 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimiting fluctuation and trajectorial stability of multilayer neural networks with mean field training
Oct 29, 2021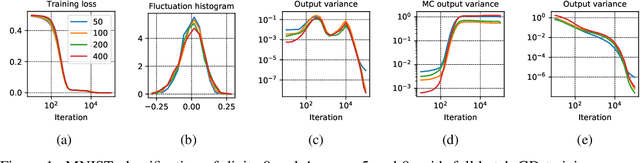
The mean field (MF) theory of multilayer neural networks centers around a particular infinite-width scaling, where the learning dynamics is closely tracked by the MF limit. A random fluctuation around this infinite-width limit is expected from a large-width expansion to the next order. This fluctuation has been studied only in shallow networks, where previous works employ heavily technical notions or additional formulation ideas amenable only to that case. Treatment of the multilayer case has been missing, with the chief difficulty in finding a formulation that captures the stochastic dependency across not only time but also depth. In this work, we initiate the study of the fluctuation in the case of multilayer networks, at any network depth. Leveraging on the neuronal embedding framework recently introduced by Nguyen and Pham, we systematically derive a system of dynamical equations, called the second-order MF limit, that captures the limiting fluctuation distribution. We demonstrate through the framework the complex interaction among neurons in this second-order MF limit, the stochasticity with cross-layer dependency and the nonlinear time evolution inherent in the limiting fluctuation. A limit theorem is proven to relate quantitatively this limit to the fluctuation of large-width networks. We apply the result to show a stability property of gradient descent MF training: in the large-width regime, along the training trajectory, it progressively biases towards a solution with "minimal fluctuation" (in fact, vanishing fluctuation) in the learned output function, even after the network has been initialized at or has converged (sufficiently fast) to a global optimum. This extends a similar phenomenon previously shown only for shallow networks with a squared loss in the ERM setting, to multilayer networks with a loss function that is not necessarily convex in a more general setting.
Global Convergence of Three-layer Neural Networks in the Mean Field Regime
May 11, 2021In the mean field regime, neural networks are appropriately scaled so that as the width tends to infinity, the learning dynamics tends to a nonlinear and nontrivial dynamical limit, known as the mean field limit. This lends a way to study large-width neural networks via analyzing the mean field limit. Recent works have successfully applied such analysis to two-layer networks and provided global convergence guarantees. The extension to multilayer ones however has been a highly challenging puzzle, and little is known about the optimization efficiency in the mean field regime when there are more than two layers. In this work, we prove a global convergence result for unregularized feedforward three-layer networks in the mean field regime. We first develop a rigorous framework to establish the mean field limit of three-layer networks under stochastic gradient descent training. To that end, we propose the idea of a \textit{neuronal embedding}, which comprises of a fixed probability space that encapsulates neural networks of arbitrary sizes. The identified mean field limit is then used to prove a global convergence guarantee under suitable regularity and convergence mode assumptions, which -- unlike previous works on two-layer networks -- does not rely critically on convexity. Underlying the result is a universal approximation property, natural of neural networks, which importantly is shown to hold at \textit{any} finite training time (not necessarily at convergence) via an algebraic topology argument.
A Note on the Global Convergence of Multilayer Neural Networks in the Mean Field Regime
Jun 16, 2020In a recent work, we introduced a rigorous framework to describe the mean field limit of the gradient-based learning dynamics of multilayer neural networks, based on the idea of a neuronal embedding. There we also proved a global convergence guarantee for three-layer (as well as two-layer) networks using this framework. In this companion note, we point out that the insights in our previous work can be readily extended to prove a global convergence guarantee for multilayer networks of any depths. Unlike our previous three-layer global convergence guarantee that assumes i.i.d. initializations, our present result applies to a type of correlated initialization. This initialization allows to, at any finite training time, propagate a certain universal approximation property through the depth of the neural network. To achieve this effect, we introduce a bidirectional diversity condition.
A Rigorous Framework for the Mean Field Limit of Multilayer Neural Networks
Jan 30, 2020We develop a mathematically rigorous framework for multilayer neural networks in the mean field regime. As the network's width increases, the network's learning trajectory is shown to be well captured by a meaningful and dynamically nonlinear limit (the \textit{mean field} limit), which is characterized by a system of ODEs. Our framework applies to a broad range of network architectures, learning dynamics and network initializations. Central to the framework is the new idea of a \textit{neuronal embedding}, which comprises of a non-evolving probability space that allows to embed neural networks of arbitrary widths. We demonstrate two applications of our framework. Firstly the framework gives a principled way to study the simplifying effects that independent and identically distributed initializations have on the mean field limit. Secondly we prove a global convergence guarantee for two-layer and three-layer networks. Unlike previous works that rely on convexity, our result requires a certain universal approximation property, which is a distinctive feature of infinite-width neural networks. To the best of our knowledge, this is the first time global convergence is established for neural networks of more than two layers in the mean field regime.