 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GCN-SE: Attention as Explainability for Node Classification in Dynamic Graphs
Oct 11, 2021
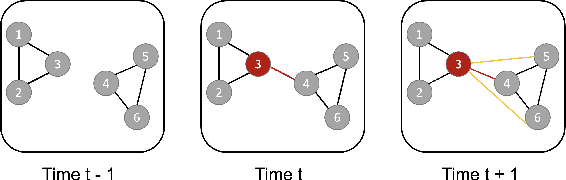
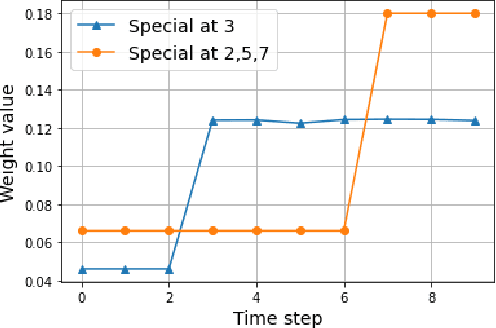
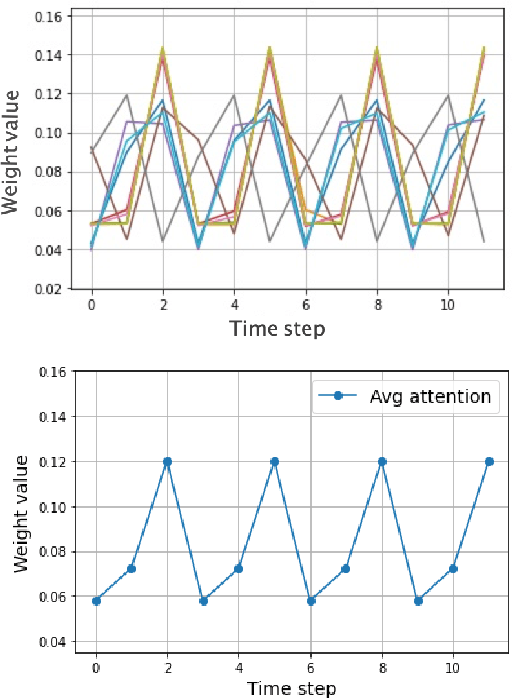
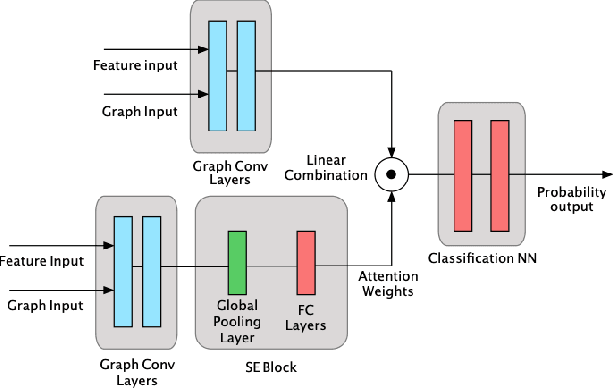
Graph Convolutional Networks (GCNs) are a popular method from graph representation learning that have proved effective for tasks like node classification tasks. Although typical GCN models focus on classifying nodes within a static graph, several recent variants propose node classification in dynamic graphs whose topologies and node attributes change over time, e.g., social networks with dynamic relationships, or literature citation networks with changing co-authorships. These works, however, do not fully address the challenge of flexibly assigning different importance to snapshots of the graph at different times, which depending on the graph dynamics may have more or less predictive power on the labels. We address this challenge by proposing a new method, GCN-SE, that attaches a set of learnable attention weights to graph snapshots at different times, inspired by Squeeze and Excitation Net (SE-Net). We show that GCN-SE outperforms previously proposed node classification methods on a variety of graph datasets. To verify the effectiveness of the attention weight in determining the importance of different graph snapshots, we adapt perturbation-based methods from the field of explainable machine learning to graphical settings and evaluate the correlation between the attention weights learned by GCN-SE and the importance of different snapshots over time. These experiments demonstrate that GCN-SE can in fact identify different snapshots' predictive power for dynamic node classification.
CCO-VOXEL: Chance Constrained Optimization over Uncertain Voxel-Grid Representation for Safe Trajectory Planning
Oct 06, 2021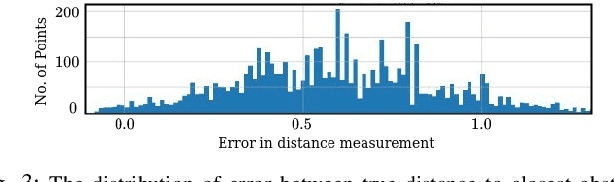
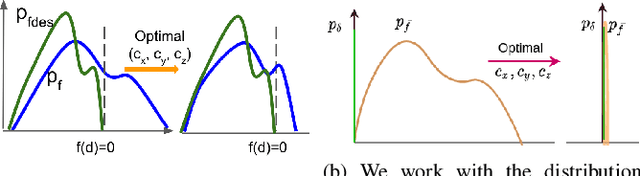
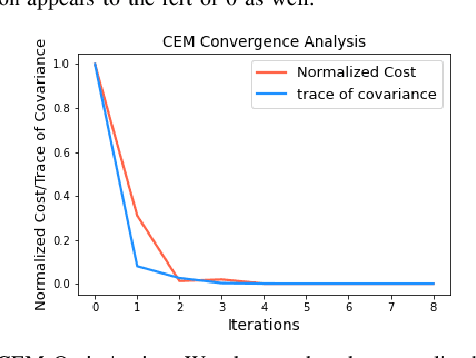

We present CCO-VOXEL: the very first chance-constrained optimization (CCO) algorithm that can compute trajectory plans with probabilistic safety guarantees in real-time directly on the voxel-grid representation of the world. CCO-VOXEL maps the distribution over the distance to the closest obstacle to a distribution over collision-constraint violation and computes an optimal trajectory that minimizes the violation probability. Importantly, unlike existing works, we never assume the nature of the sensor uncertainty or the probability distribution of the resulting collision-constraint violations. We leverage the notion of Hilbert Space embedding of distributions and Maximum Mean Discrepancy (MMD) to compute a tractable surrogate for the original chance-constrained optimization problem and employ a combination of A* based graph-search and Cross-Entropy Method for obtaining its minimum. We show tangible performance gain in terms of collision avoidance and trajectory smoothness as a consequence of our probabilistic formulation vis a vis state-of-the-art planning methods that do not account for such nonparametric noise. Finally, we also show how a combination of low-dimensional feature embedding and pre-caching of Kernel Matrices of MMD allows us to achieve real-time performance in simulations as well as in implementations on on-board commodity hardware that controls the quadrotor flight
Objective hearing threshold identification from auditory brainstem response measurements using supervised and self-supervised approaches
Dec 16, 2021
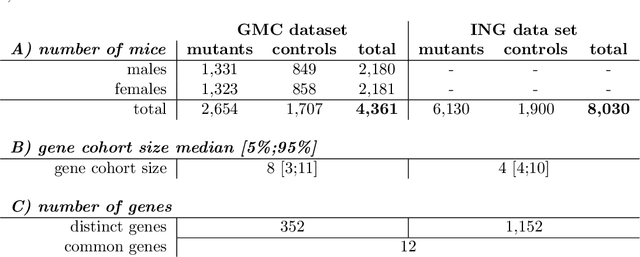
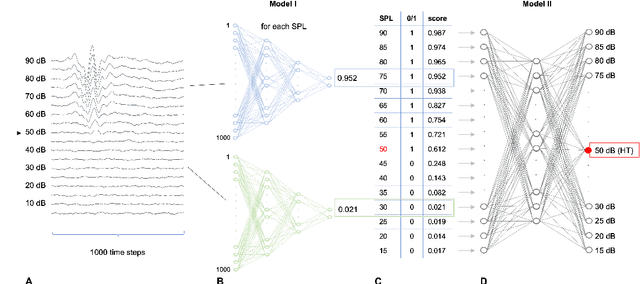
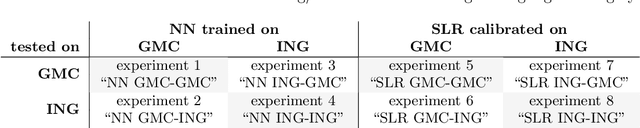
Hearing loss is a major health problem and psychological burden in humans. Mouse models offer a possibility to elucidate genes involved in the underlying developmental and pathophysiological mechanisms of hearing impairment. To this end, large-scale mouse phenotyping programs include auditory phenotyping of single-gene knockout mouse lines. Using the auditory brainstem response (ABR) procedure, the German Mouse Clinic and similar facilities worldwide have produced large, uniform data sets of averaged ABR raw data of mutant and wildtype mice. In the course of standard ABR analysis, hearing thresholds are assessed visually by trained staff from series of signal curves of increasing sound pressure level. This is time-consuming and prone to be biased by the reader as well as the graphical display quality and scale. In an attempt to reduce workload and improve quality and reproducibility, we developed and compared two methods for automated hearing threshold identification from averaged ABR raw data: a supervised approach involving two combined neural networks trained on human-generated labels and a self-supervised approach, which exploits the signal power spectrum and combines random forest sound level estimation with a piece-wise curve fitting algorithm for threshold finding. We show that both models work well, outperform human threshold detection, and are suitable for fast, reliable, and unbiased hearing threshold detection and quality control. In a high-throughput mouse phenotyping environment, both methods perform well as part of an automated end-to-end screening pipeline to detect candidate genes for hearing involvement. Code for both models as well as data used for this work are freely available.
Detecting Attacks on IoT Devices using Featureless 1D-CNN
Sep 09, 2021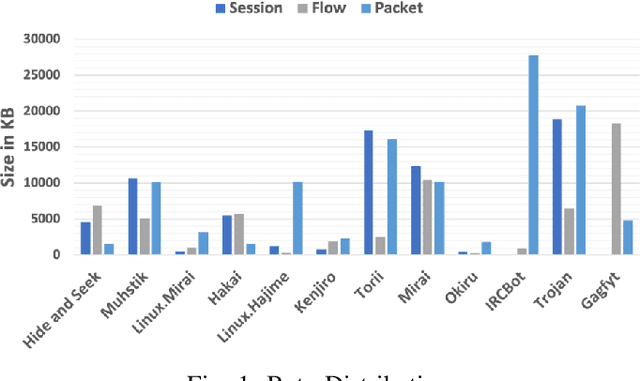
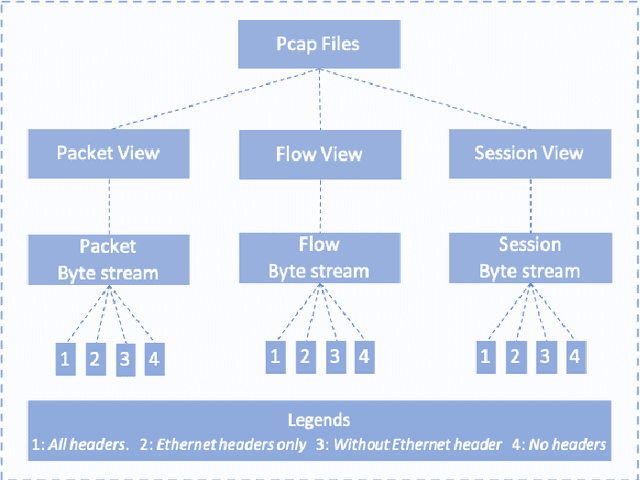
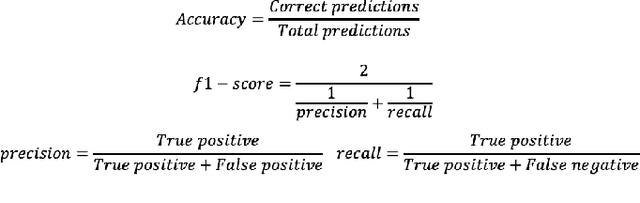
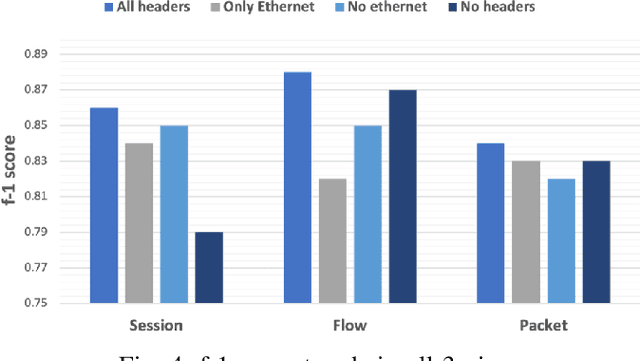
The generalization of deep learning has helped us, in the past, address challenges such as malware identification and anomaly detection in the network security domain. However, as effective as it is, scarcity of memory and processing power makes it difficult to perform these tasks in Internet of Things (IoT) devices. This research finds an easy way out of this bottleneck by depreciating the need for feature engineering and subsequent processing in machine learning techniques. In this study, we introduce a Featureless machine learning process to perform anomaly detection. It uses unprocessed byte streams of packets as training data. Featureless machine learning enables a low cost and low memory time-series analysis of network traffic. It benefits from eliminating the significant investment in subject matter experts and the time required for feature engineering.
Improving the Chamberlin Digital State Variable Filter
Nov 10, 2021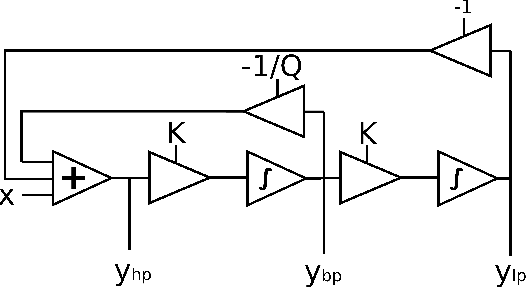
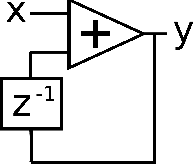
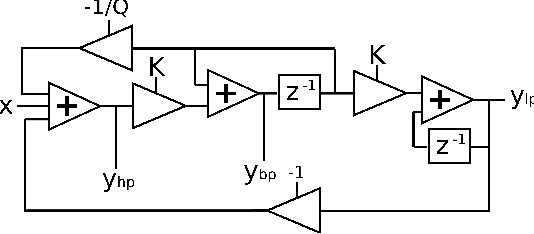
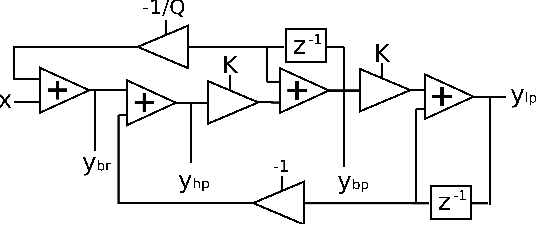
The state variable filter configuration is a classic analogue design which has been employed in many electronic music applications. A digital implementation of this filter was put forward by Chamberlin, which has been deployed in both software and hardware forms. While this has proven to be a straightforward and successful digital filter design, it suffers from some issues, which have already been identified in the literature. From a modified Chamberlin block diagram, we derive the transfer functions describing its three basic responses, highpass, bandpass, and lowpass. An analysis of these leads to the development of an improvement, which attempts to better shape the filter spectrum. From these new transfer functions, a set of filter equations is developed. Finally, the approach is compared to an alternative time-domain based re-organisation of update equations, which is shown to deliver a similar result.
UMPNet: Universal Manipulation Policy Network for Articulated Objects
Sep 19, 2021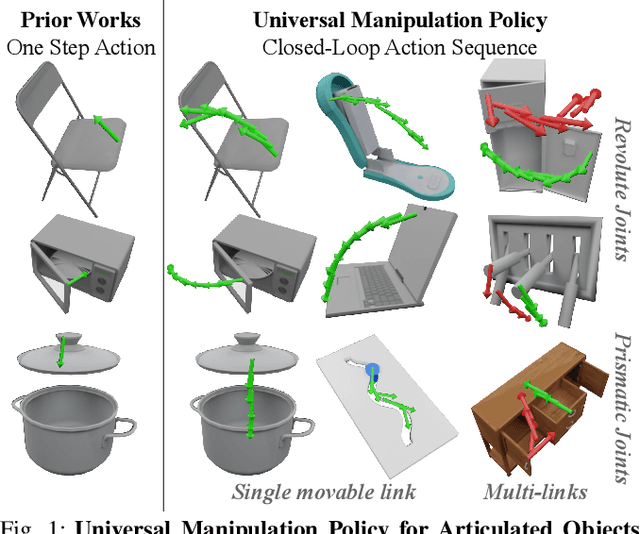
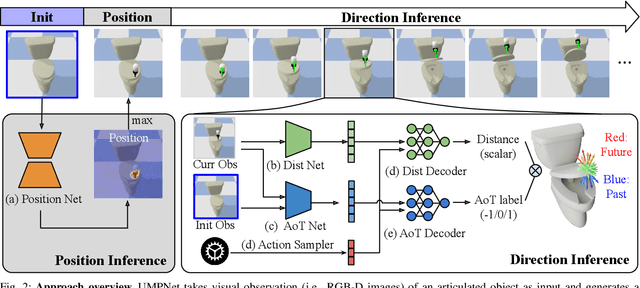
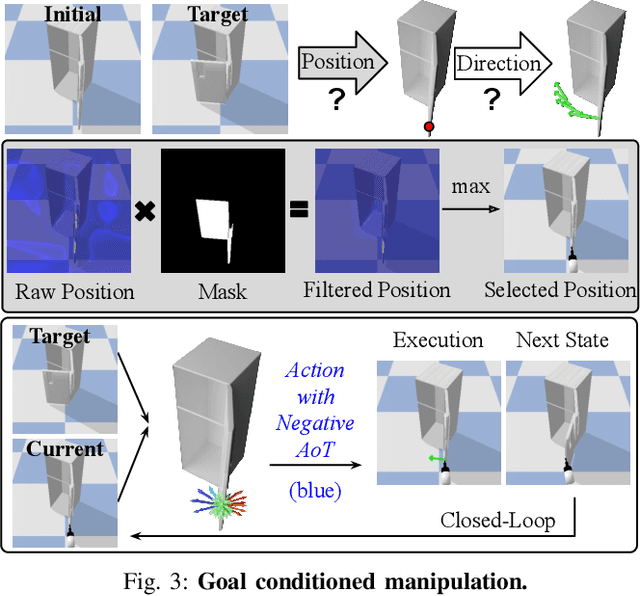
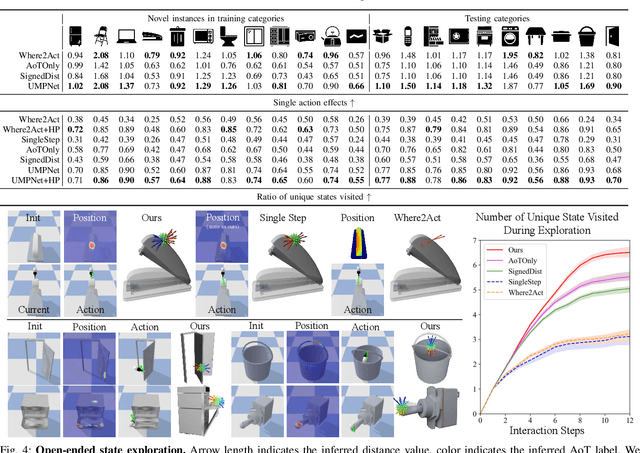
We introduce the Universal Manipulation Policy Network (UMPNet) -- a single image-based policy network that infers closed-loop action sequences for manipulating arbitrary articulated objects. To infer a wide range of action trajectories, the policy supports 6DoF action representation and varying trajectory length. To handle a diverse set of objects, the policy learns from objects with different articulation structures and generalizes to unseen objects or categories. The policy is trained with self-guided exploration without any human demonstrations, scripted policy, or pre-defined goal conditions. To support effective multi-step interaction, we introduce a novel Arrow-of-Time action attribute that indicates whether an action will change the object state back to the past or forward into the future. With the Arrow-of-Time inference at each interaction step, the learned policy is able to select actions that consistently lead towards or away from a given state, thereby, enabling both effective state exploration and goal-conditioned manipulation. Video is available at https://youtu.be/KqlvcL9RqKM
Limiting fluctuation and trajectorial stability of multilayer neural networks with mean field training
Oct 29, 2021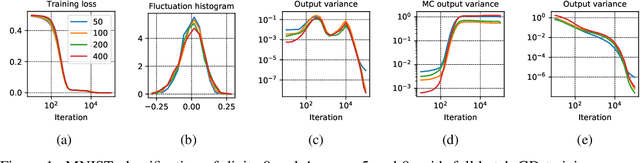
The mean field (MF) theory of multilayer neural networks centers around a particular infinite-width scaling, where the learning dynamics is closely tracked by the MF limit. A random fluctuation around this infinite-width limit is expected from a large-width expansion to the next order. This fluctuation has been studied only in shallow networks, where previous works employ heavily technical notions or additional formulation ideas amenable only to that case. Treatment of the multilayer case has been missing, with the chief difficulty in finding a formulation that captures the stochastic dependency across not only time but also depth. In this work, we initiate the study of the fluctuation in the case of multilayer networks, at any network depth. Leveraging on the neuronal embedding framework recently introduced by Nguyen and Pham, we systematically derive a system of dynamical equations, called the second-order MF limit, that captures the limiting fluctuation distribution. We demonstrate through the framework the complex interaction among neurons in this second-order MF limit, the stochasticity with cross-layer dependency and the nonlinear time evolution inherent in the limiting fluctuation. A limit theorem is proven to relate quantitatively this limit to the fluctuation of large-width networks. We apply the result to show a stability property of gradient descent MF training: in the large-width regime, along the training trajectory, it progressively biases towards a solution with "minimal fluctuation" (in fact, vanishing fluctuation) in the learned output function, even after the network has been initialized at or has converged (sufficiently fast) to a global optimum. This extends a similar phenomenon previously shown only for shallow networks with a squared loss in the ERM setting, to multilayer networks with a loss function that is not necessarily convex in a more general setting.
Comparison of computing efficiency among FFT, CZT and Zoom FFT in THz-TDS
Aug 09, 2021

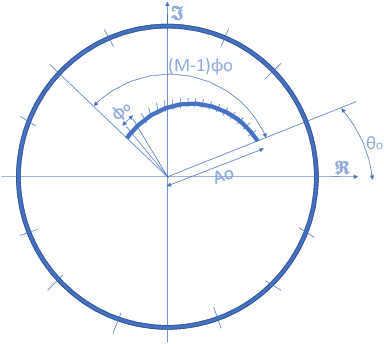
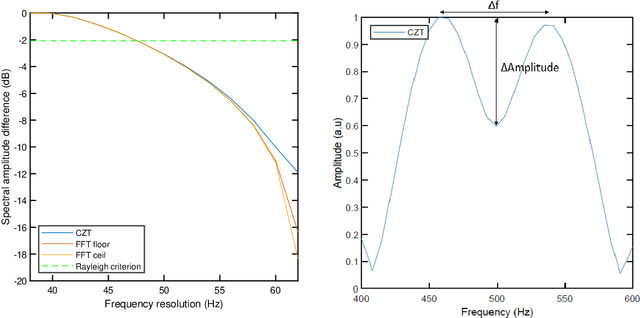
A study of alternative transforms to FFT in order to compare their potential to enhance resolution and computation time in the framework of THz time domain spectroscopy (THz-TDS) instruments is carried out. Both from simulated and experimental data it is shown that, as expected, resolution cannot be enhanced using CZT or Zoom FFT and, in terms of computing efficiency, FFT is in practical cases, the most efficient one.
Physics-Informed Neural Networks for AC Optimal Power Flow
Oct 06, 2021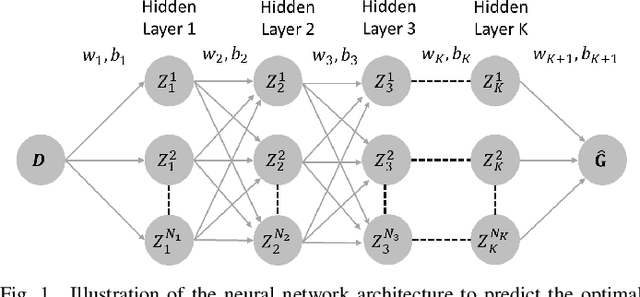
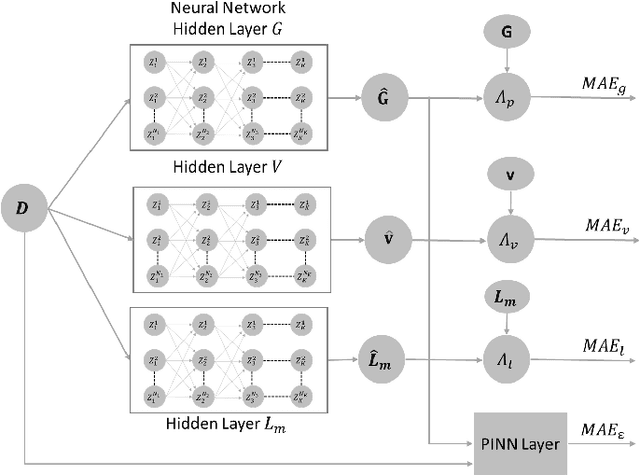
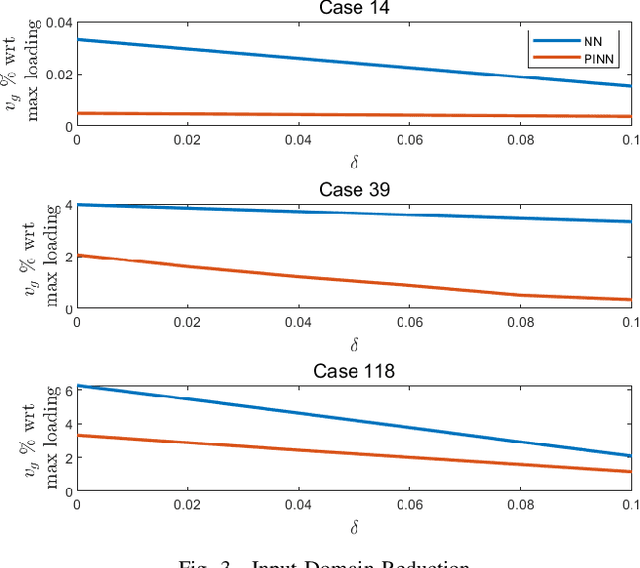
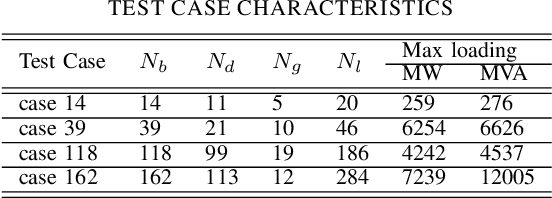
This paper introduces, for the first time to our knowledge, physics-informed neural networks to accurately estimate the AC-OPF result and delivers rigorous guarantees about their performance. Power system operators, along with several other actors, are increasingly using Optimal Power Flow (OPF) algorithms for a wide number of applications, including planning and real-time operations. However, in its original form, the AC Optimal Power Flow problem is often challenging to solve as it is non-linear and non-convex. Besides the large number of approximations and relaxations, recent efforts have also been focusing on Machine Learning approaches, especially neural networks. So far, however, these approaches have only partially considered the wide number of physical models available during training. And, more importantly, they have offered no guarantees about potential constraint violations of their output. Our approach (i) introduces the AC power flow equations inside neural network training and (ii) integrates methods that rigorously determine and reduce the worst-case constraint violations across the entire input domain, while maintaining the optimality of the prediction. We demonstrate how physics-informed neural networks achieve higher accuracy and lower constraint violations than standard neural networks, and show how we can further reduce the worst-case violations for all neural networks.
Learn to cycle: Time-consistent feature discovery for action recognition
Jun 23, 2020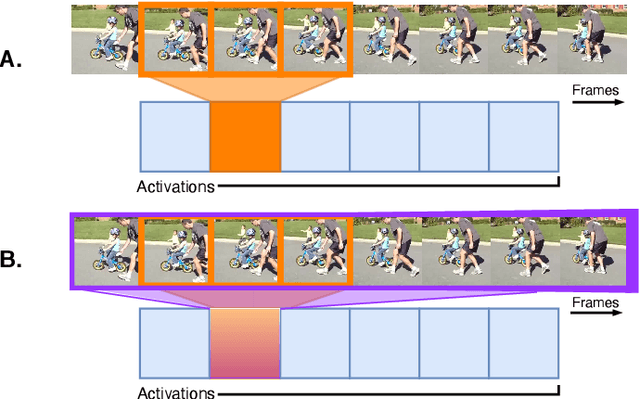
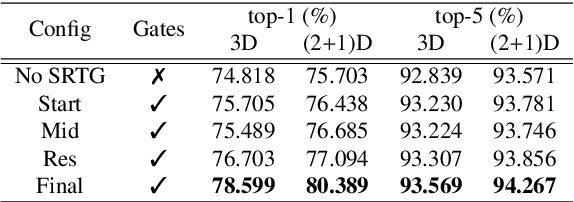
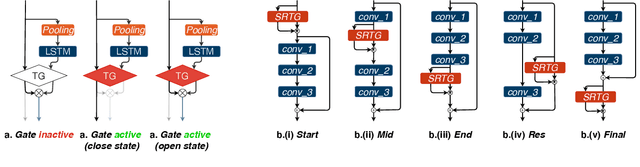
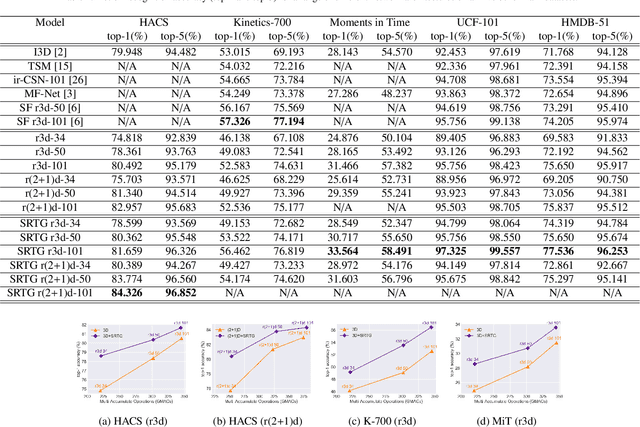
Generalizing over temporal variations is a prerequisite for effective action recognition in videos. Despite significant advances in deep neural networks, it remains a challenge to focus on short-term discriminative motions in relation to the overall performance of an action. We address this challenge by allowing some flexibility in discovering relevant spatio-temporal features. We introduce Squeeze and Recursion Temporal Gates (SRTG), an approach that favors inputs with similar activations with potential temporal variations. We implement this idea with a novel CNN block that uses an LSTM to encapsulate feature dynamics, in conjunction with a temporal gate that is responsible for evaluating the consistency of the discovered dynamics and the modeled features. We show consistent improvement when using SRTG blocks, with only a minimal increase in the number of GFLOPs. On Kinetics-700, we perform on par with current state-of-the-art models, and outperform these on HACS, Moments in Time, UCF-101 and HMDB-51.