 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
A Separable Temporal Convolution Neural Network with Attention for Small-Footprint Keyword Spotting
Sep 01, 2021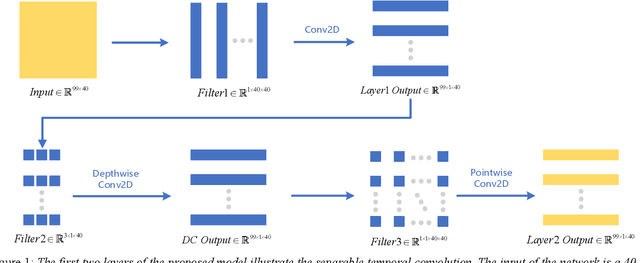

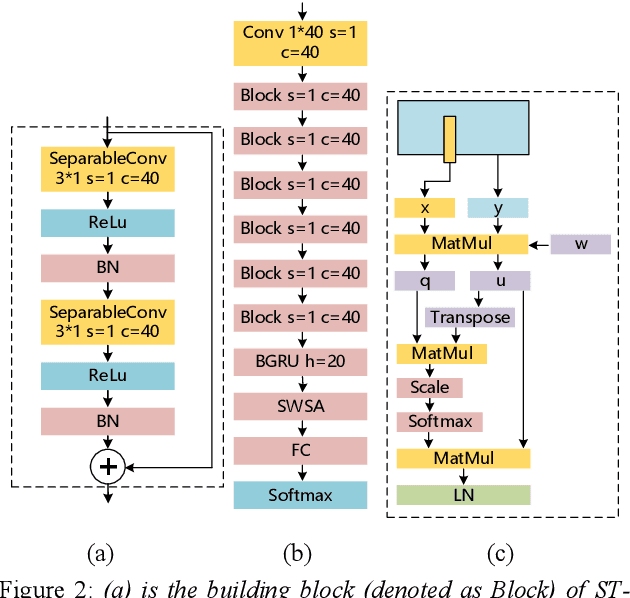
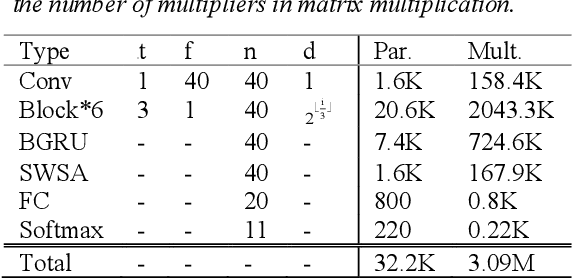
Keyword spotting (KWS) on mobile devices generally requires a small memory footprint. However, most current models still maintain a large number of parameters in order to ensure good performance. To solve this problem, this paper proposes a separable temporal convolution neural network with attention, it has a small number of parameters. Through the time convolution combined with attention mechanism, a small number of parameters model (32.2K) is implemented while maintaining high performance. The proposed model achieves 95.7% accuracy on the Google Speech Commands dataset, which is close to the performance of Res15(239K), the state-of-the-art model in KWS at present.
Separable Temporal Convolution plus Temporally Pooled Attention for Lightweight High-performance Keyword Spotting
Aug 27, 2021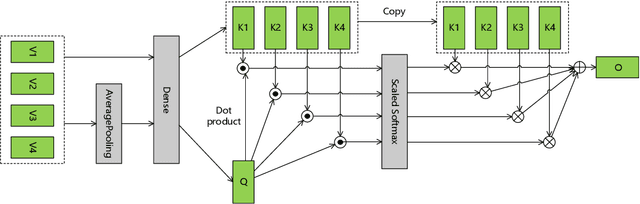
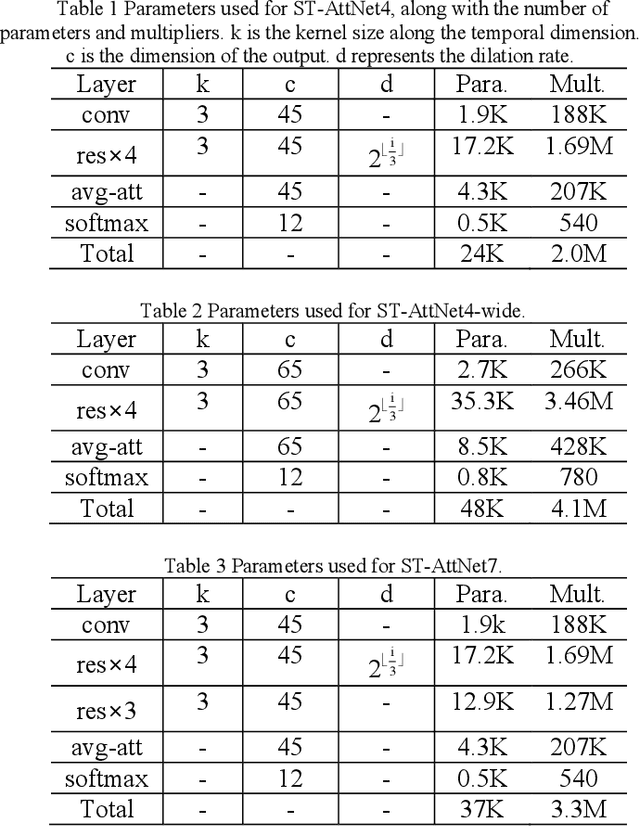
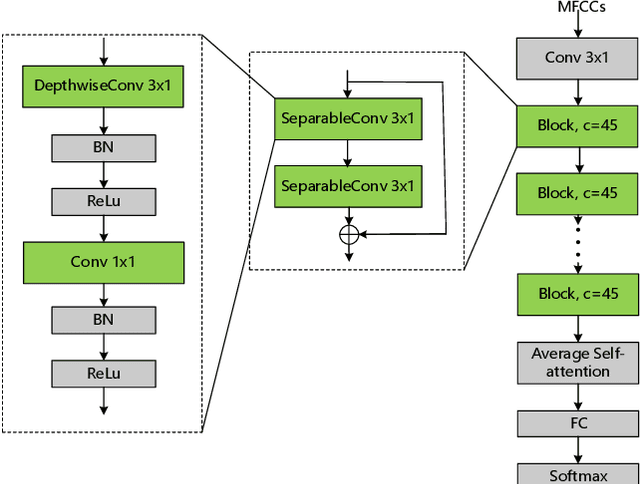
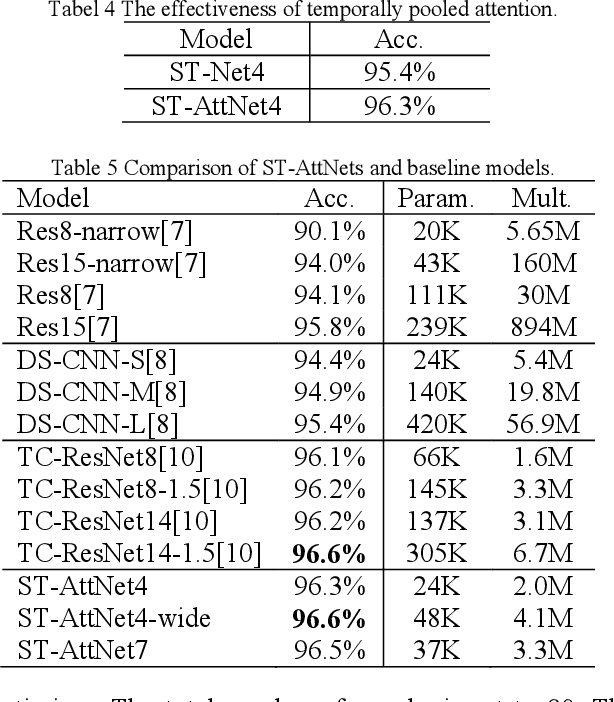
Keyword spotting (KWS) on mobile devices generally requires a small memory footprint. However, most current models still maintain a large number of parameters in order to ensure good performance. In this paper, we propose a temporally pooled attention module which can capture global features better than the AveragePool. Besides, we design a separable temporal convolution network which leverages depthwise separable and temporal convolution to reduce the number of parameter and calculations. Finally, taking advantage of separable temporal convolution and temporally pooled attention, a efficient neural network (ST-AttNet) is designed for KWS system. We evaluate the models on the publicly available Google speech commands data sets V1. The number of parameters of proposed model (48K) is 1/6 of state-of-the-art TC-ResNet14-1.5 model (305K). The proposed model achieves a 96.6% accuracy, which is comparable to the TC-ResNet14-1.5 model (96.6%).