 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tuning Mixed Input Hyperparameters on the Fly for Efficient Population Based AutoRL
Jun 30, 2021

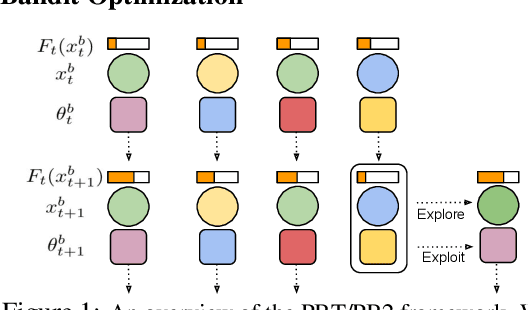
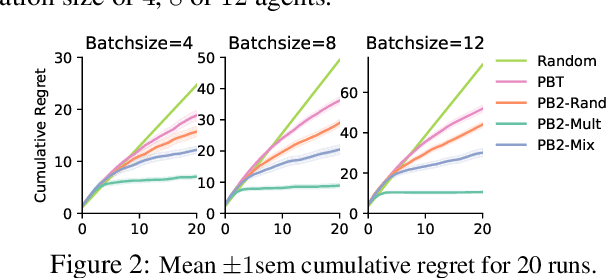
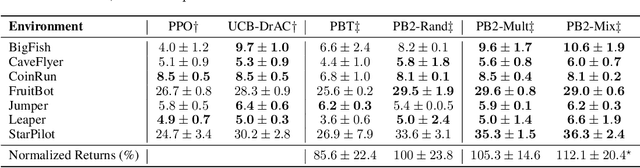
Despite a series of recent successes in reinforcement learning (RL), many RL algorithms remain sensitive to hyperparameters. As such, there has recently been interest in the field of AutoRL, which seeks to automate design decisions to create more general algorithms. Recent work suggests that population based approaches may be effective AutoRL algorithms, by learning hyperparameter schedules on the fly. In particular, the PB2 algorithm is able to achieve strong performance in RL tasks by formulating online hyperparameter optimization as time varying GP-bandit problem, while also providing theoretical guarantees. However, PB2 is only designed to work for continuous hyperparameters, which severely limits its utility in practice. In this paper we introduce a new (provably) efficient hierarchical approach for optimizing both continuous and categorical variables, using a new time-varying bandit algorithm specifically designed for the population based training regime. We evaluate our approach on the challenging Procgen benchmark, where we show that explicitly modelling dependence between data augmentation and other hyperparameters improves generalization.
Graph-based Approximate Message Passing Iterations
Sep 24, 2021Approximate-message passing (AMP) algorithms have become an important element of high-dimensional statistical inference, mostly due to their adaptability and concentration properties, the state evolution (SE) equations. This is demonstrated by the growing number of new iterations proposed for increasingly complex problems, ranging from multi-layer inference to low-rank matrix estimation with elaborate priors. In this paper, we address the following questions: is there a structure underlying all AMP iterations that unifies them in a common framework? Can we use such a structure to give a modular proof of state evolution equations, adaptable to new AMP iterations without reproducing each time the full argument ? We propose an answer to both questions, showing that AMP instances can be generically indexed by an oriented graph. This enables to give a unified interpretation of these iterations, independent from the problem they solve, and a way of composing them arbitrarily. We then show that all AMP iterations indexed by such a graph admit rigorous SE equations, extending the reach of previous proofs, and proving a number of recent heuristic derivations of those equations. Our proof naturally includes non-separable functions and we show how existing refinements, such as spatial coupling or matrix-valued variables, can be combined with our framework.
Dual Aspect Self-Attention based on Transformer for Remaining Useful Life Prediction
Jun 30, 2021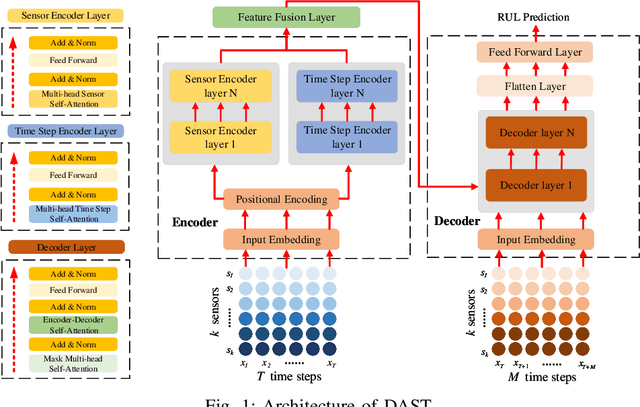
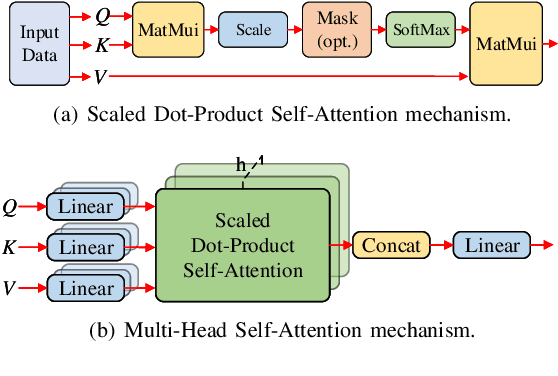
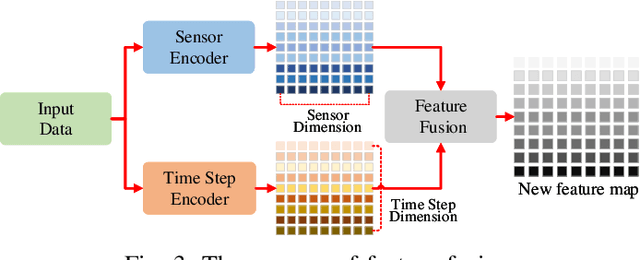
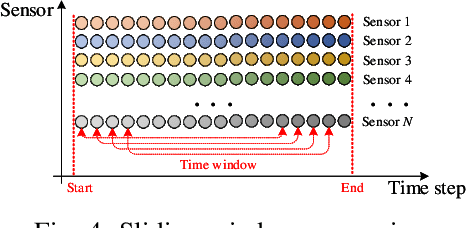
Remaining useful life prediction (RUL) is one of the key technologies of condition-based maintenance, which is important to maintain the reliability and safety of industrial equipments. While deep learning has achieved great success in RUL prediction, existing methods have difficulties in processing long sequences and extracting information from the sensor and time step aspects. In this paper, we propose Dual Aspect Self-attention based on Transformer (DAST), a novel deep RUL prediction method. DAST consists of two encoders, which work in parallel to simultaneously extract features of different sensors and time steps. Solely based on self-attention, the DAST encoders are more effective in processing long data sequences, and are capable of adaptively learning to focus on more important parts of input. Moreover, the parallel feature extraction design avoids mutual influence of information from two aspects. Experimental results on two real turbofan engine datasets show that our method significantly outperforms state-of-the-art methods.
Complex Temporal Question Answering on Knowledge Graphs
Sep 18, 2021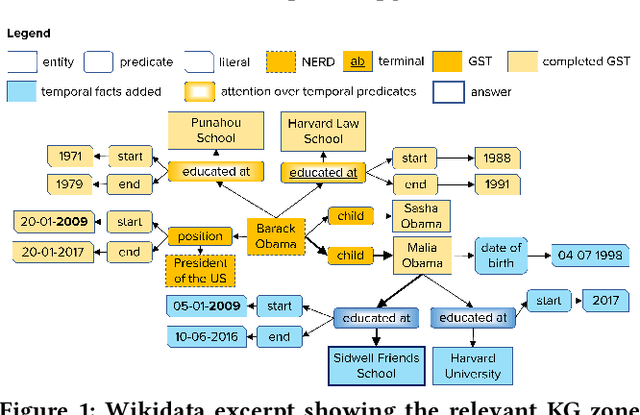

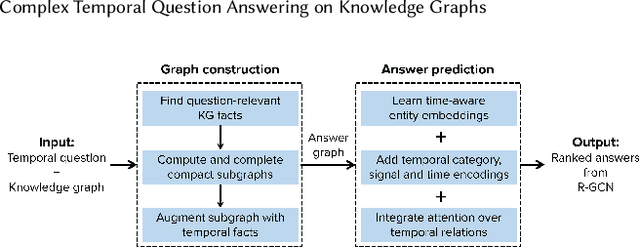
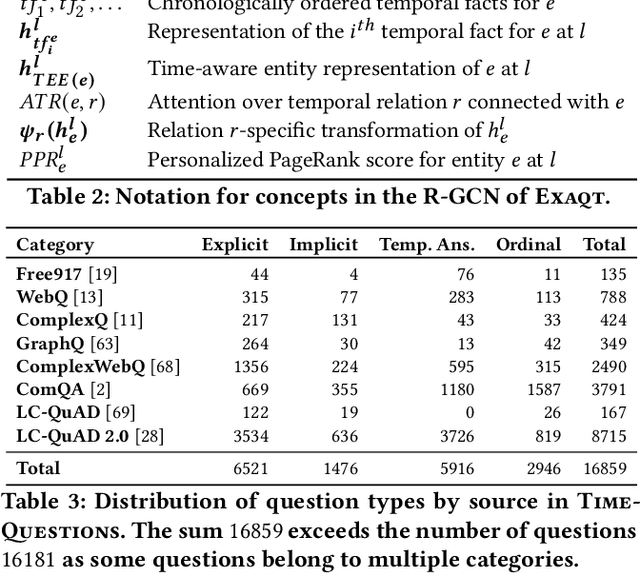
Question answering over knowledge graphs (KG-QA) is a vital topic in IR. Questions with temporal intent are a special class of practical importance, but have not received much attention in research. This work presents EXAQT, the first end-to-end system for answering complex temporal questions that have multiple entities and predicates, and associated temporal conditions. EXAQT answers natural language questions over KGs in two stages, one geared towards high recall, the other towards precision at top ranks. The first step computes question-relevant compact subgraphs within the KG, and judiciously enhances them with pertinent temporal facts, using Group Steiner Trees and fine-tuned BERT models. The second step constructs relational graph convolutional networks (R-GCNs) from the first step's output, and enhances the R-GCNs with time-aware entity embeddings and attention over temporal relations. We evaluate EXAQT on TimeQuestions, a large dataset of 16k temporal questions we compiled from a variety of general purpose KG-QA benchmarks. Results show that EXAQT outperforms three state-of-the-art systems for answering complex questions over KGs, thereby justifying specialized treatment of temporal QA.
Causality and Generalizability: Identifiability and Learning Methods
Oct 04, 2021This PhD thesis contains several contributions to the field of statistical causal modeling. Statistical causal models are statistical models embedded with causal assumptions that allow for the inference and reasoning about the behavior of stochastic systems affected by external manipulation (interventions). This thesis contributes to the research areas concerning the estimation of causal effects, causal structure learning, and distributionally robust (out-of-distribution generalizing) prediction methods. We present novel and consistent linear and non-linear causal effects estimators in instrumental variable settings that employ data-dependent mean squared prediction error regularization. Our proposed estimators show, in certain settings, mean squared error improvements compared to both canonical and state-of-the-art estimators. We show that recent research on distributionally robust prediction methods has connections to well-studied estimators from econometrics. This connection leads us to prove that general K-class estimators possess distributional robustness properties. We, furthermore, propose a general framework for distributional robustness with respect to intervention-induced distributions. In this framework, we derive sufficient conditions for the identifiability of distributionally robust prediction methods and present impossibility results that show the necessity of several of these conditions. We present a new structure learning method applicable in additive noise models with directed trees as causal graphs. We prove consistency in a vanishing identifiability setup and provide a method for testing substructure hypotheses with asymptotic family-wise error control that remains valid post-selection. Finally, we present heuristic ideas for learning summary graphs of nonlinear time-series models.
Time-Continuous Energy-Conservation Neural Network for Structural Dynamics Analysis
Dec 16, 2020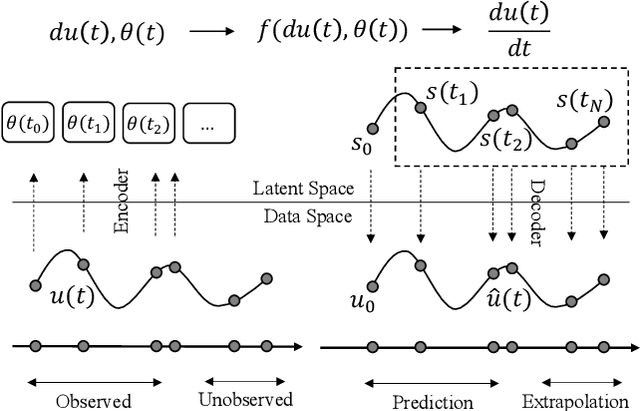
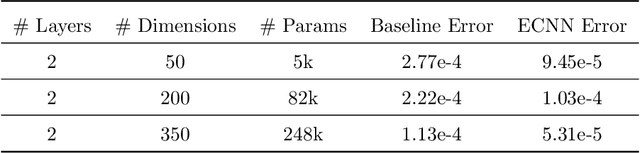
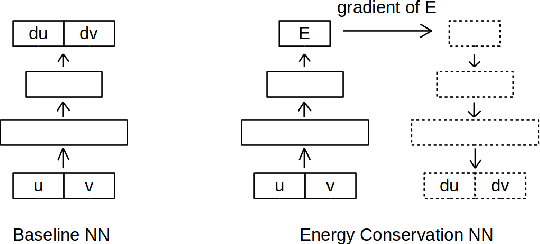
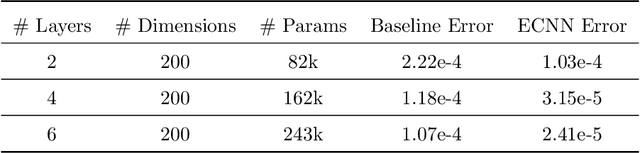
Fast and accurate structural dynamics analysis is important for structural design and damage assessment. Structural dynamics analysis leveraging machine learning techniques has become a popular research focus in recent years. Although the basic neural network provides an alternative approach for structural dynamics analysis, the lack of physics law inside the neural network limits the model accuracy and fidelity. In this paper, a new family of the energy-conservation neural network is introduced, which respects the physical laws. The neural network is explored from a fundamental single-degree-of-freedom system to a complicated multiple-degrees-of-freedom system. The damping force and external forces are also considered step by step. To improve the parallelization of the algorithm, the derivatives of the structural states are parameterized with the novel energy-conservation neural network instead of specifying the discrete sequence of structural states. The proposed model uses the system energy as the last layer of the neural network and leverages the underlying automatic differentiation graph to incorporate the system energy naturally, which ultimately improves the accuracy and long-term stability of structures dynamics response calculation under an earthquake impact. The trade-off between computation accuracy and speed is discussed. As a case study, a 3-story building earthquake simulation is conducted with realistic earthquake records.
PLEX: Towards Practical Learned Indexing
Aug 11, 2021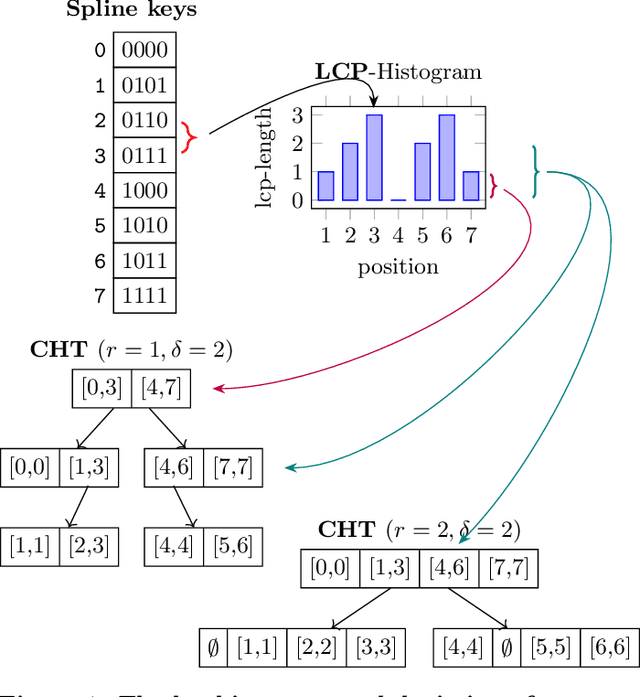
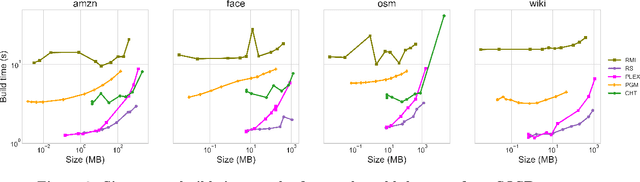
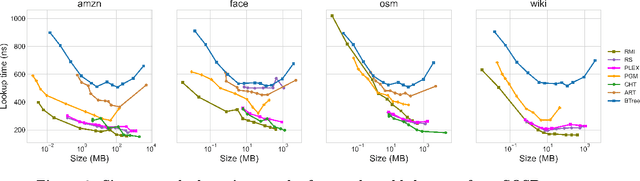
Latest research proposes to replace existing index structures with learned models. However, current learned indexes tend to have many hyperparameters, often do not provide any error guarantees, and are expensive to build. We introduce Practical Learned Index (PLEX). PLEX only has a single hyperparameter $\epsilon$ (maximum prediction error) and offers a better trade-off between build and lookup time than state-of-the-art approaches. Similar to RadixSpline, PLEX consists of a spline and a (multi-level) radix layer. It first builds a spline satisfying the given $\epsilon$ and then performs an ad-hoc analysis of the distribution of spline points to quickly tune the radix layer.
SMS: An Efficient Source Model Selection Framework for Model Reuse
Oct 13, 2021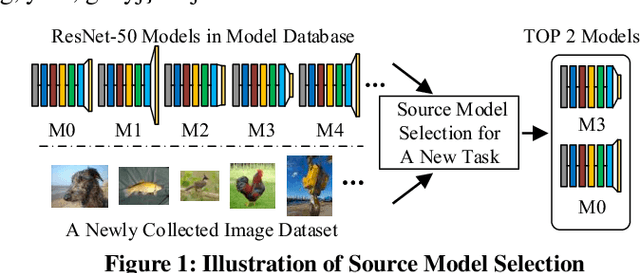
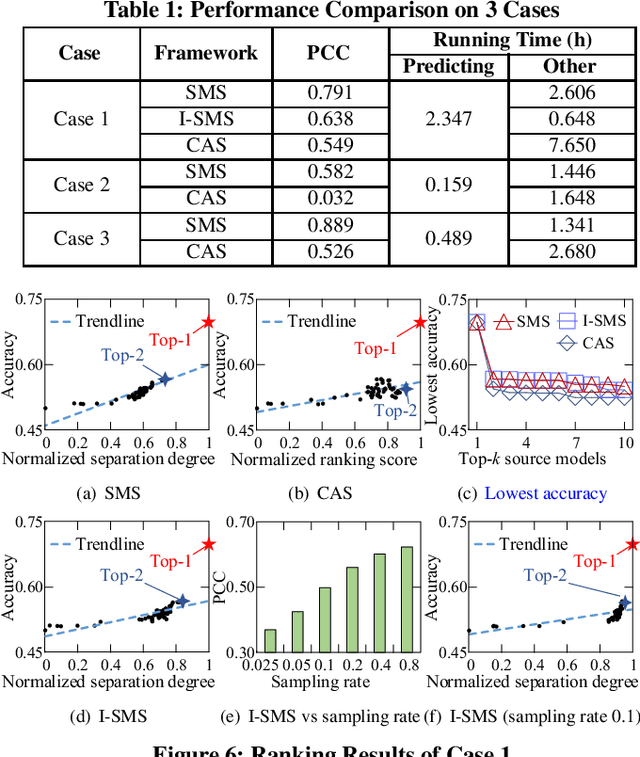

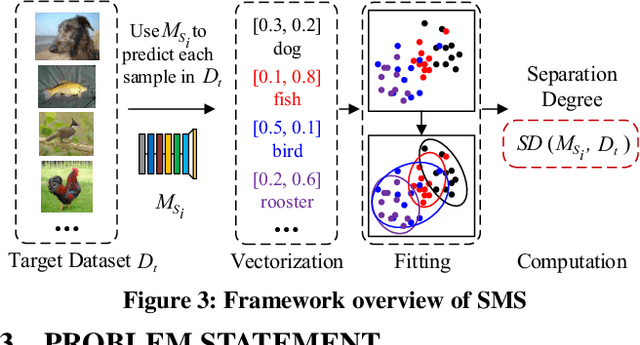
With the explosive increase of big data, training a Machine Learning (ML) model becomes a computation-intensive workload, which would take days or even weeks. Thus, model reuse has received attention in the ML community, where it is called transfer learning. Transfer learning avoids training a new model from scratch by transferring knowledge from a source task to a target task. Existing transfer learning methods mostly focus on how to improve the performance of the target task through a specific source model, but assume that the source model is given. As many source models are available, it is difficult for data scientists to select the best source model for the target task manually. Hence, how to efficiently select a suitable source model for model reuse is still an unsolved problem. In this paper, we propose SMS, an effective, efficient and flexible source model selection framework. SMS is effective even when source and target datasets have significantly different data labels, is flexible to support source models with any type of structure, and is efficient to avoid any training process. For each source model, SMS first vectorizes the samples in the target dataset into soft labels by directly applying this model to the target dataset, then uses Gaussian distributions to fit the clusters of soft labels, and finally measures its distinguishing ability using Gaussian mixture-based metric. Moreover, we present an improved SMS (I-SMS), which decreases the output number of source model. I-SMS can significantly reduce the selection time while retaining the selection performance of SMS. Extensive experiments on a range of practical model reuse workloads demonstrate the effectiveness and efficiency of SMS.
Interior point search for nonparametric image segmentation
Jun 11, 2021
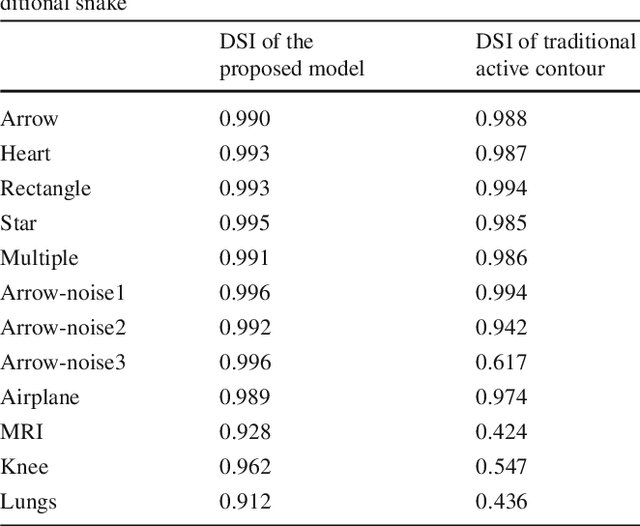
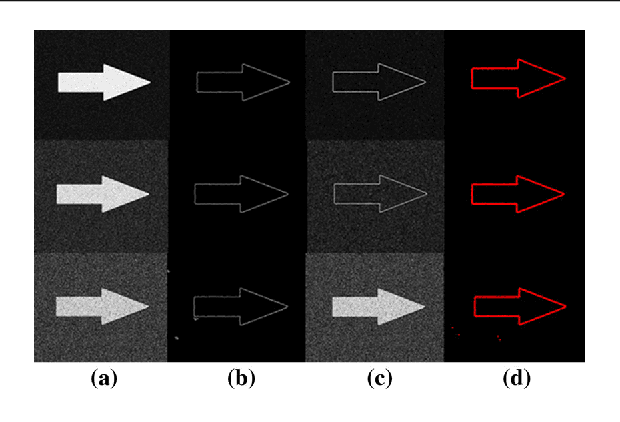
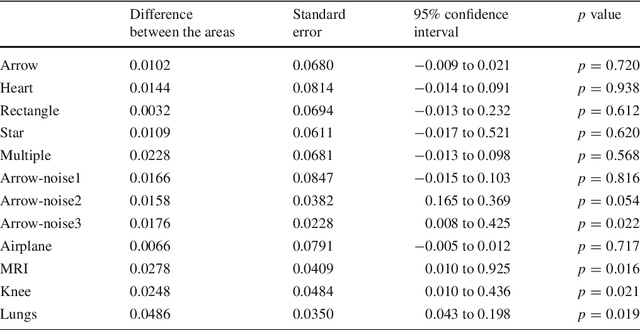
Precise object boundary detection for automatic image segmentation is critical for image analysis, including that used in computer-aided diagnosis. However, such detection traditionally uses active contour or snake models requiring accurate initialization and parameter optimization. Identifying optimal parameter values requires time-consuming multiple runs and provides results that vary by user expertise, limiting the use of these models in high-throughput or real-time situations. Thus, we developed a nonparametric snake model using an interior point search method applied in iterations to find and improve the set of snake points forming the edge of a shape. At each iteration, one or more snake points are replaced by others in the edge map. We validated the model using binary and continuous edge images of single and multiple objects, and noisy and real images, comparing the results to those obtained using traditional snake models. The proposed model not only provides better results on all image types tested but is more robust than traditional snake models. Unlike traditional snake models, the proposed model requires no user interaction for initializing snakes and no pre-processing of noisy images. Thus, our method offers robust automatic image segmentation that is simpler to use and less time-consuming than traditional snake models
The Impact of Positional Encodings on Multilingual Compression
Sep 11, 2021
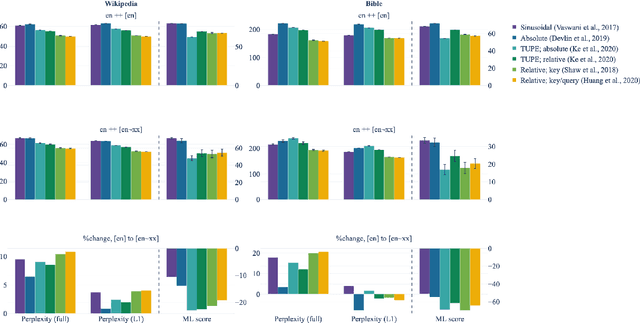

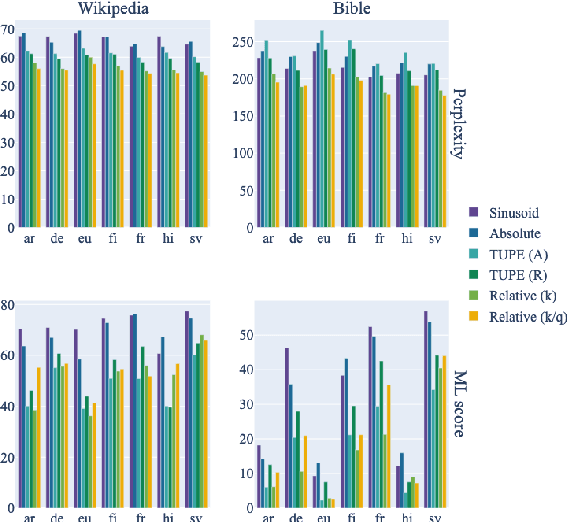
In order to preserve word-order information in a non-autoregressive setting, transformer architectures tend to include positional knowledge, by (for instance) adding positional encodings to token embeddings. Several modifications have been proposed over the sinusoidal positional encodings used in the original transformer architecture; these include, for instance, separating position encodings and token embeddings, or directly modifying attention weights based on the distance between word pairs. We first show that surprisingly, while these modifications tend to improve monolingual language models, none of them result in better multilingual language models. We then answer why that is: Sinusoidal encodings were explicitly designed to facilitate compositionality by allowing linear projections over arbitrary time steps. Higher variances in multilingual training distributions requires higher compression, in which case, compositionality becomes indispensable. Learned absolute positional encodings (e.g., in mBERT) tend to approximate sinusoidal embeddings in multilingual settings, but more complex positional encoding architectures lack the inductive bias to effectively learn compositionality and cross-lingual alignment. In other words, while sinusoidal positional encodings were originally designed for monolingual applications, they are particularly useful in multilingual language models.