 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model reduction for the material point method via learning the deformation map and its spatial-temporal gradients
Sep 25, 2021
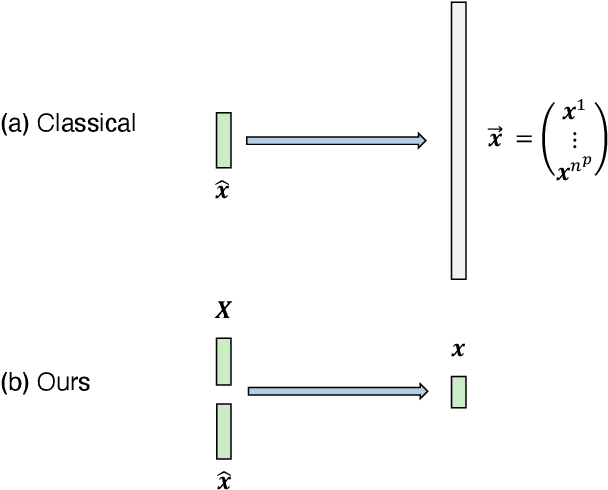
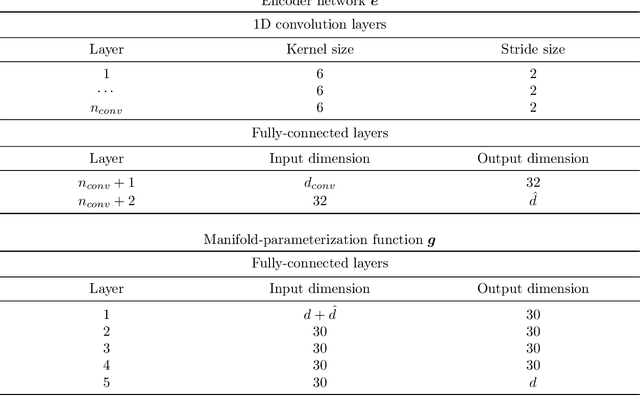
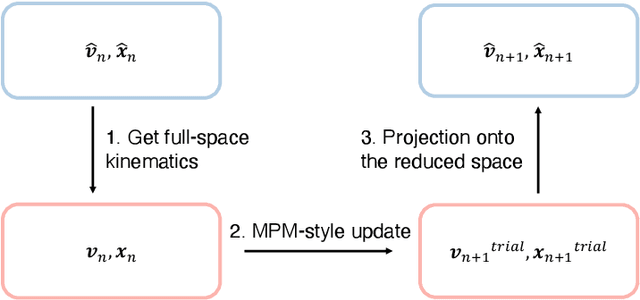

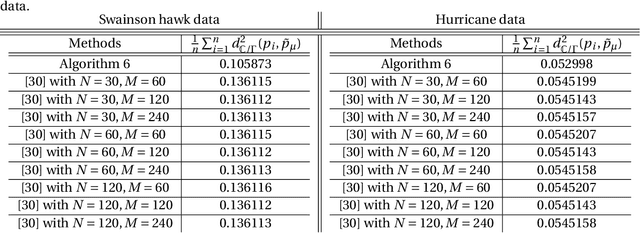
This work proposes a model-reduction approach for the material point method on nonlinear manifolds. The technique approximates the $\textit{kinematics}$ by approximating the deformation map in a manner that restricts deformation trajectories to reside on a low-dimensional manifold expressed from the extrinsic view via a parameterization function. By explicitly approximating the deformation map and its spatial-temporal gradients, the deformation gradient and the velocity can be computed simply by differentiating the associated parameterization function. Unlike classical model reduction techniques that build a subspace for a finite number of degrees of freedom, the proposed method approximates the entire deformation map with infinite degrees of freedom. Therefore, the technique supports resolution changes in the reduced simulation, attaining the challenging task of zero-shot super-resolution by generating material points unseen in the training data. The ability to generate material points also allows for adaptive quadrature rules for stress update. A family of projection methods is devised to generate $\textit{dynamics}$, i.e., at every time step, the methods perform three steps: (1) generate quadratures in the full space from the reduced space, (2) compute position and velocity updates in the full space, and (3) perform a least-squares projection of the updated position and velocity onto the low-dimensional manifold and its tangent space. Computational speedup is achieved via hyper-reduction, i.e., only a subset of the original material points are needed for dynamics update. Large-scale numerical examples with millions of material points illustrate the method's ability to gain an order-of-magnitude computational-cost saving -- indeed $\textit{real-time simulations}$ in some cases -- with negligible errors.
Amplitude Mean of Functional Data on $\mathbb{S}^2$
Aug 18, 2021

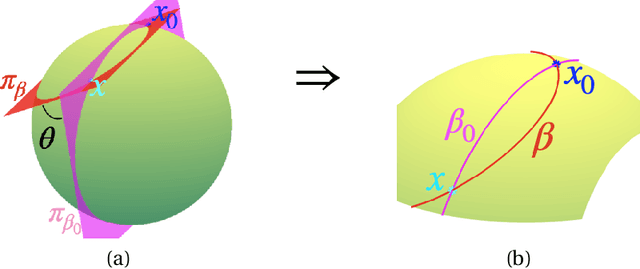
Manifold-valued functional data analysis (FDA) recently becomes an active area of research motivated by the raising availability of trajectories or longitudinal data observed on non-linear manifolds. The challenges of analyzing such data come from many aspects, including infinite dimensionality and nonlinearity, as well as time-domain or phase variability. In this paper, we study the amplitude part of manifold-valued functions on $\mathbb{S}^2$, which is invariant to random time warping or re-parameterization. Utilizing the nice geometry of $\mathbb{S}^2$, we develop a set of efficient and accurate tools for temporal alignment of functions, geodesic computing, and sample mean calculation. At the heart of these tools, they rely on gradient descent algorithms with carefully derived gradients. We show the advantages of these newly developed tools over its competitors with extensive simulations and real data and demonstrate the importance of considering the amplitude part of functions instead of mixing it with phase variability in manifold-valued FDA.
Retro-Actions: Learning 'Close' by Time-Reversing 'Open' Videos
Sep 20, 2019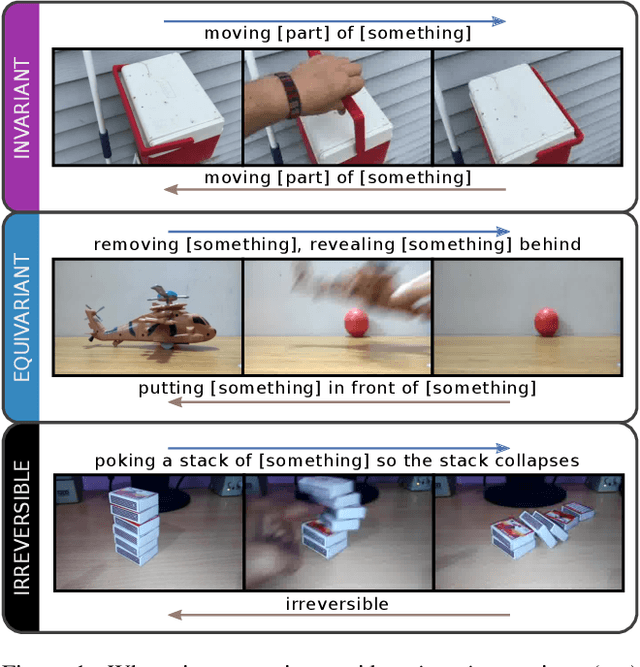
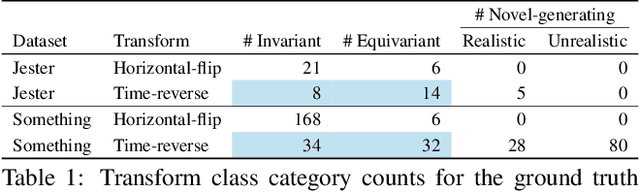

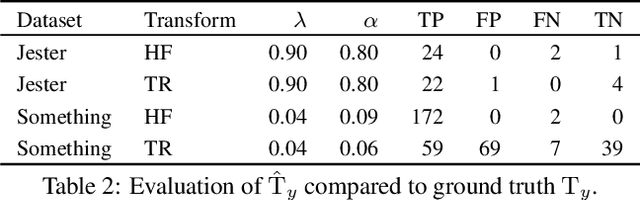
We investigate video transforms that result in class-homogeneous label-transforms. These are video transforms that consistently maintain or modify the labels of all videos in each class. We propose a general approach to discover invariant classes, whose transformed examples maintain their label; pairs of equivariant classes, whose transformed examples exchange their labels; and novel-generating classes, whose transformed examples belong to a new class outside the dataset. Label transforms offer additional supervision previously unexplored in video recognition benefiting data augmentation and enabling zero-shot learning opportunities by learning a class from transformed videos of its counterpart. Amongst such video transforms, we study horizontal-flipping, time-reversal, and their composition. We highlight errors in naively using horizontal-flipping as a form of data augmentation in video. Next, we validate the realism of time-reversed videos through a human perception study where people exhibit equal preference for forward and time-reversed videos. Finally, we test our approach on two datasets, Jester and Something-Something, evaluating the three video transforms for zero-shot learning and data augmentation. Our results show that gestures such as zooming in can be learnt from zooming out in a zero-shot setting, as well as more complex actions with state transitions such as digging something out of something from burying something in something.
DECAF: Generating Fair Synthetic Data Using Causally-Aware Generative Networks
Oct 25, 2021
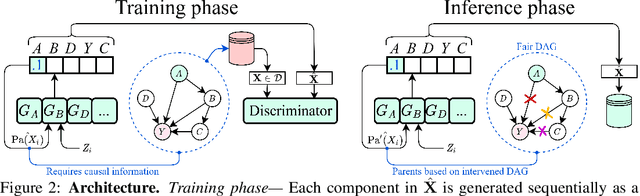
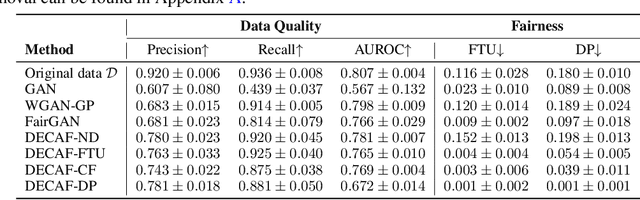
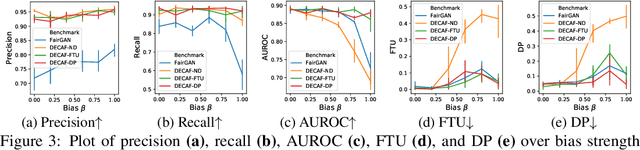
Machine learning models have been criticized for reflecting unfair biases in the training data. Instead of solving for this by introducing fair learning algorithms directly, we focus on generating fair synthetic data, such that any downstream learner is fair. Generating fair synthetic data from unfair data - while remaining truthful to the underlying data-generating process (DGP) - is non-trivial. In this paper, we introduce DECAF: a GAN-based fair synthetic data generator for tabular data. With DECAF we embed the DGP explicitly as a structural causal model in the input layers of the generator, allowing each variable to be reconstructed conditioned on its causal parents. This procedure enables inference time debiasing, where biased edges can be strategically removed for satisfying user-defined fairness requirements. The DECAF framework is versatile and compatible with several popular definitions of fairness. In our experiments, we show that DECAF successfully removes undesired bias and - in contrast to existing methods - is capable of generating high-quality synthetic data. Furthermore, we provide theoretical guarantees on the generator's convergence and the fairness of downstream models.
Scalable Channel Estimation and Reflection Optimization for Reconfigurable Intelligent Surface-Enhanced OFDM Systems
Oct 25, 2021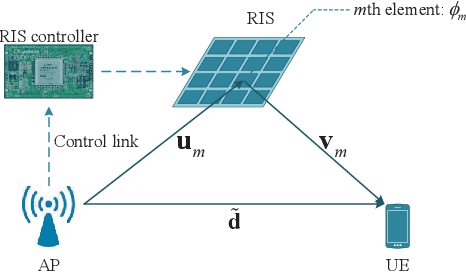
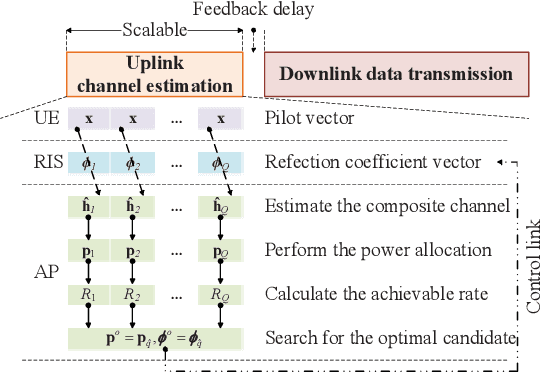
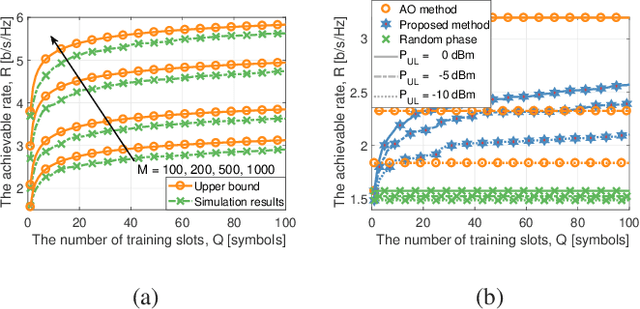
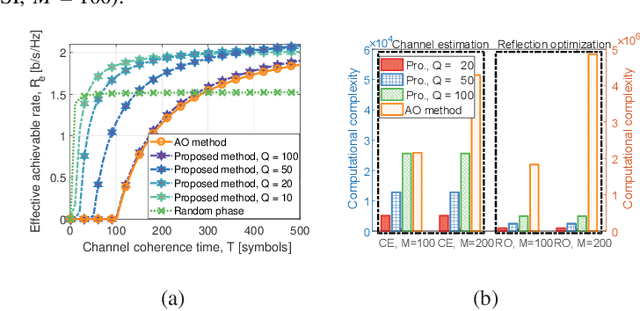
This paper proposes a scalable channel estimation and reflection optimization framework for reconfigurable intelligent surface (RIS)-enhanced orthogonal frequency division multiplexing (OFDM) systems. Specifically, the proposed scheme firstly generates a training set of RIS reflection coefficient vectors offline. For each RIS reflection coefficient vector in the training set, the proposed scheme estimates only the end-to-end composite channel and then performs the transmit power allocation. As a result, the RIS reflection optimization is simplified by searching for the optimal reflection coefficient vector maximizing the achievable rate from the pre-designed training set. The proposed scheme is capable of flexibly adjusting the training overhead according to the given channel coherence time, which is in sharp contrast to the conventional counterparts. Moreover, we discuss the computational complexity of the proposed scheme and analyze the theoretical scaling law of the achievable rate versus the number of training slots. Finally, simulation results demonstrate that the proposed scheme is superior to existing approaches in terms of decreasing training overhead, reducing complexity as well as improving rate performance in the presence of channel estimation errors.
Quantum Boosting using Domain-Partitioning Hypotheses
Oct 25, 2021
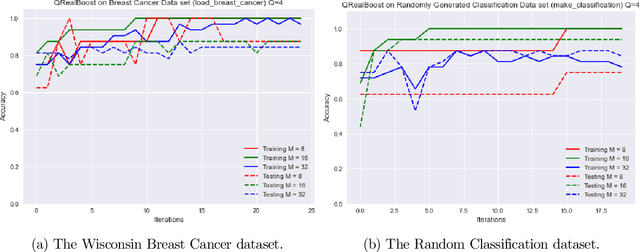
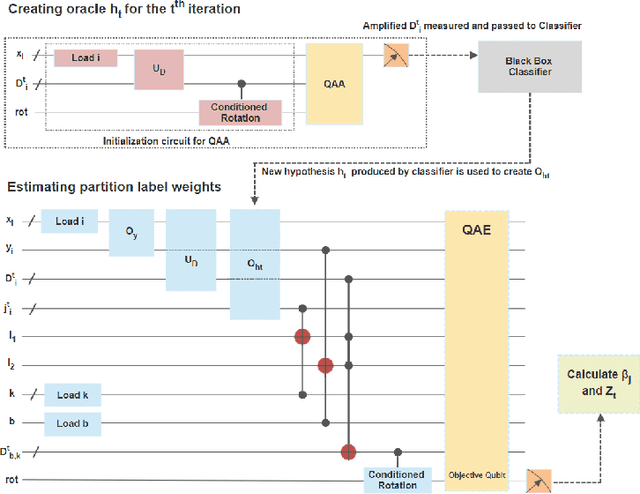
Boosting is an ensemble learning method that converts a weak learner into a strong learner in the PAC learning framework. Freund and Schapire gave the first classical boosting algorithm for binary hypothesis known as AdaBoost, and this was recently adapted into a quantum boosting algorithm by Arunachalam et al. Their quantum boosting algorithm (which we refer to as Q-AdaBoost) is quadratically faster than the classical version in terms of the VC-dimension of the hypothesis class of the weak learner but polynomially worse in the bias of the weak learner. In this work we design a different quantum boosting algorithm that uses domain partitioning hypotheses that are significantly more flexible than those used in prior quantum boosting algorithms in terms of margin calculations. Our algorithm Q-RealBoost is inspired by the "Real AdaBoost" (aka. RealBoost) extension to the original AdaBoost algorithm. Further, we show that Q-RealBoost provides a polynomial speedup over Q-AdaBoost in terms of both the bias of the weak learner and the time taken by the weak learner to learn the target concept class.
Dictionary Learning with Convex Update (ROMD)
Oct 25, 2021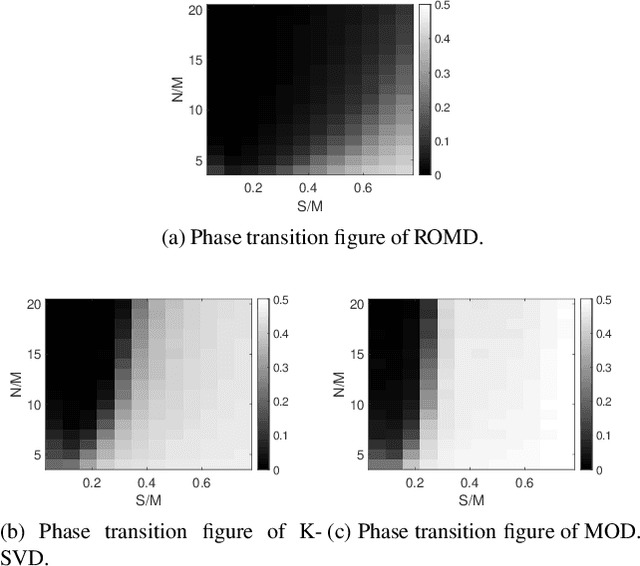
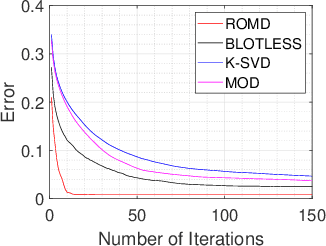
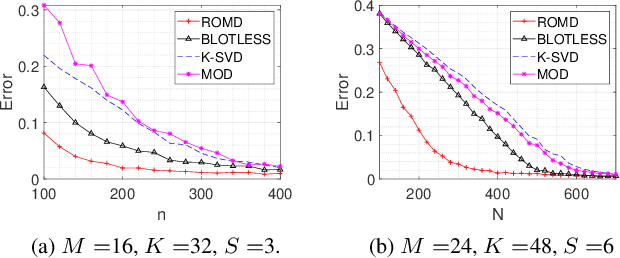
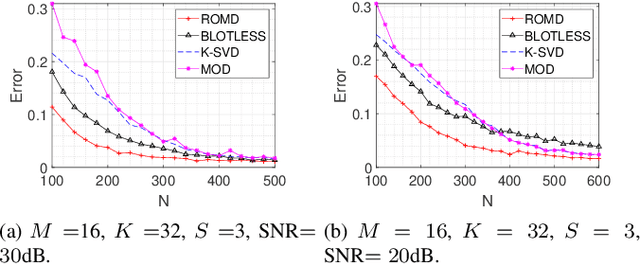
Dictionary learning aims to find a dictionary under which the training data can be sparsely represented, and it is usually achieved by iteratively applying two stages: sparse coding and dictionary update. Typical methods for dictionary update focuses on refining both dictionary atoms and their corresponding sparse coefficients by using the sparsity patterns obtained from sparse coding stage, and hence it is a non-convex bilinear inverse problem. In this paper, we propose a Rank-One Matrix Decomposition (ROMD) algorithm to recast this challenge into a convex problem by resolving these two variables into a set of rank-one matrices. Different from methods in the literature, ROMD updates the whole dictionary at a time using convex programming. The advantages hence include both convergence guarantees for dictionary update and faster convergence of the whole dictionary learning. The performance of ROMD is compared with other benchmark dictionary learning algorithms. The results show the improvement of ROMD in recovery accuracy, especially in the cases of high sparsity level and fewer observation data.
Spatio-Temporal Self-Attention Network for Video Saliency Prediction
Aug 24, 2021
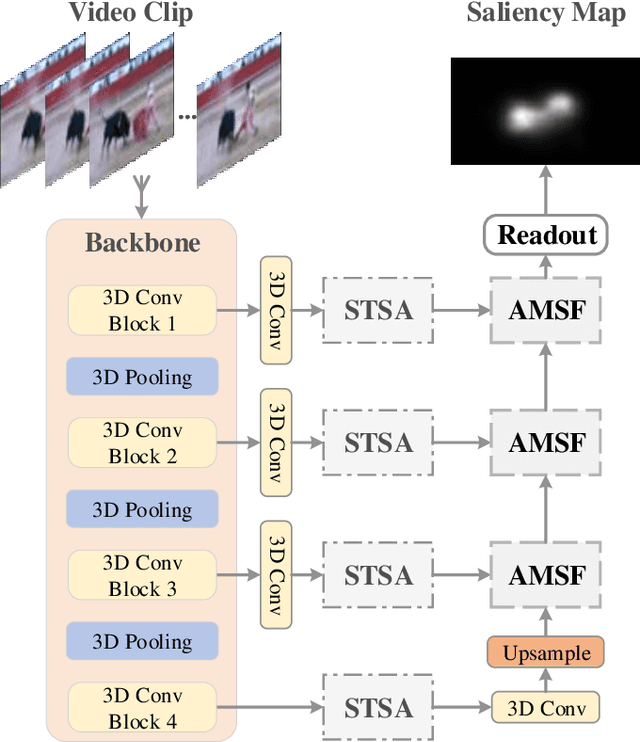
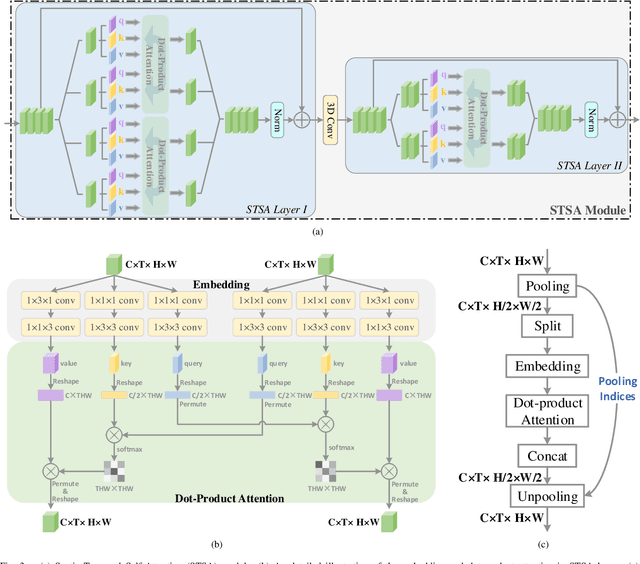
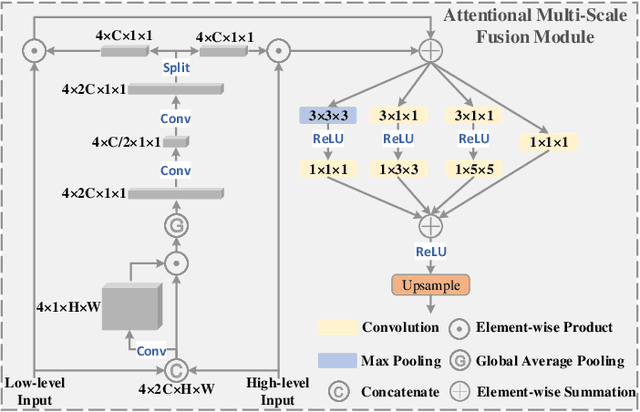
3D convolutional neural networks have achieved promising results for video tasks in computer vision, including video saliency prediction that is explored in this paper. However, 3D convolution encodes visual representation merely on fixed local spacetime according to its kernel size, while human attention is always attracted by relational visual features at different time of a video. To overcome this limitation, we propose a novel Spatio-Temporal Self-Attention 3D Network (STSANet) for video saliency prediction, in which multiple Spatio-Temporal Self-Attention (STSA) modules are employed at different levels of 3D convolutional backbone to directly capture long-range relations between spatio-temporal features of different time steps. Besides, we propose an Attentional Multi-Scale Fusion (AMSF) module to integrate multi-level features with the perception of context in semantic and spatio-temporal subspaces. Extensive experiments demonstrate the contributions of key components of our method, and the results on DHF1K, Hollywood-2, UCF, and DIEM benchmark datasets clearly prove the superiority of the proposed model compared with all state-of-the-art models.
Reception strategies for sky-ground uplink non-orthogonal multiple access
Aug 15, 2021



Integration of unmanned aerial vehicles (UAVs) into fifth generation (5G) and beyond 5G (B5G) cellular networks is an intriguing problem that has recently tackled a lot of interest in both academia and industry. An effective solution is represented by cellular-connected UAVs, where traditional terrestrial users coexist with flying UAVs acting as additional aerial users, which access the 5G/B5G cellular network infrastructure from the sky. In this scenario, we study the challenging application in which an UAV acting as aerial user (AU) and a static (i.e., fixed) terrestrial user (TU) are paired to simultaneously transmit their uplink signals to a ground base station (BS) in the same time-frequency resource blocks. In such a case, due to the highly dynamic nature of the UAV, the signal transmitted by the AU experiences both time dispersion due to multipath propagation effects and frequency dispersion caused by Doppler shifts. On the other hand, for a static ground network, frequency dispersion of the signal transmitted by TU is negligible and only multipath effects have to be taken into account. To decode the superposed signals at the BS by using finite-length data record, we propose a novel sky-ground (SG) nonorthogonal multiple access (NOMA) receiving structure that additionally exploits the different circularity/noncircularity and almost-cyclostationarity properties of the AU and TU by means of improved channel estimation and time-varying successive interference cancellation. Numerical results demonstrate the usefulness of the proposed SG uplink NOMA reception scheme in future 5G/B5G networks.
Hierarchical Modeling for Task Recognition and Action Segmentation in Weakly-Labeled Instructional Videos
Oct 12, 2021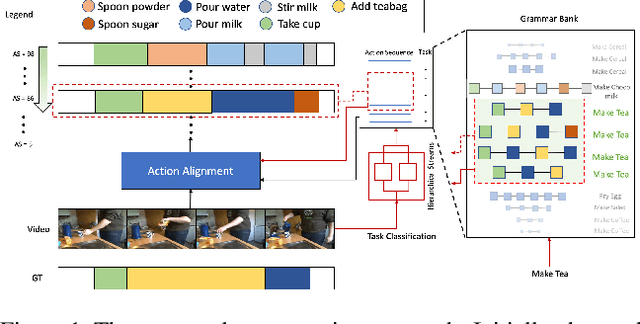
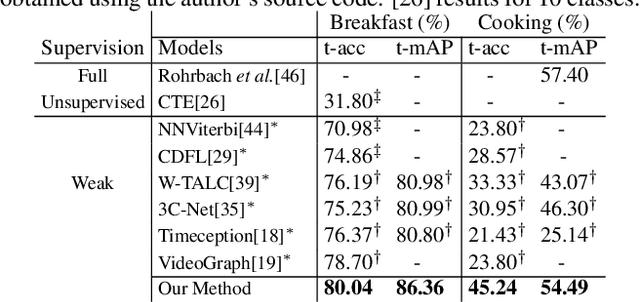
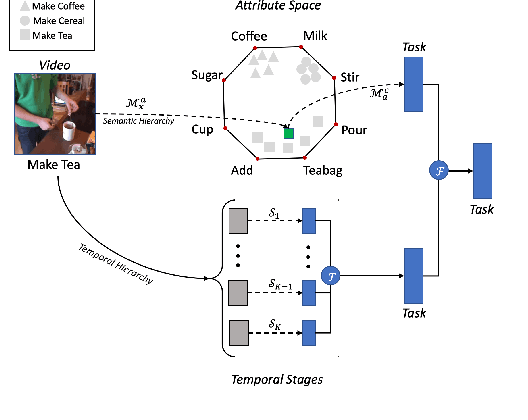
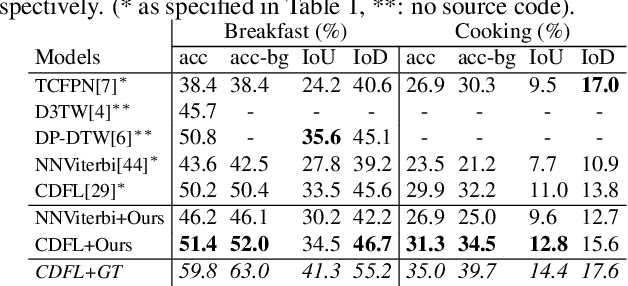
This paper focuses on task recognition and action segmentation in weakly-labeled instructional videos, where only the ordered sequence of video-level actions is available during training. We propose a two-stream framework, which exploits semantic and temporal hierarchies to recognize top-level tasks in instructional videos. Further, we present a novel top-down weakly-supervised action segmentation approach, where the predicted task is used to constrain the inference of fine-grained action sequences. Experimental results on the popular Breakfast and Cooking 2 datasets show that our two-stream hierarchical task modeling significantly outperforms existing methods in top-level task recognition for all datasets and metrics. Additionally, using our task recognition framework in the proposed top-down action segmentation approach consistently improves the state of the art, while also reducing segmentation inference time by 80-90 percent.