 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Gait Generation for Multi-Terrain Exoskeletons via Constrained Kernelized Movement Primitives
May 04, 2026Lower limb exoskeletons (LLEs) present the potential to make motor-impaired individuals walk again. Their application in real-world environments is still limited by the lack of effective adaptive gait planning. Indeed, current exoskeletons are meant to walk only on a flat and even terrain. Generating environment-aware, physiologically consistent gait trajectories in real-time is an open challenge. To overcome this, we propose a novel Kernelized Movement Primitives (KMP)-based framework for adaptive gait generation (AGG) across multiple indoor terrains. The proposed approach learns a probabilistic representation of human gait in both the joint and task spaces from a limited number of human demonstrations, representing natural gait characteristics and ensuring kinematic feasibility. In addition, the learned trajectories are adapted using environmental information extracted from an onboard RGB-D camera by treating the AGG as a linearly constrained optimization problem with via-points. The proposed method has been thoroughly validated first in simulations for gait generation in different scenarios, such as flat-ground walking, slopes, stairs, and obstacles crossing. Finally, the effectiveness and robustness of the method have been demonstrated with experiments on a commercial LLE in real-world scenarios. The results obtained demonstrate the feasibility of an environment-aware gait planning system for a new generation of intelligent lower limb exoskeletons for assisting people with disabilities in their every-day life.
GEGLU-Transformer for IMU-to-EMG Estimation with Few-Shot Adaptation
Apr 28, 2026Reliable estimation of neuromuscular activation is a key enabler for adaptive and personalized control in wearable robotics. However, surface electromyography (EMG) remains difficult to deploy robustly outside laboratory settings due to electrode sensitivity, signal non-stationarity, and strong subject dependence. In this work, we propose an adaptive IMU-to-EMG learning framework that reconstructs continuous muscle activation envelopes from wearable inertial measurements across heterogeneous movement conditions. The approach combines a Transformer encoder with Gaussian Error Gated Linear Units (GEGLU-Transformer) to enhance cross-subject generalization and enable rapid subject-specific personalization. Under a strict leave-one-subject-out (LOSO) protocol on a multi-condition lower-limb biomechanics dataset, the proposed architecture achieves r = 0.706 +/- 0.139 and R^2 = 0.474 +/- 0.208 without subject-specific adaptation. With only 0.5% adaptation data, performance increases to r = 0.761 +/- 0.030 and R^2 = 0.559 +/- 0.047, demonstrating rapid adaptation and early performance saturation. These results support attention-based architectures combined with lightweight adaptation as a practical and scalable alternative to direct EMG sensing for real-world wearable robotic applications.
DISF: Disentangled Iterative Surface Fitting for Contact-stable Grasp Planning with Grasp Pose Alignment to the Object Center of Mass
Dec 31, 2025In this work, we address the limitation of surface fitting-based grasp planning algorithm, which primarily focuses on geometric alignment between the gripper and object surface while overlooking the stability of contact point distribution, often resulting in unstable grasps due to inadequate contact configurations. To overcome this limitation, we propose a novel surface fitting algorithm that integrates contact stability while preserving geometric compatibility. Inspired by human grasping behavior, our method disentangles the grasp pose optimization into three sequential steps: (1) rotation optimization to align contact normals, (2) translation refinement to improve the alignment between the gripper frame origin and the object Center of Mass (CoM), and (3) gripper aperture adjustment to optimize contact point distribution. We validate our approach in simulation across 15 objects under both Known-shape (with clean CAD-derived dataset) and Observed-shape (with YCB object dataset) settings, including cross-platform grasp execution on three robot--gripper platforms. We further validate the method in real-world grasp experiments on a UR3e robot. Overall, DISF reduces CoM misalignment while maintaining geometric compatibility, translating into higher grasp success in both simulation and real-world execution compared to baselines. Additional videos and supplementary results are available on our project page: https://tomoya-yamanokuchi.github.io/disf-ras-project-page/
Disentangled Iterative Surface Fitting for Contact-stable Grasp Planning
Feb 17, 2025In this work, we address the limitation of surface fitting-based grasp planning algorithm, which primarily focuses on geometric alignment between the gripper and object surface while overlooking the stability of contact point distribution, often resulting in unstable grasps due to inadequate contact configurations. To overcome this limitation, we propose a novel surface fitting algorithm that integrates contact stability while preserving geometric compatibility. Inspired by human grasping behavior, our method disentangles the grasp pose optimization into three sequential steps: (1) rotation optimization to align contact normals, (2) translation refinement to improve Center of Mass (CoM) alignment, and (3) gripper aperture adjustment to optimize contact point distribution. We validate our approach through simulations on ten YCB dataset objects, demonstrating an 80% improvement in grasp success over conventional surface fitting methods that disregard contact stability. Further details can be found on our project page: https://tomoya-yamanokuchi.github.io/disf-project-page/.
Exploiting Local Features and Range Images for Small Data Real-Time Point Cloud Semantic Segmentation
Oct 14, 2024



Semantic segmentation of point clouds is an essential task for understanding the environment in autonomous driving and robotics. Recent range-based works achieve real-time efficiency, while point- and voxel-based methods produce better results but are affected by high computational complexity. Moreover, highly complex deep learning models are often not suited to efficiently learn from small datasets. Their generalization capabilities can easily be driven by the abundance of data rather than the architecture design. In this paper, we harness the information from the three-dimensional representation to proficiently capture local features, while introducing the range image representation to incorporate additional information and facilitate fast computation. A GPU-based KDTree allows for rapid building, querying, and enhancing projection with straightforward operations. Extensive experiments on SemanticKITTI and nuScenes datasets demonstrate the benefits of our modification in a ``small data'' setup, in which only one sequence of the dataset is used to train the models, but also in the conventional setup, where all sequences except one are used for training. We show that a reduced version of our model not only demonstrates strong competitiveness against full-scale state-of-the-art models but also operates in real-time, making it a viable choice for real-world case applications. The code of our method is available at https://github.com/Bender97/WaffleAndRange.
WasteGAN: Data Augmentation for Robotic Waste Sorting through Generative Adversarial Networks
Sep 25, 2024



Robotic waste sorting poses significant challenges in both perception and manipulation, given the extreme variability of objects that should be recognized on a cluttered conveyor belt. While deep learning has proven effective in solving complex tasks, the necessity for extensive data collection and labeling limits its applicability in real-world scenarios like waste sorting. To tackle this issue, we introduce a data augmentation method based on a novel GAN architecture called wasteGAN. The proposed method allows to increase the performance of semantic segmentation models, starting from a very limited bunch of labeled examples, such as few as 100. The key innovations of wasteGAN include a novel loss function, a novel activation function, and a larger generator block. Overall, such innovations helps the network to learn from limited number of examples and synthesize data that better mirrors real-world distributions. We then leverage the higher-quality segmentation masks predicted from models trained on the wasteGAN synthetic data to compute semantic-aware grasp poses, enabling a robotic arm to effectively recognizing contaminants and separating waste in a real-world scenario. Through comprehensive evaluation encompassing dataset-based assessments and real-world experiments, our methodology demonstrated promising potential for robotic waste sorting, yielding performance gains of up to 5.8\% in picking contaminants. The project page is available at https://github.com/bach05/wasteGAN.git
SOOD-ImageNet: a Large-Scale Dataset for Semantic Out-Of-Distribution Image Classification and Semantic Segmentation
Sep 02, 2024



Out-of-Distribution (OOD) detection in computer vision is a crucial research area, with related benchmarks playing a vital role in assessing the generalizability of models and their applicability in real-world scenarios. However, existing OOD benchmarks in the literature suffer from two main limitations: (1) they often overlook semantic shift as a potential challenge, and (2) their scale is limited compared to the large datasets used to train modern models. To address these gaps, we introduce SOOD-ImageNet, a novel dataset comprising around 1.6M images across 56 classes, designed for common computer vision tasks such as image classification and semantic segmentation under OOD conditions, with a particular focus on the issue of semantic shift. We ensured the necessary scalability and quality by developing an innovative data engine that leverages the capabilities of modern vision-language models, complemented by accurate human checks. Through extensive training and evaluation of various models on SOOD-ImageNet, we showcase its potential to significantly advance OOD research in computer vision. The project page is available at https://github.com/bach05/SOODImageNet.git.
Show and Grasp: Few-shot Semantic Segmentation for Robot Grasping through Zero-shot Foundation Models
Apr 19, 2024



The ability of a robot to pick an object, known as robot grasping, is crucial for several applications, such as assembly or sorting. In such tasks, selecting the right target to pick is as essential as inferring a correct configuration of the gripper. A common solution to this problem relies on semantic segmentation models, which often show poor generalization to unseen objects and require considerable time and massive data to be trained. To reduce the need for large datasets, some grasping pipelines exploit few-shot semantic segmentation models, which are capable of recognizing new classes given a few examples. However, this often comes at the cost of limited performance and fine-tuning is required to be effective in robot grasping scenarios. In this work, we propose to overcome all these limitations by combining the impressive generalization capability reached by foundation models with a high-performing few-shot classifier, working as a score function to select the segmentation that is closer to the support set. The proposed model is designed to be embedded in a grasp synthesis pipeline. The extensive experiments using one or five examples show that our novel approach overcomes existing performance limitations, improving the state of the art both in few-shot semantic segmentation on the Graspnet-1B (+10.5% mIoU) and Ocid-grasp (+1.6% AP) datasets, and real-world few-shot grasp synthesis (+21.7% grasp accuracy). The project page is available at: https://leobarcellona.github.io/showandgrasp.github.io/
A Graph-based Optimization Framework for Hand-Eye Calibration for Multi-Camera Setups
Mar 08, 2023



Hand-eye calibration is the problem of estimating the spatial transformation between a reference frame, usually the base of a robot arm or its gripper, and the reference frame of one or multiple cameras. Generally, this calibration is solved as a non-linear optimization problem, what instead is rarely done is to exploit the underlying graph structure of the problem itself. Actually, the problem of hand-eye calibration can be seen as an instance of the Simultaneous Localization and Mapping (SLAM) problem. Inspired by this fact, in this work we present a pose-graph approach to the hand-eye calibration problem that extends a recent state-of-the-art solution in two different ways: i) by formulating the solution to eye-on-base setups with one camera; ii) by covering multi-camera robotic setups. The proposed approach has been validated in simulation against standard hand-eye calibration methods. Moreover, a real application is shown. In both scenarios, the proposed approach overcomes all alternative methods. We release with this paper an open-source implementation of our graph-based optimization framework for multi-camera setups.
Pushing the Limits of Learning-based Traversability Analysis for Autonomous Driving on CPU
Jun 07, 2022
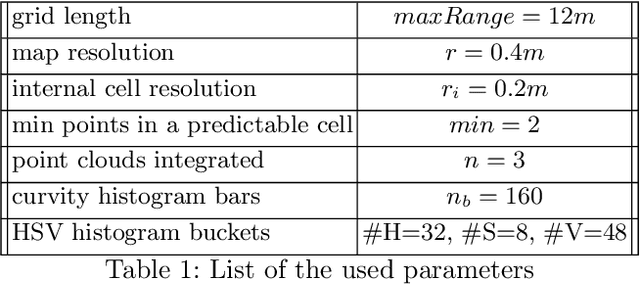

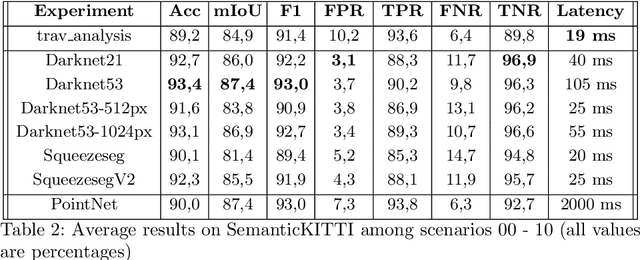
Self-driving vehicles and autonomous ground robots require a reliable and accurate method to analyze the traversability of the surrounding environment for safe navigation. This paper proposes and evaluates a real-time machine learning-based Traversability Analysis method that combines geometric features with appearance-based features in a hybrid approach based on a SVM classifier. In particular, we show that integrating a new set of geometric and visual features and focusing on important implementation details enables a noticeable boost in performance and reliability. The proposed approach has been compared with state-of-the-art Deep Learning approaches on a public dataset of outdoor driving scenarios. It reaches an accuracy of 89.2% in scenarios of varying complexity, demonstrating its effectiveness and robustness. The method runs fully on CPU and reaches comparable results with respect to the other methods, operates faster, and requires fewer hardware resources.