 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIA Forecaster: Technical Report
Nov 10, 2025This technical report describes the AIA Forecaster, a Large Language Model (LLM)-based system for judgmental forecasting using unstructured data. The AIA Forecaster approach combines three core elements: agentic search over high-quality news sources, a supervisor agent that reconciles disparate forecasts for the same event, and a set of statistical calibration techniques to counter behavioral biases in large language models. On the ForecastBench benchmark (Karger et al., 2024), the AIA Forecaster achieves performance equal to human superforecasters, surpassing prior LLM baselines. In addition to reporting on ForecastBench, we also introduce a more challenging forecasting benchmark sourced from liquid prediction markets. While the AIA Forecaster underperforms market consensus on this benchmark, an ensemble combining AIA Forecaster with market consensus outperforms consensus alone, demonstrating that our forecaster provides additive information. Our work establishes a new state of the art in AI forecasting and provides practical, transferable recommendations for future research. To the best of our knowledge, this is the first work that verifiably achieves expert-level forecasting at scale.
When and how epochwise double descent happens
Aug 26, 2021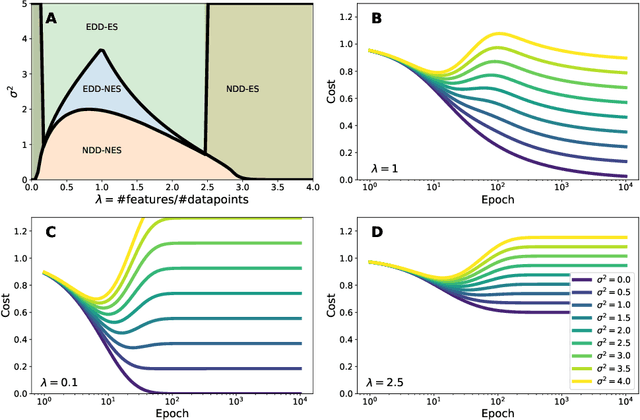
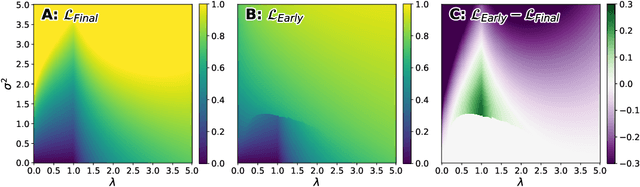
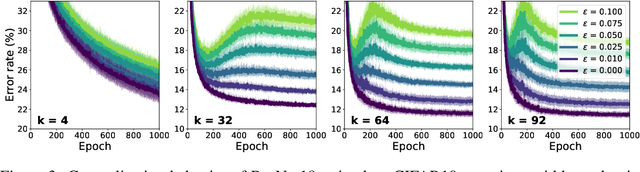
Deep neural networks are known to exhibit a `double descent' behavior as the number of parameters increases. Recently, it has also been shown that an `epochwise double descent' effect exists in which the generalization error initially drops, then rises, and finally drops again with increasing training time. This presents a practical problem in that the amount of time required for training is long, and early stopping based on validation performance may result in suboptimal generalization. In this work we develop an analytically tractable model of epochwise double descent that allows us to characterise theoretically when this effect is likely to occur. This model is based on the hypothesis that the training data contains features that are slow to learn but informative. We then show experimentally that deep neural networks behave similarly to our theoretical model. Our findings indicate that epochwise double descent requires a critical amount of noise to occur, but above a second critical noise level early stopping remains effective. Using insights from theory, we give two methods by which epochwise double descent can be removed: one that removes slow to learn features from the input and reduces generalization performance, and another that instead modifies the training dynamics and matches or exceeds the generalization performance of standard training. Taken together, our results suggest a new picture of how epochwise double descent emerges from the interplay between the dynamics of training and noise in the training data.
Understanding the Logit Distributions of Adversarially-Trained Deep Neural Networks
Aug 26, 2021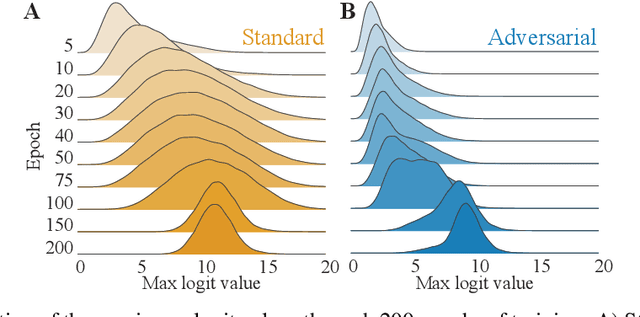

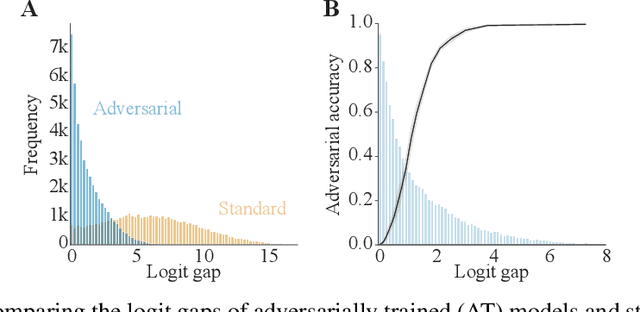

Adversarial defenses train deep neural networks to be invariant to the input perturbations from adversarial attacks. Almost all defense strategies achieve this invariance through adversarial training i.e. training on inputs with adversarial perturbations. Although adversarial training is successful at mitigating adversarial attacks, the behavioral differences between adversarially-trained (AT) models and standard models are still poorly understood. Motivated by a recent study on learning robustness without input perturbations by distilling an AT model, we explore what is learned during adversarial training by analyzing the distribution of logits in AT models. We identify three logit characteristics essential to learning adversarial robustness. First, we provide a theoretical justification for the finding that adversarial training shrinks two important characteristics of the logit distribution: the max logit values and the "logit gaps" (difference between the logit max and next largest values) are on average lower for AT models. Second, we show that AT and standard models differ significantly on which samples are high or low confidence, then illustrate clear qualitative differences by visualizing samples with the largest confidence difference. Finally, we find learning information about incorrect classes to be essential to learning robustness by manipulating the non-max logit information during distillation and measuring the impact on the student's robustness. Our results indicate that learning some adversarial robustness without input perturbations requires a model to learn specific sample-wise confidences and incorrect class orderings that follow complex distributions.
Generalization in multitask deep neural classifiers: a statistical physics approach
Oct 30, 2019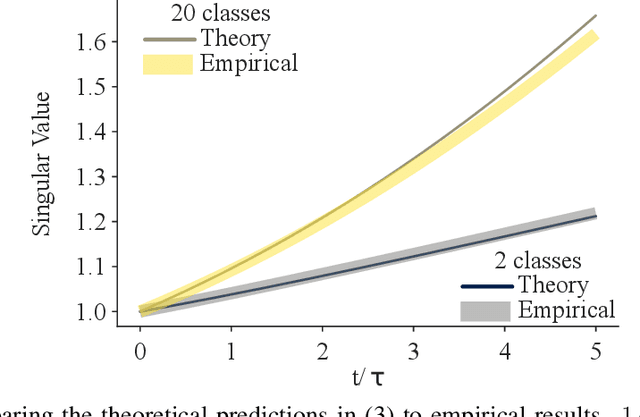

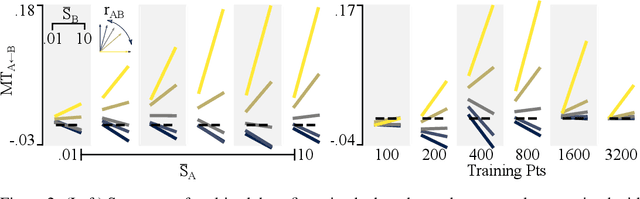
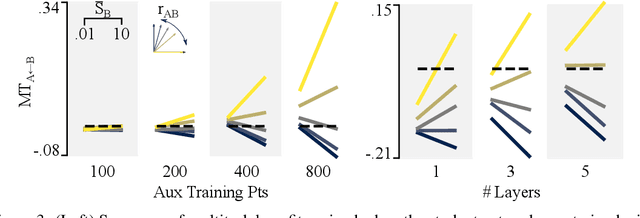
A proper understanding of the striking generalization abilities of deep neural networks presents an enduring puzzle. Recently, there has been a growing body of numerically-grounded theoretical work that has contributed important insights to the theory of learning in deep neural nets. There has also been a recent interest in extending these analyses to understanding how multitask learning can further improve the generalization capacity of deep neural nets. These studies deal almost exclusively with regression tasks which are amenable to existing analytical techniques. We develop an analytic theory of the nonlinear dynamics of generalization of deep neural networks trained to solve classification tasks using softmax outputs and cross-entropy loss, addressing both single task and multitask settings. We do so by adapting techniques from the statistical physics of disordered systems, accounting for both finite size datasets and correlated outputs induced by the training dynamics. We discuss the validity of our theoretical results in comparison to a comprehensive suite of numerical experiments. Our analysis provides theoretical support for the intuition that the performance of multitask learning is determined by the noisiness of the tasks and how well their input features align with each other. Highly related, clean tasks benefit each other, whereas unrelated, clean tasks can be detrimental to individual task performance.
Label-efficient audio classification through multitask learning and self-supervision
Oct 19, 2019
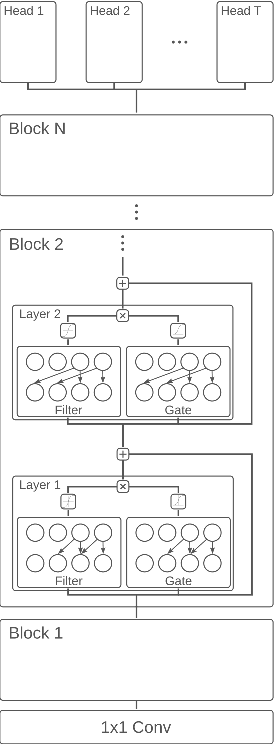
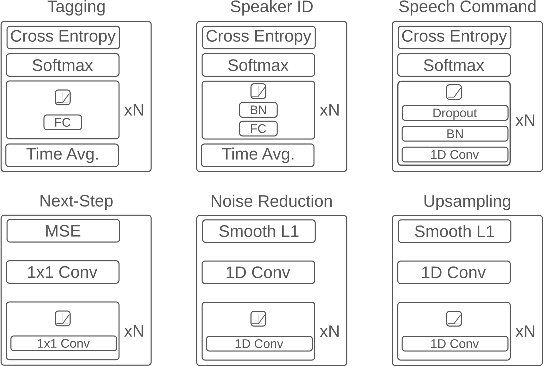
While deep learning has been incredibly successful in modeling tasks with large, carefully curated labeled datasets, its application to problems with limited labeled data remains a challenge. The aim of the present work is to improve the label efficiency of large neural networks operating on audio data through a combination of multitask learning and self-supervised learning on unlabeled data. We trained an end-to-end audio feature extractor based on WaveNet that feeds into simple, yet versatile task-specific neural networks. We describe several easily implemented self-supervised learning tasks that can operate on any large, unlabeled audio corpus. We demonstrate that, in scenarios with limited labeled training data, one can significantly improve the performance of three different supervised classification tasks individually by up to 6% through simultaneous training with these additional self-supervised tasks. We also show that incorporating data augmentation into our multitask setting leads to even further gains in performance.
Many-to-Many Voice Conversion with Out-of-Dataset Speaker Support
Apr 30, 2019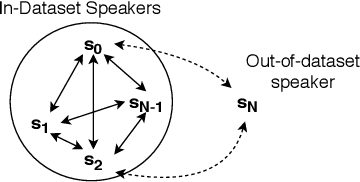
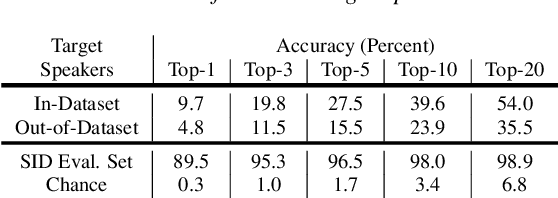
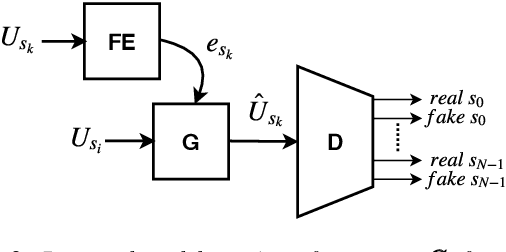

We present a Cycle-GAN based many-to-many voice conversion method that can convert between speakers that are not in the training set. This property is enabled through speaker embeddings generated by a neural network that is jointly trained with the Cycle-GAN. In contrast to prior work in this domain, our method enables conversion between an out-of-dataset speaker and a target speaker in either direction and does not require re-training. Out-of-dataset speaker conversion quality is evaluated using an independently trained speaker identification model, and shows good style conversion characteristics for previously unheard speakers. Subjective tests on human listeners show style conversion quality for in-dataset speakers is comparable to the state-of-the-art baseline model.