 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess In-Context Learning: Enhancing Mathematical Reasoning via Dynamic Demonstration Insertion
Jan 17, 2026In-context learning (ICL) has proven highly effective across diverse large language model (LLM) tasks. However, its potential for enhancing tasks that demand step-by-step logical deduction, such as mathematical reasoning, remains underexplored. A core limitation of existing ICL approaches is their static use of demonstrations: examples are pre-selected before inference and remain fixed, failing to adapt to the dynamic confusion points that often arise during multi-step reasoning such as ambiguous calculations or logical gaps. These unresolved confusion points can lead to cascading errors that degrade final accuracy. To tackle this issue, we propose Process In-Context Learning (PICL), a dynamic demonstration integration framework designed to boost mathematical reasoning by responding to real-time inference needs. PICL operates in two stages: 1)~it identifies potential confusion points by analyzing semantics and entropy in the reasoning process and summarizes their core characteristics; 2)~upon encountering these points, it retrieves relevant demonstrations from the demonstration pool that match the confusion context and inserts them directly into the ongoing reasoning process to guide subsequent steps. Experiments show that PICL outperforms baseline methods by mitigating mid-inference confusion, highlighting the value of adaptive demonstration insertion in complex mathematical reasoning.
Adaptive Dependency-aware Prompt Optimization Framework for Multi-Step LLM Pipeline
Dec 31, 2025Multi-step LLM pipelines invoke large language models multiple times in a structured sequence and can effectively solve complex tasks, but their performance heavily depends on the prompts used at each step. Jointly optimizing these prompts is difficult due to missing step-level supervision and inter-step dependencies. Existing end-to-end prompt optimization methods struggle under these conditions and often yield suboptimal or unstable updates. We propose ADOPT, an Adaptive Dependency-aware Prompt Optimization framework for multi-step LLM pipelines. ADOPT explicitly models the dependency between each LLM step and the final task outcome, enabling precise text-gradient estimation analogous to computing analytical derivatives. It decouples textual gradient estimation from gradient updates, reducing multi-prompt optimization to flexible single-prompt optimization steps, and employs a Shapley-based mechanism to adaptively allocate optimization resources. Experiments on real-world datasets and diverse pipeline structures show that ADOPT is effective and robust, consistently outperforming state-of-the-art prompt optimization baselines.
Revisiting Chain-of-Thought Prompting: Zero-shot Can Be Stronger than Few-shot
Jun 17, 2025In-Context Learning (ICL) is an essential emergent ability of Large Language Models (LLMs), and recent studies introduce Chain-of-Thought (CoT) to exemplars of ICL to enhance the reasoning capability, especially in mathematics tasks. However, given the continuous advancement of model capabilities, it remains unclear whether CoT exemplars still benefit recent, stronger models in such tasks. Through systematic experiments, we find that for recent strong models such as the Qwen2.5 series, adding traditional CoT exemplars does not improve reasoning performance compared to Zero-Shot CoT. Instead, their primary function is to align the output format with human expectations. We further investigate the effectiveness of enhanced CoT exemplars, constructed using answers from advanced models such as \texttt{Qwen2.5-Max} and \texttt{DeepSeek-R1}. Experimental results indicate that these enhanced exemplars still fail to improve the model's reasoning performance. Further analysis reveals that models tend to ignore the exemplars and focus primarily on the instructions, leading to no observable gain in reasoning ability. Overall, our findings highlight the limitations of the current ICL+CoT framework in mathematical reasoning, calling for a re-examination of the ICL paradigm and the definition of exemplars.
SparDL: Distributed Deep Learning Training with Efficient Sparse Communication
Apr 03, 2023



Top-$k$ sparsification has recently been widely used to reduce the communication volume in distributed deep learning; however, due to Gradient Accumulation (GA) dilemma, the performance of top-$k$ sparsification is still limited. Several methods have been proposed to handle the GA dilemma but have two drawbacks: (1) they are frustrated by the high communication complexity as they introduce a large amount of extra transmission; (2) they are not flexible for non-power-of-two numbers of workers. To solve these two problems, we propose a flexible and efficient sparse communication framework, dubbed SparDL. SparDL uses the Spar-Reduce-Scatter algorithm to solve the GA dilemma without additional communication operations and is flexible to any number of workers. Besides, to further reduce the communication complexity and adjust the proportion of latency and bandwidth cost in communication complexity, we propose the Spar-All-Gather algorithm as part of SparDL. Extensive experiments validate the superiority of SparDL.
SMS: An Efficient Source Model Selection Framework for Model Reuse
Oct 18, 2021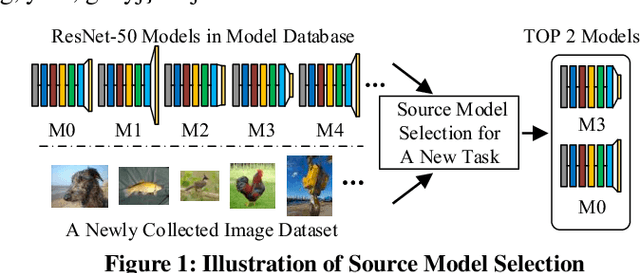
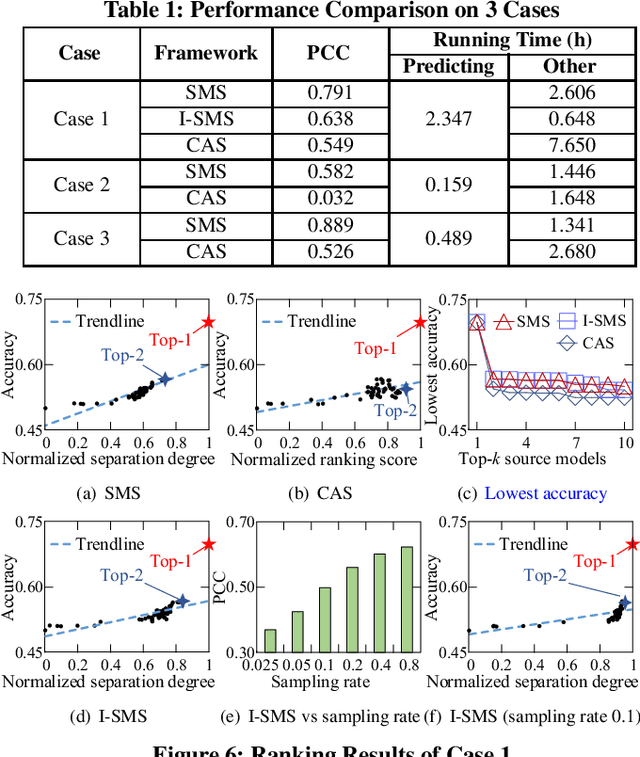

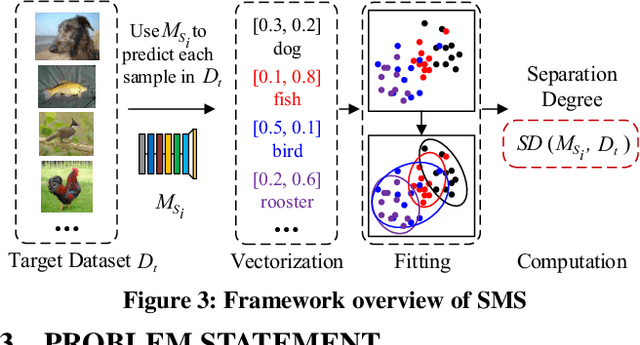
With the explosive increase of big data, training a Machine Learning (ML) model becomes a computation-intensive workload, which would take days or even weeks. Thus, model reuse has received attention in the ML community, where it is called transfer learning. Transfer learning avoids training a new model from scratch by transferring knowledge from a source task to a target task. Existing transfer learning methods mostly focus on how to improve the performance of the target task through a specific source model, and assume that the source model is given. Although many source models are available, it is difficult for data scientists to select the best source model for the target task manually. Hence, how to efficiently select a suitable source model for model reuse is still an unsolved problem. In this paper, we propose SMS, an effective, efficient and flexible source model selection framework. SMS is effective even when source and target datasets have significantly different data labels, is flexible to support source models with any type of structure, and is efficient to avoid any training process. For each source model, SMS first vectorizes the samples in the target dataset into soft labels by directly applying this model to the target dataset, then uses Gaussian distributions to fit for clusters of soft labels, and finally measures its distinguishing ability using Gaussian mixture-based metric. Moreover, we present an improved SMS (I-SMS), which decreases the output number of source model. I-SMS can significantly reduce the selection time while retaining the selection performance of SMS. Extensive experiments on a range of practical model reuse workloads demonstrate the effectiveness and efficiency of SMS.