 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainbow Deep Q-Learning with Kinematics-Aware Design for Cooperative Delta and 3-RRS Parallel Robot Insertion
May 12, 2026This paper presents a kinematics-aware deep reinforcement learning framework based on Rainbow Deep Q-Networks (DQN) for cooperative peg-in-hole manipulation by a Delta parallel robot and a 3-RRS (Revolute--Revolute--Spherical) parallel manipulator. A key contribution is the integration of a geometric design-optimization stage that precedes learning: the 3-RRS geometry is tuned to maximize the singularity-free workspace and improve conditioning, which in turn enlarges the safe region in which the reinforcement learning policy can explore. Together the two manipulators expose a 6~degree-of-freedom (DoF) controllable subspace (three Delta translations, two 3-RRS rotations, and one 3-RRS vertical translation); the peg-in-hole task is invariant to rotation about the peg axis, so the task-relevant manifold is five dimensional. The cooperative insertion problem is cast as a Markov Decision Process with a 12-dimensional state vector and a discrete action set containing $6 \times 2 = 12$ incremental commands (one positive and one negative per controlled DoF). A shaped reward combines dense proximity guidance, penalties for kinematic and workspace violations, and sparse bonuses for successful insertions. The Rainbow DQN -- integrating double Q-learning, dueling architecture, prioritized replay, multi-step returns, noisy linear layers for exploration, and a distributional value head -- is trained with a two-stage curriculum. The co-designed framework is validated in a high-fidelity kinematic simulator, where it achieves stable policy convergence, reliable insertions, and reduced constraint violations compared against a vanilla DQN agent and a classical sampling-based planner.
Quantum Machine Learning and Grover's Algorithm for Quantum Optimization of Robotic Manipulators
Sep 08, 2025Optimizing high-degree of freedom robotic manipulators requires searching complex, high-dimensional configuration spaces, a task that is computationally challenging for classical methods. This paper introduces a quantum native framework that integrates quantum machine learning with Grover's algorithm to solve kinematic optimization problems efficiently. A parameterized quantum circuit is trained to approximate the forward kinematics model, which then constructs an oracle to identify optimal configurations. Grover's algorithm leverages this oracle to provide a quadratic reduction in search complexity. Demonstrated on 1-DoF, 2-DoF, and dual-arm manipulator tasks, the method achieves significant speedups-up to 93x over classical optimizers like Nelder Mead as problem dimensionality increases. This work establishes a foundational, quantum-native framework for robot kinematic optimization, effectively bridging quantum computing and robotics problems.
Bayes Net based highbrid Monte Carlo Optimization for Redundant Manipulator
Dec 14, 2023This paper proposes a Bayes Net based Monte Carlo optimization for motion planning (BN-MCO). Primarily, we adjust the potential fields determined by goal and start constraints to progressively guide the sampled clusters toward the goal and start points. Then, we utilize the Gaussian mixed modal (GMM) to perform the Monte Carlo optimization, confronting these two non-convex potential fields. Moreover, KL divergence measures the bias between the true distribution determined by the fields and the proposed GMM, whose parameters are learned incrementally according to the manifold information of the bias. In this way, the Bayesian network consisting of sequential updated GMMs expands until the constraints are satisfied and the shortest path method can find a feasible path. Finally, we tune the key parameters and benchmark BN-MCO against the other 5 planners on LBR-iiwa in a bookshelf. The result shows the highest success rate and moderate solving efficiency of BN-MCO.
Optimal Motion Planning using Finite Fourier Series in a Learning-based Collision Field
Dec 14, 2023This paper utilizes finite Fourier series to represent a time-continuous motion and proposes a novel planning method that adjusts the motion harmonics of each manipulator joint. Primarily, we sum the potential energy for collision detection and the kinetic energy up to calculate the Hamiltonian of the manipulator motion harmonics. Though the adaptive interior-point method is designed to modify the harmonics in its finite frequency domain, we still encounter the local minima due to the non-convexity of the collision field. In this way, we learn the collision field through a support vector machine with a Gaussian kernel, which is highly convex. The learning-based collision field is applied for Hamiltonian, and the experiment results show our method's high reliability and efficiency.
Adaptive Gaussian Process based Stochastic Trajectory Optimization for Motion Planning
Dec 30, 2021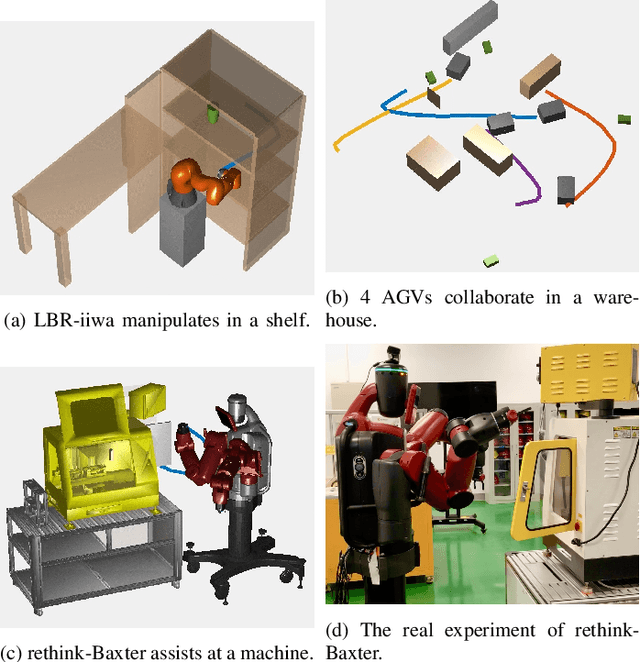
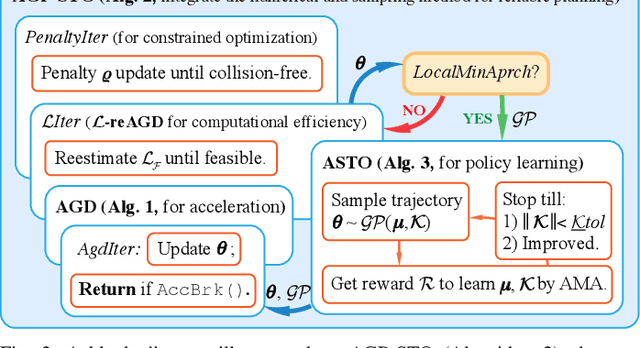
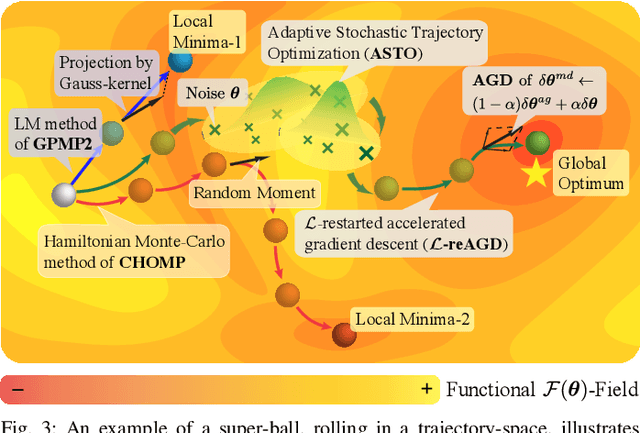
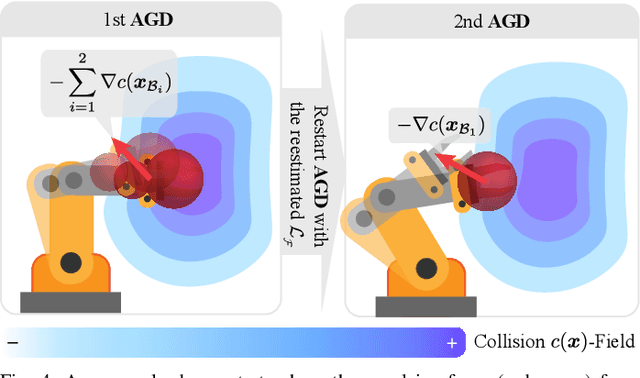
We propose a new formulation of optimal motion planning (OMP) algorithm for robots operating in a hazardous environment, called adaptive Gaussian-process based stochastic trajectory optimization (AGP-STO). It first restarts the accelerated gradient descent with the reestimated Lipschitz constant (L-reAGD) to improve the computation efficiency, only requiring 1st-order momentum. However, it still cannot infer a global optimum of the nonconvex problem, informed by the prior information of Gaussian-process (GP) and obstacles. So it then integrates the adaptive stochastic trajectory optimization (ASTO) in the L-reestimation process to learn the GP-prior rewarded by the important samples via accelerated moving averaging (AMA). Moreover, we introduce the incremental optimal motion planning (iOMP) to upgrade AGP-STO to iAGP-STO. It interpolates the trajectory incrementally among the previously optimized waypoints to ensure time-continuous safety. Finally, we benchmark iAGP-STO against the numerical (CHOMP, TrajOpt, GPMP) and sampling (STOMP, RRT-Connect) methods and conduct the tuning experiment of key parameters to show how the integration of L-reAGD, ASTO, and iOMP elevates computation efficiency and reliability. Moreover, the implementation of iAGP- STO on LBR-iiwa, multi-AGV, and rethink-Baxter demonstrates its application in manipulation, collaboration, and assistance.