 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multistep Electric Vehicle Charging Station Occupancy Prediction using Mixed LSTM Neural Networks
Jun 09, 2021
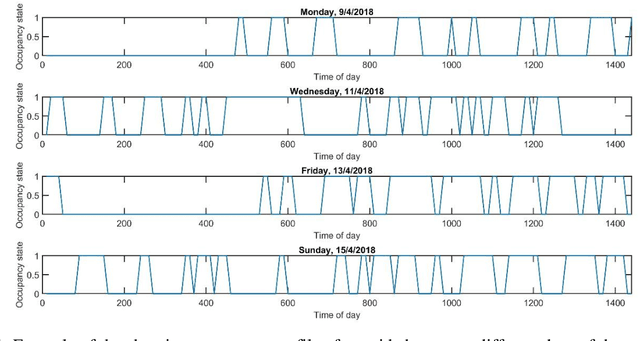
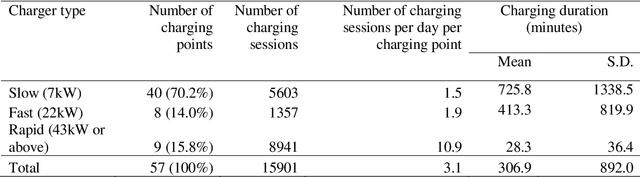
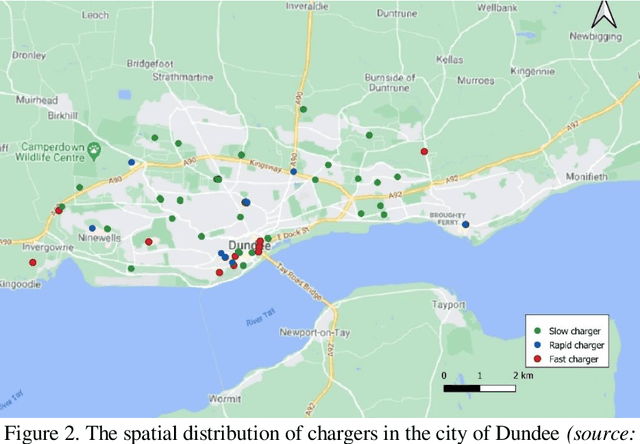

Public charging station occupancy prediction plays key importance in developing a smart charging strategy to reduce electric vehicle (EV) operator and user inconvenience. However, existing studies are mainly based on conventional econometric or time series methodologies with limited accuracy. We propose a new mixed long short-term memory neural network incorporating both historical charging state sequences and time-related features for multistep discrete charging occupancy state prediction. Unlike the existing LSTM networks, the proposed model separates different types of features and handles them differently with mixed neural network architecture. The model is compared to a number of state-of-the-art machine learning and deep learning approaches based on the EV charging data obtained from the open data portal of the city of Dundee, UK. The results show that the proposed method produces very accurate predictions (99.99% and 81.87% for 1 step (10 minutes) and 6 step (1 hour) ahead, respectively, and outperforms the benchmark approaches significantly (+22.4% for one-step-ahead prediction and +6.2% for 6 steps ahead). A sensitivity analysis is conducted to evaluate the impact of the model parameters on prediction accuracy.
Feature Pyramid Network for Multi-task Affective Analysis
Jul 19, 2021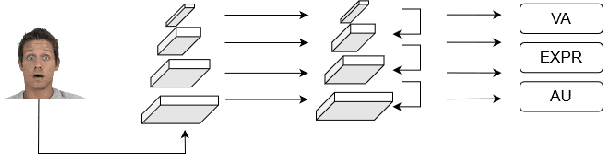
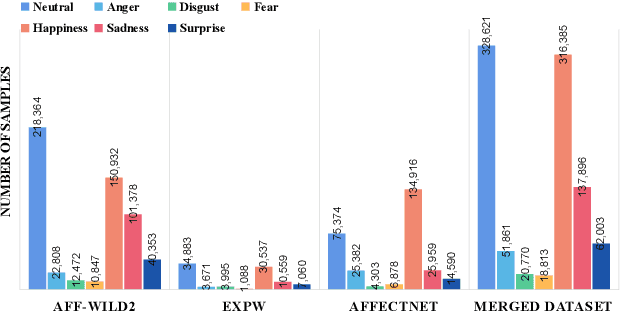
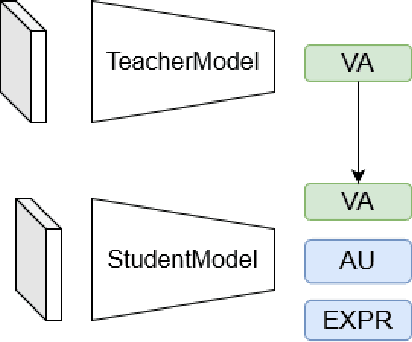
Affective Analysis is not a single task, and the valence-arousal value, expression class, and action unit can be predicted at the same time. Previous researches did not pay enough attention to the entanglement and hierarchical relation of these three facial attributes. We propose a novel model named feature pyramid networks for multi-task affect analysis. The hierarchical features are extracted to predict three labels and we apply a teacher-student training strategy to learn from pretrained single-task models. Extensive experiment results demonstrate the proposed model outperforms other models. This is a submission to The 2nd Workshop and Competition on Affective Behavior Analysis in the wild (ABAW). The code and model are available for research purposes at https://github.com/ryanhe312/ABAW2-FPNMAA.
Zygarde: Time-Sensitive On-Device Deep Intelligence on Intermittently-Powered Systems
May 05, 2019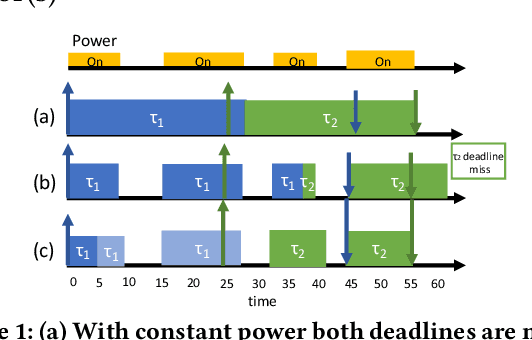
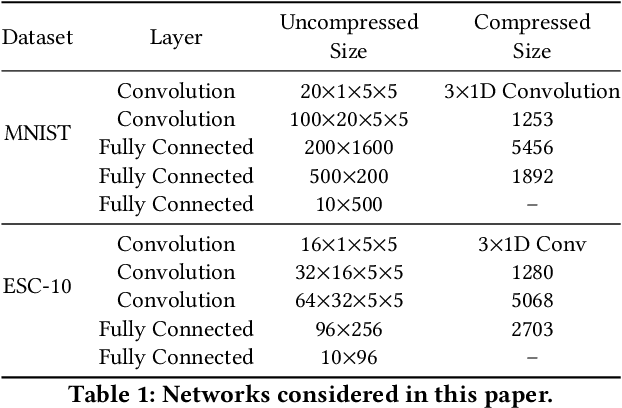
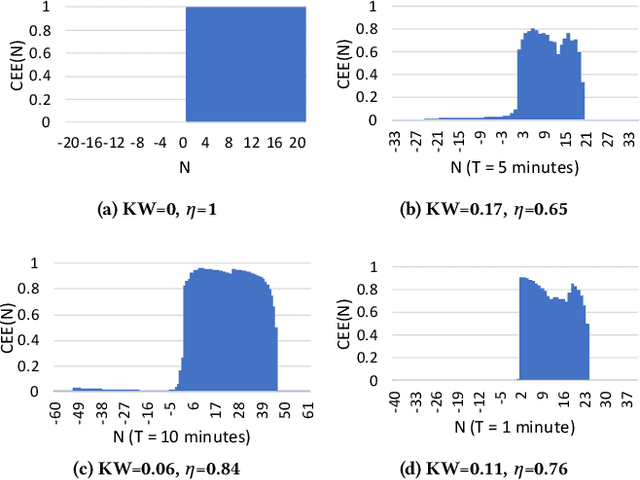
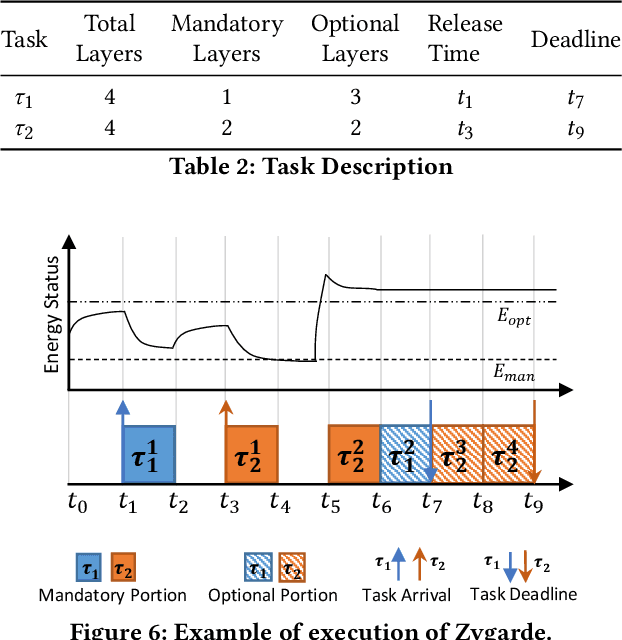
In this paper, we propose a time-, energy-, and accuracy-aware scheduling algorithm for intermittently powered systems that execute compressed deep learning tasks that are suitable for MCUs and are powered solely by harvested energy. The sporadic nature of harvested energy, resource constraints of the embedded platform, and the computational demand of deep neural networks (even though compressed) pose a unique and challenging real-time scheduling problem for which no solutions have been proposed in the literature. We empirically study the problem and model the energy harvesting pattern as well as the trade-off between the accuracy and execution of a deep neural network. We develop an imprecise computing-based scheduling algorithm that improves the schedulability of deep learning tasks on intermittently powered systems. We also utilize the dependency of the computational need of data samples for deep learning models and propose early termination of deep neural networks. We further propose a semi-supervised machine learning model that exploits the deep features and contributes in determining the imprecise partition of a task. We implement our proposed algorithms on two different datasets and real-life scenarios and show that it increases the accuracy by 9.45% - 3.19%, decreases the execution time by 14\% and successfully schedules 33%-12% more tasks.
Self-supervised Contrastive Learning for Irrigation Detection in Satellite Imagery
Aug 12, 2021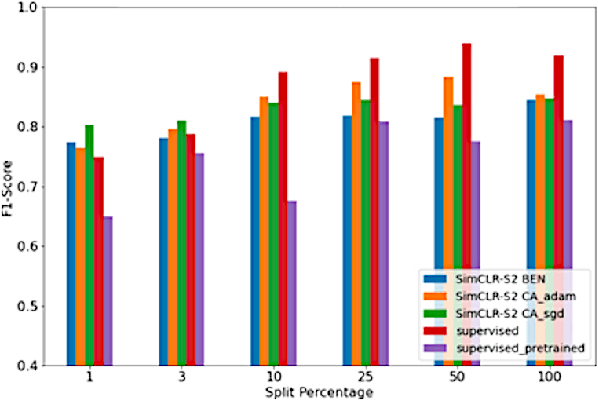
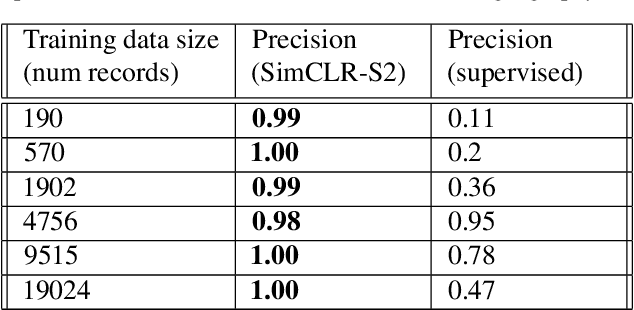
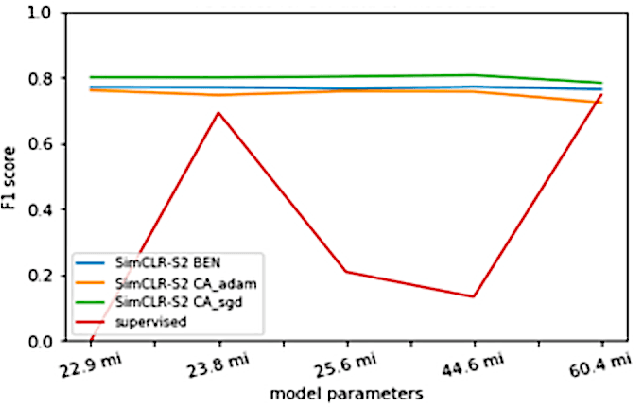
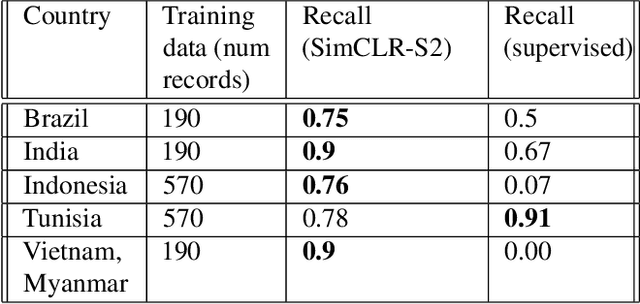
Climate change has caused reductions in river runoffs and aquifer recharge resulting in an increasingly unsustainable crop water demand from reduced freshwater availability. Achieving food security while deploying water in a sustainable manner will continue to be a major challenge necessitating careful monitoring and tracking of agricultural water usage. Historically, monitoring water usage has been a slow and expensive manual process with many imperfections and abuses. Ma-chine learning and remote sensing developments have increased the ability to automatically monitor irrigation patterns, but existing techniques often require curated and labelled irrigation data, which are expensive and time consuming to obtain and may not exist for impactful areas such as developing countries. In this paper, we explore an end-to-end real world application of irrigation detection with uncurated and unlabeled satellite imagery. We apply state-of-the-art self-supervised deep learning techniques to optical remote sensing data, and find that we are able to detect irrigation with up to nine times better precision, 90% better recall and 40% more generalization ability than the traditional supervised learning methods.
Prior-Guided Deep Interference Mitigation for FMCW Radars
Aug 30, 2021
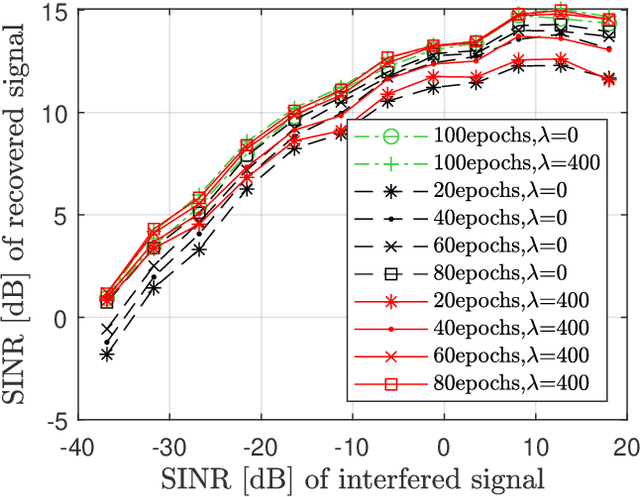
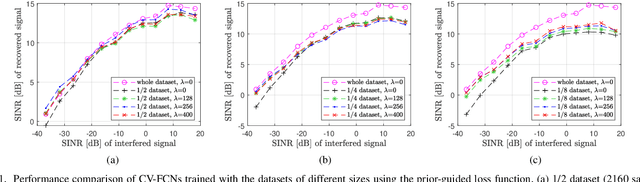
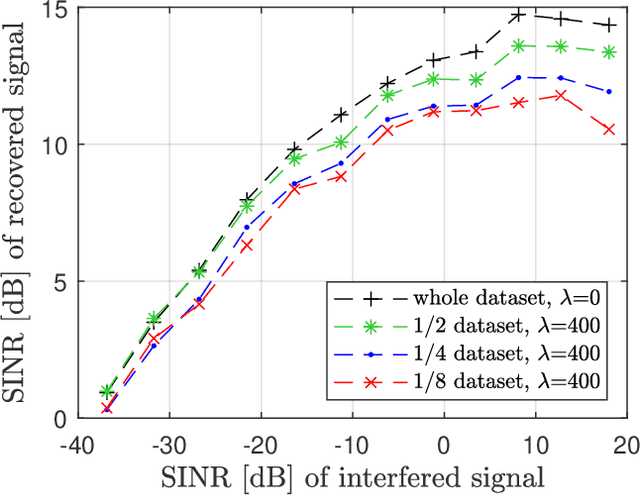
A prior-guided deep learning (DL) based interference mitigation approach is proposed for frequency modulated continuous wave (FMCW) radars. In this paper, the interference mitigation problem is tackled as a regression problem. Considering the complex-valued nature of radar signals, the complex-valued convolutional neural network is utilized as an architecture for implementation, which is different from the conventional real-valued counterparts. Meanwhile, as the useful beat signals of FMCW radars and interferences exhibit different distributions in the time-frequency domain, this prior feature is exploited as a regularization term to avoid overfitting of the learned representation. The effectiveness and accuracy of our proposed complex-valued fully convolutional network (CV-FCN) based interference mitigation approach are verified and analyzed through both simulated and measured radar signals. Compared to the real-valued counterparts, the CV-FCN shows a better interference mitigation performance with a potential of half memory reduction in low Signal to Interference plus Noise Ratio (SINR) scenarios. Moreover, the CV-FCN trained using only simulated data can be directly utilized for interference mitigation in various measured radar signals and shows a superior generalization capability. Furthermore, by incorporating the prior feature, the CV-FCN trained on only 1/8 of the full data achieves comparable performance as that on the full dataset in low SINR scenarios, and the training procedure converges faster.
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
Aug 24, 2021
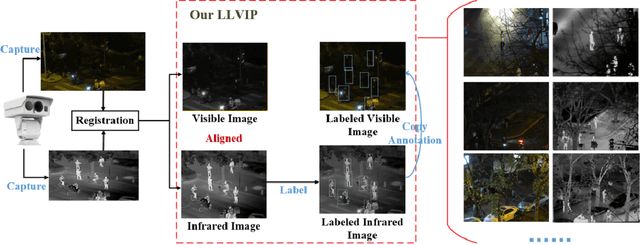
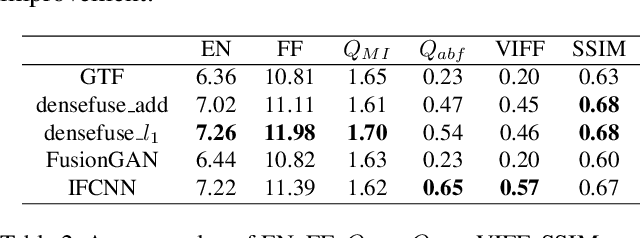

It is very challenging for various visual tasks such as image fusion, pedestrian detection and image-to-image translation in low light conditions due to the loss of effective target areas. In this case, infrared and visible images can be used together to provide both rich detail information and effective target areas. In this paper, we present LLVIP, a visible-infrared paired dataset for low-light vision. This dataset contains 33672 images, or 16836 pairs, most of which were taken at very dark scenes, and all of the images are strictly aligned in time and space. Pedestrians in the dataset are labeled. We compare the dataset with other visible-infrared datasets and evaluate the performance of some popular visual algorithms including image fusion, pedestrian detection and image-to-image translation on the dataset. The experimental results demonstrate the complementary effect of fusion on image information, and find the deficiency of existing algorithms of the three visual tasks in very low-light conditions. We believe the LLVIP dataset will contribute to the community of computer vision by promoting image fusion, pedestrian detection and image-to-image translation in very low-light applications. The dataset is being released in https://bupt-ai-cz.github.io/LLVIP.
Knowledge Triggering, Extraction and Storage via Human-Robot Verbal Interaction
Apr 22, 2021
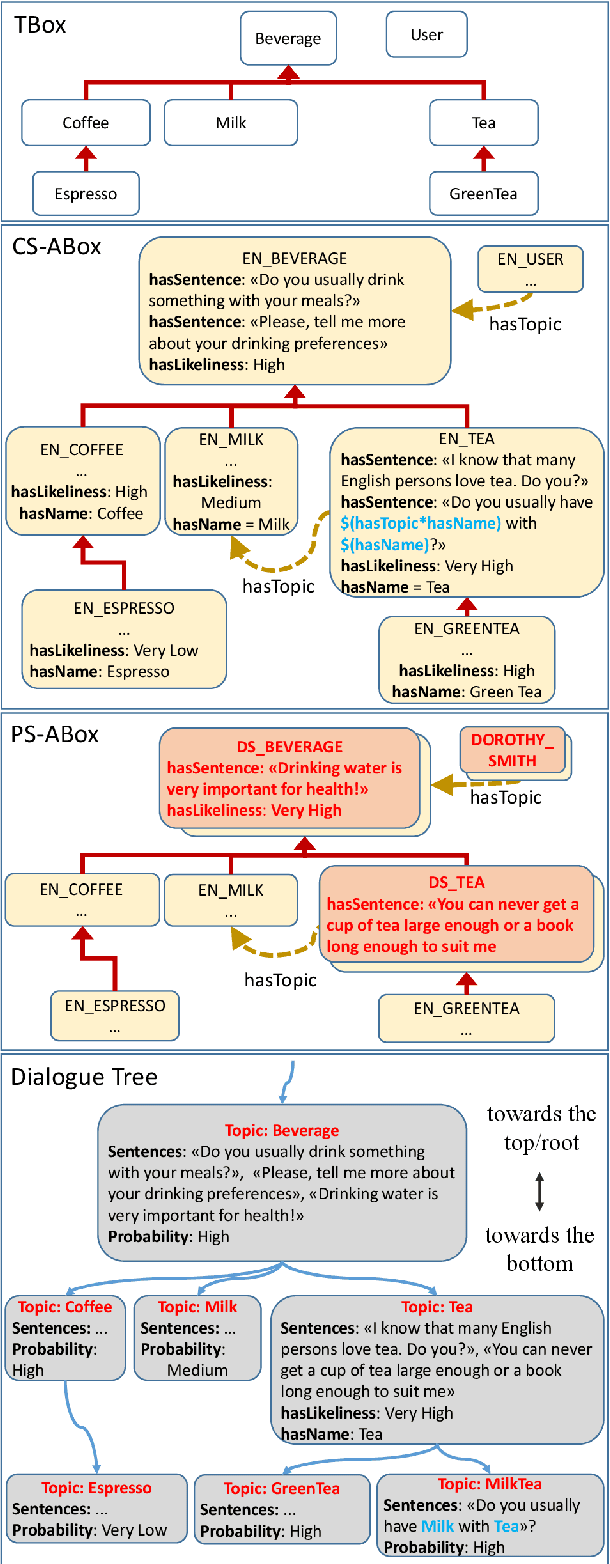
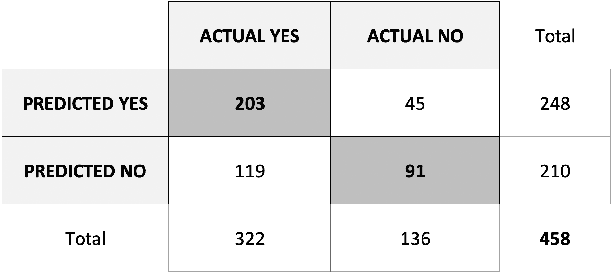
This article describes a novel approach to expand in run-time the knowledge base of an Artificial Conversational Agent. A technique for automatic knowledge extraction from the user's sentence and four methods to insert the new acquired concepts in the knowledge base have been developed and integrated into a system that has already been tested for knowledge-based conversation between a social humanoid robot and residents of care homes. The run-time addition of new knowledge allows overcoming some limitations that affect most robots and chatbots: the incapability of engaging the user for a long time due to the restricted number of conversation topics. The insertion in the knowledge base of new concepts recognized in the user's sentence is expected to result in a wider range of topics that can be covered during an interaction, making the conversation less repetitive. Two experiments are presented to assess the performance of the knowledge extraction technique, and the efficiency of the developed insertion methods when adding several concepts in the Ontology.
Unifying Probabilistic Models for Time-Frequency Analysis
Nov 06, 2018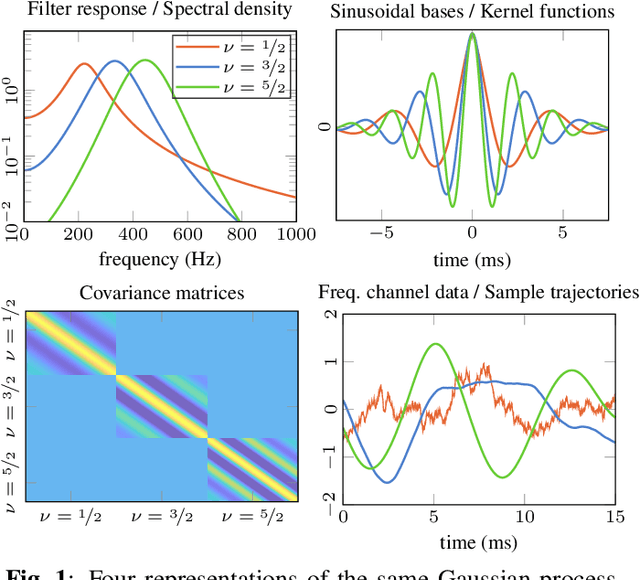
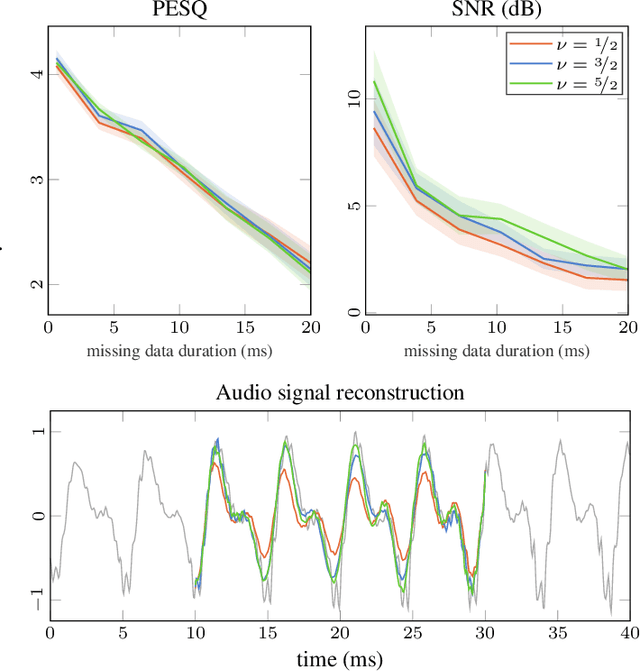
In audio signal processing, probabilistic time-frequency models have many benefits over their non-probabilistic counterparts. They adapt to the incoming signal, quantify uncertainty, and measure correlation between the signal's amplitude and phase information, making time domain resynthesis straightforward. However, these models are still not widely used since they come at a high computational cost, and because they are formulated in such a way that it can be difficult to interpret all the modelling assumptions. By showing their equivalence to Spectral Mixture Gaussian processes, we illuminate the underlying model assumptions and provide a general framework for constructing more complex models that better approximate real-world signals. Our interpretation makes it intuitive to inspect, compare, and alter the models since all prior knowledge is encoded in the Gaussian process kernel functions. We utilise a state space representation to perform efficient inference via Kalman smoothing, and we demonstrate how our interpretation allows for efficient parameter learning in the frequency domain.
Fake News and Phishing Detection Using a Machine Learning Trained Expert System
Aug 04, 2021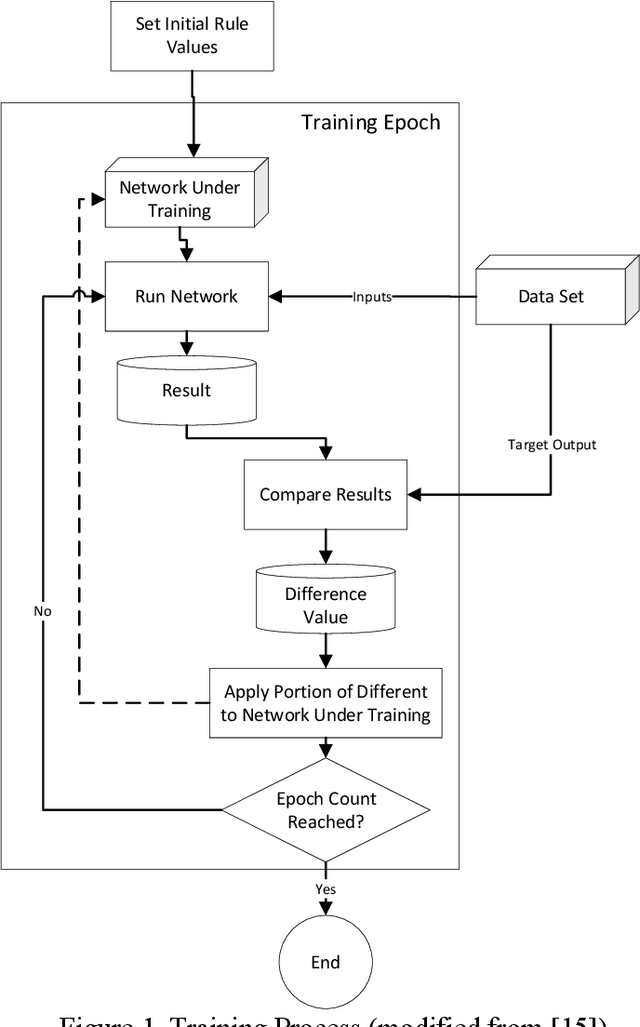
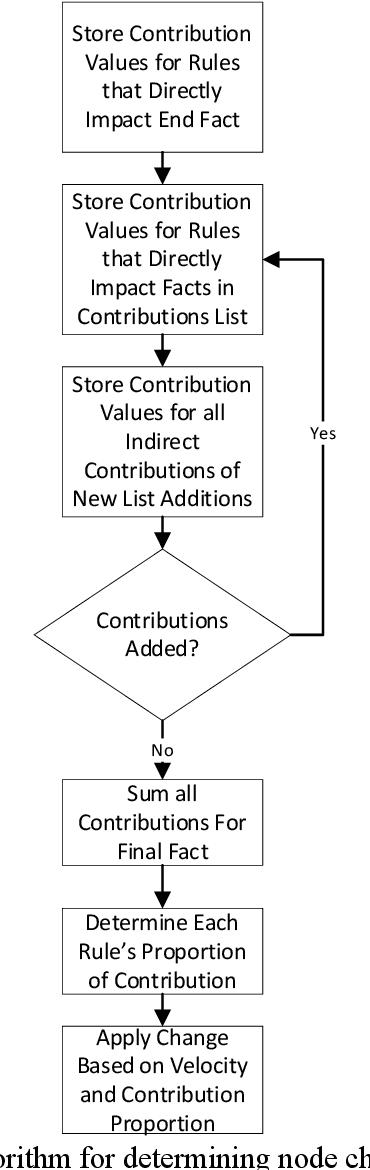

Expert systems have been used to enable computers to make recommendations and decisions. This paper presents the use of a machine learning trained expert system (MLES) for phishing site detection and fake news detection. Both topics share a similar goal: to design a rule-fact network that allows a computer to make explainable decisions like domain experts in each respective area. The phishing website detection study uses a MLES to detect potential phishing websites by analyzing site properties (like URL length and expiration time). The fake news detection study uses a MLES rule-fact network to gauge news story truthfulness based on factors such as emotion, the speaker's political affiliation status, and job. The two studies use different MLES network implementations, which are presented and compared herein. The fake news study utilized a more linear design while the phishing project utilized a more complex connection structure. Both networks' inputs are based on commonly available data sets.
Stimuli-Aware Visual Emotion Analysis
Sep 04, 2021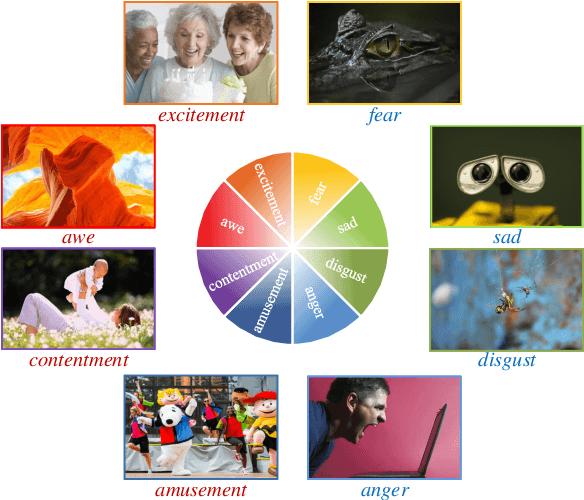
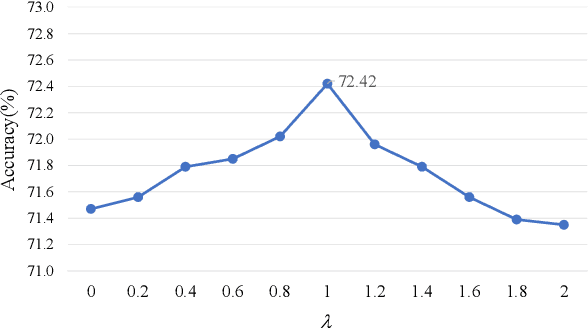
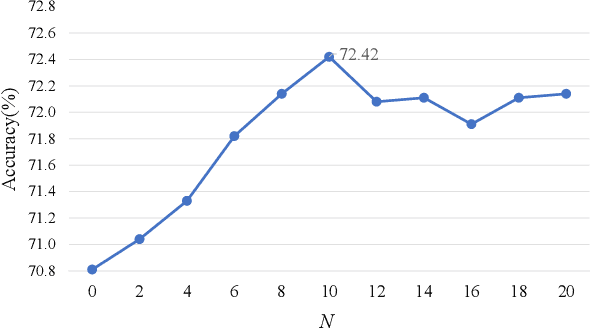

Visual emotion analysis (VEA) has attracted great attention recently, due to the increasing tendency of expressing and understanding emotions through images on social networks. Different from traditional vision tasks, VEA is inherently more challenging since it involves a much higher level of complexity and ambiguity in human cognitive process. Most of the existing methods adopt deep learning techniques to extract general features from the whole image, disregarding the specific features evoked by various emotional stimuli. Inspired by the \textit{Stimuli-Organism-Response (S-O-R)} emotion model in psychological theory, we proposed a stimuli-aware VEA method consisting of three stages, namely stimuli selection (S), feature extraction (O) and emotion prediction (R). First, specific emotional stimuli (i.e., color, object, face) are selected from images by employing the off-the-shelf tools. To the best of our knowledge, it is the first time to introduce stimuli selection process into VEA in an end-to-end network. Then, we design three specific networks, i.e., Global-Net, Semantic-Net and Expression-Net, to extract distinct emotional features from different stimuli simultaneously. Finally, benefiting from the inherent structure of Mikel's wheel, we design a novel hierarchical cross-entropy loss to distinguish hard false examples from easy ones in an emotion-specific manner. Experiments demonstrate that the proposed method consistently outperforms the state-of-the-art approaches on four public visual emotion datasets. Ablation study and visualizations further prove the validity and interpretability of our method.
* Accepted by TIP