 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WaveTTS: Tacotron-based TTS with Joint Time-Frequency Domain Loss
Feb 02, 2020
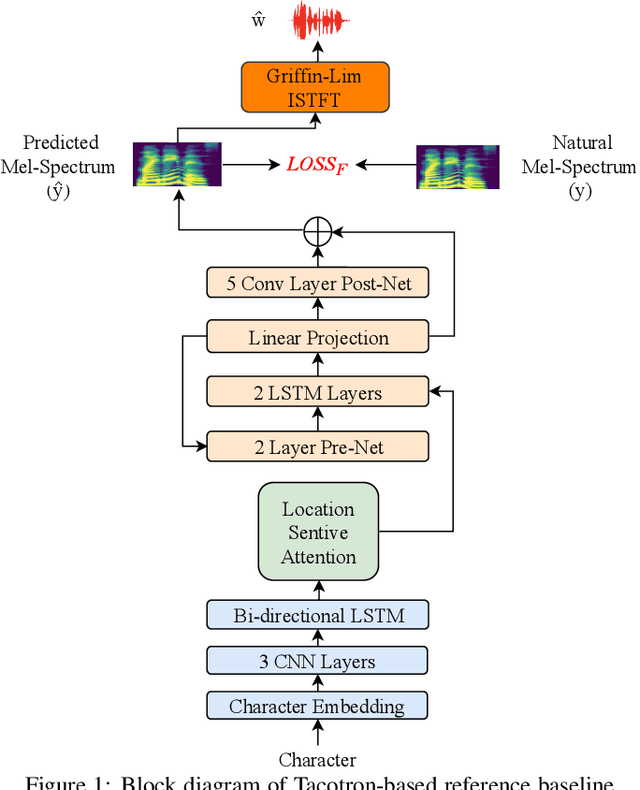

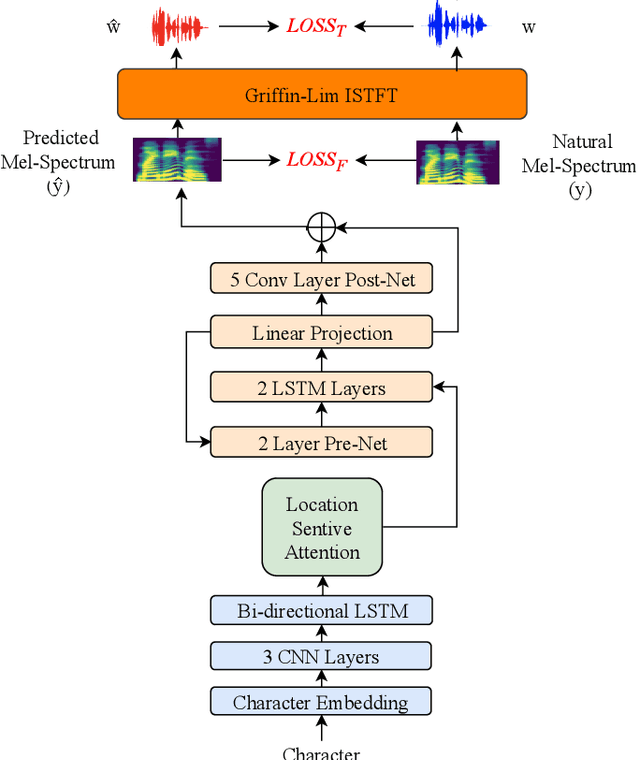
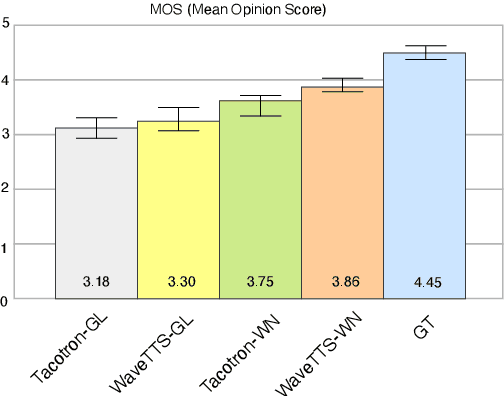
Tacotron-based text-to-speech (TTS) systems directly synthesize speech from text input. Such frameworks typically consist of a feature prediction network that maps character sequences to frequency-domain acoustic features, followed by a waveform reconstruction algorithm or a neural vocoder that generates the time-domain waveform from acoustic features. As the loss function is usually calculated only for frequency-domain acoustic features, that doesn't directly control the quality of the generated time-domain waveform. To address this problem, we propose a new training scheme for Tacotron-based TTS, referred to as WaveTTS, that has 2 loss functions: 1) time-domain loss, denoted as the waveform loss, that measures the distortion between the natural and generated waveform; and 2) frequency-domain loss, that measures the Mel-scale acoustic feature loss between the natural and generated acoustic features. WaveTTS ensures both the quality of the acoustic features and the resulting speech waveform. To our best knowledge, this is the first implementation of Tacotron with joint time-frequency domain loss. Experimental results show that the proposed framework outperforms the baselines and achieves high-quality synthesized speech.
Learning the noise fingerprint of quantum devices
Sep 23, 2021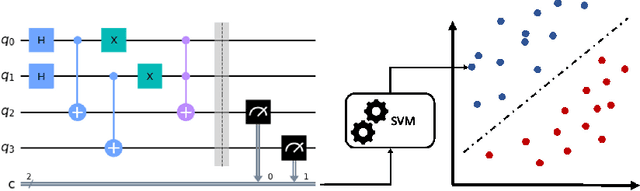
Noise sources unavoidably affect any quantum technological device. Noise's main features are expected to strictly depend on the physical platform on which the quantum device is realized, in the form of a distinguishable fingerprint. Noise sources are also expected to evolve and change over time. Here, we first identify and then characterize experimentally the noise fingerprint of IBM cloud-available quantum computers, by resorting to machine learning techniques designed to classify noise distributions using time-ordered sequences of measured outcome probabilities.
Adaptive Gaussian Process based Stochastic Trajectory Optimization for Motion Planning
Dec 30, 2021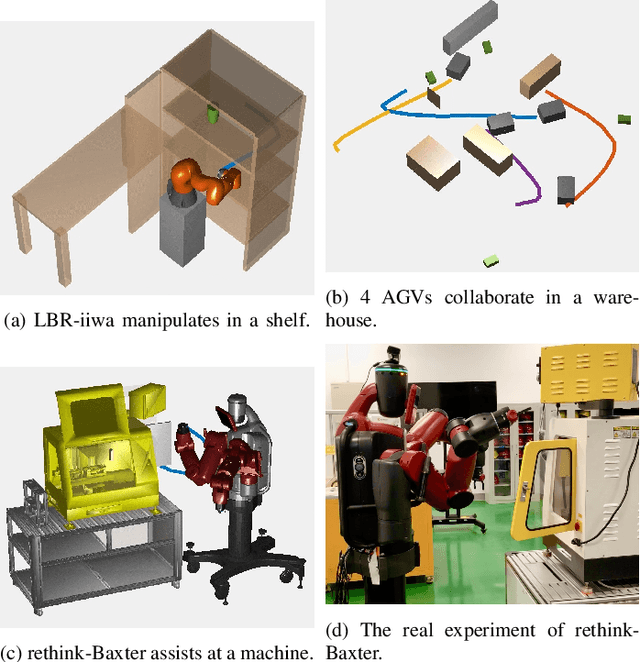
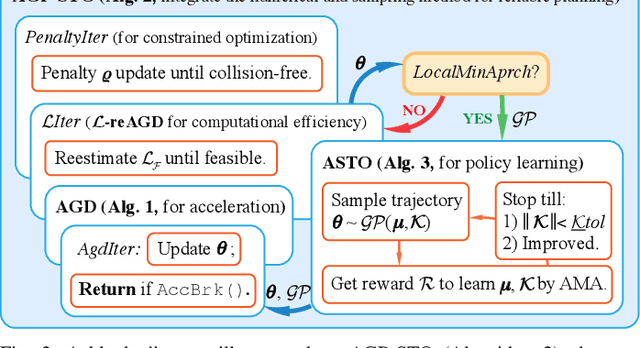
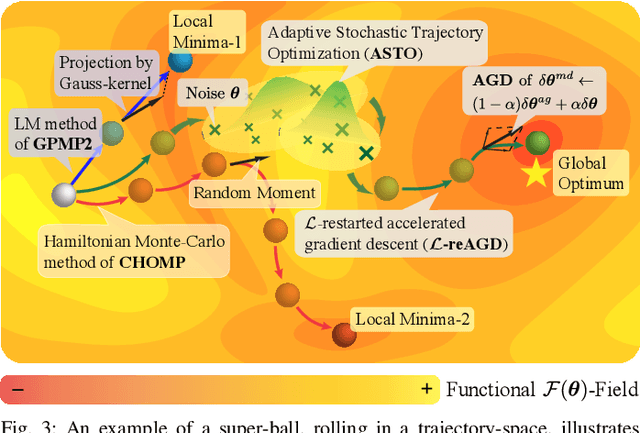
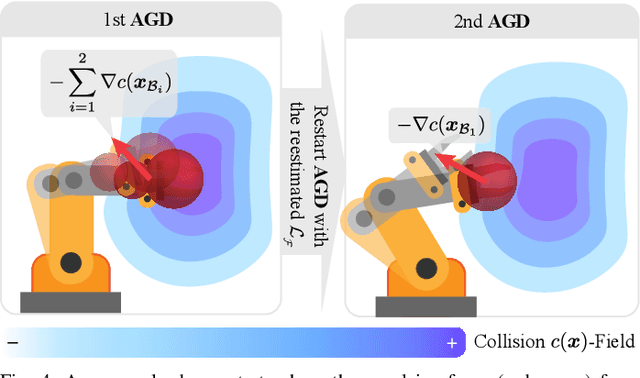
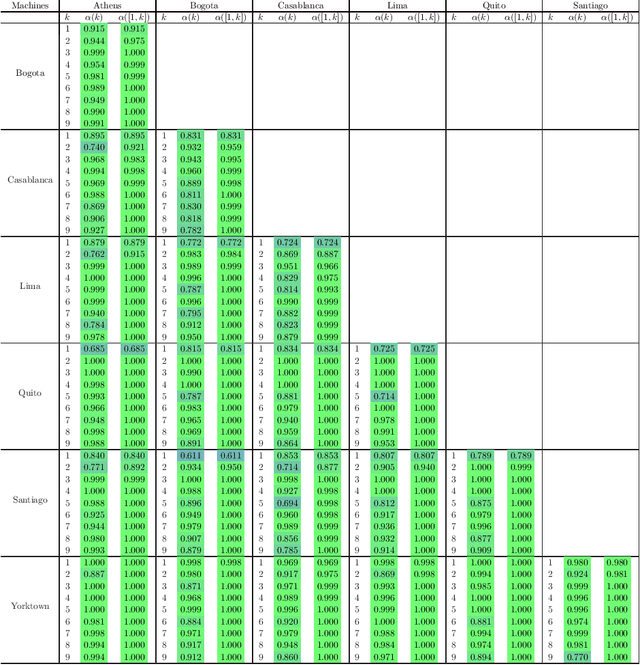
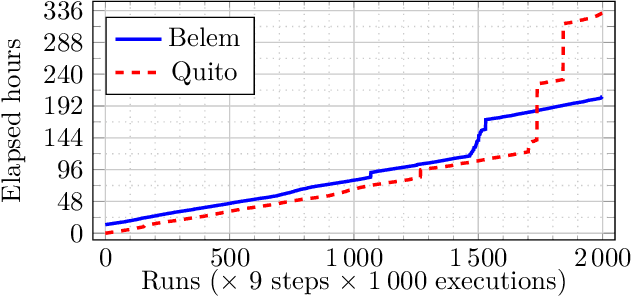
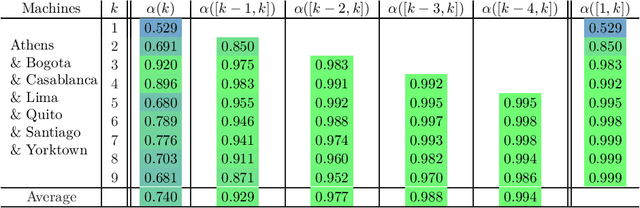
We propose a new formulation of optimal motion planning (OMP) algorithm for robots operating in a hazardous environment, called adaptive Gaussian-process based stochastic trajectory optimization (AGP-STO). It first restarts the accelerated gradient descent with the reestimated Lipschitz constant (L-reAGD) to improve the computation efficiency, only requiring 1st-order momentum. However, it still cannot infer a global optimum of the nonconvex problem, informed by the prior information of Gaussian-process (GP) and obstacles. So it then integrates the adaptive stochastic trajectory optimization (ASTO) in the L-reestimation process to learn the GP-prior rewarded by the important samples via accelerated moving averaging (AMA). Moreover, we introduce the incremental optimal motion planning (iOMP) to upgrade AGP-STO to iAGP-STO. It interpolates the trajectory incrementally among the previously optimized waypoints to ensure time-continuous safety. Finally, we benchmark iAGP-STO against the numerical (CHOMP, TrajOpt, GPMP) and sampling (STOMP, RRT-Connect) methods and conduct the tuning experiment of key parameters to show how the integration of L-reAGD, ASTO, and iOMP elevates computation efficiency and reliability. Moreover, the implementation of iAGP- STO on LBR-iiwa, multi-AGV, and rethink-Baxter demonstrates its application in manipulation, collaboration, and assistance.
ROS georegistration: Aerial Multi-spectral Image Simulator for the Robot Operating System
Jan 19, 2022



This article describes a software package called ROS georegistration intended for use with the Robot Operating System (ROS) and the Gazebo 3D simulation environment. ROSgeoregistration provides tools for the simulation, test and deployment of aerial georegistration algorithms and is made available with a link provided in the paper. A model creation package is provided which downloads multi-spectral images from the Google Earth Engine database and, if necessary, incorporates these images into a single, possibly very large, reference image. Additionally a Gazebo plugin which uses the real-time sensor pose and image formation model to generate simulated imagery using the specified reference image is provided along with related plugins for UAV relevant data. The novelty of this work is threefold: (1) this is the first system to link the massive multi-spectral imaging database of Google's Earth Engine to the Gazebo simulator, (2) this is the first example of a system that can simulate geospatially and radiometrically accurate imagery from multiple sensor views of the same terrain region, and (3) integration with other UAS tools creates a new holistic UAS simulation environment to support UAS system and subsystem development where real-world testing would generally be prohibitive. Sensed imagery and ground truth registration information is published to client applications which can receive imagery synchronously with telemetry from other payload sensors, e.g., IMU, GPS/GNSS, barometer, and windspeed sensor data. To highlight functionality, we demonstrate ROSgeoregistration for simulating Electro-Optical (EO) and Synthetic Aperture Radar (SAR) image sensors and an example use case for developing and evaluating image-based UAS position feedback, i.e., pose for image-based Guidance Navigation and Control (GNC) applications.
TTNet: Real-time temporal and spatial video analysis of table tennis
Apr 21, 2020
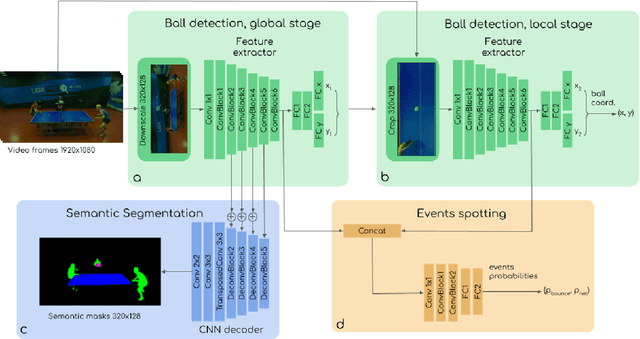
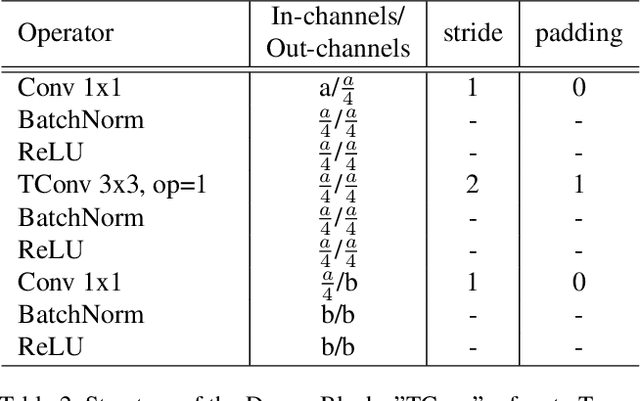
We present a neural network TTNet aimed at real-time processing of high-resolution table tennis videos, providing both temporal (events spotting) and spatial (ball detection and semantic segmentation) data. This approach gives core information for reasoning score updates by an auto-referee system. We also publish a multi-task dataset OpenTTGames with videos of table tennis games in 120 fps labeled with events, semantic segmentation masks, and ball coordinates for evaluation of multi-task approaches, primarily oriented on spotting of quick events and small objects tracking. TTNet demonstrated 97.0% accuracy in game events spotting along with 2 pixels RMSE in ball detection with 97.5% accuracy on the test part of the presented dataset. The proposed network allows the processing of downscaled full HD videos with inference time below 6 ms per input tensor on a machine with a single consumer-grade GPU. Thus, we are contributing to the development of real-time multi-task deep learning applications and presenting approach, which is potentially capable of substituting manual data collection by sports scouts, providing support for referees' decision-making, and gathering extra information about the game process.
Hardware Implementation of Spiking Neural Networks Using Time-To-First-Spike Encoding
Jun 09, 2020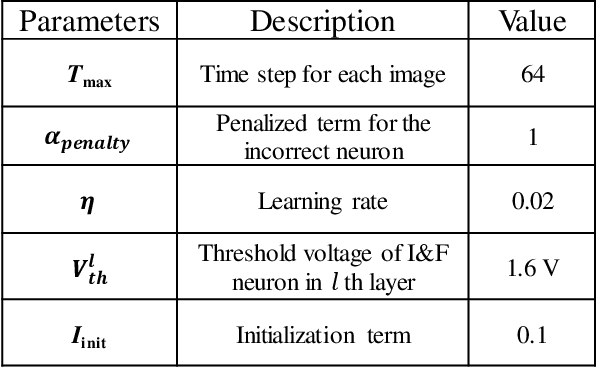

Hardware-based spiking neural networks (SNNs) are regarded as promising candidates for the cognitive computing system due to low power consumption and highly parallel operation. In this work, we train the SNN in which the firing time carries information using temporal backpropagation. The temporally encoded SNN with 512 hidden neurons showed an accuracy of 96.90% for the MNIST test set. Furthermore, the effect of the device variation on the accuracy in temporally encoded SNN is investigated and compared with that of the rate-encoded network. In a hardware configuration of our SNN, NOR-type analog memory having an asymmetric floating gate is used as a synaptic device. In addition, we propose a neuron circuit including a refractory period generator for temporally encoded SNN. The performance of the 2-layer neural network consisting of synapses and proposed neurons is evaluated through circuit simulation using SPICE. The network with 128 hidden neurons showed an accuracy of 94.9%, a 0.1% reduction compared to that of the system simulation of the MNIST dataset. Finally, the latency and power consumption of each block constituting the temporal network is analyzed and compared with those of the rate-encoded network depending on the total time step. Assuming that the total time step number of the network is 256, the temporal network consumes 15.12 times lower power than the rate-encoded network and can make decisions 5.68 times faster.
A pipeline for automated processing of Corona KH-4 (1962-1972) stereo imagery
Jan 19, 2022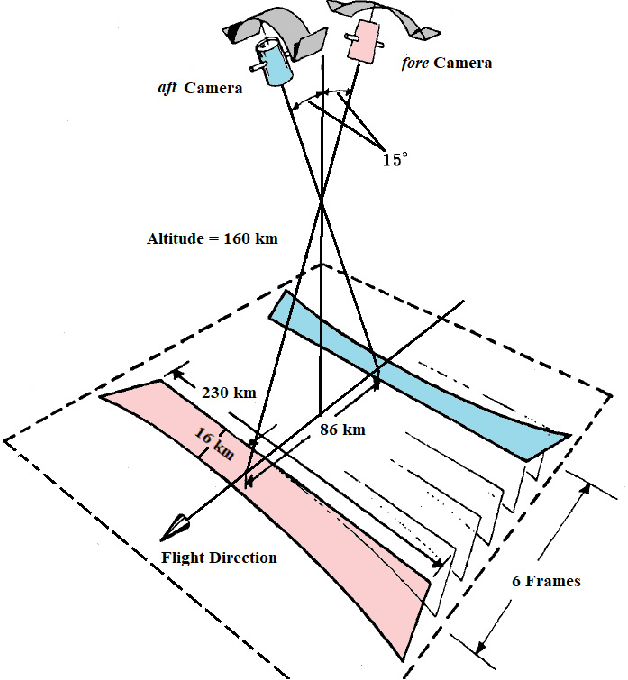
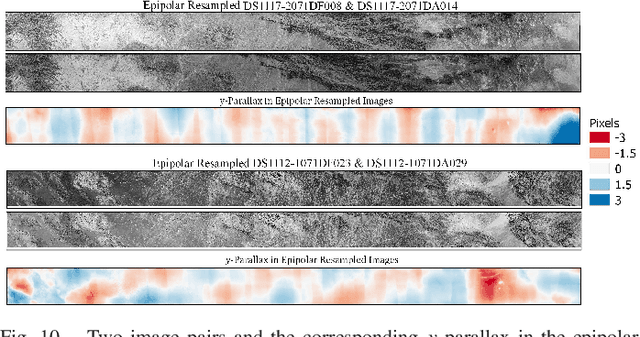
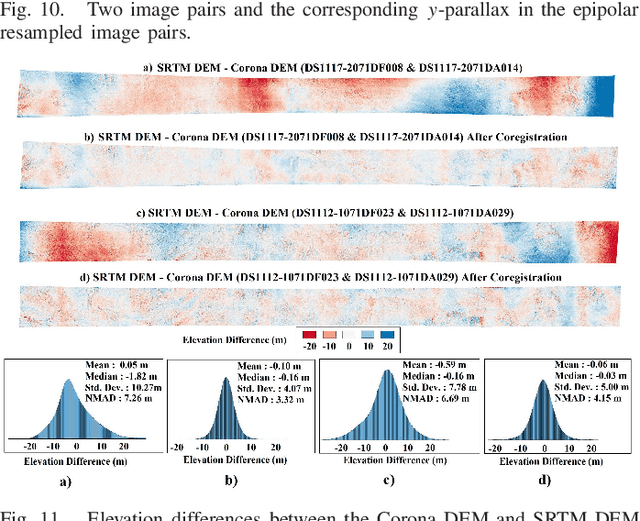

The Corona KH-4 reconnaissance satellite missions from 1962-1972 acquired panoramic stereo imagery with high spatial resolution of 1.8-7.5 m. The potential of 800,000+ declassified Corona images has not been leveraged due to the complexities arising from handling of panoramic imaging geometry, film distortions and limited availability of the metadata required for georeferencing of the Corona imagery. This paper presents Corona Stereo Pipeline (CoSP): A pipeline for processing of Corona KH-4 stereo panoramic imagery. CoSP utlizes a deep learning based feature matcher SuperGlue to automatically match features point between Corona KH-4 images and recent satellite imagery to generate Ground Control Points (GCPs). To model the imaging geometry and the scanning motion of the panoramic KH-4 cameras, a rigorous camera model consisting of modified collinearity equations with time dependent exterior orientation parameters is employed. The results show that using the entire frame of the Corona image, bundle adjustment using well-distributed GCPs results in an average standard deviation (SD) of less than 2 pixels. The distortion pattern of image residuals of GCPs and y-parallax in epipolar resampled images suggest that film distortions due to long term storage as likely cause of systematic deviations. Compared to the SRTM DEM, the Corona DEM computed using CoSP achieved a Normalized Median Absolute Deviation (NMAD) of elevation differences of ~4 m over an area of approx. 4000 $km^2$. We show that the proposed pipeline can be applied to sequence of complex scenes involving high relief and glacierized terrain and that the resulting DEMs can be used to compute long term glacier elevation changes over large areas.
On End-to-end Multi-channel Time Domain Speech Separation in Reverberant Environments
Nov 11, 2020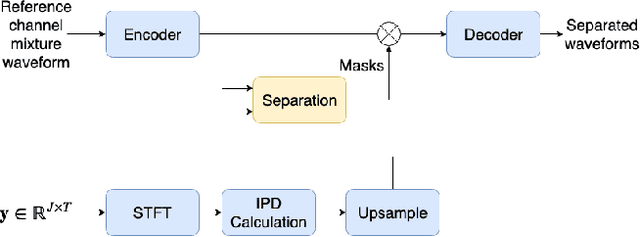

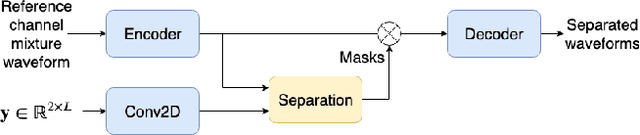
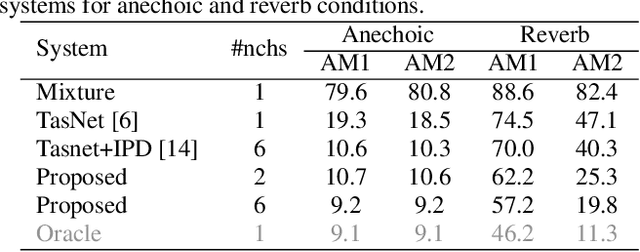
This paper introduces a new method for multi-channel time domain speech separation in reverberant environments. A fully-convolutional neural network structure has been used to directly separate speech from multiple microphone recordings, with no need of conventional spatial feature extraction. To reduce the influence of reverberation on spatial feature extraction, a dereverberation pre-processing method has been applied to further improve the separation performance. A spatialized version of wsj0-2mix dataset has been simulated to evaluate the proposed system. Both source separation and speech recognition performance of the separated signals have been evaluated objectively. Experiments show that the proposed fully-convolutional network improves the source separation metric and the word error rate (WER) by more than 13% and 50% relative, respectively, over a reference system with conventional features. Applying dereverberation as pre-processing to the proposed system can further reduce the WER by 29% relative using an acoustic model trained on clean and reverberated data.
* Presented at IEEE ICASSP 2020
Scalable Dictionary Classifiers for Time Series Classification
Jul 26, 2019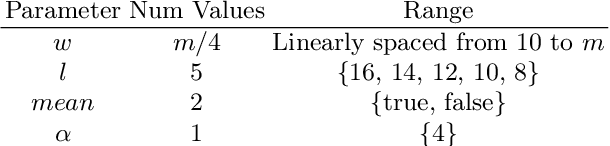


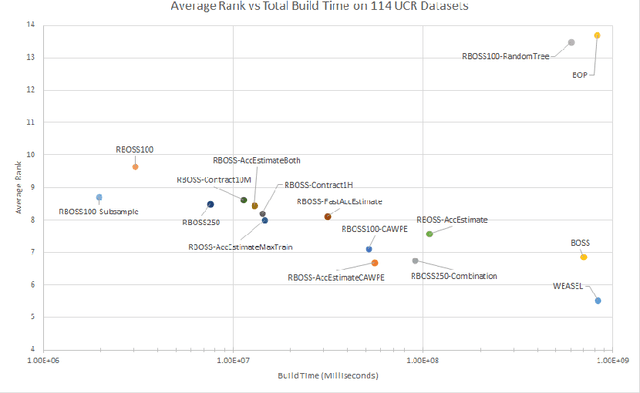
Dictionary based classifiers are a family of algorithms for time series classification (TSC), that focus on capturing the frequency of pattern occurrences in a time series. The ensemble based Bag of Symbolic Fourier Approximation Symbols (BOSS) was found to be a top performing TSC algorithm in a recent evaluation, as well as the best performing dictionary based classifier. A recent addition to the category, the Word Extraction for Time Series Classification (WEASEL), claims an improvement on this performance. Both of these algorithms however have non-trivial scalability issues, taking a considerable amount of build time and space on larger datasets. We evaluate changes to the way BOSS chooses classifiers for its ensemble, replacing its parameter search with random selection. This change allows for the easy implementation of contracting, setting a build time limit for the classifier and check-pointing, saving progress during the classifiers build. To differentiate between the two BOSS ensemble methods we refer to our randomised version as RBOSS. Additionally we test the application of common ensembling techniques to help retain accuracy from the loss of the BOSS parameter search. We achieve a significant reduction in build time without a significant change in accuracy on average when compared to BOSS by creating a size $n$ weighted ensemble selecting the best performers from $k$ randomly chosen parameter sets. Our experiments are conducted on datasets from the recently expanded UCR time series archive. We demonstrate the usability improvements to RBOSS with a case study using a large whale acoustics dataset for which BOSS proved infeasible.
Synchronous-Clock Range-Angle Relative Acoustic Navigation: A Unified Approach to Multi-AUV Localization, Command, Control and Coordination
Oct 26, 2021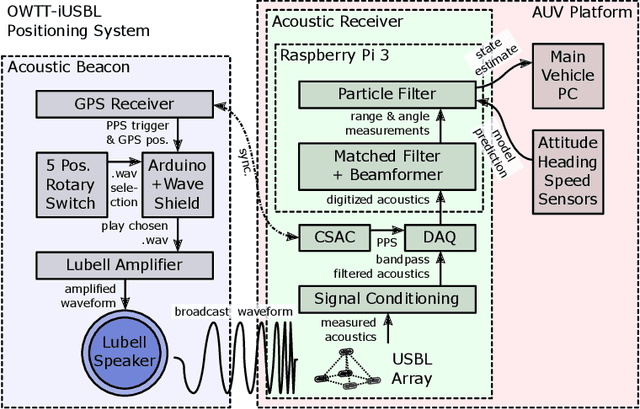
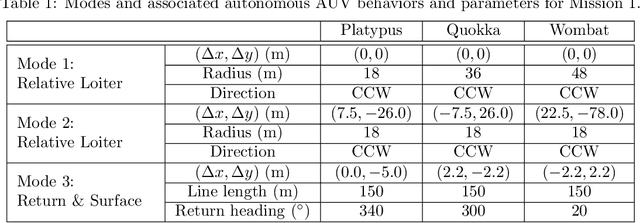


This paper presents a scalable acoustic navigation approach for the unified command, control and coordination of multiple autonomous underwater vehicles (AUVs). Existing multi-AUV operations typically achieve coordination manually, by programming individual vehicles on the surface via radio communications, which becomes impractical with large vehicle numbers; or they require bi-directional inter-vehicle acoustic communications to achieve limited coordination when submerged, with limited scalability due to the physical properties of the acoustic channel. Our approach utilizes a single, periodically-broadcasting beacon acting as a navigation reference for the group of AUVs, each of which carries a chip-scale atomic clock (CSAC) and fixed ultra-short baseline (USBL) array of acoustic receivers. One-way travel-time (OWTT) from synchronized clocks and time-delays between signals received by each array element allows any number of vehicles within receive distance to determine range, angle, and thus determine their relative position to the beacon. The operator can command different vehicle behaviors by selecting between broadcast signals from a predetermined set, while coordination between AUVs is achieved without inter-vehicle communication, by defining individual vehicle behaviors within the context of the group. Vehicle behaviors are designed within a beacon-centric moving frame of reference, allowing the operator to control the absolute position of the AUV group by re-positioning the navigation beacon to survey the area of interest. Multiple deployments with a fleet of three miniature, low-cost SandShark AUVs performing closed-loop acoustic navigation in real-time provide experimental results validated against a secondary long-baseline (LBL) positioning system, demonstrating the capabilities and robustness of our approach with real-world data.