 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-label Prediction in Time Series Data using Deep Neural Networks
Jan 27, 2020
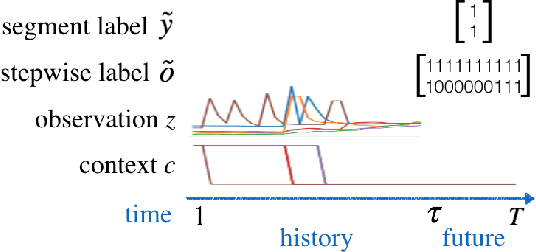

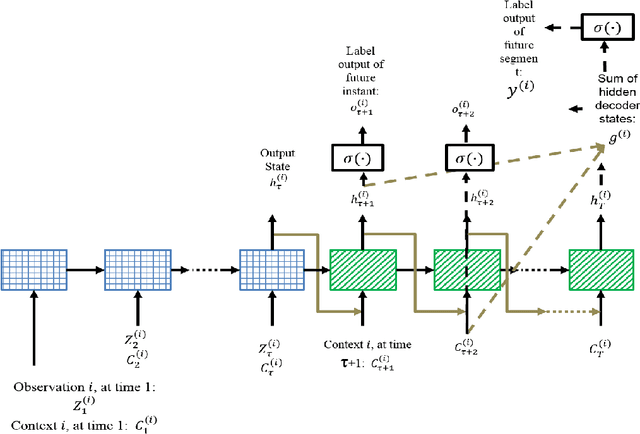
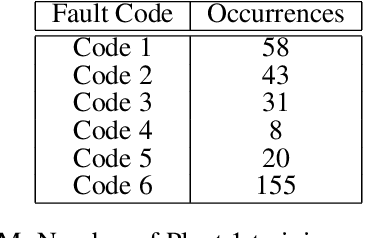
This paper addresses a multi-label predictive fault classification problem for multidimensional time-series data. While fault (event) detection problems have been thoroughly studied in literature, most of the state-of-the-art techniques can't reliably predict faults (events) over a desired future horizon. In the most general setting of these types of problems, one or more samples of data across multiple time series can be assigned several concurrent fault labels from a finite, known set and the task is to predict the possibility of fault occurrence over a desired time horizon. This type of problem is usually accompanied by strong class imbalances where some classes are represented by only a few samples. Importantly, in many applications of the problem such as fault prediction and predictive maintenance, it is exactly these rare classes that are of most interest. To address the problem, this paper proposes a general approach that utilizes a multi-label recurrent neural network with a new cost function that accentuates learning in the imbalanced classes. The proposed algorithm is tested on two public benchmark datasets: an industrial plant dataset from the PHM Society Data Challenge, and a human activity recognition dataset. The results are compared with state-of-the-art techniques for time-series classification and evaluation is performed using the F1-score, precision and recall.
A Novel Approach for Deterioration and Damage Identification in Building Structures Based on Stockwell-Transform and Deep Convolutional Neural Network
Nov 16, 2021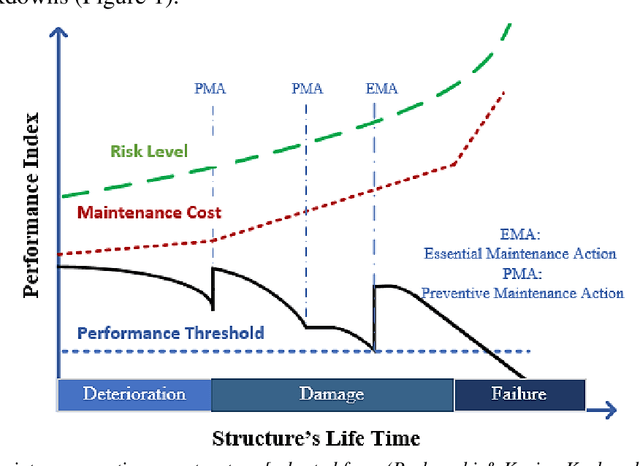
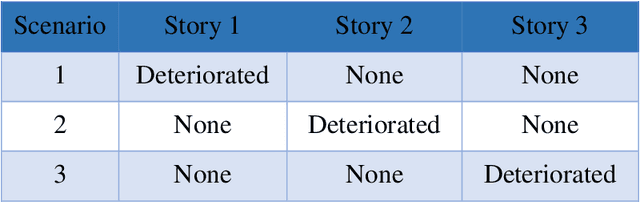
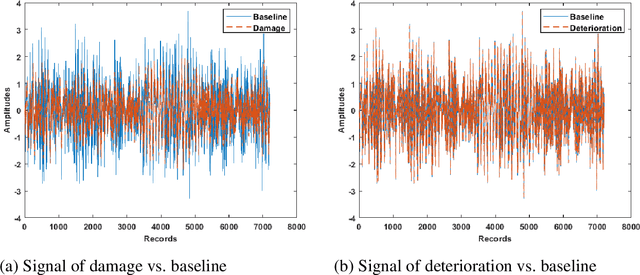
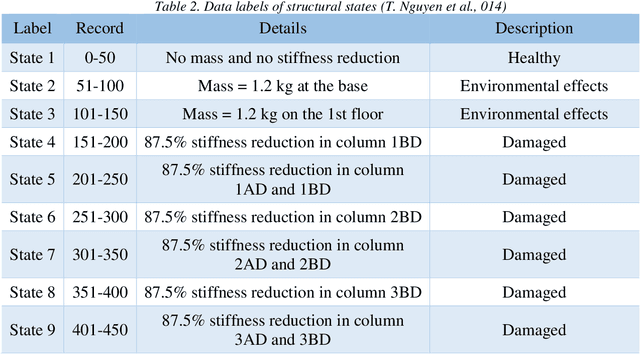
In this paper, a novel deterioration and damage identification procedure (DIP) is presented and applied to building models. The challenge associated with applications on these types of structures is related to the strong correlation of responses, which gets further complicated when coping with real ambient vibrations with high levels of noise. Thus, a DIP is designed utilizing low-cost ambient vibrations to analyze the acceleration responses using the Stockwell transform (ST) to generate spectrograms. Subsequently, the ST outputs become the input of two series of Convolutional Neural Networks (CNNs) established for identifying deterioration and damage to the building models. To the best of our knowledge, this is the first time that both damage and deterioration are evaluated on building models through a combination of ST and CNN with high accuracy.
Optimization-Based GenQSGD for Federated Edge Learning
Nov 26, 2021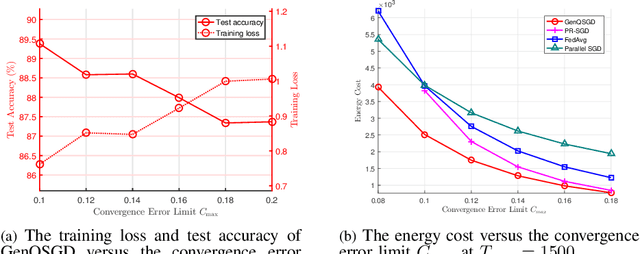
Optimal algorithm design for federated learning (FL) remains an open problem. This paper explores the full potential of FL in practical edge computing systems where workers may have different computation and communication capabilities, and quantized intermediate model updates are sent between the server and workers. First, we present a general quantized parallel mini-batch stochastic gradient descent (SGD) algorithm for FL, namely GenQSGD, which is parameterized by the number of global iterations, the numbers of local iterations at all workers, and the mini-batch size. We also analyze its convergence error for any choice of the algorithm parameters. Then, we optimize the algorithm parameters to minimize the energy cost under the time constraint and convergence error constraint. The optimization problem is a challenging non-convex problem with non-differentiable constraint functions. We propose an iterative algorithm to obtain a KKT point using advanced optimization techniques. Numerical results demonstrate the significant gains of GenQSGD over existing FL algorithms and reveal the importance of optimally designing FL algorithms.
Leveraging Transformers for StarCraft Macromanagement Prediction
Oct 11, 2021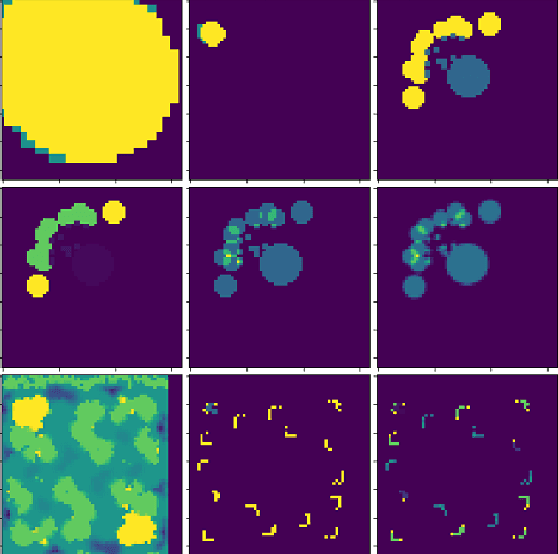
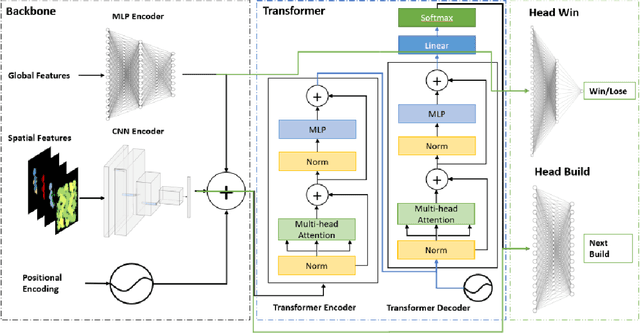
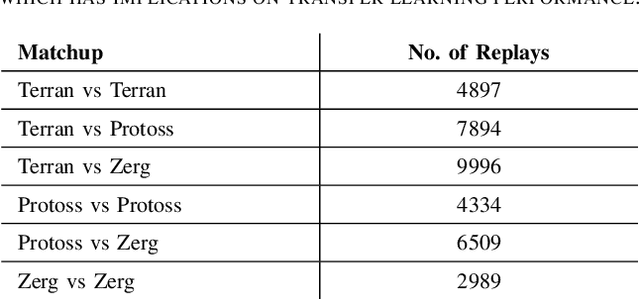
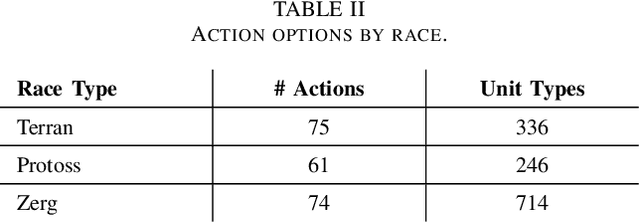
Inspired by the recent success of transformers in natural language processing and computer vision applications, we introduce a transformer-based neural architecture for two key StarCraft II (SC2) macromanagement tasks: global state and build order prediction. Unlike recurrent neural networks which suffer from a recency bias, transformers are able to capture patterns across very long time horizons, making them well suited for full game analysis. Our model utilizes the MSC (Macromanagement in StarCraft II) dataset and improves on the top performing gated recurrent unit (GRU) architecture in predicting global state and build order as measured by mean accuracy over multiple time horizons. We present ablation studies on our proposed architecture that support our design decisions. One key advantage of transformers is their ability to generalize well, and we demonstrate that our model achieves an even better accuracy when used in a transfer learning setting in which models trained on games with one racial matchup (e.g., Terran vs. Protoss) are transferred to a different one. We believe that transformers' ability to model long games, potential for parallelization, and generalization performance make them an excellent choice for StarCraft agents.
Schedule Based Temporal Difference Algorithms
Nov 23, 2021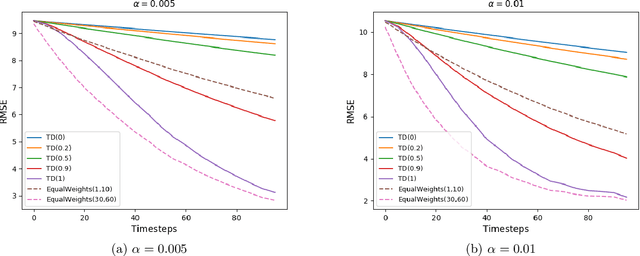
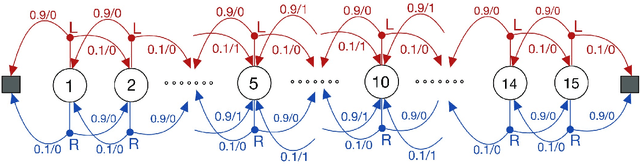
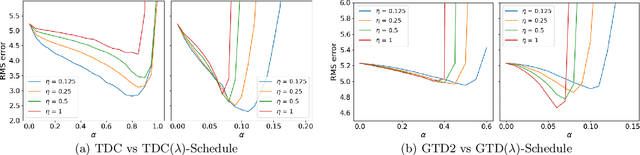
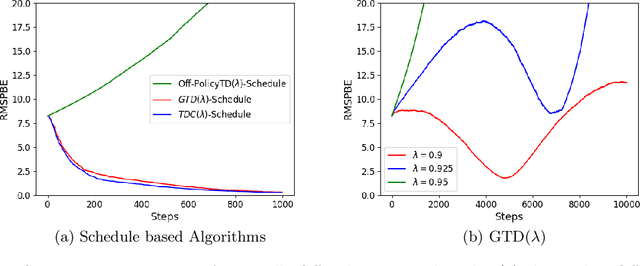
Learning the value function of a given policy from data samples is an important problem in Reinforcement Learning. TD($\lambda$) is a popular class of algorithms to solve this problem. However, the weights assigned to different $n$-step returns in TD($\lambda$), controlled by the parameter $\lambda$, decrease exponentially with increasing $n$. In this paper, we present a $\lambda$-schedule procedure that generalizes the TD($\lambda$) algorithm to the case when the parameter $\lambda$ could vary with time-step. This allows flexibility in weight assignment, i.e., the user can specify the weights assigned to different $n$-step returns by choosing a sequence $\{\lambda_t\}_{t \geq 1}$. Based on this procedure, we propose an on-policy algorithm - TD($\lambda$)-schedule, and two off-policy algorithms - GTD($\lambda$)-schedule and TDC($\lambda$)-schedule, respectively. We provide proofs of almost sure convergence for all three algorithms under a general Markov noise framework.
Adaptive Modeling Powers Fast Multi-parameter Fitting of CARS Spectra
Oct 26, 2021
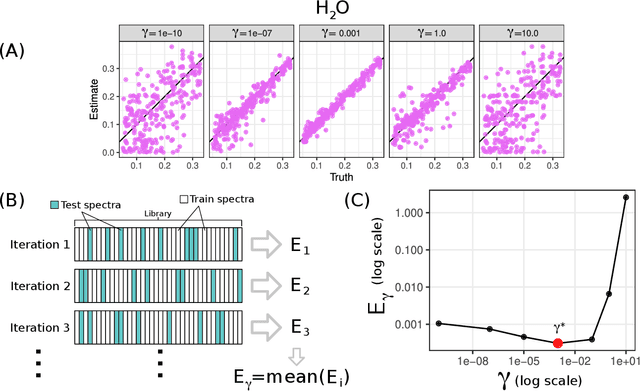
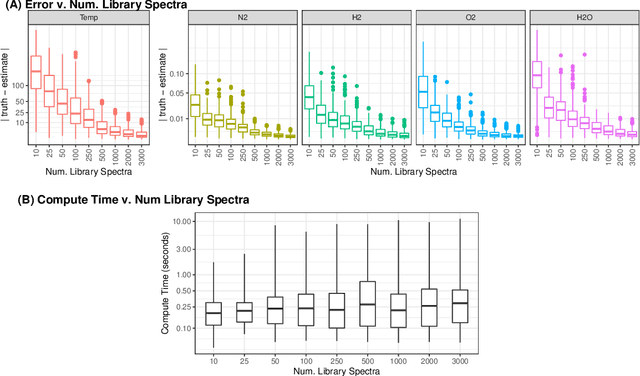
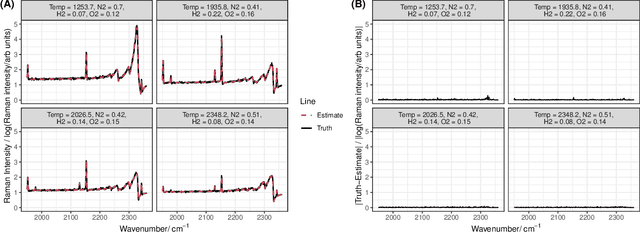
Coherent anti-Stokes Raman Spectroscopy (CARS) is a laser-based measurement technique widely applied across many science and engineering disciplines to perform non-intrusive gas diagnostics. CARS is often used to study combustion, where the measured spectra can be used to simultaneously recover multiple flow parameters from the reacting gas such as temperature and relative species mole fractions. This is typically done by using numerical optimization to find the flow parameters for which a theoretical model of the CARS spectra best matches the actual measurements. The most commonly used theoretical model is the CARSFT spectrum calculator. Unfortunately, this CARSFT spectrum generator is computationally expensive and using it to recover multiple flow parameters can be prohibitively time-consuming, especially when experiments have hundreds or thousands of measurements distributed over time or space. To overcome these issues, several methods have been developed to approximate CARSFT using a library of pre-computed theoretical spectra. In this work we present a new approach that leverages ideas from the machine learning literature to build an adaptively smoothed kernel-based approximator. In application on a simulated dual-pump CARS experiment probing a $H_2/$air flame, we show that the approach can use a small number library spectra to quickly and accurately recover temperature and four gas species' mole fractions. The method's flexibility allows fine-tuned navigation of the trade-off between speed and accuracy, and makes the approach suitable for a wide range of problems and flow regimes.
How Well Do Sparse Imagenet Models Transfer?
Dec 02, 2021

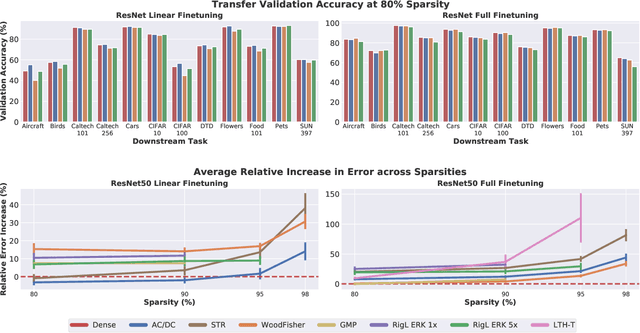
Transfer learning is a classic paradigm by which models pretrained on large "upstream" datasets are adapted to yield good results on "downstream," specialized datasets. Generally, it is understood that more accurate models on the "upstream" dataset will provide better transfer accuracy "downstream". In this work, we perform an in-depth investigation of this phenomenon in the context of convolutional neural networks (CNNs) trained on the ImageNet dataset, which have been pruned - that is, compressed by sparsifiying their connections. Specifically, we consider transfer using unstructured pruned models obtained by applying several state-of-the-art pruning methods, including magnitude-based, second-order, re-growth and regularization approaches, in the context of twelve standard transfer tasks. In a nutshell, our study shows that sparse models can match or even outperform the transfer performance of dense models, even at high sparsities, and, while doing so, can lead to significant inference and even training speedups. At the same time, we observe and analyze significant differences in the behaviour of different pruning methods.
TCTN: A 3D-Temporal Convolutional Transformer Network for Spatiotemporal Predictive Learning
Dec 02, 2021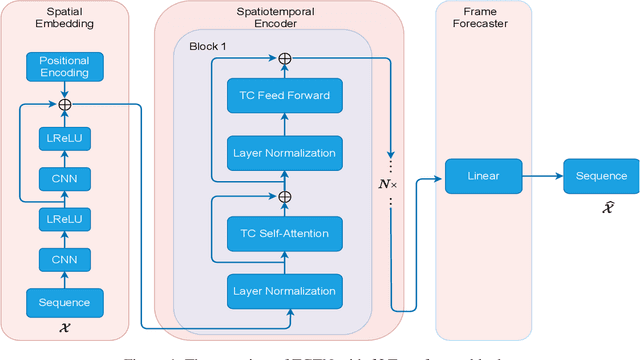
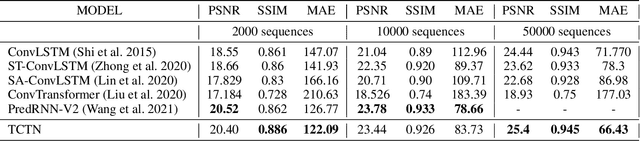
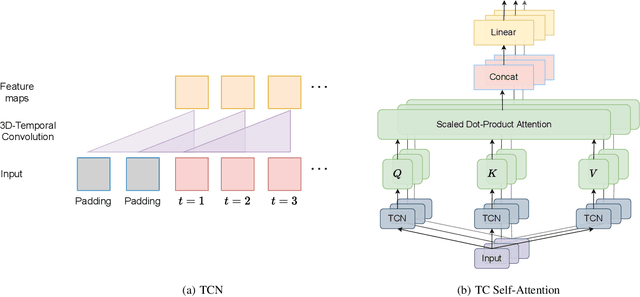
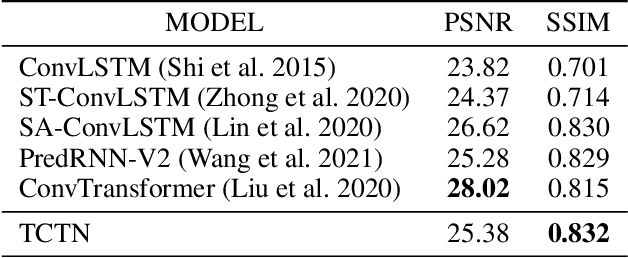
Spatiotemporal predictive learning is to generate future frames given a sequence of historical frames. Conventional algorithms are mostly based on recurrent neural networks (RNNs). However, RNN suffers from heavy computational burden such as time and long back-propagation process due to the seriality of recurrent structure. Recently, Transformer-based methods have also been investigated in the form of encoder-decoder or plain encoder, but the encoder-decoder form requires too deep networks and the plain encoder is lack of short-term dependencies. To tackle these problems, we propose an algorithm named 3D-temporal convolutional transformer (TCTN), where a transformer-based encoder with temporal convolutional layers is employed to capture short-term and long-term dependencies. Our proposed algorithm can be easy to implement and trained much faster compared with RNN-based methods thanks to the parallel mechanism of Transformer. To validate our algorithm, we conduct experiments on the MovingMNIST and KTH dataset, and show that TCTN outperforms state-of-the-art (SOTA) methods in both performance and training speed.
Overcoming Pedestrian Blockage in mm-Wave Bands using Ground Reflections
Oct 26, 2021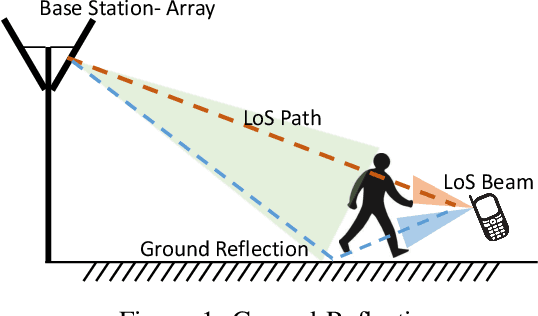
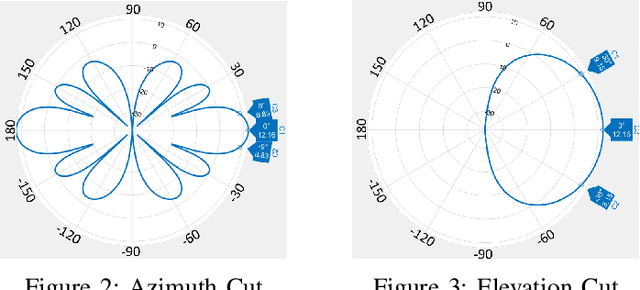
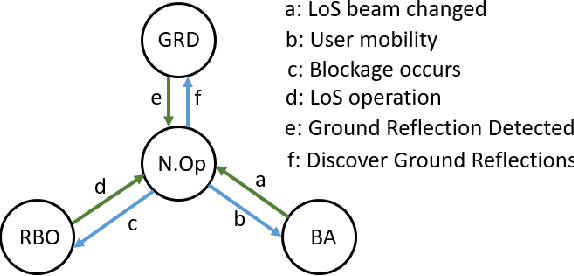
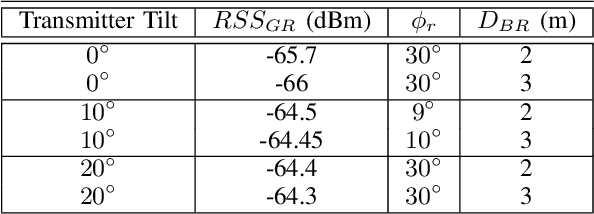
mm-Wave communication employs directional beams to overcome high path loss. High data rate communication is typically along line-of-sight (LoS). In outdoor environments, such communication is susceptible to temporary blockage by pedestrians interposed between the transmitter and receiver. It results in outages in which the user is lost, and has to be reacquired as a new user, severely disrupting interactive and high throughput applications. It has been presumed that the solution is to have a densely deployed set of base stations that will allow the mobile to perform a handover to a different non-blocked base station every time a current base station is blocked. This is however a very costly solution for outdoor environments. Through extensive experiments we show that it is possible to exploit a strong ground reflection with a received signal strength (RSS) about 4dB less than the LoS path in outdoor built environments with concrete or gravel surfaces, for beams that are narrow in azimuth but wide in zenith. While such reflected paths cannot support the high data rates of LoS paths, they can support control channel communication, and, importantly, sustain time synchronization between the mobile and the base station. This allows a mobile to quickly recover to the LoS path upon the cessation of the temporary blockage, which typically lasts a few hundred milliseconds. We present a simple in-band protocol that quickly discovers ground reflected radiation and uses it to recover the LoS link when the temporary blockage disappears.
Fairer LP-based Online Allocation
Oct 31, 2021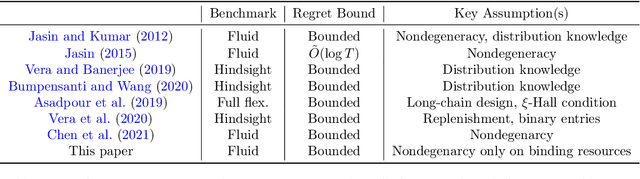
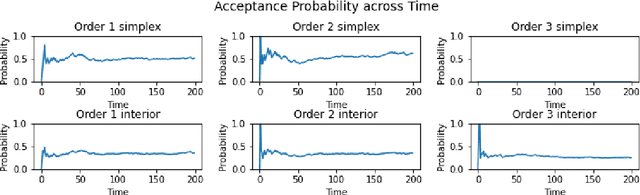
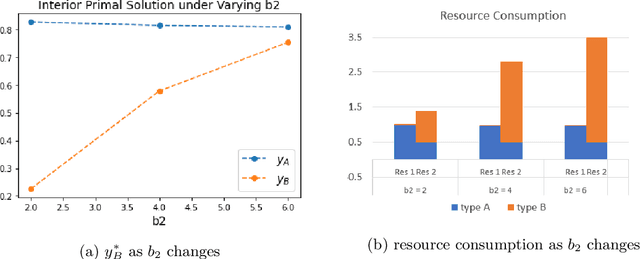
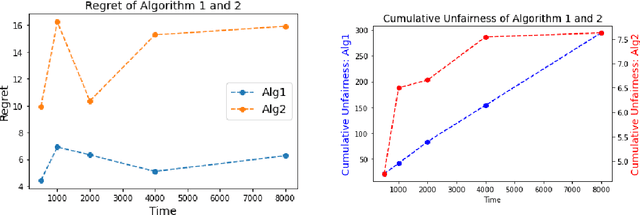
In this paper, we consider a Linear Program (LP)-based online resource allocation problem where a decision maker accepts or rejects incoming customer requests irrevocably in order to maximize expected revenue given limited resources. At each time, a new order/customer/bid is revealed with a request of some resource(s) and a reward. We consider a stochastic setting where all the orders are i.i.d. sampled from an unknown distribution. Such formulation gives rise to many classic applications such as the canonical (quantity-based) network revenue management problem and the Adwords problem. Instead of focusing only on regret minimization, this paper aims to provide fairness guarantees while maintaining low regret. Our definition of fairness is that a fair online algorithm should treat similar agents/customers similarly and the decision made for similar individuals should be consistent over time. We define the fair offline solution as the analytic center of the offline optimal solution set, and define \textit{cumulative unfairness} as the cumulative deviation from the online solutions to the fair offline solution. We propose a fair algorithm that uses an interior-point LP solver and dynamically detects unfair resource spending. Our algorithm can control cumulative unfairness on the scale of order $O(\log(T))$, while maintaining the regret to be bounded without dependency on $T$. Moreover, we partially remove the nondegeneracy assumptions used in early results in the literature. This paper only requires the nondegeneracy condition for the binding constraints, and allows the existence of multiple optimal solutions.