 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A New Backbone for Hyperspectral Image Reconstruction
Aug 17, 2021
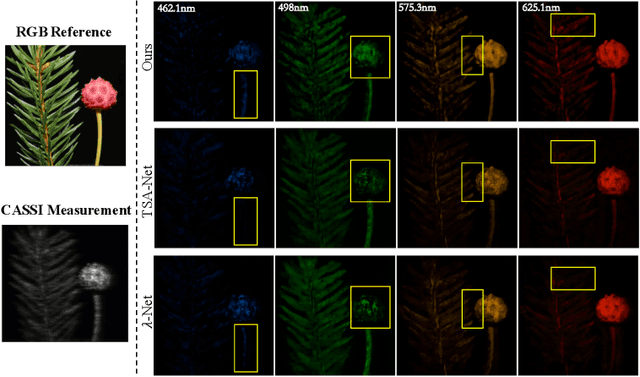



The study of 3D hyperspectral image (HSI) reconstruction refers to the inverse process of snapshot compressive imaging, during which the optical system, e.g., the coded aperture snapshot spectral imaging (CASSI) system, captures the 3D spatial-spectral signal and encodes it to a 2D measurement. While numerous sophisticated neural networks have been elaborated for end-to-end reconstruction, trade-offs still need to be made among performance, efficiency (training and inference time), and feasibility (the ability of restoring high resolution HSI on limited GPU memory). This raises a challenge to design a new baseline to conjointly meet the above requirements. In this paper, we fill in this blank by proposing a Spatial/Spectral Invariant Residual U-Net, namely SSI-ResU-Net. It differentiates with U-Net in three folds--1) scale/spectral-invariant learning, 2) nested residual learning, and 3) computational efficiency. Benefiting from these three modules, the proposed SSI-ResU-Net outperforms the current state-of-the-art method TSA-Net by over 3 dB in PSNR and 0.036 in SSIM while only using 2.82% trainable parameters. To the greatest extent, SSI-ResU-Net achieves competing performance with over 77.3% reduction in terms of floating-point operations (FLOPs), which for the first time, makes high-resolution HSI reconstruction feasible under practical application scenarios. Code and pre-trained models are made available at https://github.com/Jiamian-Wang/HSI_baseline.
3N-GAN: Semi-Supervised Classification of X-Ray Images with a 3-Player Adversarial Framework
Sep 22, 2021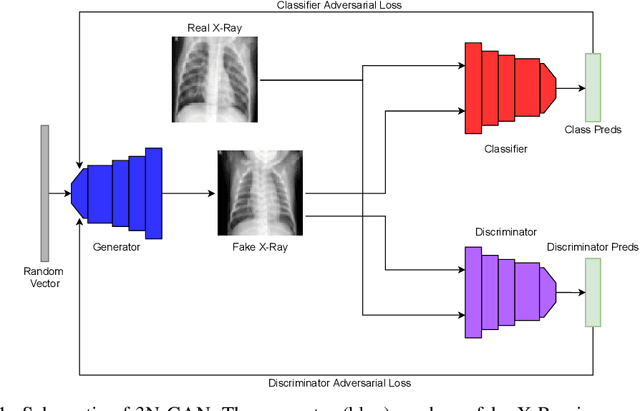
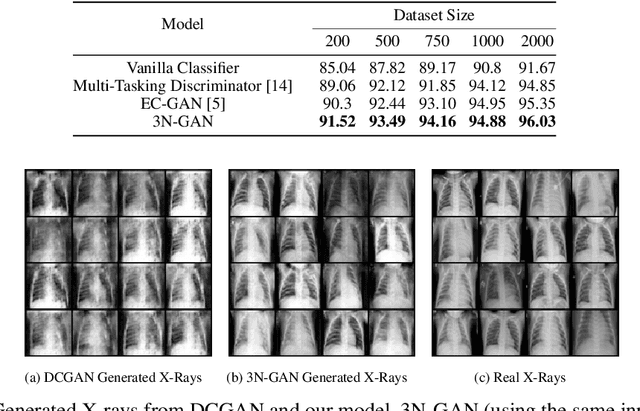
The success of deep learning for medical imaging tasks, such as classification, is heavily reliant on the availability of large-scale datasets. However, acquiring datasets with large quantities of labeled data is challenging, as labeling is expensive and time-consuming. Semi-supervised learning (SSL) is a growing alternative to fully-supervised learning, but requires unlabeled samples for training. In medical imaging, many datasets lack unlabeled data entirely, so SSL can't be conventionally utilized. We propose 3N-GAN, or 3 Network Generative Adversarial Networks, to perform semi-supervised classification of medical images in fully-supervised settings. We incorporate a classifier into the adversarial relationship such that the generator trains adversarially against both the classifier and discriminator. Our preliminary results show improved classification performance and GAN generations over various algorithms. Our work can seamlessly integrate with numerous other medical imaging model architectures and SSL methods for greater performance.
Patch Based Transformation for Minimum Variance Beamformer Image Approximation Using Delay and Sum Pipeline
Oct 19, 2021
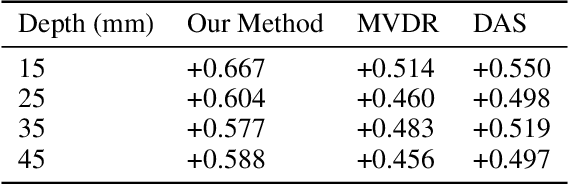
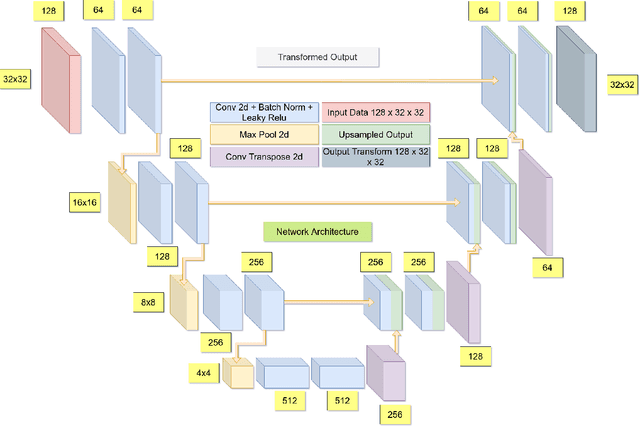
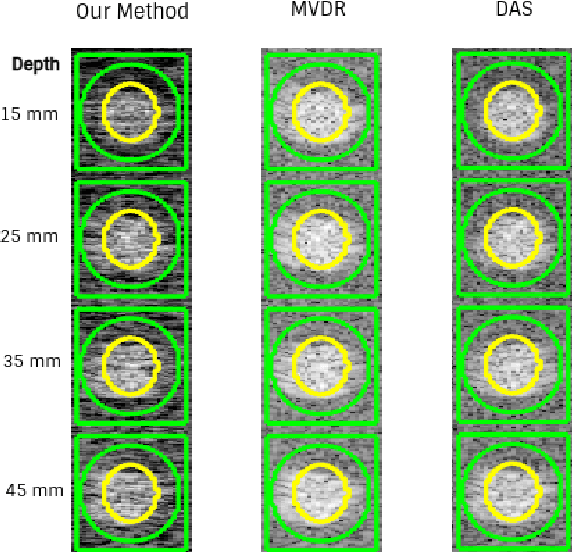
In the recent past, there have been several efforts in accelerating computationally heavy beamforming algorithms such as minimum variance distortionless response (MVDR) beamforming to achieve real-time performance comparable to the popular delay and sum (DAS) beamforming. This has been achieved using a variety of neural network architectures ranging from fully connected neural networks (FCNNs), convolutional neural networks (CNNs) and general adversarial networks (GANs). However most of these approaches are working with optimizations considering image level losses and hence require a significant amount of dataset to ensure that the process of beamforming is learned. In this work, a patch level U-Net based neural network is proposed, where the delay compensated radio frequency (RF) patch for a fixed region in space (e.g. 32x32) is transformed through a U-Net architecture and multiplied with DAS apodization weights and optimized for similarity with MVDR image of the patch. Instead of framing the beamforming problem as a regression problem to estimate the apodization weights, the proposed approach treats the non-linear transformation of the RF data space that can account for the data driven weight adaptation done by the MVDR approach in the parameters of the network. In this way, it is also observed that by restricting the input to a patch the model will learn the beamforming pipeline as an image non-linear transformation problem.
Weighted Tensor Completion for Time-Series Causal Inference
Feb 14, 2019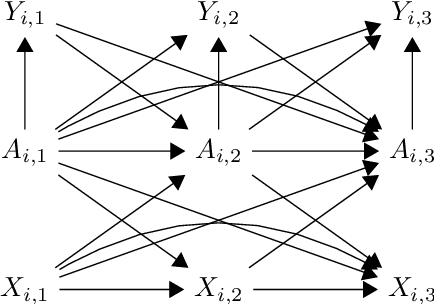
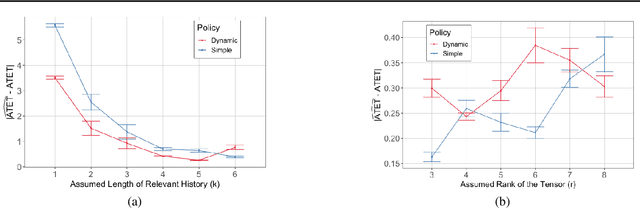
Marginal Structural Models (MSM) {Robins, 2000} are the most popular models for causal inference from time-series observational data. However, they have two main drawbacks: (a) they do not capture subject heterogeneity, and (b) they only consider fixed time intervals and do not scale gracefully with longer intervals. In this work, we propose a new family of MSMs to address these two concerns. We model the potential outcomes as a three-dimensional tensor of low rank, where the three dimensions correspond to the agents, time periods and the set of possible histories. Unlike the traditional MSM, we allow the dimensions of the tensor to increase with the number of agents and time periods. We set up a weighted tensor completion problem as our estimation procedure, and show that the solution to this problem converges to the true model in an appropriate sense. Then we show how to solve the estimation problem, providing conditions under which we can approximately and efficiently solve the estimation problem. Finally, we propose an algorithm based on projected gradient descent, which is easy to implement and evaluate its performance on a simulated dataset.
Human-Computer Interaction Glow Up: Examining Operational Trust and Intention Towards Mars Autonomous Systems
Oct 28, 2021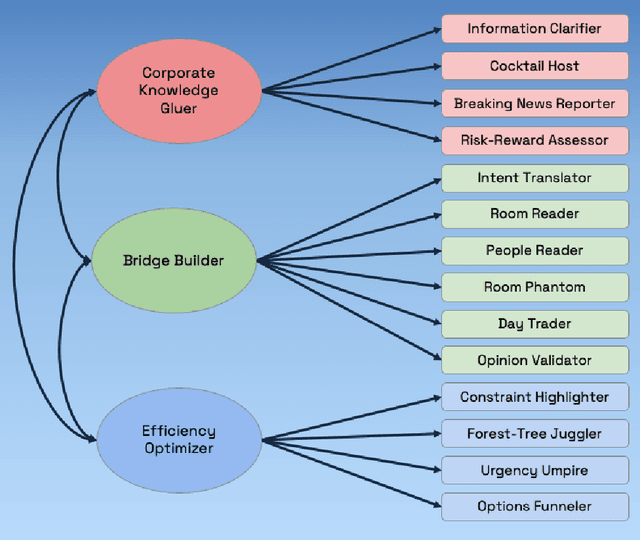
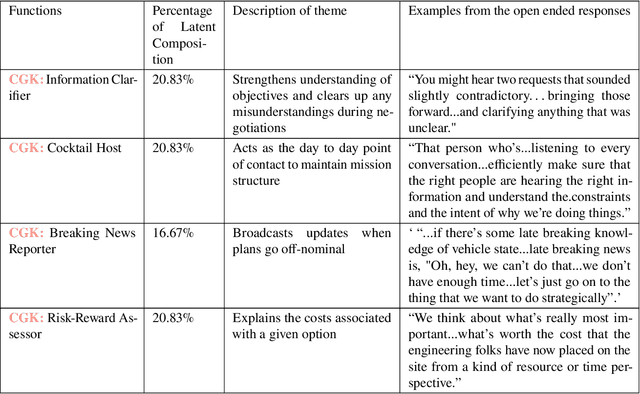
Tactful coordination on earth between hundreds of operators from diverse disciplines and backgrounds is needed to ensure that Martian rovers have a high likelihood of achieving their science goals while enduring the harsh environment of the red planet. The operations team includes many individuals, each with independent and overlapping objectives, working to decide what to execute on the Mars surface during the next planning period. The team must work together to understand each other's objectives and constraints within a fixed time period, often requiring frequent revision. This study examines the challenges faced during Mars surface operations, from high-level science objectives to formulating a valid, safe, and optimal activity plan that is ready to be radiated to the rover. Through this examination, we aim to illuminate how planning intent can be formulated and effectively communicated to future spacecrafts that will become more and more autonomous. Our findings reveal the intricate nature of human-to-human interactions that require a large array of soft skills and core competencies to communicate concurrently with science and engineering teams during plan formulation. Additionally, our findings exposed significant challenges in eliciting planning intent from operators, which will intensify in the future, as operators on the ground asynchronously co-operate the rover with the on board autonomy. Building a marvellous robot and landing it onto the Mars surface are remarkable feats -however, ensuring that scientists can get the best out of the mission is an ongoing challenge and will not cease to be a difficult task with increased autonomy.
Dynamic Gesture Recognition
Sep 22, 2021
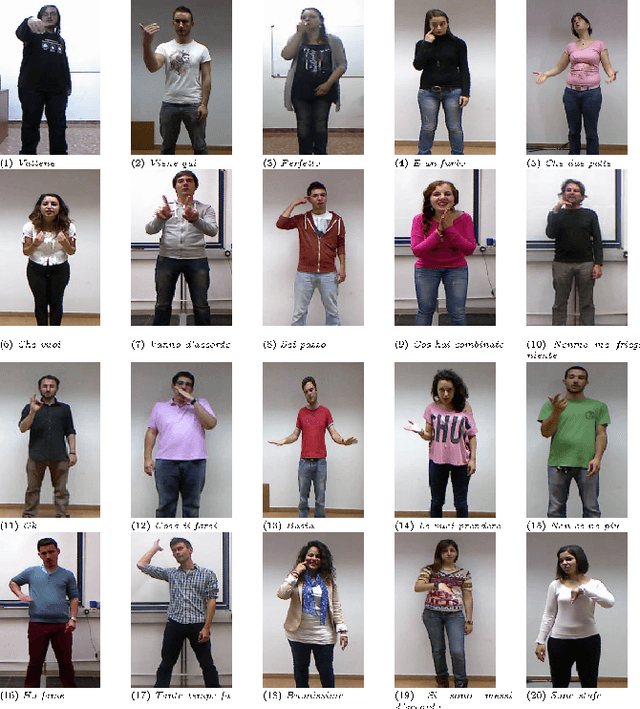
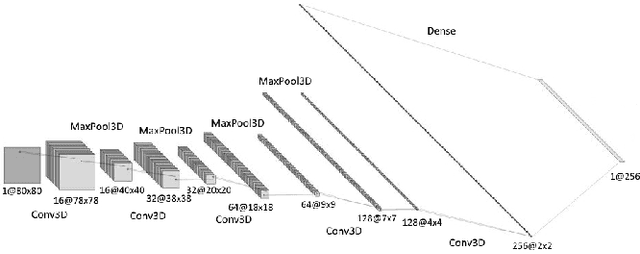
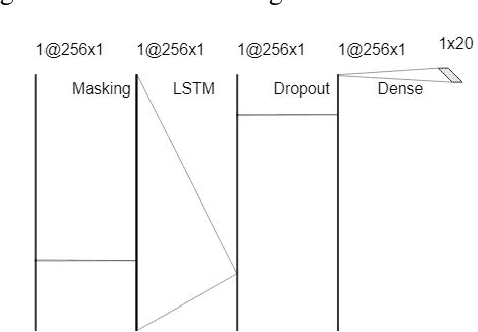
The Human-Machine Interaction (HMI) research field is an important topic in machine learning that has been deeply investigated thanks to the rise of computing power in the last years. The first time, it is possible to use machine learning to classify images and/or videos instead of the traditional computer vision algorithms. The aim of this project is to builda symbiosis between a convolutional neural network (CNN)[1] and a recurrent neural network (RNN) [2] to recognize cultural/anthropological Italian sign language gestures from videos. The CNN extracts important features that later areused by the RNN. With RNNs we are able to store temporal information inside the model to provide contextual information from previous frames to enhance the prediction accuracy. Our novel approach uses different data augmentation techniquesand regularization methods from only RGB frames to avoid overfitting and provide a small generalization error.
Deep speech inpainting of time-frequency masks
Oct 22, 2019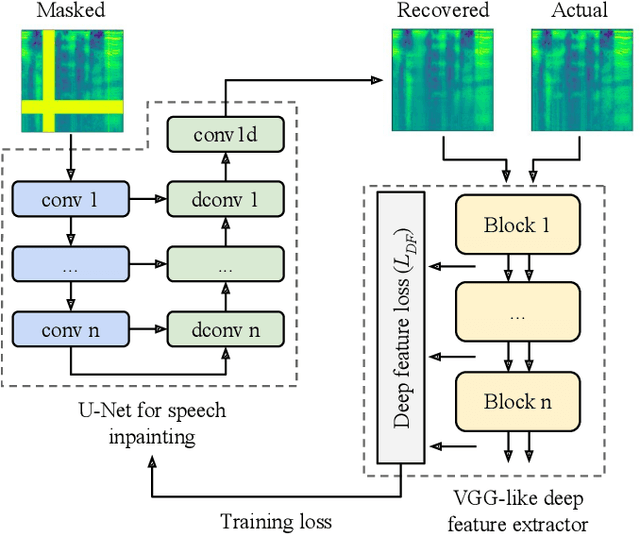
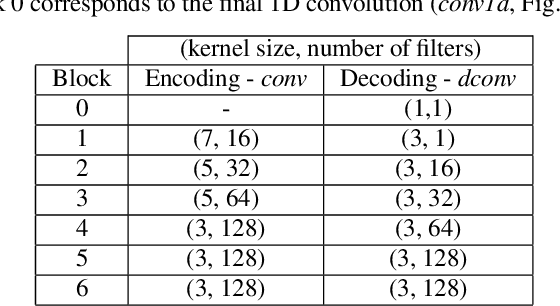
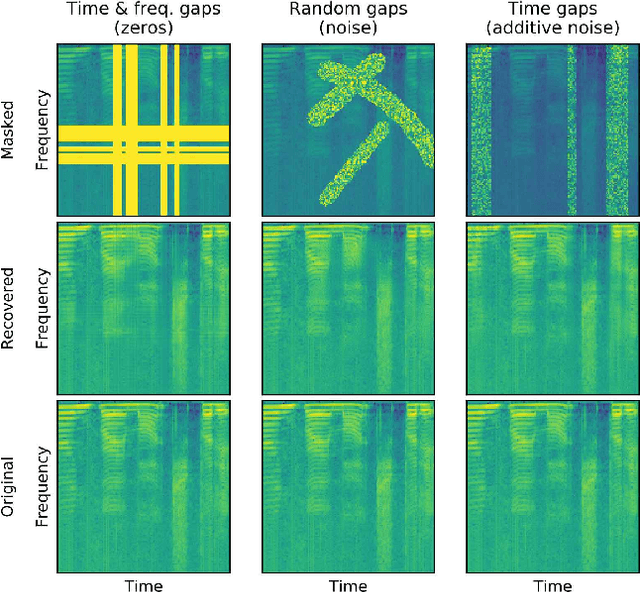
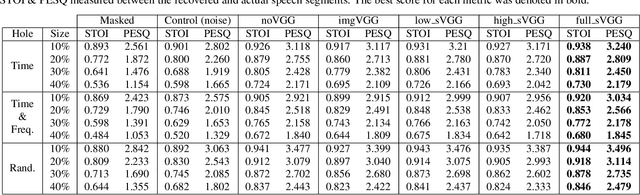
In particularly noisy environments, transient loud intrusions can completely overpower parts of the speech signal, leading to an inevitable loss of information. Recent algorithms for noise suppression often yield impressive results but tend to struggle when the signal-to-noise ratio (SNR) of the mixture is low or when parts of the signal are missing. To address these issues, here we introduce an end-to-end framework for the retrieval of missing or severely distorted parts of time-frequency representation of speech, from the short-term context, thus speech inpainting. The framework is based on a convolutional U-Net trained via deep feature losses, obtained through speechVGG, a deep speech feature extractor pre-trained on the word classification task. Our evaluation results demonstrate that the proposed framework is effective at recovering large portions of missing or distorted parts of speech. Specifically, it yields notable improvements in STOI & PESQ objective metrics, as assessed using the LibriSpeech dataset.
An Interleaved Approach to Trait-Based Task Allocation and Scheduling
Aug 05, 2021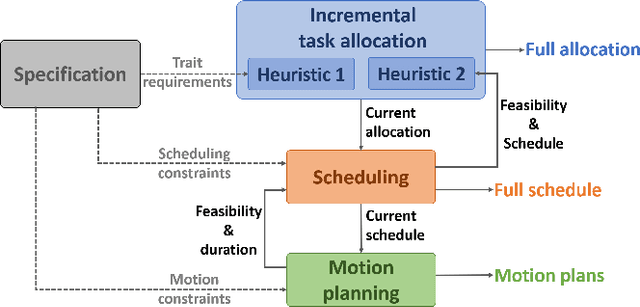
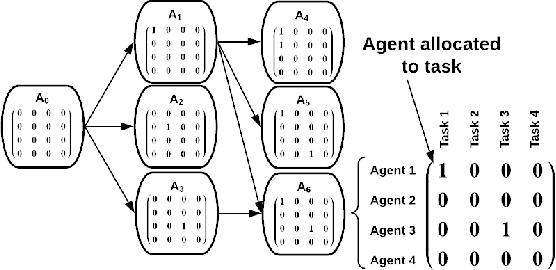
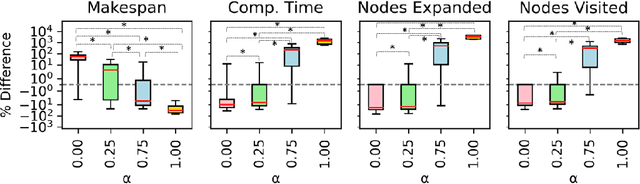
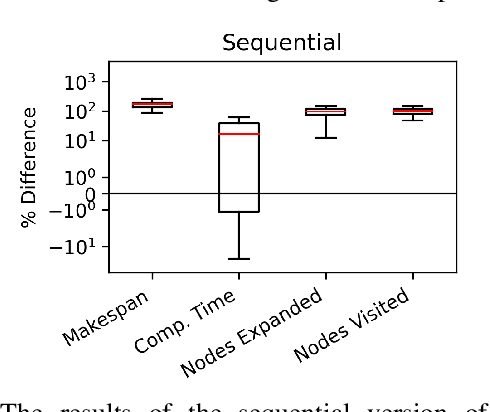
To realize effective heterogeneous multi-robot teams, researchers must leverage individual robots' relative strengths and coordinate their individual behaviors. Specifically, heterogeneous multi-robot systems must answer three important questions: \textit{who} (task allocation), \textit{when} (scheduling), and \textit{how} (motion planning). While specific variants of each of these problems are known to be NP-Hard, their interdependence only exacerbates the challenges involved in solving them together. In this paper, we present a novel framework that interleaves task allocation, scheduling, and motion planning. We introduce a search-based approach for trait-based time-extended task allocation named Incremental Task Allocation Graph Search (ITAGS). In contrast to approaches that solve the three problems in sequence, ITAGS's interleaved approach enables efficient search for allocations while simultaneously satisfying scheduling constraints and accounting for the time taken to execute motion plans. To enable effective interleaving, we develop a convex combination of two search heuristics that optimizes the satisfaction of task requirements as well as the makespan of the associated schedule. We demonstrate the efficacy of ITAGS using detailed ablation studies and comparisons against two state-of-the-art algorithms in a simulated emergency response domain.
MITAS: A Compressed Time-Domain Audio Separation Network with Parameter Sharing
Dec 09, 2019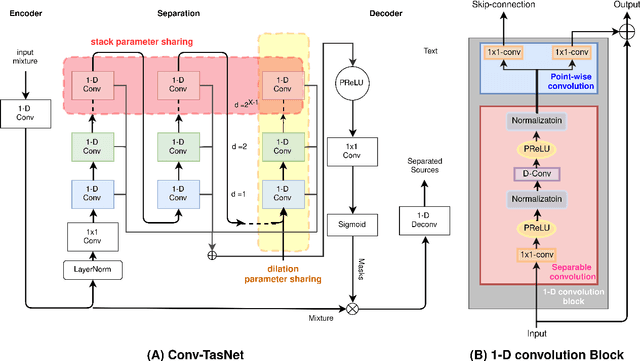
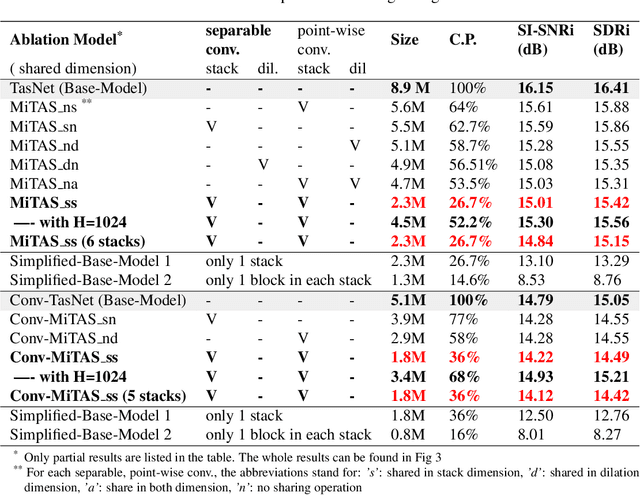
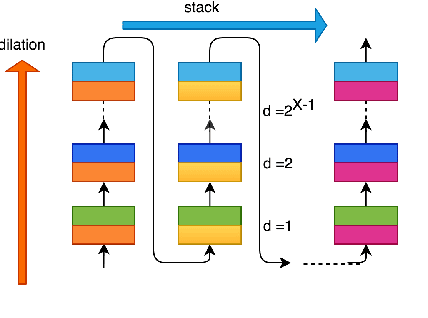
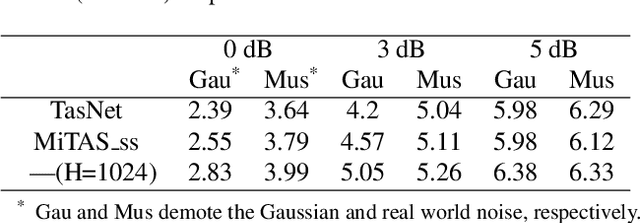
Deep learning methods have brought substantial advancements in speech separation (SS). Nevertheless, it remains challenging to deploy deep-learning-based models on edge devices. Thus, identifying an effective way to compress these large models without hurting SS performance has become an important research topic. Recently, TasNet and Conv-TasNet have been proposed. They achieved state-of-the-art results on several standardized SS tasks. Moreover, their low latency natures make them definitely suitable for real-time on-device applications. In this study, we propose two parameter-sharing schemes to lower the memory consumption on TasNet and Conv-TasNet. Accordingly, we derive a novel so-called MiTAS (Mini TasNet). Our experimental results first confirmed the robustness of our MiTAS on two types of perturbations in mixed audio. We also designed a series of ablation experiments to analyze the relation between SS performance and the amount of parameters in the model. The results show that MiTAS is able to reduce the model size by a factor of four while maintaining comparable SS performance with improved stability as compared to TasNet and Conv-TasNet. This suggests that MiTAS is more suitable for real-time low latency applications.
A Dynamic Keypoints Selection Network for 6DoF Pose Estimation
Oct 24, 2021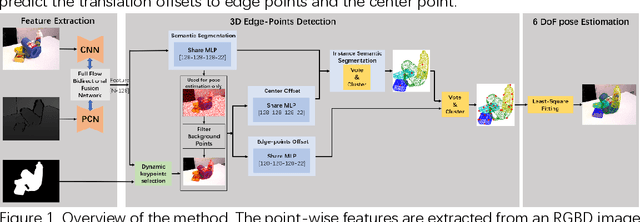
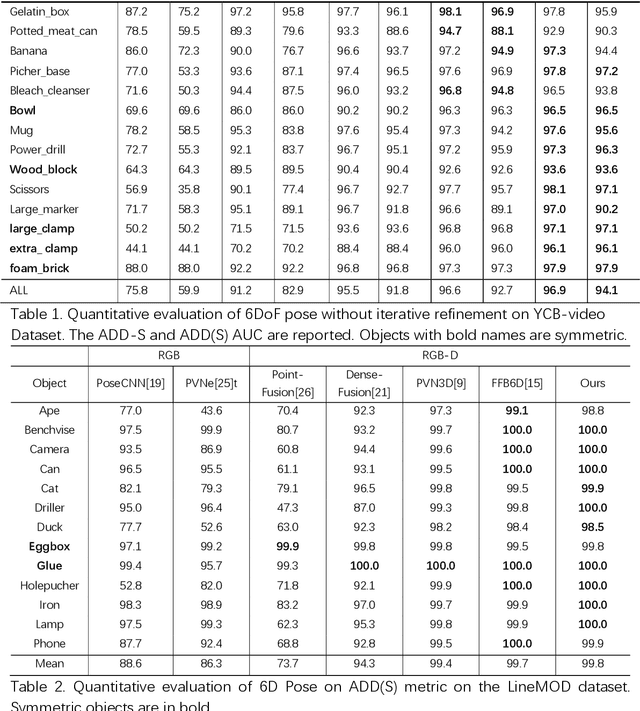


6 DoF poses estimation problem aims to estimate the rotation and translation parameters between two coordinates, such as object world coordinate and camera world coordinate. Although some advances are made with the help of deep learning, how to full use scene information is still a problem. Prior works tackle the problem by pixel-wise feature fusion but need to randomly selecte numerous points from images, which can not satisfy the demands of fast inference simultaneously and accurate pose estimation. In this work, we present a novel deep neural network based on dynamic keypoints selection designed for 6DoF pose estimation from a single RGBD image. Our network includes three parts, instance semantic segmentation, edge points detection and 6DoF pose estimation. Given an RGBD image, our network is trained to predict pixel category and the translation to edge points and center points. Then, a least-square fitting manner is applied to estimate the 6DoF pose parameters. Specifically, we propose a dynamic keypoints selection algorithm to choose keypoints from the foreground feature map. It allows us to leverage geometric and appearance information. During 6DoF pose estimation, we utilize the instance semantic segmentation result to filter out background points and only use foreground points to finish edge points detection and 6DoF pose estimation. Experiments on two commonly used 6DoF estimation benchmark datasets, YCB-Video and LineMoD, demonstrate that our method outperforms the state-of-the-art methods and achieves significant improvements over other same category methods time efficiency.