 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Quantum Gaussian Processes for Multi-Agent Systems
Feb 16, 2026Gaussian Processes (GPs) are a powerful tool for probabilistic modeling, but their performance is often constrained in complex, largescale real-world domains due to the limited expressivity of classical kernels. Quantum computing offers the potential to overcome this limitation by embedding data into exponentially large Hilbert spaces, capturing complex correlations that remain inaccessible to classical computing approaches. In this paper, we propose a Distributed Quantum Gaussian Process (DQGP) method in a multiagent setting to enhance modeling capabilities and scalability. To address the challenging non-Euclidean optimization problem, we develop a Distributed consensus Riemannian Alternating Direction Method of Multipliers (DR-ADMM) algorithm that aggregates local agent models into a global model. We evaluate the efficacy of our method through numerical experiments conducted on a quantum simulator in classical hardware. We use real-world, non-stationary elevation datasets of NASA's Shuttle Radar Topography Mission and synthetic datasets generated by Quantum Gaussian Processes. Beyond modeling advantages, our framework highlights potential computational speedups that quantum hardware may provide, particularly in Gaussian processes and distributed optimization.
* 9 pages, 4 figures, accepted at AAMAS 2026 (International Conference on Autonomous Agents and Multiagent Systems)
Design of an Autonomous Agriculture Robot for Real Time Weed Detection using CNN
Nov 22, 2022



Agriculture has always remained an integral part of the world. As the human population keeps on rising, the demand for food also increases, and so is the dependency on the agriculture industry. But in today's scenario, because of low yield, less rainfall, etc., a dearth of manpower is created in this agricultural sector, and people are moving to live in the cities, and villages are becoming more and more urbanized. On the other hand, the field of robotics has seen tremendous development in the past few years. The concepts like Deep Learning (DL), Artificial Intelligence (AI), and Machine Learning (ML) are being incorporated with robotics to create autonomous systems for various sectors like automotive, agriculture, assembly line management, etc. Deploying such autonomous systems in the agricultural sector help in many aspects like reducing manpower, better yield, and nutritional quality of crops. So, in this paper, the system design of an autonomous agricultural robot which primarily focuses on weed detection is described. A modified deep-learning model for the purpose of weed detection is also proposed. The primary objective of this robot is the detection of weed on a real-time basis without any human involvement, but it can also be extended to design robots in various other applications involved in farming like weed removal, plowing, harvesting, etc., in turn making the farming industry more efficient. Source code and other details can be found at https://github.com/Dhruv2012/Autonomous-Farm-Robot
Schedule Based Temporal Difference Algorithms
Nov 23, 2021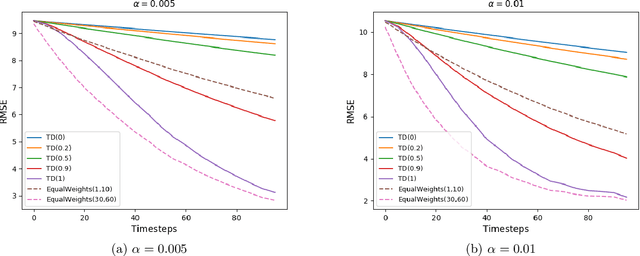
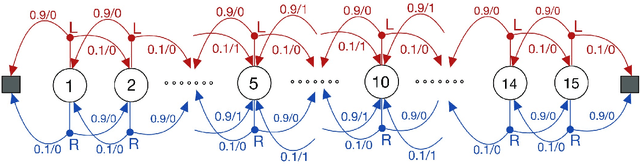
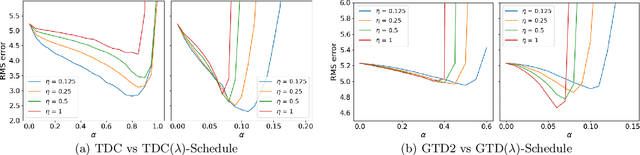
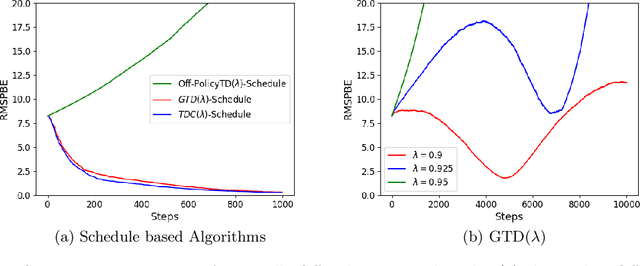
Learning the value function of a given policy from data samples is an important problem in Reinforcement Learning. TD($\lambda$) is a popular class of algorithms to solve this problem. However, the weights assigned to different $n$-step returns in TD($\lambda$), controlled by the parameter $\lambda$, decrease exponentially with increasing $n$. In this paper, we present a $\lambda$-schedule procedure that generalizes the TD($\lambda$) algorithm to the case when the parameter $\lambda$ could vary with time-step. This allows flexibility in weight assignment, i.e., the user can specify the weights assigned to different $n$-step returns by choosing a sequence $\{\lambda_t\}_{t \geq 1}$. Based on this procedure, we propose an on-policy algorithm - TD($\lambda$)-schedule, and two off-policy algorithms - GTD($\lambda$)-schedule and TDC($\lambda$)-schedule, respectively. We provide proofs of almost sure convergence for all three algorithms under a general Markov noise framework.
Audiomer: A Convolutional Transformer for Keyword Spotting
Sep 21, 2021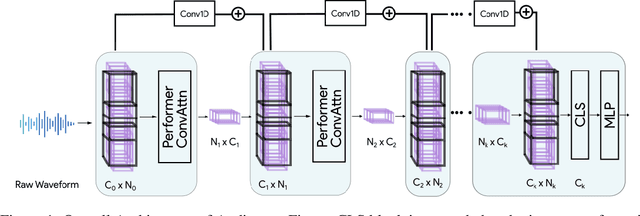

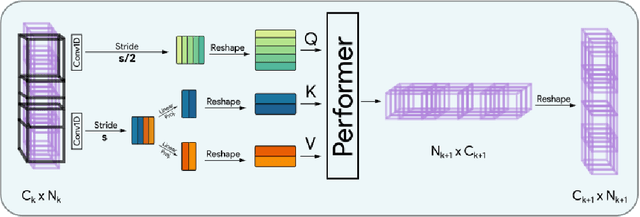
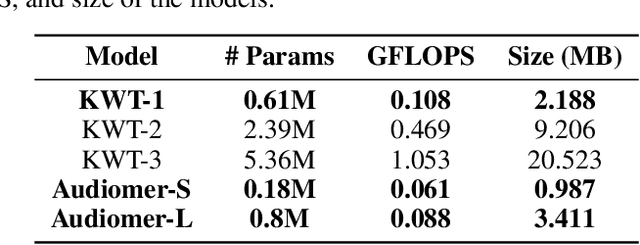
Transformers have seen an unprecedented rise in Natural Language Processing and Computer Vision tasks. However, in audio tasks, they are either infeasible to train due to extremely large sequence length of audio waveforms or reach competitive performance after feature extraction through Fourier-based methods, incurring a loss-floor. In this work, we introduce an architecture, Audiomer, where we combine 1D Residual Networks with Performer Attention to achieve state-of-the-art performance in Keyword Spotting with raw audio waveforms, out-performing all previous methods while also being computationally cheaper, much more parameter and data-efficient. Audiomer allows for deployment in compute-constrained devices and training on smaller datasets.
A reinforcement learning approach to hybrid control design
Sep 02, 2020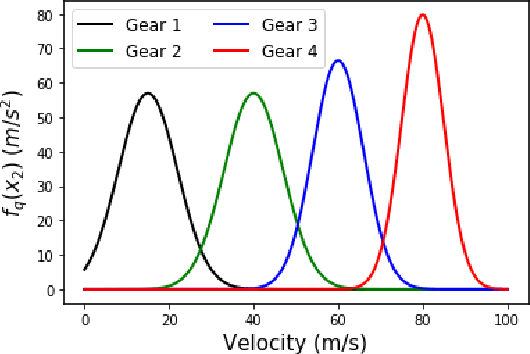
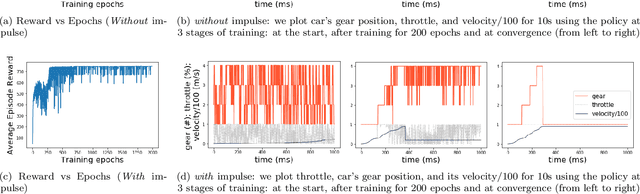
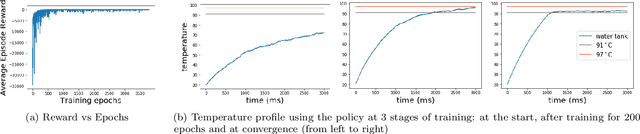

In this paper we design hybrid control policies for hybrid systems whose mathematical models are unknown. Our contributions are threefold. First, we propose a framework for modelling the hybrid control design problem as a single Markov Decision Process (MDP). This result facilitates the application of off-the-shelf algorithms from Reinforcement Learning (RL) literature towards designing optimal control policies. Second, we model a set of benchmark examples of hybrid control design problem in the proposed MDP framework. Third, we adapt the recently proposed Proximal Policy Optimisation (PPO) algorithm for the hybrid action space and apply it to the above set of problems. It is observed that in each case the algorithm converges and finds the optimal policy.