 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastSGD: A Fast Compressed SGD Framework for Distributed Machine Learning
Dec 08, 2021
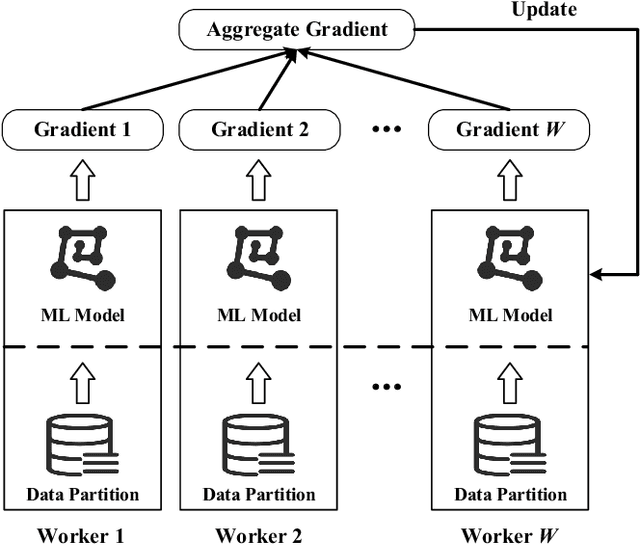
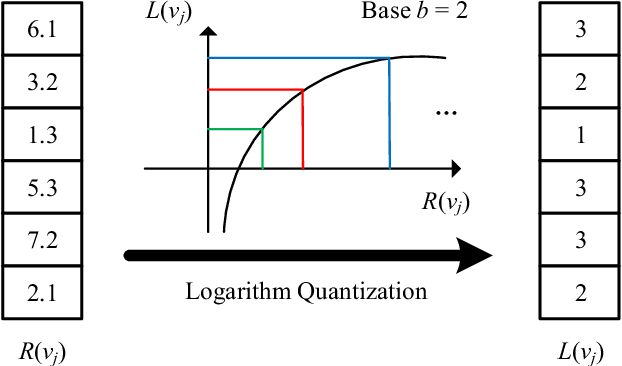
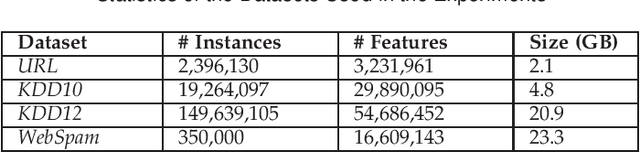
With the rapid increase of big data, distributed Machine Learning (ML) has been widely applied in training large-scale models. Stochastic Gradient Descent (SGD) is arguably the workhorse algorithm of ML. Distributed ML models trained by SGD involve large amounts of gradient communication, which limits the scalability of distributed ML. Thus, it is important to compress the gradients for reducing communication. In this paper, we propose FastSGD, a Fast compressed SGD framework for distributed ML. To achieve a high compression ratio at a low cost, FastSGD represents the gradients as key-value pairs, and compresses both the gradient keys and values in linear time complexity. For the gradient value compression, FastSGD first uses a reciprocal mapper to transform original values into reciprocal values, and then, it utilizes a logarithm quantization to further reduce reciprocal values to small integers. Finally, FastSGD filters reduced gradient integers by a given threshold. For the gradient key compression, FastSGD provides an adaptive fine-grained delta encoding method to store gradient keys with fewer bits. Extensive experiments on practical ML models and datasets demonstrate that FastSGD achieves the compression ratio up to 4 orders of magnitude, and accelerates the convergence time up to 8x, compared with state-of-the-art methods.
SMS: An Efficient Source Model Selection Framework for Model Reuse
Oct 18, 2021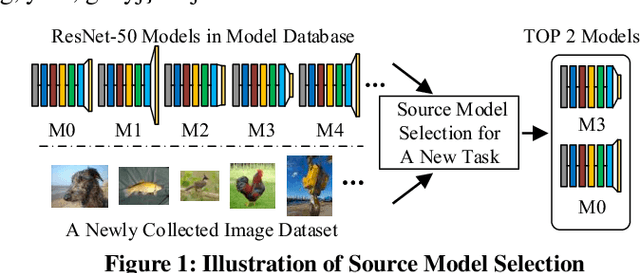
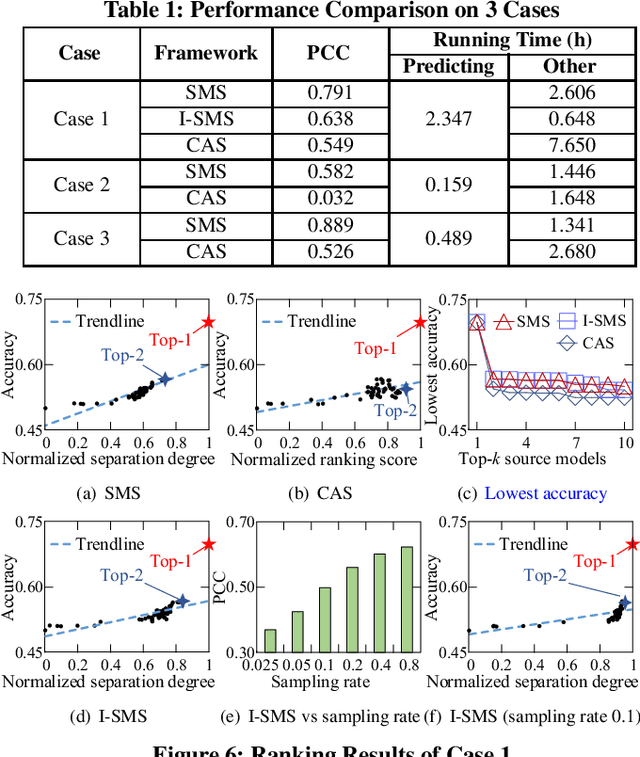

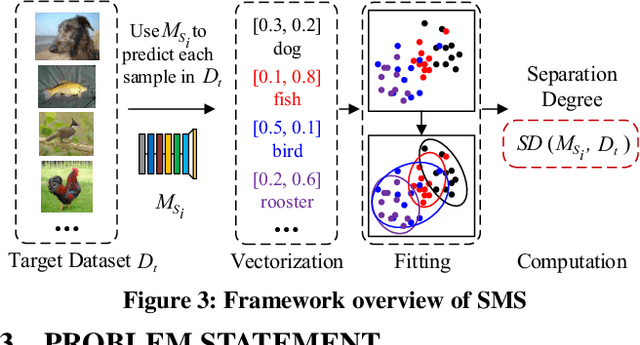
With the explosive increase of big data, training a Machine Learning (ML) model becomes a computation-intensive workload, which would take days or even weeks. Thus, model reuse has received attention in the ML community, where it is called transfer learning. Transfer learning avoids training a new model from scratch by transferring knowledge from a source task to a target task. Existing transfer learning methods mostly focus on how to improve the performance of the target task through a specific source model, and assume that the source model is given. Although many source models are available, it is difficult for data scientists to select the best source model for the target task manually. Hence, how to efficiently select a suitable source model for model reuse is still an unsolved problem. In this paper, we propose SMS, an effective, efficient and flexible source model selection framework. SMS is effective even when source and target datasets have significantly different data labels, is flexible to support source models with any type of structure, and is efficient to avoid any training process. For each source model, SMS first vectorizes the samples in the target dataset into soft labels by directly applying this model to the target dataset, then uses Gaussian distributions to fit for clusters of soft labels, and finally measures its distinguishing ability using Gaussian mixture-based metric. Moreover, we present an improved SMS (I-SMS), which decreases the output number of source model. I-SMS can significantly reduce the selection time while retaining the selection performance of SMS. Extensive experiments on a range of practical model reuse workloads demonstrate the effectiveness and efficiency of SMS.
CrowdTSC: Crowd-based Neural Networks for Text Sentiment Classification
Apr 26, 2020
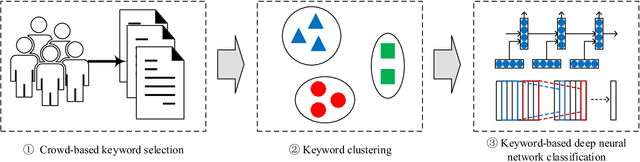

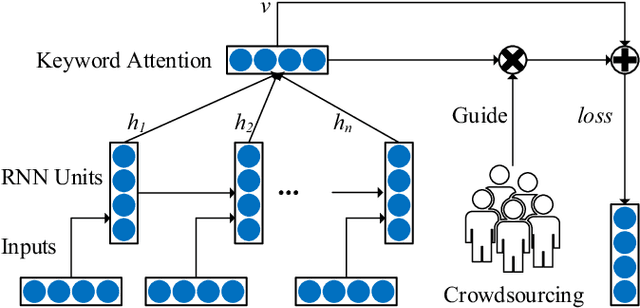
Sentiment classification is a fundamental task in content analysis. Although deep learning has demonstrated promising performance in text classification compared with shallow models, it is still not able to train a satisfying classifier for text sentiment. Human beings are more sophisticated than machine learning models in terms of understanding and capturing the emotional polarities of texts. In this paper, we leverage the power of human intelligence into text sentiment classification. We propose Crowd-based neural networks for Text Sentiment Classification (CrowdTSC for short). We design and post the questions on a crowdsourcing platform to collect the keywords in texts. Sampling and clustering are utilized to reduce the cost of crowdsourcing. Also, we present an attention-based neural network and a hybrid neural network, which incorporate the collected keywords as human being's guidance into deep neural networks. Extensive experiments on public datasets confirm that CrowdTSC outperforms state-of-the-art models, justifying the effectiveness of crowd-based keyword guidance.