 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
STAR-IOS Aided NOMA Networks: Channel Model Approximation and Performance Analysis
Jul 04, 2021
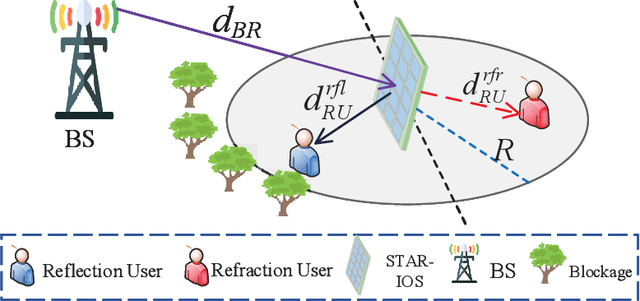
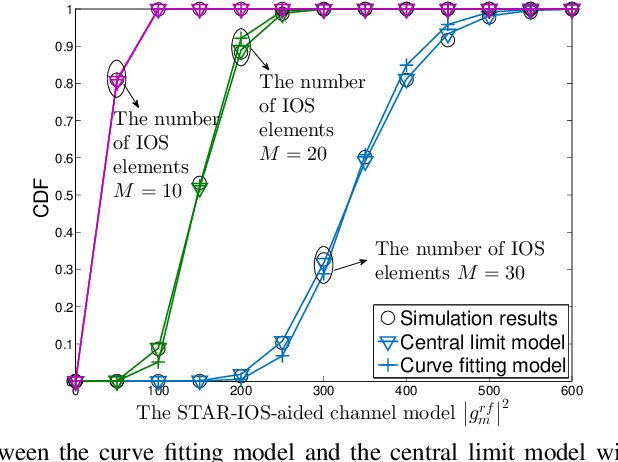
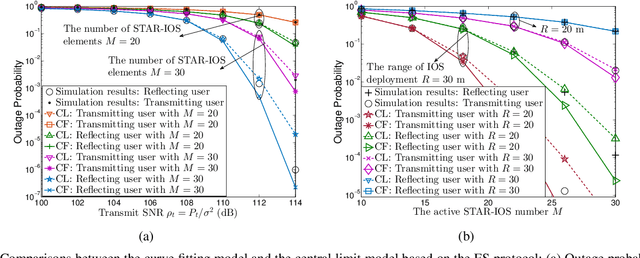
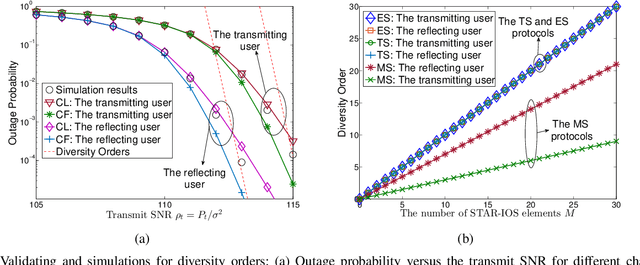
Simultaneous transmitting and reflecting intelligent omini-surfaces (STAR-IOSs) are able to achieve full coverage "smart radio environments". By splitting the energy or altering the active number of STAR-IOS elements, STAR-IOSs provide high flexibility of successive interference cancellation (SIC) orders for non-orthogonal multiple access (NOMA) systems. Based on the aforementioned advantages, this paper investigates a STAR-IOS-aided downlink NOMA network with randomly deployed users. We first propose three tractable channel models for different application scenarios, namely the central limit model, the curve fitting model, and the M-fold convolution model. More specifically, the central limit model fits the scenarios with large-size STAR-IOSs while the curve fitting model is extended to evaluate multi-cell networks. However, these two models cannot obtain accurate diversity orders. Hence, we figure out the M-fold convolution model to derive accurate diversity orders. We consider three protocols for STAR-IOSs, namely, the energy splitting (ES) protocol, the time switching (TS) protocol, and the mode switching (MS) protocol. Based on the ES protocol, we derive analytical outage probability expressions for the paired NOMA users by the central limit model and the curve fitting model. Based on three STAR-IOS protocols, we derive the diversity gains of NOMA users by the M-fold convolution model. The analytical results reveal that the diversity gain of NOMA users is equal to the active number of STAR-IOS elements. Numerical results indicate that 1) in high signal-to-noise ratio regions, the central limit model performs as an upper bound, while a lower bound is obtained by the curve fitting model; 2) the TS protocol has the best performance but requesting more time blocks than other protocols; 3) the ES protocol outperforms the MS protocol as the ES protocol has higher diversity gains.
DRINet: A Dual-Representation Iterative Learning Network for Point Cloud Segmentation
Aug 09, 2021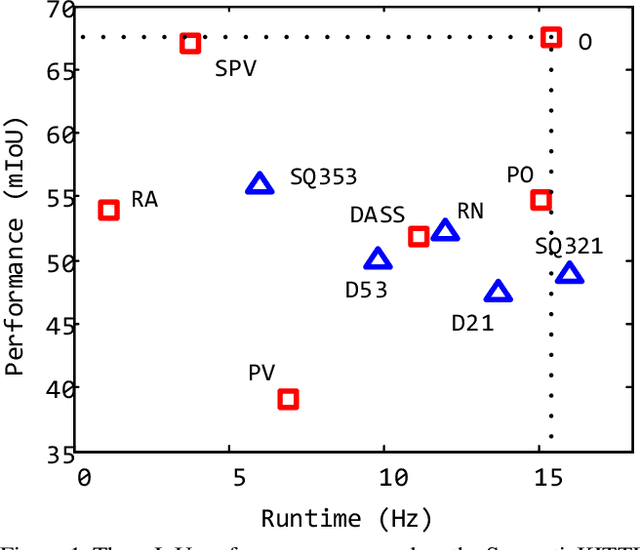
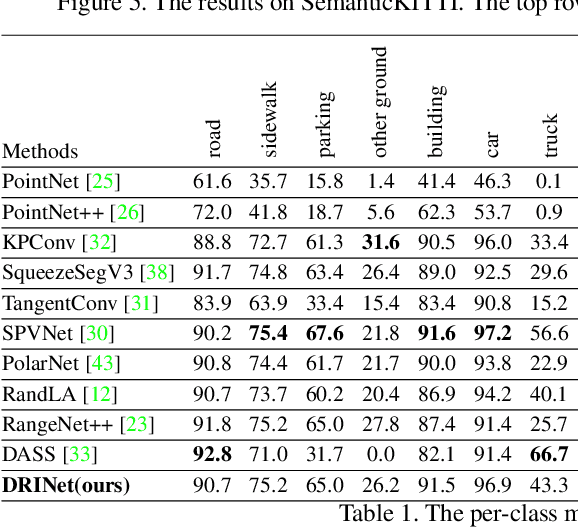
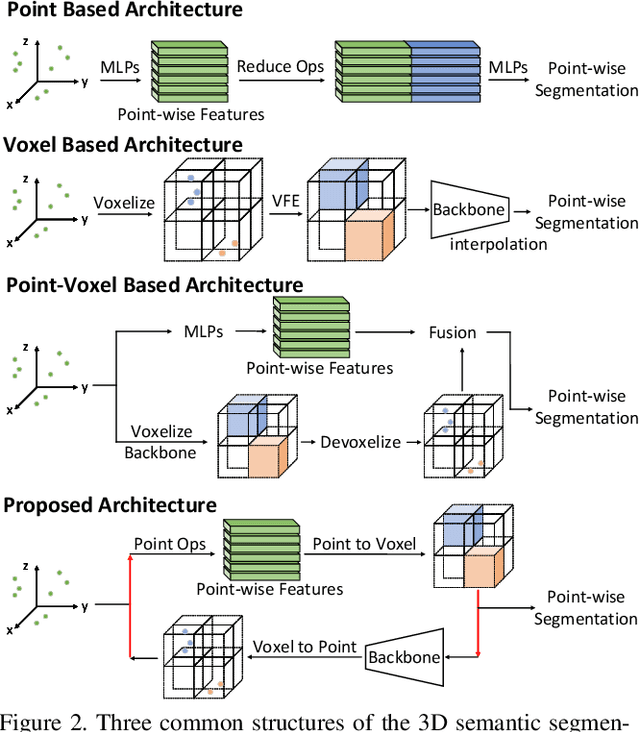

We present a novel and flexible architecture for point cloud segmentation with dual-representation iterative learning. In point cloud processing, different representations have their own pros and cons. Thus, finding suitable ways to represent point cloud data structure while keeping its own internal physical property such as permutation and scale-invariant is a fundamental problem. Therefore, we propose our work, DRINet, which serves as the basic network structure for dual-representation learning with great flexibility at feature transferring and less computation cost, especially for large-scale point clouds. DRINet mainly consists of two modules called Sparse Point-Voxel Feature Extraction and Sparse Voxel-Point Feature Extraction. By utilizing these two modules iteratively, features can be propagated between two different representations. We further propose a novel multi-scale pooling layer for pointwise locality learning to improve context information propagation. Our network achieves state-of-the-art results for point cloud classification and segmentation tasks on several datasets while maintaining high runtime efficiency. For large-scale outdoor scenarios, our method outperforms state-of-the-art methods with a real-time inference speed of 62ms per frame.
Deep Fake Detection: Survey of Facial Manipulation Detection Solutions
Jun 23, 2021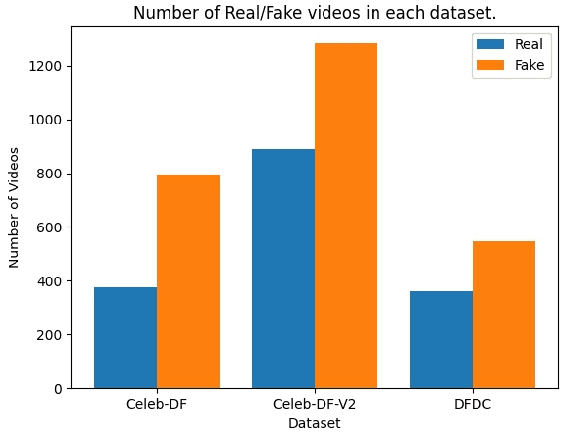
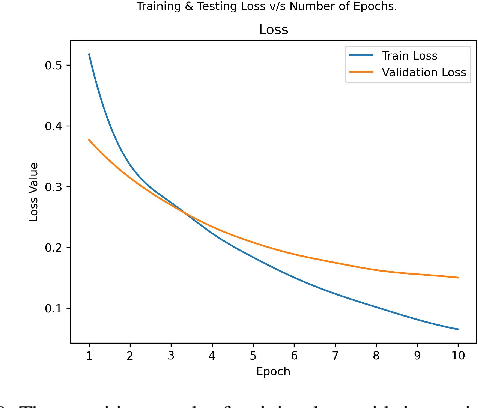
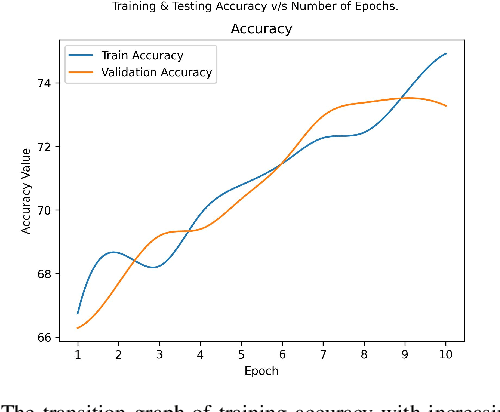
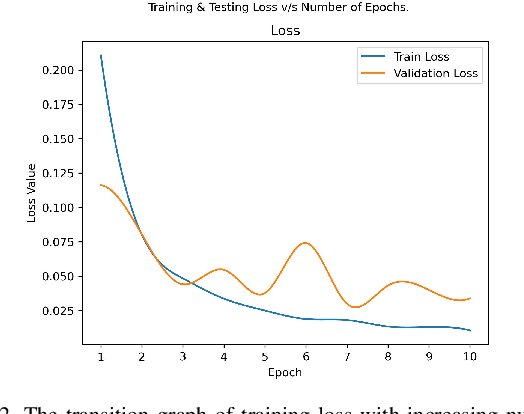
Deep Learning as a field has been successfully used to solve a plethora of complex problems, the likes of which we could not have imagined a few decades back. But as many benefits as it brings, there are still ways in which it can be used to bring harm to our society. Deep fakes have been proven to be one such problem, and now more than ever, when any individual can create a fake image or video simply using an application on the smartphone, there need to be some countermeasures, with which we can detect if the image or video is a fake or real and dispose of the problem threatening the trustworthiness of online information. Although the Deep fakes created by neural networks, may seem to be as real as a real image or video, it still leaves behind spatial and temporal traces or signatures after moderation, these signatures while being invisible to a human eye can be detected with the help of a neural network trained to specialize in Deep fake detection. In this paper, we analyze several such states of the art neural networks (MesoNet, ResNet-50, VGG-19, and Xception Net) and compare them against each other, to find an optimal solution for various scenarios like real-time deep fake detection to be deployed in online social media platforms where the classification should be made as fast as possible or for a small news agency where the classification need not be in real-time but requires utmost accuracy.
* 7 Pages, 14 figures, and 1 table
Feature Pyramid Network for Multi-task Affective Analysis
Jul 09, 2021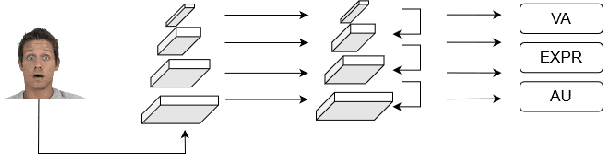
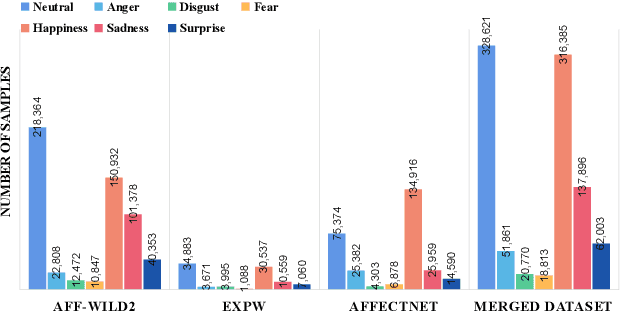
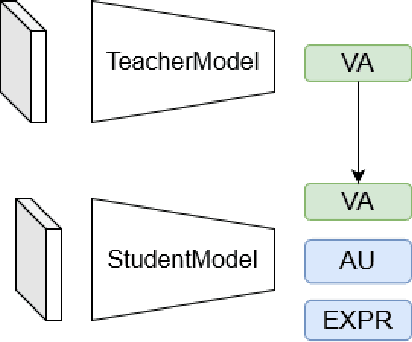
Affective Analysis is not a single task, and the valence-arousal value, expression class and action unit can be predicted at the same time. Previous researches failed to take them as a whole task or ignore the entanglement and hierarchical relation of this three facial attributes. We propose a novel model named feature pyramid networks for multi-task affect analysis. The hierarchical features are extracted to predict three labels and we apply teacher-student training strategy to learn from pretrained single-task models. Extensive experiment results demonstrate the proposed model outperform other models.This is a submission to The 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). The code and model are available for research purposes at https://github.com/ryanhe312/ABAW2-FPNMAA.
Self-Supervised Disentangled Representation Learning for Third-Person Imitation Learning
Aug 02, 2021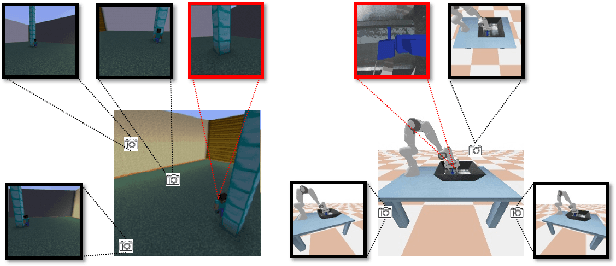
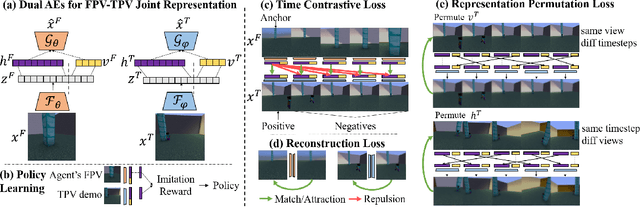
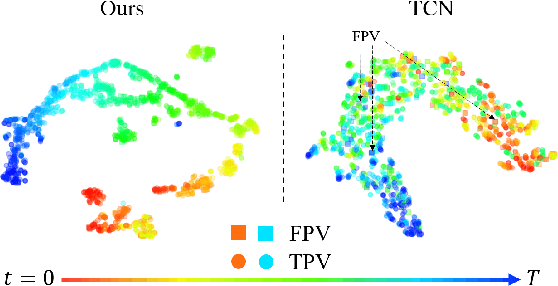
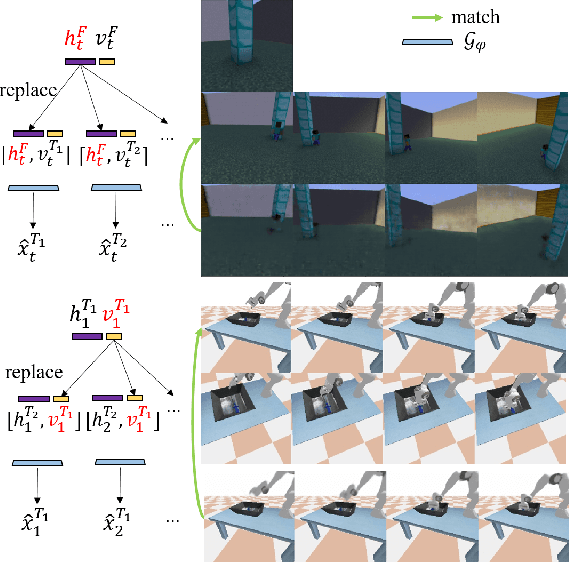
Humans learn to imitate by observing others. However, robot imitation learning generally requires expert demonstrations in the first-person view (FPV). Collecting such FPV videos for every robot could be very expensive. Third-person imitation learning (TPIL) is the concept of learning action policies by observing other agents in a third-person view (TPV), similar to what humans do. This ultimately allows utilizing human and robot demonstration videos in TPV from many different data sources, for the policy learning. In this paper, we present a TPIL approach for robot tasks with egomotion. Although many robot tasks with ground/aerial mobility often involve actions with camera egomotion, study on TPIL for such tasks has been limited. Here, FPV and TPV observations are visually very different; FPV shows egomotion while the agent appearance is only observable in TPV. To enable better state learning for TPIL, we propose our disentangled representation learning method. We use a dual auto-encoder structure plus representation permutation loss and time-contrastive loss to ensure the state and viewpoint representations are well disentangled. Our experiments show the effectiveness of our approach.
From Navigation to Racing: Reward Signal Design for Autonomous Racing
Mar 18, 2021
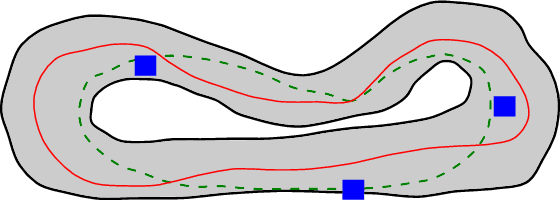
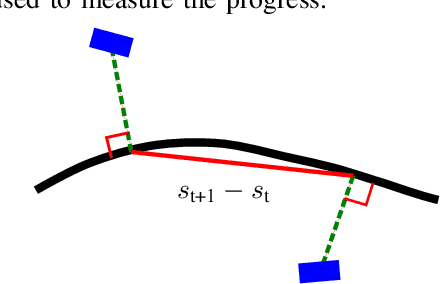
The problem of autonomous navigation is to generate a set of navigation references which when followed move the vehicle from a starting position to and end goal location while avoiding obstacles. Autonomous racing complicates the navigation problem by adding the objective of minimising the time to complete a track. Solutions aiming for a minimum time solution require that the planner is concerned with the optimality of the trajectory according to the vehicle dynamics. Neural networks, trained from experience with reinforcement learning, have shown to be effective local planners which generate navigation references to follow a global plan and avoid obstacles. We address the problem designing a reward signal which can be used to train neural network-based local planners to race in a time-efficient manner and avoid obstacles. The general challenge of reward signal design is to represent a desired behavior in an equation that can be calculated at each time step. The specific challenge of designing a reward signal for autonomous racing is to encode obstacle-free, time optimal racing trajectories in a clear signal We propose several methods of encoding ideal racing behavior based using a combination of the position and velocity of the vehicle and the actions taken by the network. The reward function candidates are expressed as equations and evaluated in the context of F1/10th autonomous racing. The results show that the best reward signal rewards velocity along, and punishes the lateral deviation from a precalculated, optimal reference trajectory.
Exploiting statistical dependencies of time series with hierarchical correlation reconstruction
Sep 11, 2018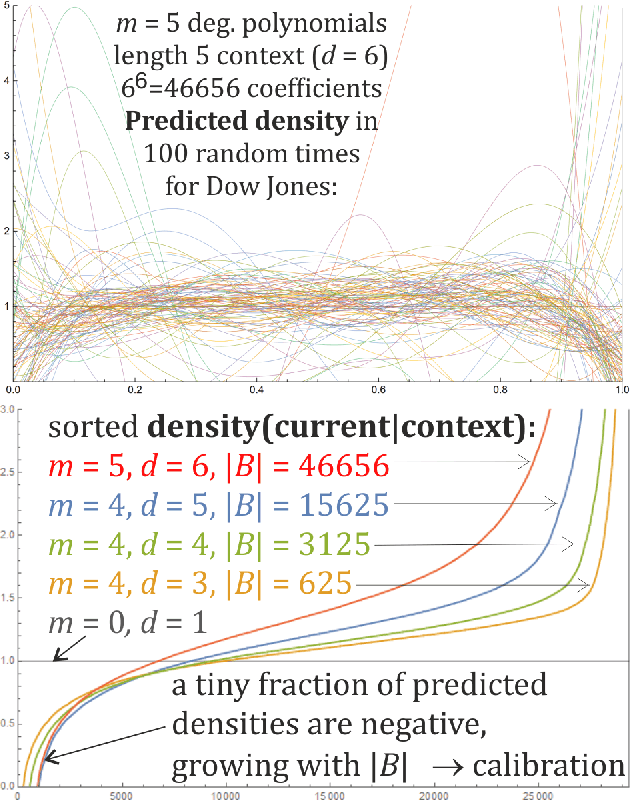
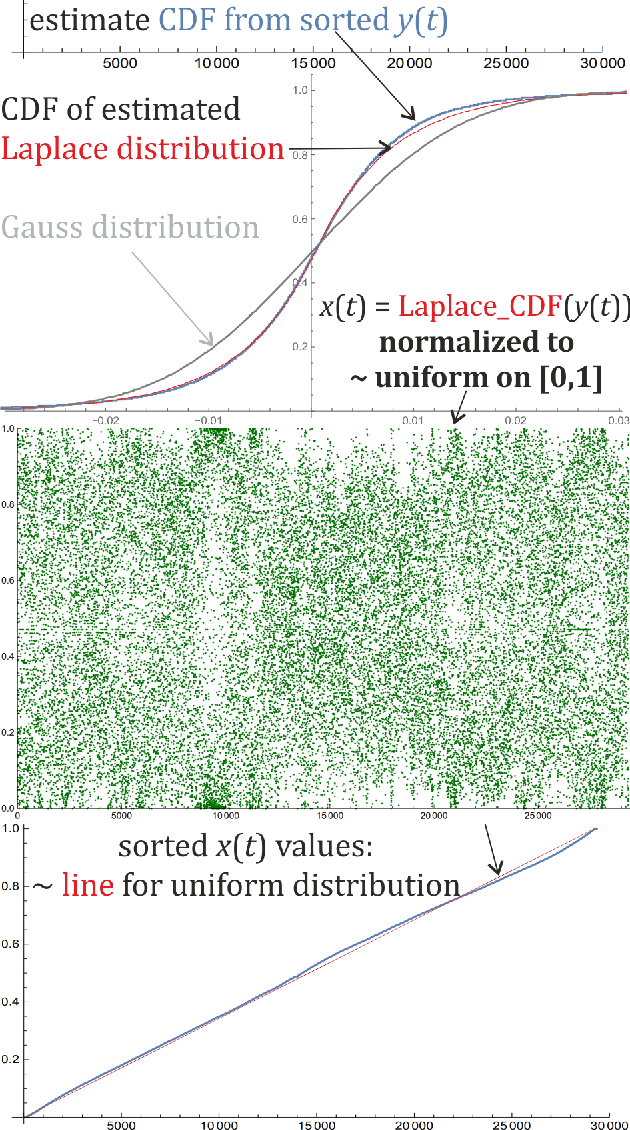
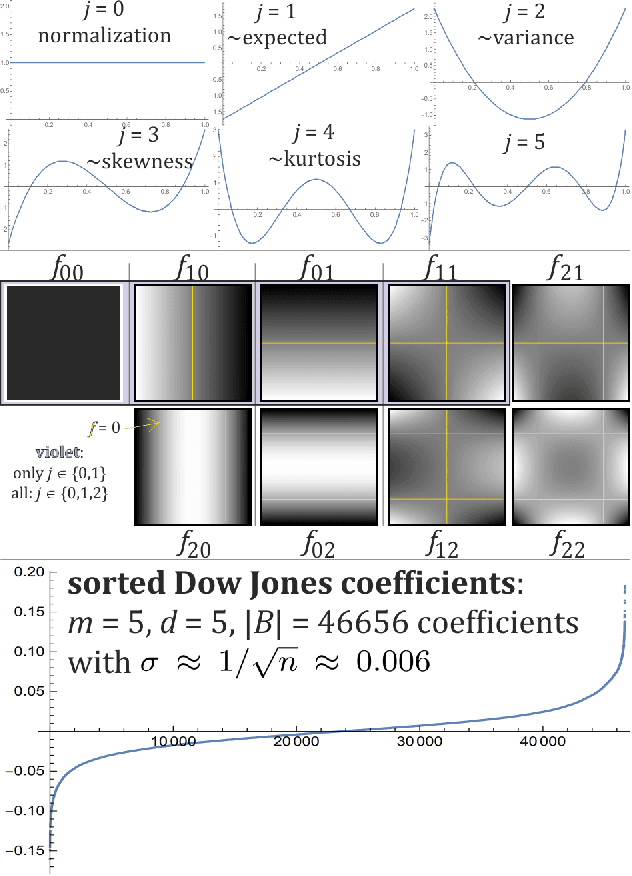
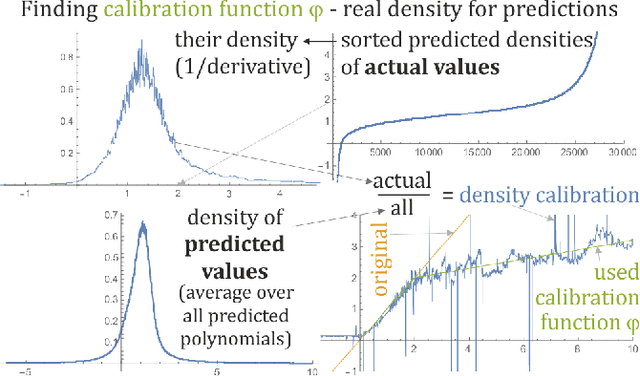
While we are usually focused on forecasting future values of time series, it is often valuable to additionally predict their entire probability distributions, e.g. to evaluate risk, Monte Carlo simulations. On example of time series of $\approx$ 30000 Dow Jones Industrial Averages, there will be presented application of hierarchical correlation reconstruction for this purpose: mean-square estimating polynomial as joint density for (current value, context), where context is for example a few previous values. Then substituting the currently observed context and normalizing density to 1, we get predicted probability distribution for the current value. In contrast to standard machine learning approaches like neural networks, optimal polynomial coefficients here can be inexpensively directly calculated, have controllable accuracy, are unique and independent, each has a specific cumulant-like interpretation, and such approximation using can approach complete description of any real joint distribution - providing a perfect tool to quantitatively describe and exploit statistical dependencies in time series. There is also discussed application for non-stationary time series like calculating linear time trend, or adapting coefficients to local statistical behavior.
Learning off-road maneuver plans for autonomous vehicles
Aug 02, 2021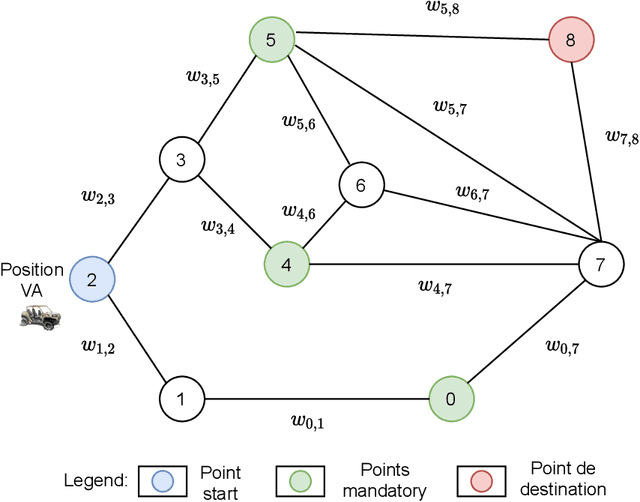


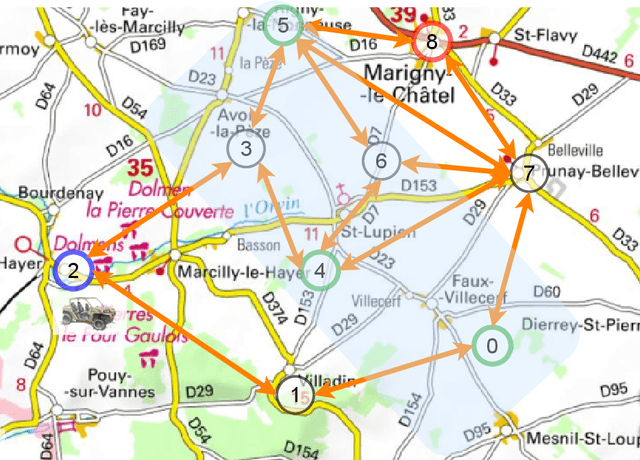
This thesis explores the benefits machine learning algorithms can bring to online planning and scheduling for autonomous vehicles in off-road situations. Mainly, we focus on typical problems of interest which include computing itineraries that meet certain objectives, as well as computing scheduling strategies to execute synchronized maneuvers with other vehicles. We present a range of learning-based heuristics to assist different itinerary planners. We show that these heuristics allow a significant increase in performance for optimal planners. Furthermore, in the case of approximate planning, we show that not only does the running time decrease, the quality of the itinerary found also becomes almost always better. Finally, in order to synthesize strategies to execute synchronized maneuvers, we propose a novel type of scheduling controllability and a learning-assisted algorithm. The proposed framework achieves significant improvement on known benchmarks in this controllability type over the performance of state-of-the-art works in a related controllability type. Moreover, it is able to find strategies on complex scheduling problems for which previous works fail to do so.
SOTR: Segmenting Objects with Transformers
Aug 15, 2021

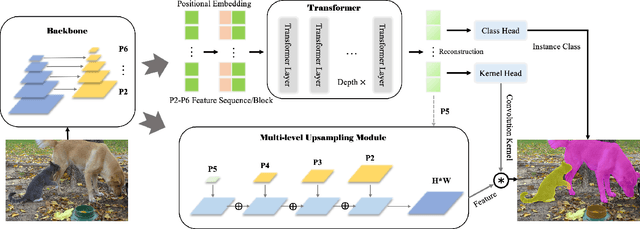
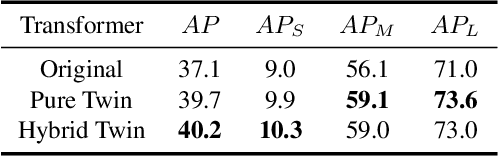
Most recent transformer-based models show impressive performance on vision tasks, even better than Convolution Neural Networks (CNN). In this work, we present a novel, flexible, and effective transformer-based model for high-quality instance segmentation. The proposed method, Segmenting Objects with TRansformers (SOTR), simplifies the segmentation pipeline, building on an alternative CNN backbone appended with two parallel subtasks: (1) predicting per-instance category via transformer and (2) dynamically generating segmentation mask with the multi-level upsampling module. SOTR can effectively extract lower-level feature representations and capture long-range context dependencies by Feature Pyramid Network (FPN) and twin transformer, respectively. Meanwhile, compared with the original transformer, the proposed twin transformer is time- and resource-efficient since only a row and a column attention are involved to encode pixels. Moreover, SOTR is easy to be incorporated with various CNN backbones and transformer model variants to make considerable improvements for the segmentation accuracy and training convergence. Extensive experiments show that our SOTR performs well on the MS COCO dataset and surpasses state-of-the-art instance segmentation approaches. We hope our simple but strong framework could serve as a preferment baseline for instance-level recognition. Our code is available at https://github.com/easton-cau/SOTR.
Multi-View TRGRU: Transformer based Spatiotemporal Model for Short-Term Metro Origin-Destination Matrix Prediction
Aug 09, 2021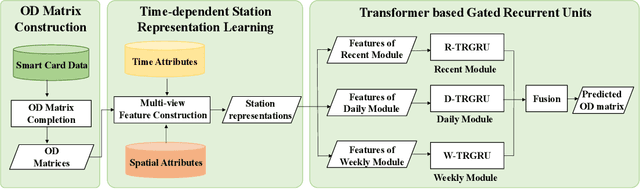
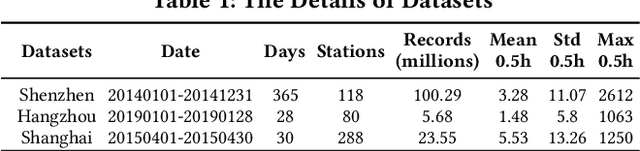

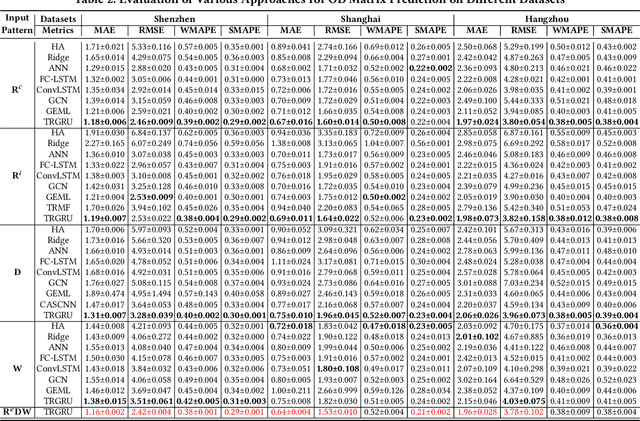
Accurate prediction of short-term OD Matrix (i.e. the distribution of passenger flows from various origins to destinations) is a crucial task in metro systems. It is highly challenging due to the constantly changing nature of many impacting factors and the real-time de- layed data collection problem. Recently, some deep learning-based models have been proposed for OD Matrix forecasting in ride- hailing and high way traffic scenarios. However, these models can not sufficiently capture the complex spatiotemporal correlation between stations in metro networks due to their different prior knowledge and contextual settings. In this paper we propose a hy- brid framework Multi-view TRGRU to address OD metro matrix prediction. In particular, it uses three modules to model three flow change patterns: recent trend, daily trend, weekly trend. In each module, a multi-view representation based on embedding for each station is constructed and fed into a transformer based gated re- current structure so as to capture the dynamic spatial dependency in OD flows of different stations by a global self-attention mecha- nism. Extensive experiments on three large-scale, real-world metro datasets demonstrate the superiority of our Multi-view TRGRU over other competitors.