 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality
Oct 13, 2021
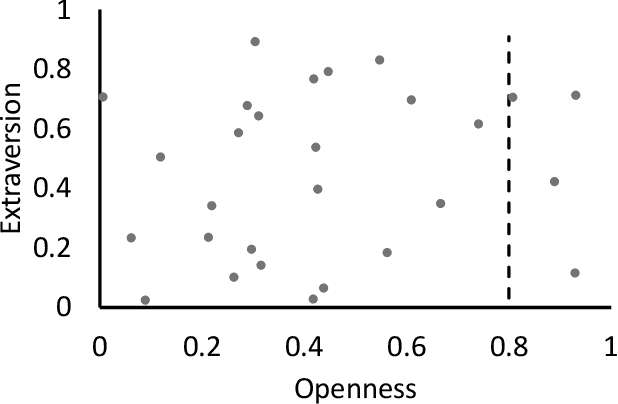
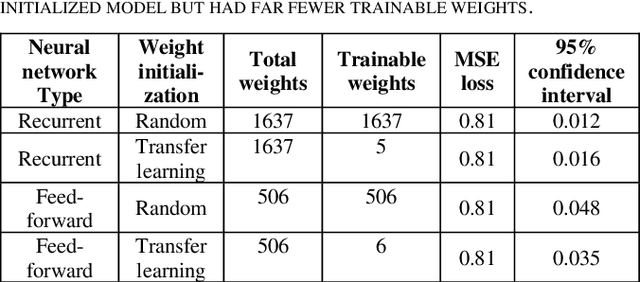
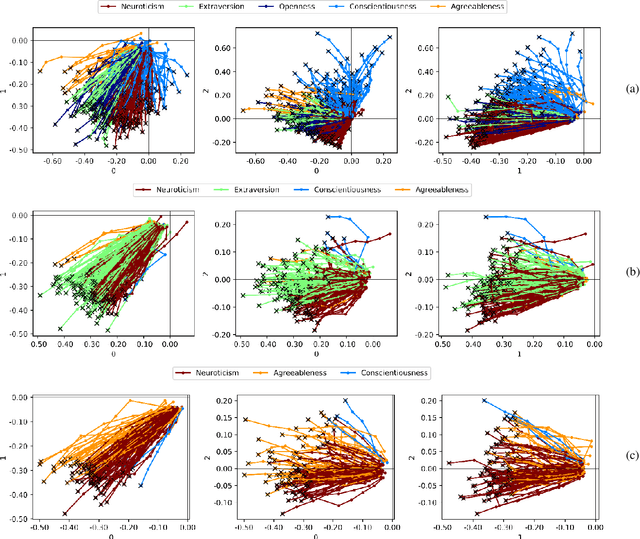
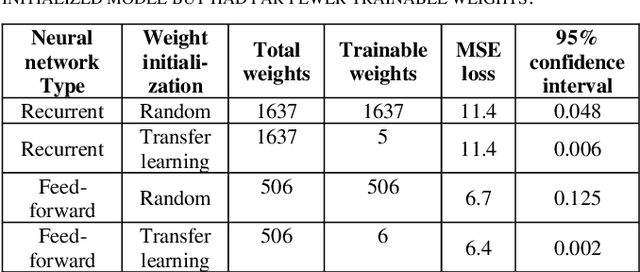
Customer segmentation has long been a productive field in banking. However, with new approaches to traditional problems come new opportunities. Fine-grained customer segments are notoriously elusive and one method of obtaining them is through feature extraction. It is possible to assign coefficients of standard personality traits to financial transaction classes aggregated over time. However, we have found that the clusters formed are not sufficiently discriminatory for micro-segmentation. In a novel approach, we extract temporal features with continuous values from the hidden states of neural networks predicting customers' spending personality from their financial transactions. We consider both temporal and non-sequential models, using long short-term memory (LSTM) and feed-forward neural networks, respectively. We found that recurrent neural networks produce micro-segments where feed-forward networks produce only coarse segments. Finally, we show that classification using these extracted features performs at least as well as bespoke models on two common metrics, namely loan default rate and customer liquidity index.
PIMIP: An Open Source Platform for Pathology Information Management and Integration
Nov 09, 2021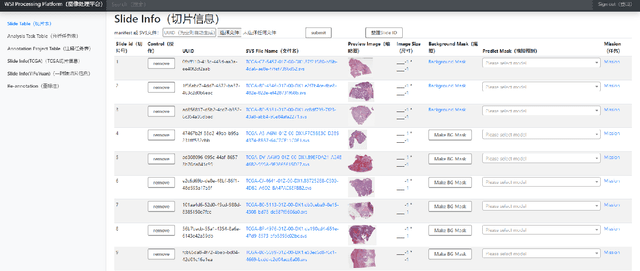
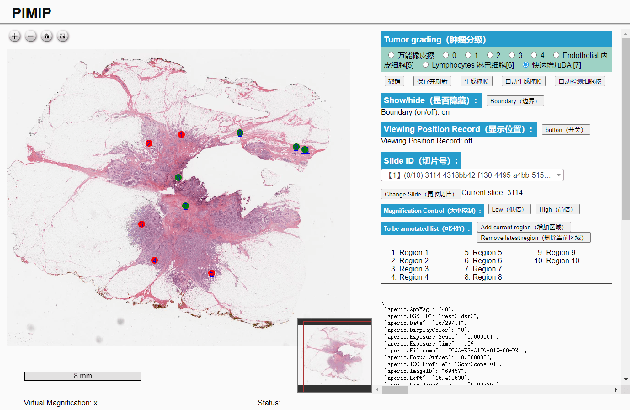
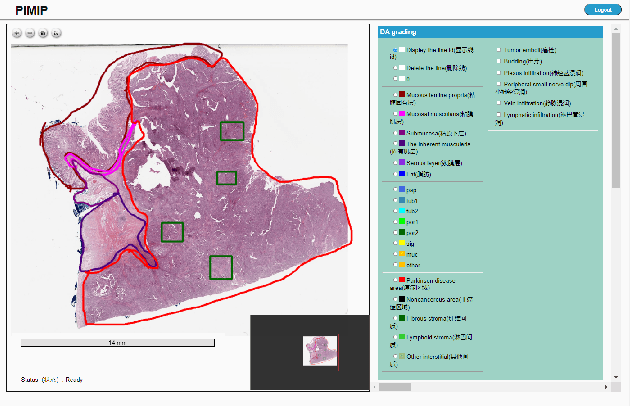
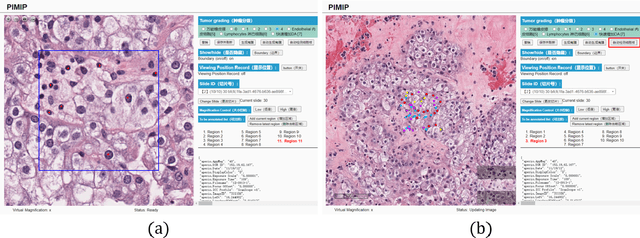
Digital pathology plays a crucial role in the development of artificial intelligence in the medical field. The digital pathology platform can make the pathological resources digital and networked, and realize the permanent storage of visual data and the synchronous browsing processing without the limitation of time and space. It has been widely used in various fields of pathology. However, there is still a lack of an open and universal digital pathology platform to assist doctors in the management and analysis of digital pathological sections, as well as the management and structured description of relevant patient information. Most platforms cannot integrate image viewing, annotation and analysis, and text information management. To solve the above problems, we propose a comprehensive and extensible platform PIMIP. Our PIMIP has developed the image annotation functions based on the visualization of digital pathological sections. Our annotation functions support multi-user collaborative annotation and multi-device annotation, and realize the automation of some annotation tasks. In the annotation task, we invited a professional pathologist for guidance. We introduce a machine learning module for image analysis. The data we collected included public data from local hospitals and clinical examples. Our platform is more clinical and suitable for clinical use. In addition to image data, we also structured the management and display of text information. So our platform is comprehensive. The platform framework is built in a modular way to support users to add machine learning modules independently, which makes our platform extensible.
Universal Paralinguistic Speech Representations Using Self-Supervised Conformers
Oct 09, 2021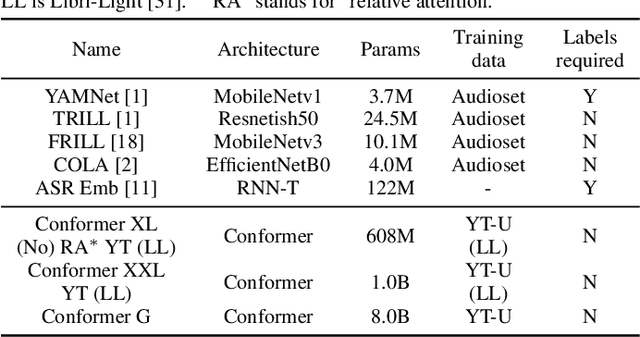
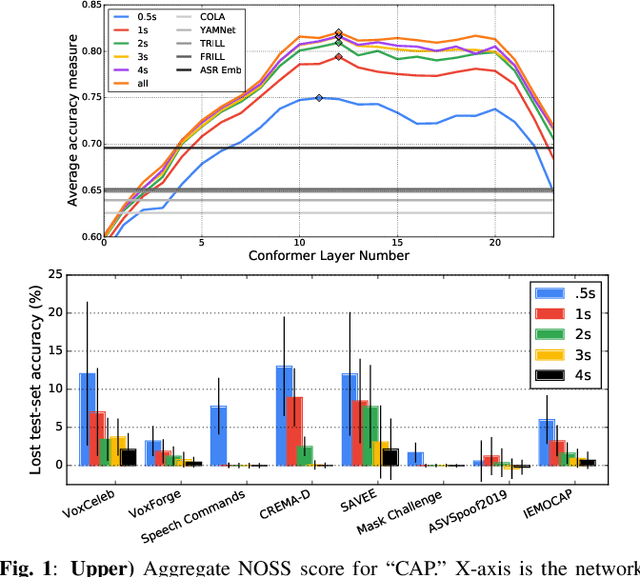
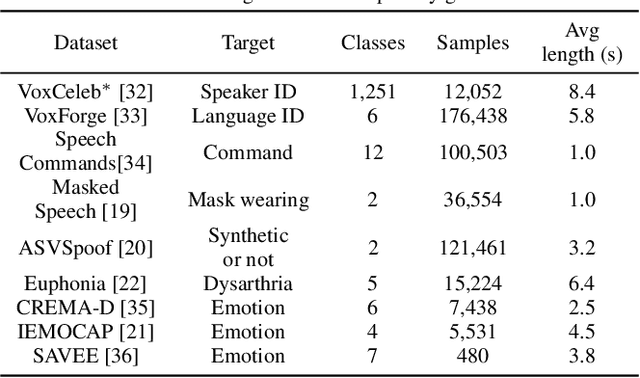
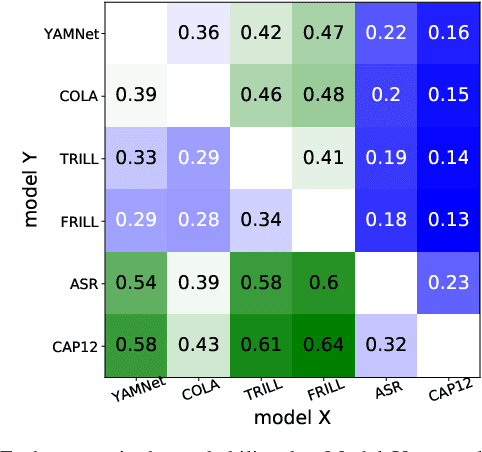
Many speech applications require understanding aspects beyond the words being spoken, such as recognizing emotion, detecting whether the speaker is wearing a mask, or distinguishing real from synthetic speech. In this work, we introduce a new state-of-the-art paralinguistic representation derived from large-scale, fully self-supervised training of a 600M+ parameter Conformer-based architecture. We benchmark on a diverse set of speech tasks and demonstrate that simple linear classifiers trained on top of our time-averaged representation outperform nearly all previous results, in some cases by large margins. Our analyses of context-window size demonstrate that, surprisingly, 2 second context-windows achieve 98% the performance of the Conformers that use the full long-term context. Furthermore, while the best per-task representations are extracted internally in the network, stable performance across several layers allows a single universal representation to reach near optimal performance on all tasks.
A Spatial-temporal Graph Deep Learning Model for Urban Flood Nowcasting Leveraging Heterogeneous Community Features
Nov 17, 2021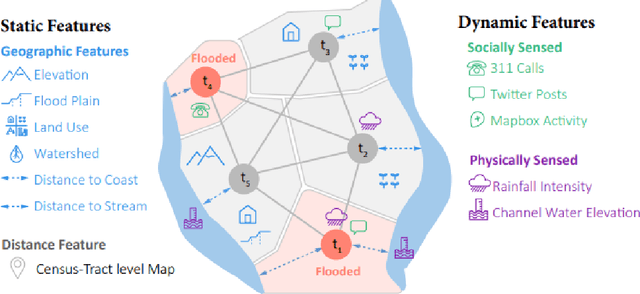
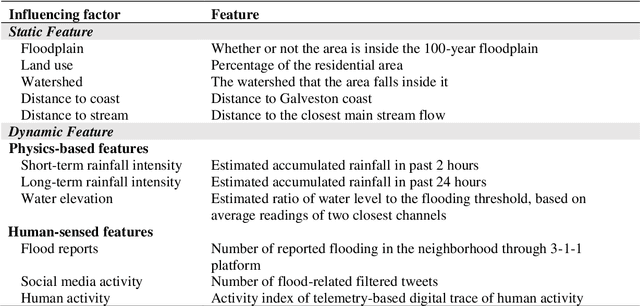
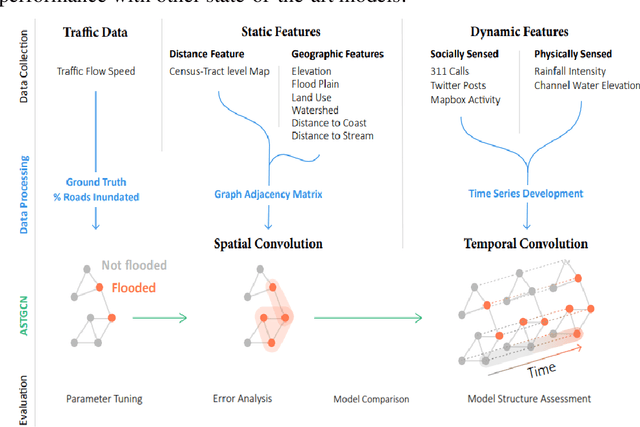
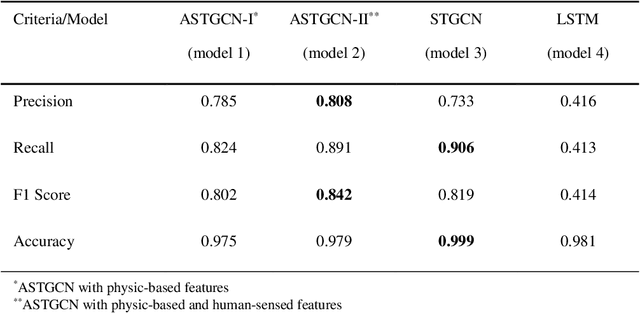
The objective of this study is to develop and test a novel structured deep-learning modeling framework for urban flood nowcasting by integrating physics-based and human-sensed features. We present a new computational modeling framework including an attention-based spatial-temporal graph convolution network (ASTGCN) model and different streams of data that are collected in real-time, preprocessed, and fed into the model to consider spatial and temporal information and dependencies that improve flood nowcasting. The novelty of the computational modeling framework is threefold; first, the model is capable of considering spatial and temporal dependencies in inundation propagation thanks to the spatial and temporal graph convolutional modules; second, it enables capturing the influence of heterogeneous temporal data streams that can signal flooding status, including physics-based features such as rainfall intensity and water elevation, and human-sensed data such as flood reports and fluctuations of human activity. Third, its attention mechanism enables the model to direct its focus on the most influential features that vary dynamically. We show the application of the modeling framework in the context of Harris County, Texas, as the case study and Hurricane Harvey as the flood event. Results indicate that the model provides superior performance for the nowcasting of urban flood inundation at the census tract level, with a precision of 0.808 and a recall of 0.891, which shows the model performs better compared with some other novel models. Moreover, ASTGCN model performance improves when heterogeneous dynamic features are added into the model that solely relies on physics-based features, which demonstrates the promise of using heterogenous human-sensed data for flood nowcasting,
Can an AI agent hit a moving target?
Oct 06, 2021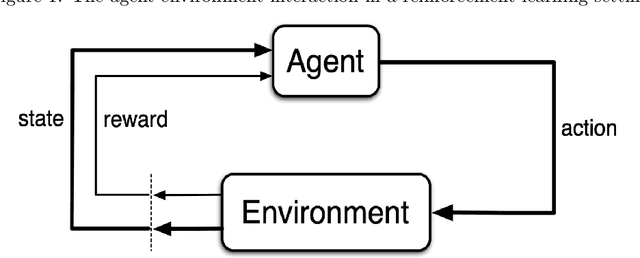

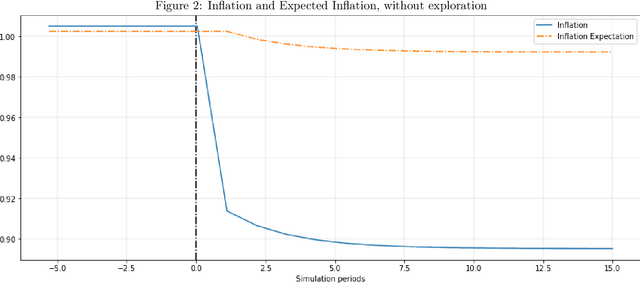
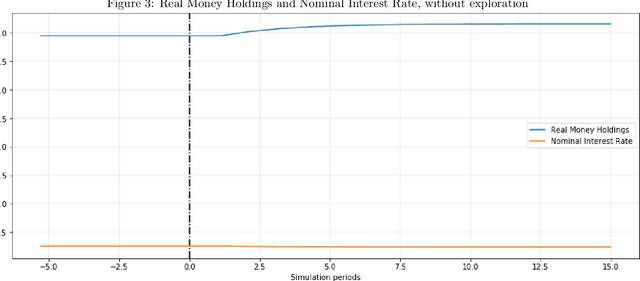
As the economies we live in are evolving over time, it is imperative that economic agents in models form expectations that can adjust to changes in the environment. This exercise offers a plausible expectation formation model that connects to computer science, psychology and neural science research on learning and decision-making, and applies it to an economy with a policy regime change. Employing the actor-critic model of reinforcement learning, the agent born in a fresh environment learns through first interacting with the environment. This involves taking exploratory actions and observing the corresponding stimulus signals. This interactive experience is then used to update its subjective belief about the world. I show, through several simulation experiments, that the agent adjusts its subjective belief facing an increase of inflation target. Moreover, the subjective belief evolves according to the agent's experience in the world.
On Selecting Stable Predictors in Time Series Models
May 18, 2019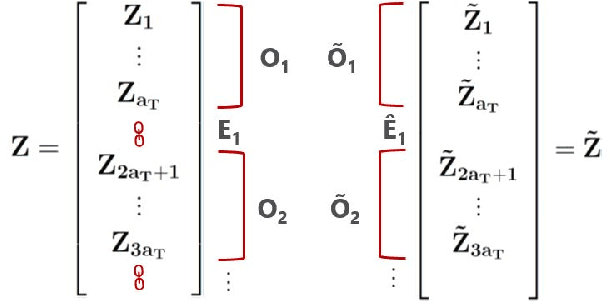
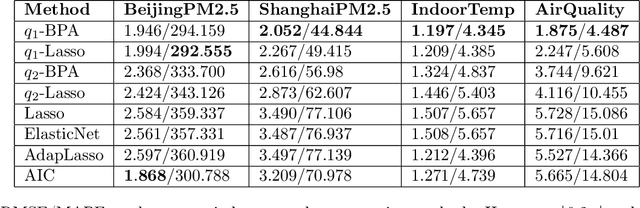
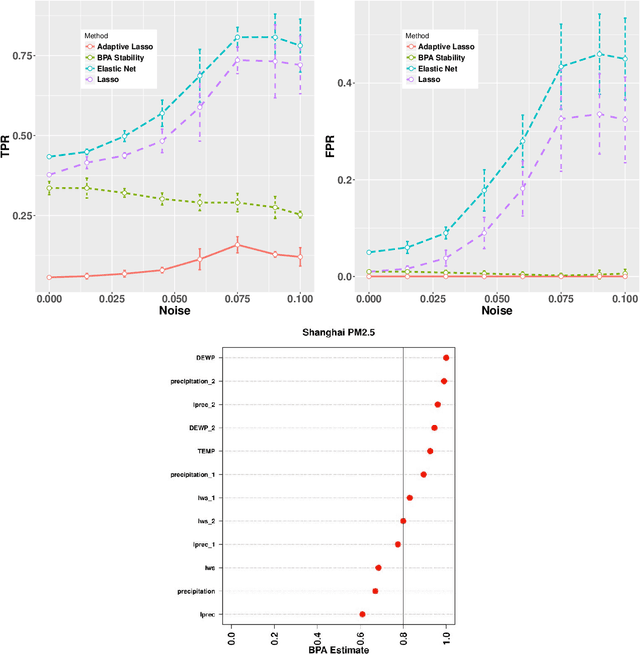
We extend the feature selection methodology to dependent data and propose a novel time series predictor selection scheme that accommodates statistical dependence in a more typical i.i.d sub-sampling based framework. Furthermore, the machinery of mixing stationary processes allows us to quantify the improvements of our approach over any base predictor selection method (such as lasso) even in a finite sample setting. Using the lasso as a base procedure we demonstrate the applicability of our methods to simulated and several real time series datasets.
Unsupervised Learning of Deep Features for Music Segmentation
Aug 30, 2021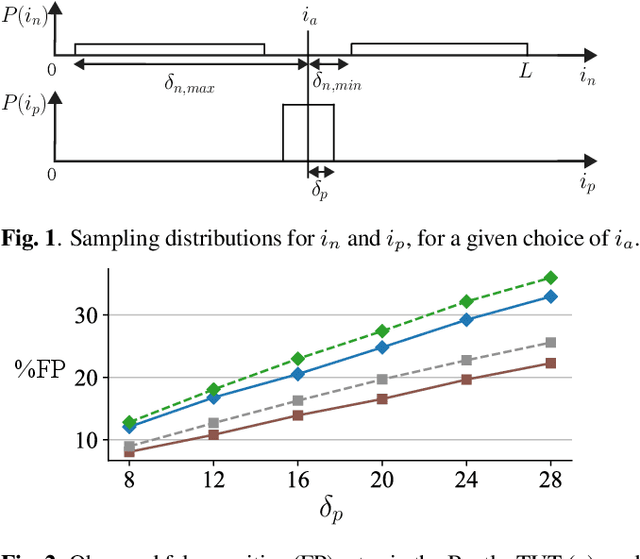
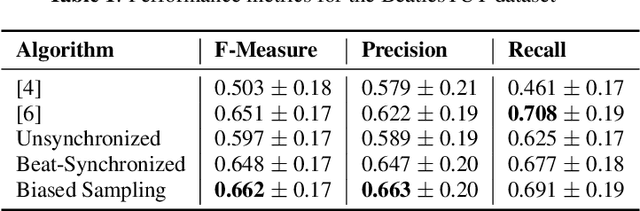

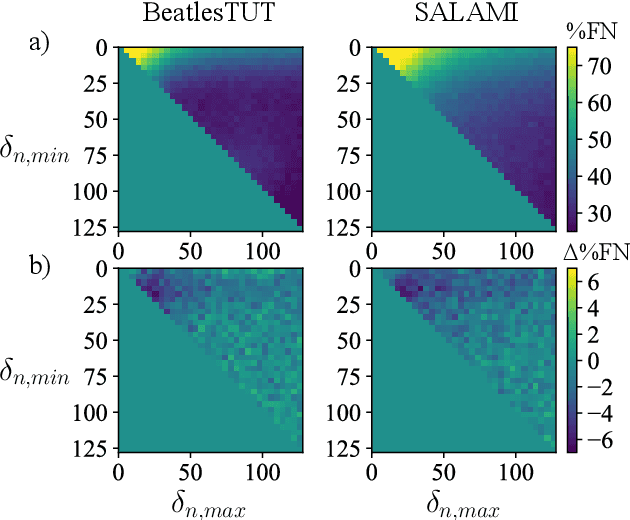
Music segmentation refers to the dual problem of identifying boundaries between, and labeling, distinct music segments, e.g., the chorus, verse, bridge etc. in popular music. The performance of a range of music segmentation algorithms has been shown to be dependent on the audio features chosen to represent the audio. Some approaches have proposed learning feature transformations from music segment annotation data, although, such data is time consuming or expensive to create and as such these approaches are likely limited by the size of their datasets. While annotated music segmentation data is a scarce resource, the amount of available music audio is much greater. In the neighboring field of semantic audio unsupervised deep learning has shown promise in improving the performance of solutions to the query-by-example and sound classification tasks. In this work, unsupervised training of deep feature embeddings using convolutional neural networks (CNNs) is explored for music segmentation. The proposed techniques exploit only the time proximity of audio features that is implicit in any audio timeline. Employing these embeddings in a classic music segmentation algorithm is shown not only to significantly improve the performance of this algorithm, but obtain state of the art performance in unsupervised music segmentation.
Passive Phased Array Acoustic Emission Localisation via Recursive Signal-Averaged Lamb Waves with an Applied Warped Frequency Transformation
Oct 13, 2021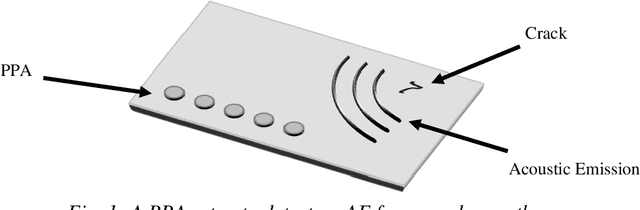

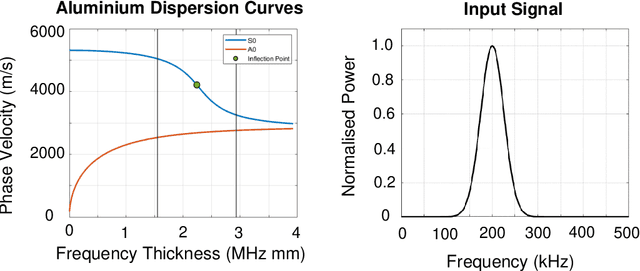

This work presents a concept for the localisation of Lamb waves using a Passive Phased Array (PPA). A Warped Frequency Transformation (WFT) is applied to the acquired signals using numerically determined phase velocity information to compensate for signal dispersion. Whilst powerful, uncertainty between material properties cannot completely remove dispersion and hence the close intra-element spacing of the array is leveraged to allow for the assumption that each acquired signal is a scaled, translated, and noised copy of its adjacent counterparts. Following this, a recursive signal-averaging method using artificial time-locking to denoise the acquired signals by assuming the presence of non-correlated, zero mean noise is applied. Unlike the application of bandpass filters, the signal-averaging method does not remove potentially useful frequency components. The proposed methodology is compared against a bandpass filtered approach through a parametric study. A further discussion is made regarding applications and future developments of this technique.
Application of Machine Learning to Sleep Stage Classification
Nov 04, 2021
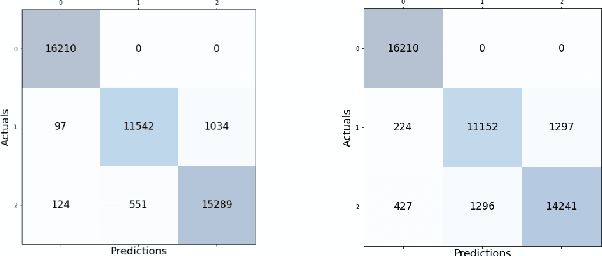
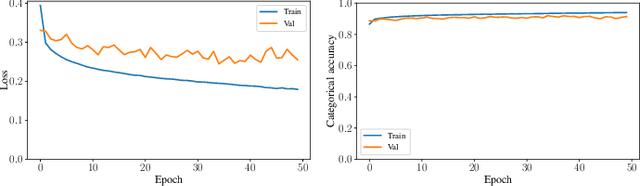
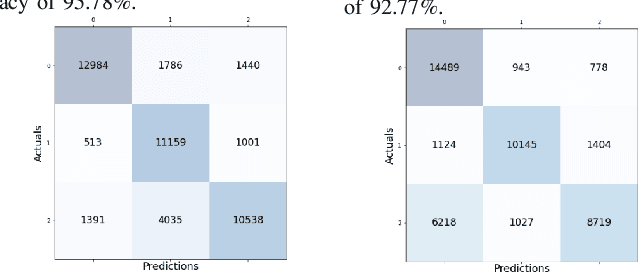
Sleep studies are imperative to recapitulate phenotypes associated with sleep loss and uncover mechanisms contributing to psychopathology. Most often, investigators manually classify the polysomnography into vigilance states, which is time-consuming, requires extensive training, and is prone to inter-scorer variability. While many works have successfully developed automated vigilance state classifiers based on multiple EEG channels, we aim to produce an automated and open-access classifier that can reliably predict vigilance state based on a single cortical electroencephalogram (EEG) from rodents to minimize the disadvantages that accompany tethering small animals via wires to computer programs. Approximately 427 hours of continuously monitored EEG, electromyogram (EMG), and activity were labeled by a domain expert out of 571 hours of total data. Here we evaluate the performance of various machine learning techniques on classifying 10-second epochs into one of three discrete classes: paradoxical, slow-wave, or wake. Our investigations include Decision Trees, Random Forests, Naive Bayes Classifiers, Logistic Regression Classifiers, and Artificial Neural Networks. These methodologies have achieved accuracies ranging from approximately 74% to approximately 96%. Most notably, the Random Forest and the ANN achieved remarkable accuracies of 95.78% and 93.31%, respectively. Here we have shown the potential of various machine learning classifiers to automatically, accurately, and reliably classify vigilance states based on a single EEG reading and a single EMG reading.
Efficacy the of Confinement Policies on the COVID-19 Spread Dynamics in the Early Period of the Pandemic
Nov 04, 2021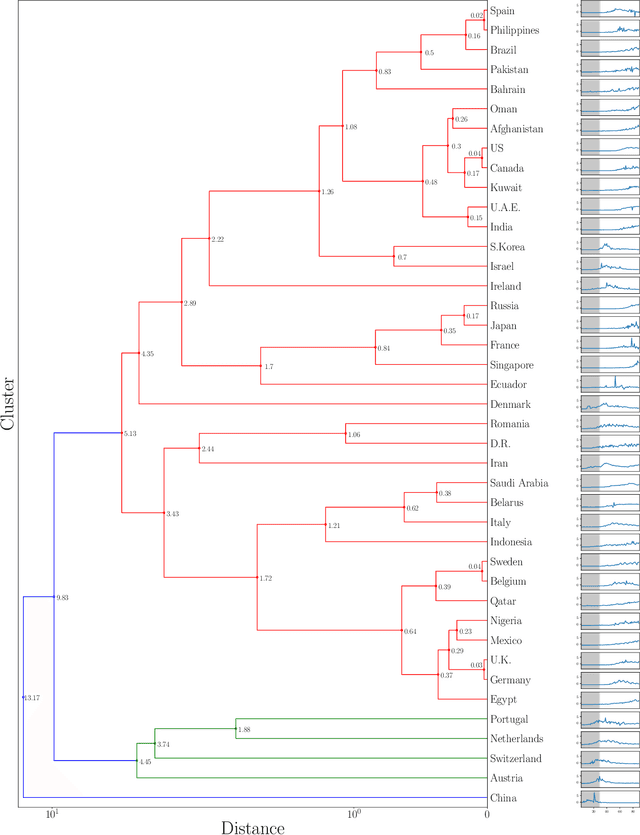
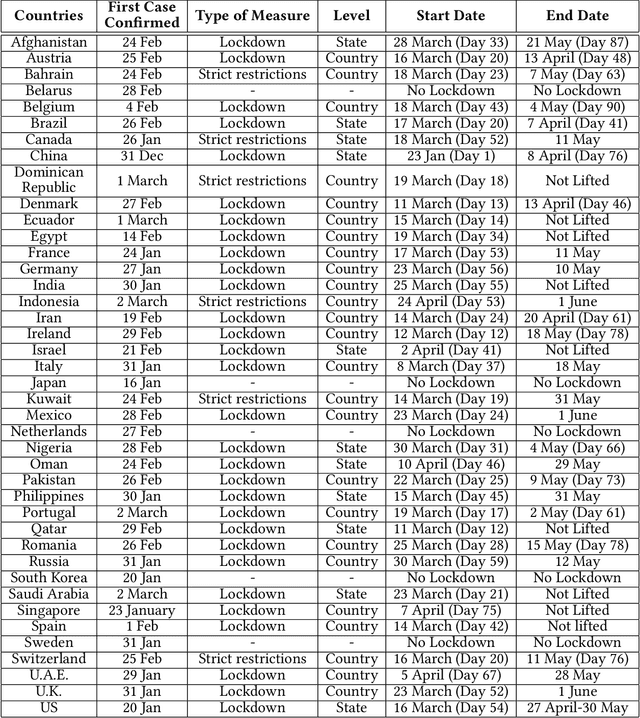
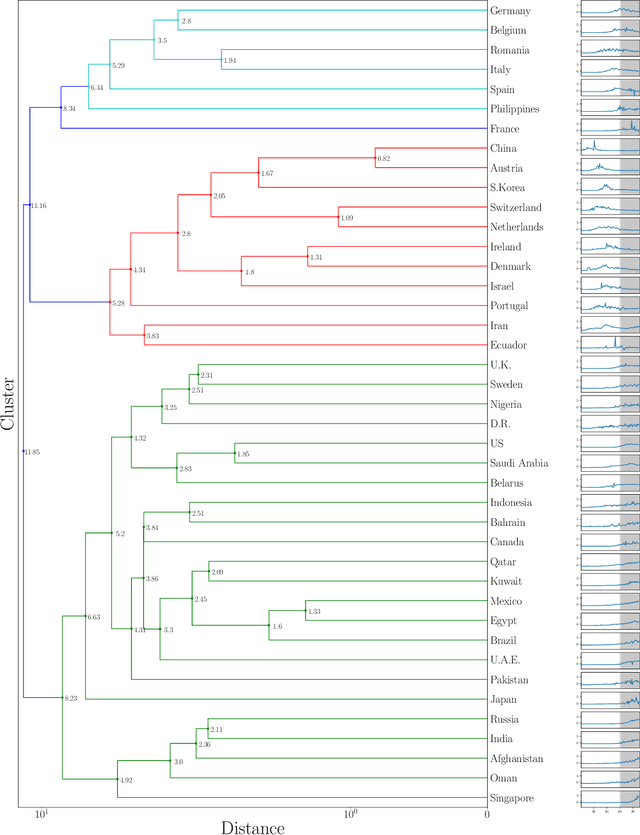
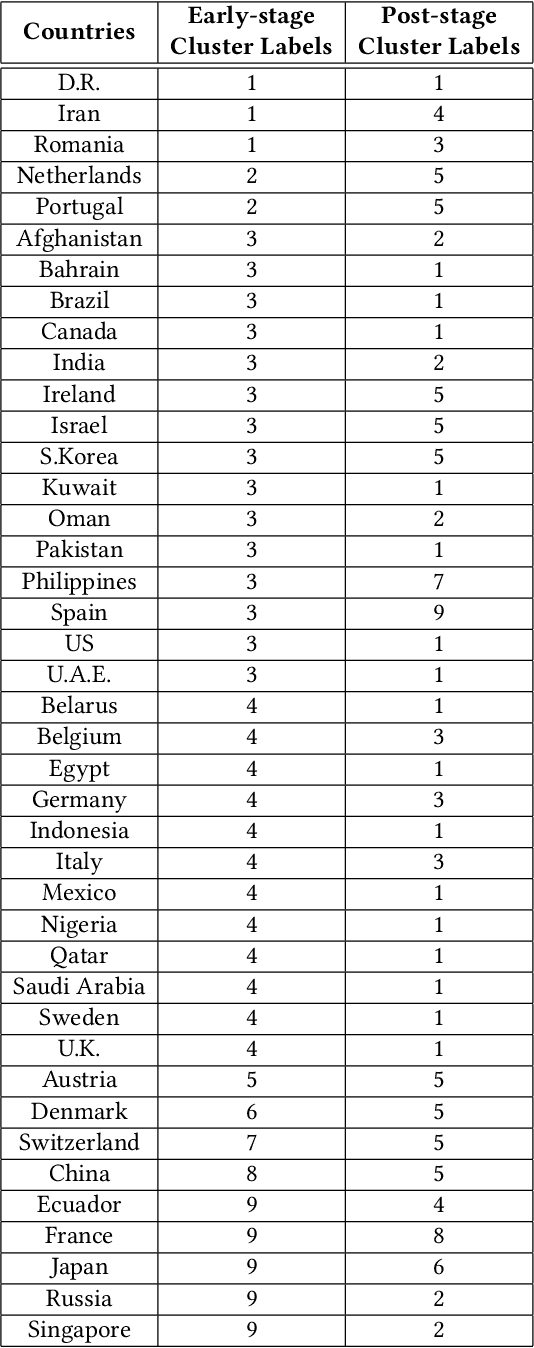
In this study, we propose a clustering-based approach on time-series data to capture COVID-19 spread patterns in the early period of the pandemic. We analyze the spread dynamics based on the early and post stages of COVID-19 for different countries based on different geographical locations. Furthermore, we investigate the confinement policies and the effect they made on the spread. We found that implementations of the same confinement policies exhibit different results in different countries. Specifically, lockdowns become less effective in densely populated regions, because of the reluctance to comply with social distancing measures. Lack of testing, contact tracing, and social awareness in some countries forestall people from self-isolation and maintaining social distance. Large labor camps with unhealthy living conditions also aid in high community transmissions in countries depending on foreign labor. Distrust in government policies and fake news instigate the spread in both developed and under-developed countries. Large social gatherings play a vital role in causing rapid outbreaks almost everywhere. While some countries were able to contain the spread by implementing strict and widely adopted confinement policies, some others contained the spread with the help of social distancing measures and rigorous testing capacity. An early and rapid response at the beginning of the pandemic is necessary to contain the spread, yet it is not always sufficient.