 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Deep Learning Generative Model Approach for Image Synthesis of Plant Leaves
Nov 05, 2021
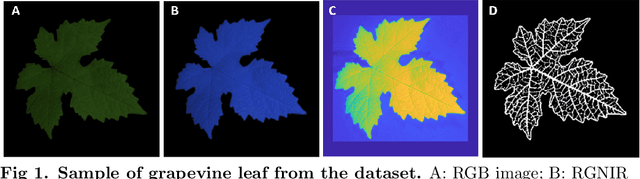
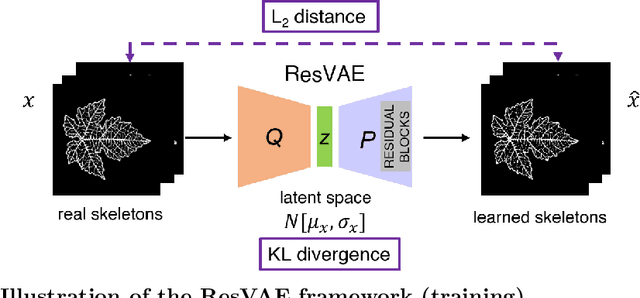
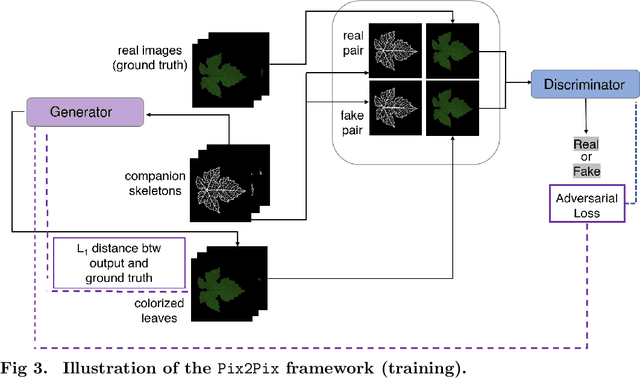
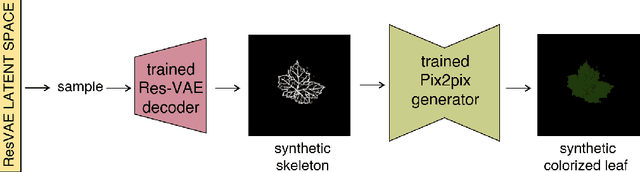
Objectives. We generate via advanced Deep Learning (DL) techniques artificial leaf images in an automatized way. We aim to dispose of a source of training samples for AI applications for modern crop management. Such applications require large amounts of data and, while leaf images are not truly scarce, image collection and annotation remains a very time--consuming process. Data scarcity can be addressed by augmentation techniques consisting in simple transformations of samples belonging to a small dataset, but the richness of the augmented data is limited: this motivates the search for alternative approaches. Methods. Pursuing an approach based on DL generative models, we propose a Leaf-to-Leaf Translation (L2L) procedure structured in two steps: first, a residual variational autoencoder architecture generates synthetic leaf skeletons (leaf profile and veins) starting from companions binarized skeletons of real images. In a second step, we perform translation via a Pix2pix framework, which uses conditional generator adversarial networks to reproduce the colorization of leaf blades, preserving the shape and the venation pattern. Results. The L2L procedure generates synthetic images of leaves with a realistic appearance. We address the performance measurement both in a qualitative and a quantitative way; for this latter evaluation, we employ a DL anomaly detection strategy which quantifies the degree of anomaly of synthetic leaves with respect to real samples. Conclusions. Generative DL approaches have the potential to be a new paradigm to provide low-cost meaningful synthetic samples for computer-aided applications. The present L2L approach represents a step towards this goal, being able to generate synthetic samples with a relevant qualitative and quantitative resemblance to real leaves.
PWPAE: An Ensemble Framework for Concept Drift Adaptation in IoT Data Streams
Sep 10, 2021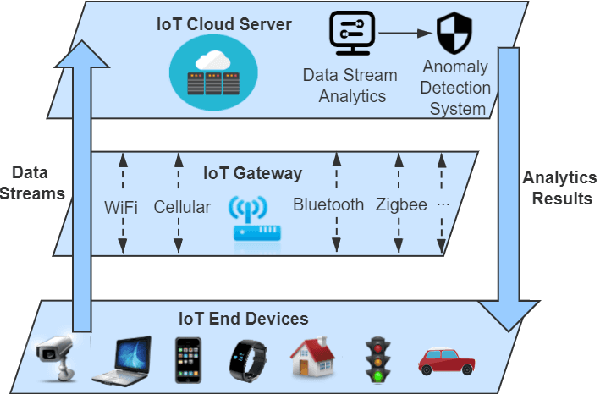
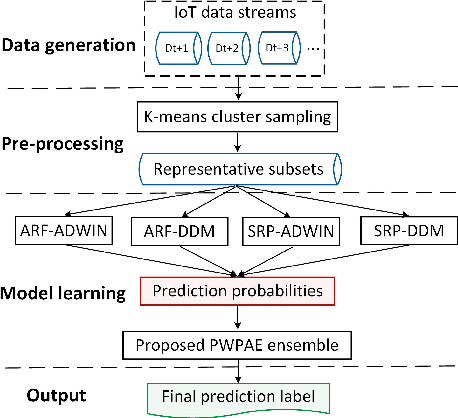
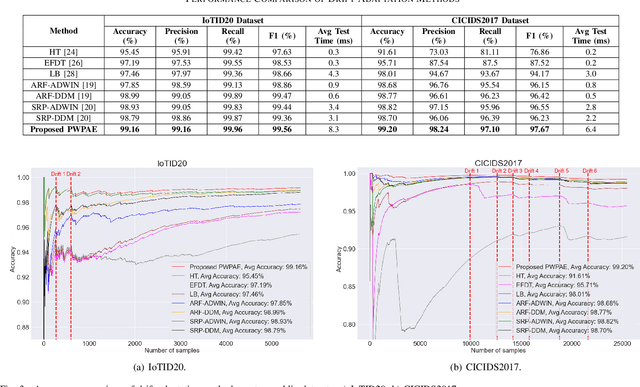
As the number of Internet of Things (IoT) devices and systems have surged, IoT data analytics techniques have been developed to detect malicious cyber-attacks and secure IoT systems; however, concept drift issues often occur in IoT data analytics, as IoT data is often dynamic data streams that change over time, causing model degradation and attack detection failure. This is because traditional data analytics models are static models that cannot adapt to data distribution changes. In this paper, we propose a Performance Weighted Probability Averaging Ensemble (PWPAE) framework for drift adaptive IoT anomaly detection through IoT data stream analytics. Experiments on two public datasets show the effectiveness of our proposed PWPAE method compared against state-of-the-art methods.
SIRe-Networks: Skip Connections over Interlaced Multi-Task Learning and Residual Connections for Structure Preserving Object Classification
Oct 06, 2021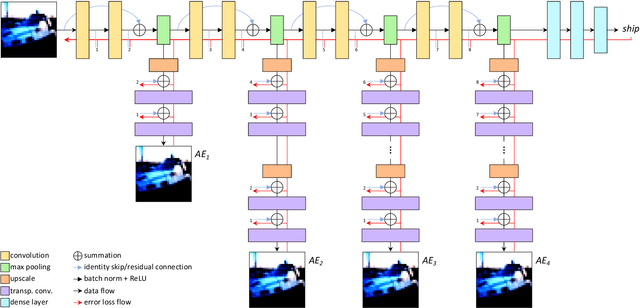
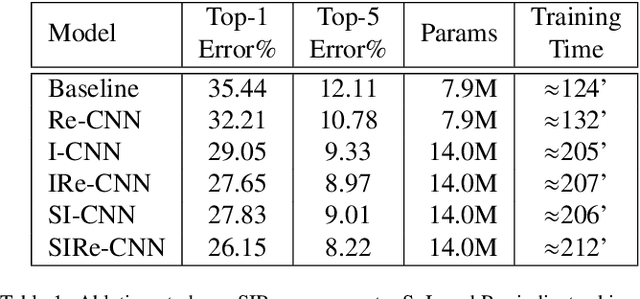

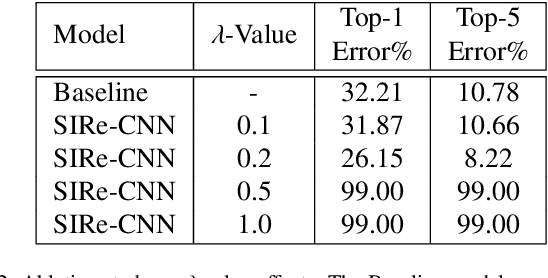
Improving existing neural network architectures can involve several design choices such as manipulating the loss functions, employing a diverse learning strategy, exploiting gradient evolution at training time, optimizing the network hyper-parameters, or increasing the architecture depth. The latter approach is a straightforward solution, since it directly enhances the representation capabilities of a network; however, the increased depth generally incurs in the well-known vanishing gradient problem. In this paper, borrowing from different methods addressing this issue, we introduce an interlaced multi-task learning strategy, defined SIRe, to reduce the vanishing gradient in relation to the object classification task. The presented methodology directly improves a convolutional neural network (CNN) by enforcing the input image structure preservation through interlaced auto-encoders, and further refines the base network architecture by means of skip and residual connections. To validate the presented methodology, a simple CNN and various implementations of famous networks are extended via the SIRe strategy and extensively tested on the CIFAR100 dataset; where the SIRe-extended architectures achieve significantly increased performances across all models, thus confirming the presented approach effectiveness.
CORNET 2.0: A Co-Simulation Middleware forRobot Networks
Sep 14, 2021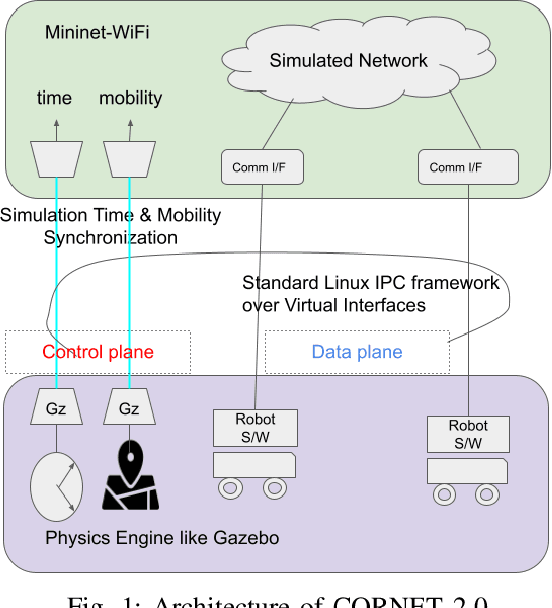
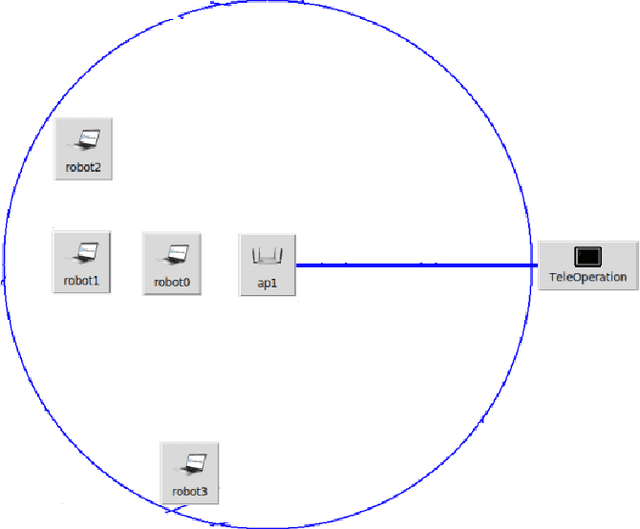
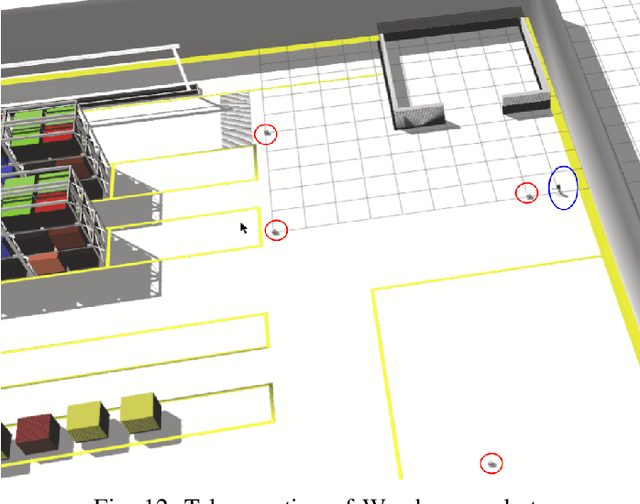
We present a networked co-simulation framework for multi-robot systems applications. We require a simulation framework that captures both physical interactions and communications aspects to effectively design such complex systems. This is necessary to co-design the multi-robots' autonomy logic and the communication protocols. The proposed framework extends existing tools to simulate the robot's autonomy and network-related aspects. We have used Gazebo with ROS/ROS2 to develop the autonomy logic for robots and mininet-WiFi as the network simulator to capture the cyber-physical systems properties of the multi-robot system. This framework addresses the need to seamlessly integrate the two simulation environments by synchronizing mobility and time, allowing for easy migration of the algorithms to real platforms.
When and how epochwise double descent happens
Aug 26, 2021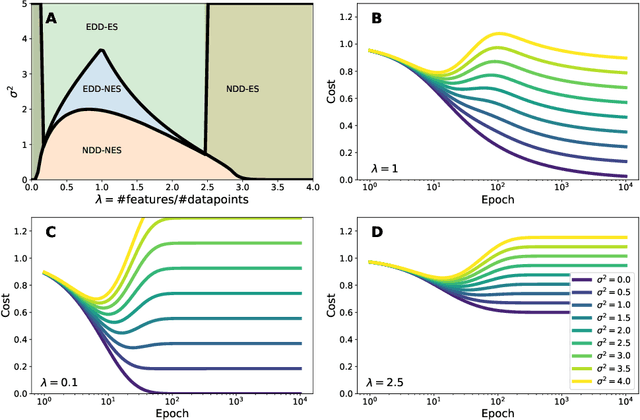
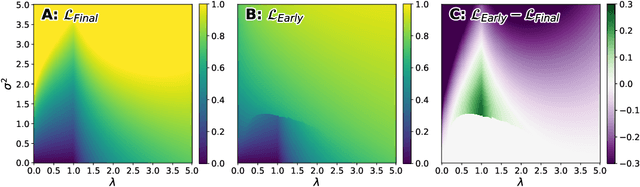
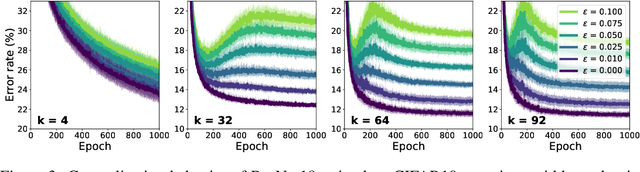
Deep neural networks are known to exhibit a `double descent' behavior as the number of parameters increases. Recently, it has also been shown that an `epochwise double descent' effect exists in which the generalization error initially drops, then rises, and finally drops again with increasing training time. This presents a practical problem in that the amount of time required for training is long, and early stopping based on validation performance may result in suboptimal generalization. In this work we develop an analytically tractable model of epochwise double descent that allows us to characterise theoretically when this effect is likely to occur. This model is based on the hypothesis that the training data contains features that are slow to learn but informative. We then show experimentally that deep neural networks behave similarly to our theoretical model. Our findings indicate that epochwise double descent requires a critical amount of noise to occur, but above a second critical noise level early stopping remains effective. Using insights from theory, we give two methods by which epochwise double descent can be removed: one that removes slow to learn features from the input and reduces generalization performance, and another that instead modifies the training dynamics and matches or exceeds the generalization performance of standard training. Taken together, our results suggest a new picture of how epochwise double descent emerges from the interplay between the dynamics of training and noise in the training data.
Self learning robot using real-time neural networks
Jan 06, 2020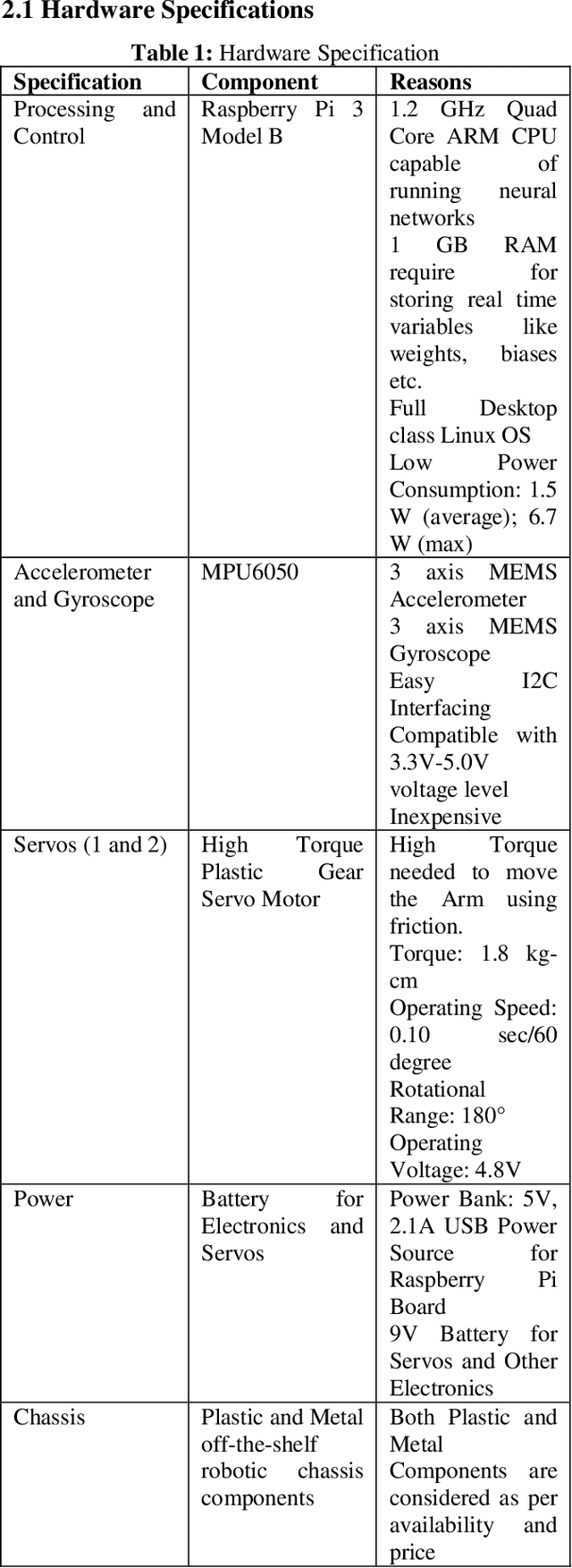
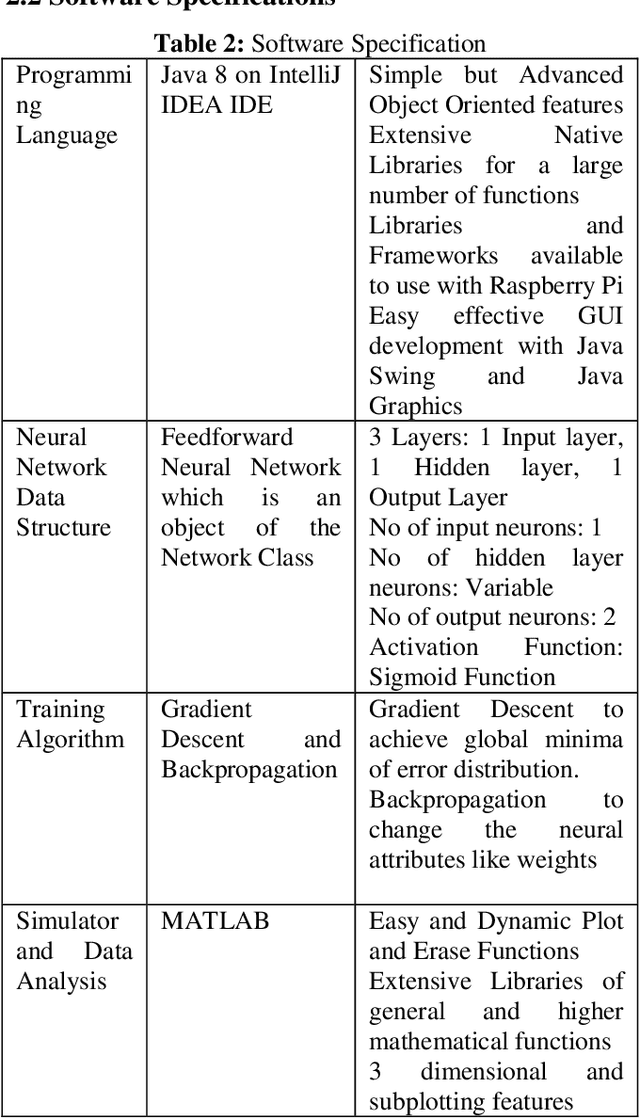
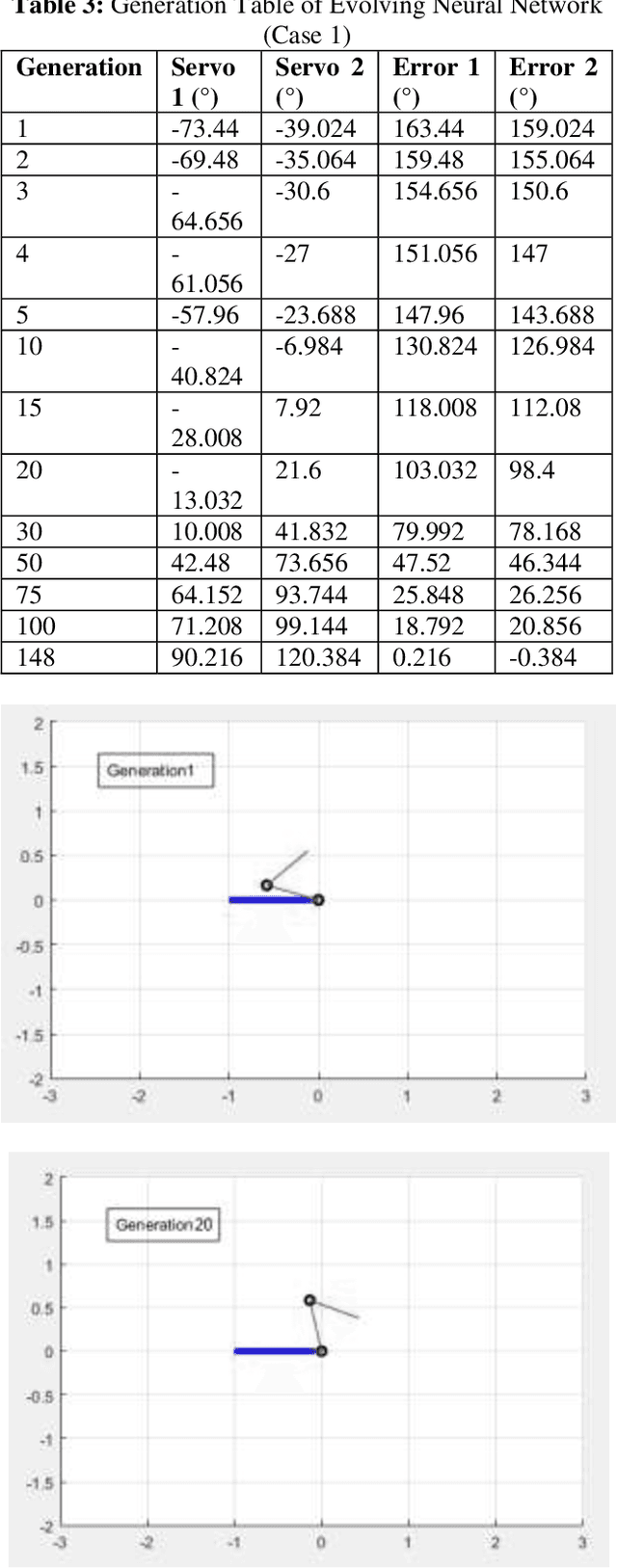
With the advancements in high volume, low precision computational technology and applied research on cognitive artificially intelligent heuristic systems, machine learning solutions through neural networks with real-time learning has seen an immense interest in the research community as well the industry. This paper involves research, development and experimental analysis of a neural network implemented on a robot with an arm through which evolves to learn to walk in a straight line or as required. The neural network learns using the algorithms of Gradient Descent and Backpropagation. Both the implementation and training of the neural network is done locally on the robot on a raspberry pi 3 so that its learning process is completely independent. The neural network is first tested on a custom simulator developed on MATLAB and then implemented on the raspberry computer. Data at each generation of the evolving network is stored, and analysis both mathematical and graphical is done on the data. Impact of factors like the learning rate and error tolerance on the learning process and final output is analyzed.
* 8 pages, 14 figures
A Separable Temporal Convolution Neural Network with Attention for Small-Footprint Keyword Spotting
Sep 01, 2021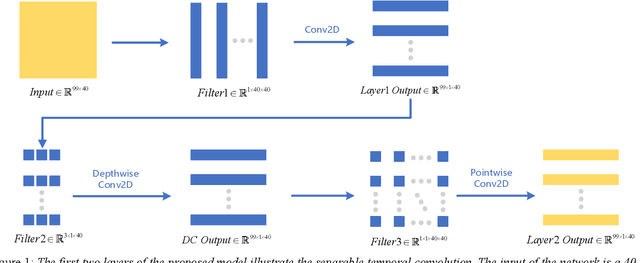

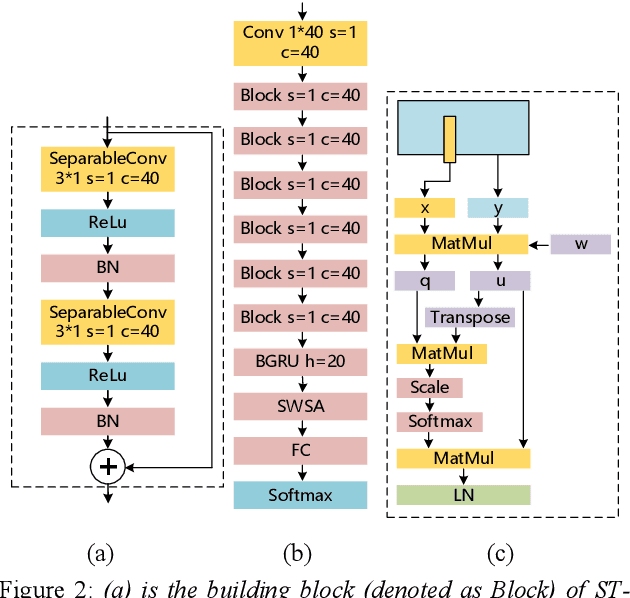
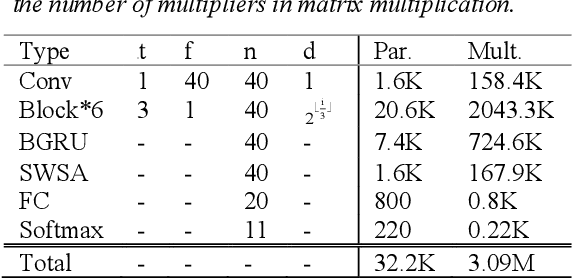
Keyword spotting (KWS) on mobile devices generally requires a small memory footprint. However, most current models still maintain a large number of parameters in order to ensure good performance. To solve this problem, this paper proposes a separable temporal convolution neural network with attention, it has a small number of parameters. Through the time convolution combined with attention mechanism, a small number of parameters model (32.2K) is implemented while maintaining high performance. The proposed model achieves 95.7% accuracy on the Google Speech Commands dataset, which is close to the performance of Res15(239K), the state-of-the-art model in KWS at present.
Straight to Shapes++: Real-time Instance Segmentation Made More Accurate
May 27, 2019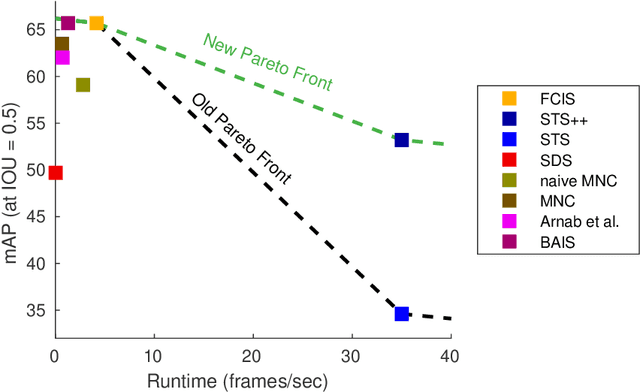
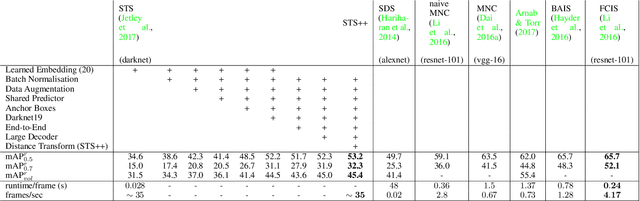
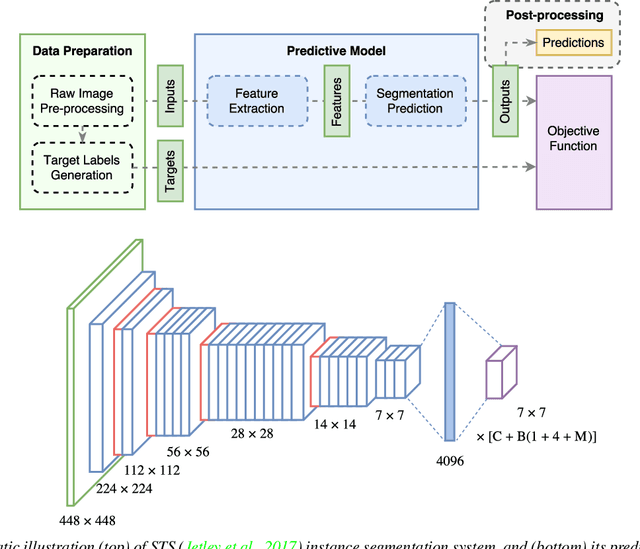
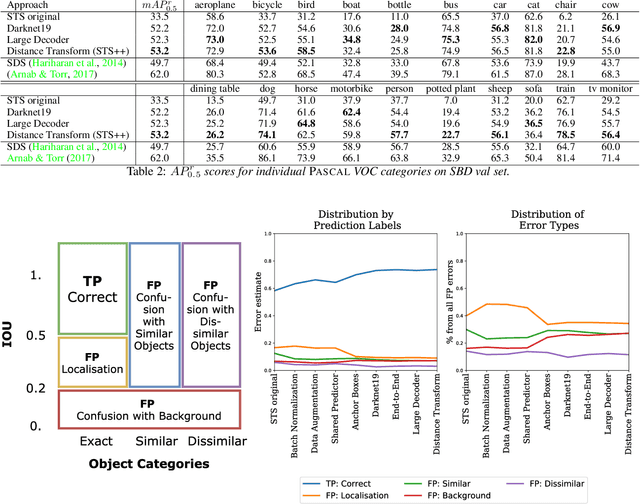
Instance segmentation is an important problem in computer vision, with applications in autonomous driving, drone navigation and robotic manipulation. However, most existing methods are not real-time, complicating their deployment in time-sensitive contexts. In this work, we extend an existing approach to real-time instance segmentation, called `Straight to Shapes' (STS), which makes use of low-dimensional shape embedding spaces to directly regress to object shape masks. The STS model can run at 35 FPS on a high-end desktop, but its accuracy is significantly worse than that of offline state-of-the-art methods. We leverage recent advances in the design and training of deep instance segmentation models to improve the performance accuracy of the STS model whilst keeping its real-time capabilities intact. In particular, we find that parameter sharing, more aggressive data augmentation and the use of structured loss for shape mask prediction all provide a useful boost to the network performance. Our proposed approach, `Straight to Shapes++', achieves a remarkable 19.7 point improvement in mAP (at IOU of 0.5) over the original method as evaluated on the PASCAL VOC dataset, thus redefining the accuracy frontier at real-time speeds. Since the accuracy of instance segmentation is closely tied to that of object bounding box prediction, we also study the error profile of the latter and examine the failure modes of our method for future improvements.
Long-term series forecasting with Query Selector -- efficient model of sparse attention
Jul 19, 2021
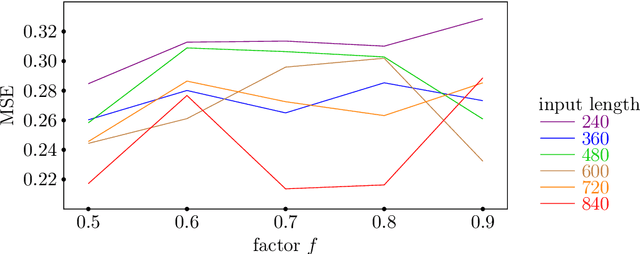
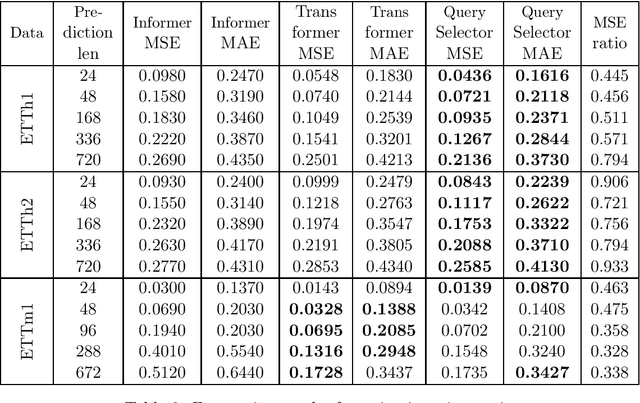
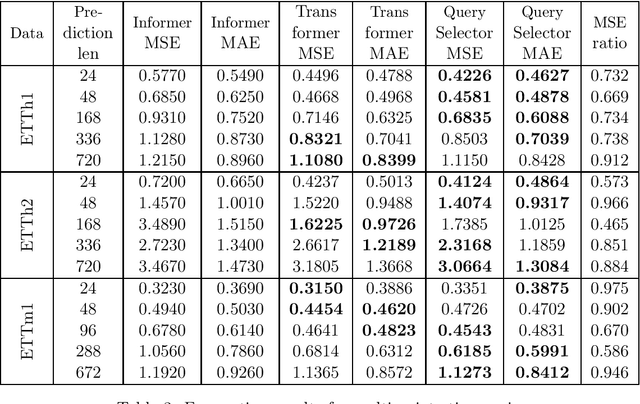
Various modifications of TRANSFORMER were recently used to solve time-series forecasting problem. We propose Query Selector - an efficient, deterministic algorithm for sparse attention matrix. Experiments show it achieves state-of-the art results on ETT data set.
Concepts of Self-maintaining Robots and Their Design
Oct 12, 2021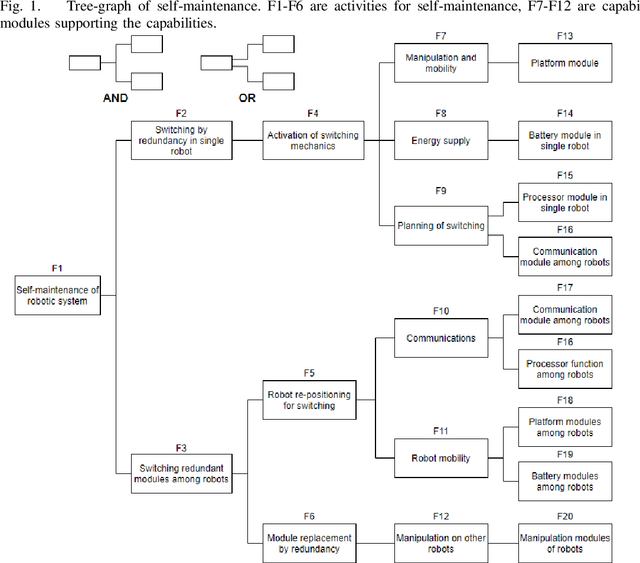
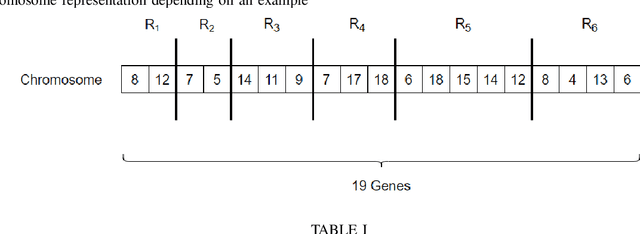
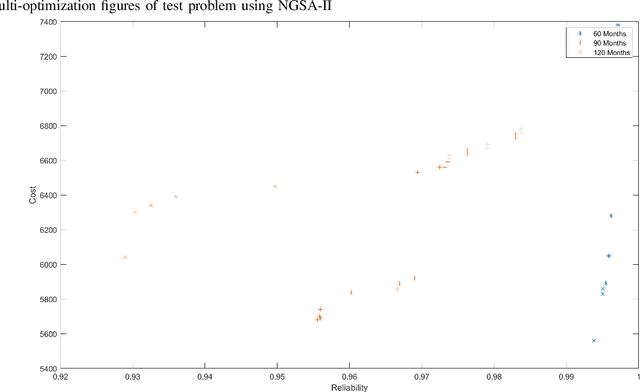

This paper proposes an initial theory for robotic systems that can be fully self-maintaining. The new design principles focus on functional survival of the robots over long periods of time without human maintenance. Self-maintaining semi-autonomous mobile robots are in great demand in nuclear disposal sites from where their removal for maintenance is undesirable due to their radioactive contamination. Similar are requirements for robots in various defence tasks or space missions. For optimal design, modular solutions are balanced against capabilities to replace smaller components in a robot by itself or by help from another robot. Modules are proposed for the basic platform, which enable self-maintenance within a team of robots helping each other. The primary method of self-maintenance is replacement of malfunctioning modules or components by the robots themselves. Replacement necessitates a robot team's ability to diagnose and replace malfunctioning modules as needed. Due to their design, these robots still remain manually re-configurable if opportunity arises for human intervention. Apart from the basic principles, an evolutionary design approach is presented and a first mathematical theory of the reliability of a team of self-maintaining robots is introduced.