collected from two different locations in Southwestern Florida, consisting of 104,495 images featuring visually similar species, varying illumination conditions, skewed class distribution, and including samples of endangered species, i.e. Florida panthers. Experimental evaluations with ResNet-50 architecture indicate that this image classification-based dataset can further push the advancements in wildlife statistical modeling. We will make the dataset publicly available.
Point Proposal Network for Reconstructing 3D Particle Positions with Sub-Pixel Precision in Liquid Argon Time Projection Chambers
Jun 26, 2020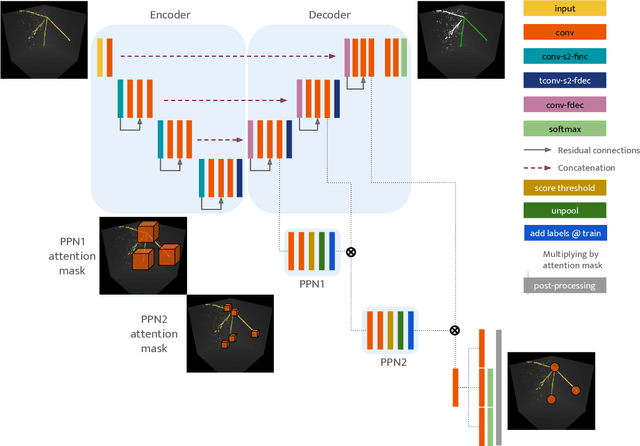

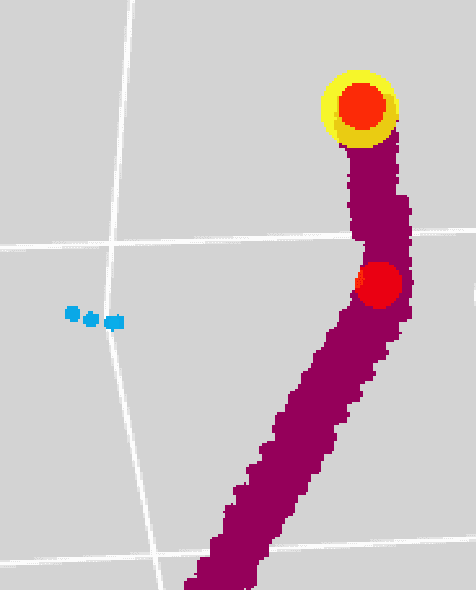
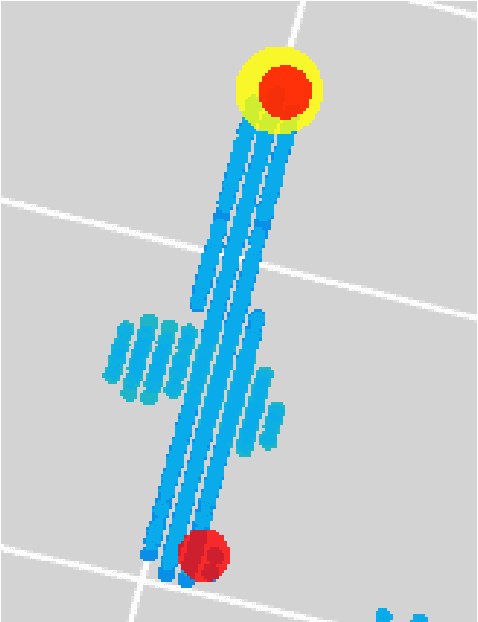
Liquid Argon Time Projection Chambers (LArTPC) are particle imaging detectors recording 2D or 3D images of numerous complex trajectories of charged particles. Identifying points of interest in these images, such as the starting and ending points of particles trajectories, is a crucial step of identifying and analyzing these particles and impacts inference of physics signals such as neutrino interaction. The Point Proposal Network is designed to discover specific points of interest, namely the starting and ending points of track-like particle trajectories such as muons and protons, and the starting points of electromagnetic shower-like particle trajectories such as electrons and gamma rays. The algorithm predicts with a sub-voxel precision their spatial location, and also determines the category of the identified points of interest. Using the PILArNet public LArTPC data sample as a benchmark, our algorithm successfully predicted 96.8%, 97.8%, and 98.1% of 3D points within the voxel distance of 3, 10, and 20 from the provided true point locations respectively. For the predicted 3D points within 3 voxels of the closest true point locations, the median distance is found to be 0.25 voxels, achieving the sub-voxel level precision. We report that the majority of predicted points that are more than 10 voxels away from the closest true point locations are legitimate mistakes, and our algorithm achieved high enough accuracy to identify issues associated with a small fraction of true point locations provided in the dataset. Further, using those predicted points, we demonstrate a set of simple algorithms to cluster 3D voxels into individual track-like particle trajectories at the clustering efficiency, purity, and Adjusted Rand Index of 83.2%, 96.7%, and 94.7% respectively.
SURFNet: Super-resolution of Turbulent Flows with Transfer Learning using Small Datasets
Aug 17, 2021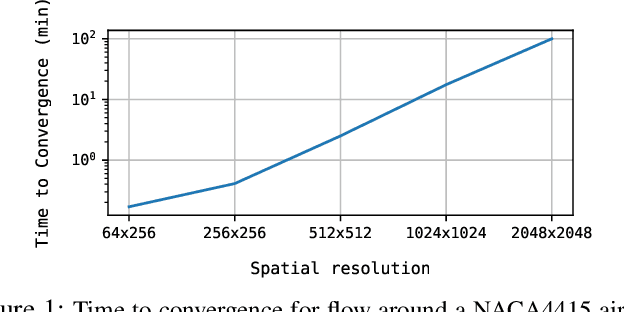
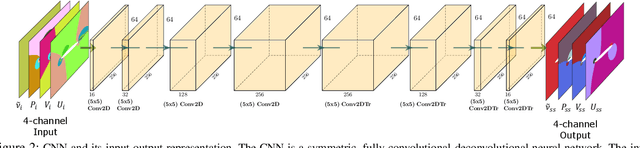
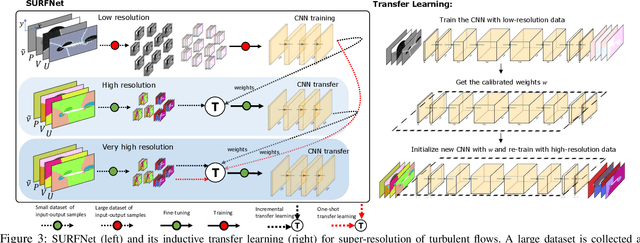

Deep Learning (DL) algorithms are emerging as a key alternative to computationally expensive CFD simulations. However, state-of-the-art DL approaches require large and high-resolution training data to learn accurate models. The size and availability of such datasets are a major limitation for the development of next-generation data-driven surrogate models for turbulent flows. This paper introduces SURFNet, a transfer learning-based super-resolution flow network. SURFNet primarily trains the DL model on low-resolution datasets and transfer learns the model on a handful of high-resolution flow problems - accelerating the traditional numerical solver independent of the input size. We propose two approaches to transfer learning for the task of super-resolution, namely one-shot and incremental learning. Both approaches entail transfer learning on only one geometry to account for fine-grid flow fields requiring 15x less training data on high-resolution inputs compared to the tiny resolution (64x256) of the coarse model, significantly reducing the time for both data collection and training. We empirically evaluate SURFNet's performance by solving the Navier-Stokes equations in the turbulent regime on input resolutions up to 256x larger than the coarse model. On four test geometries and eight flow configurations unseen during training, we observe a consistent 2-2.1x speedup over the OpenFOAM physics solver independent of the test geometry and the resolution size (up to 2048x2048), demonstrating both resolution-invariance and generalization capabilities. Our approach addresses the challenge of reconstructing high-resolution solutions from coarse grid models trained using low-resolution inputs (super-resolution) without loss of accuracy and requiring limited computational resources.
Exploiting temporal consistency for real-time video depth estimation
Aug 10, 2019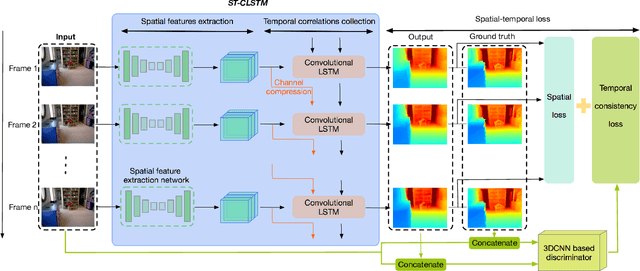
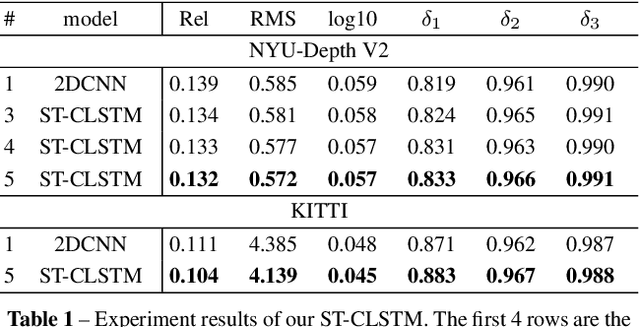
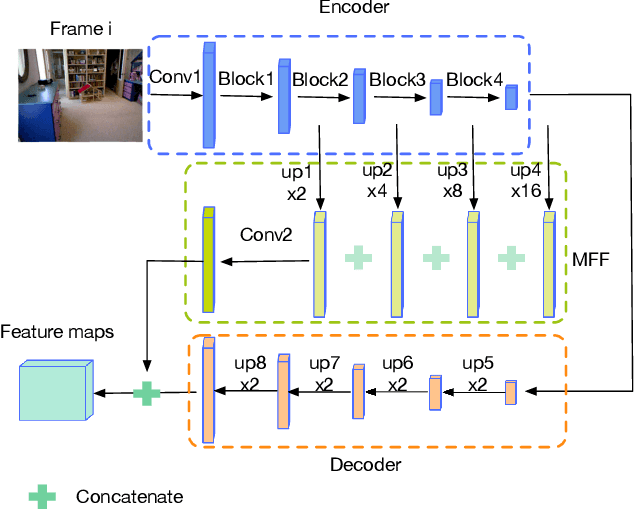
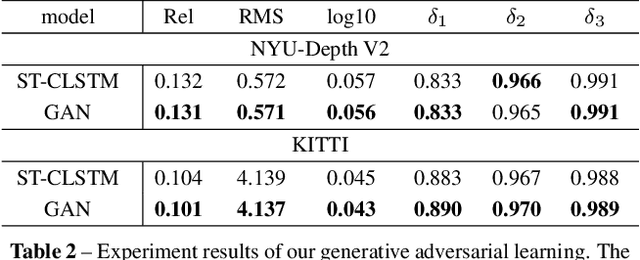
Accuracy of depth estimation from static images has been significantly improved recently, by exploiting hierarchical features from deep convolutional neural networks (CNNs). Compared with static images, vast information exists among video frames and can be exploited to improve the depth estimation performance. In this work, we focus on exploring temporal information from monocular videos for depth estimation. Specifically, we take the advantage of convolutional long short-term memory (CLSTM) and propose a novel spatial-temporal CSLTM (ST-CLSTM) structure. Our ST-CLSTM structure can capture not only the spatial features but also the temporal correlations/consistency among consecutive video frames with negligible increase in computational cost. Additionally, in order to maintain the temporal consistency among the estimated depth frames, we apply the generative adversarial learning scheme and design a temporal consistency loss. The temporal consistency loss is combined with the spatial loss to update the model in an end-to-end fashion. By taking advantage of the temporal information, we build a video depth estimation framework that runs in real-time and generates visually pleasant results. Moreover, our approach is flexible and can be generalized to most existing depth estimation frameworks. Code is available at: https://tinyurl.com/STCLSTM